图文并茂,揭秘 Spring 的 Bean 的加载过程
文章目录
-
-
- 1. 概述
- 2. 总体流程
- 3. 细节分析
-
- 3.1. 转化 BeanName
- 3.2. 合并 RootBeanDefinition
- 3.3. 处理循环依赖
-
- 3.3.1. 原型模式的循环依赖
- 3.3.2. 单例模式的构造循环依赖
- 3.3.3. 单例模式的设值循环依赖
- 3.4. 创建实例
- 3.5. 注入属性
- 3.6. 初始化
-
- 3.6.1. 触发 Aware
- 3.6.2. 触发 BeanPostProcessor
- 3.6.3. 触发自定义 init
- 3.7. 类型转换
- 4. 总结
-
1. 概述
Spring 作为 Ioc 框架,实现了依赖注入,由一个中心化的 Bean 工厂来负责各个 Bean 的实例化和依赖管理。各个 Bean 可以不需要关心各自的复杂的创建过程,达到了很好的解耦效果。
我们对 Spring 的工作流进行一个粗略的概括,主要为两大环节:
解析,读 xml 配置,扫描类文件,从配置或者注解中获取 Bean 的定义信息,注册一些扩展功能。
加载,通过解析完的定义信息获取 Bean 实例。
Spring总体流程
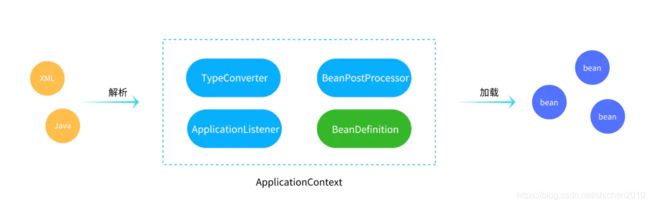
我们假设所有的配置和扩展类都已经装载到了 ApplicationContext 中,然后具体的分析一下 Bean 的加载流程。
思考一个问题,抛开 Spring 框架的实现,假设我们手头上已经有一套完整的 Bean Definition Map,然后指定一个 beanName 要进行实例化,需要关心什么?即使我们没有 Spring 框架,也需要了解这两方面的知识:
作用域。单例作用域或者原型作用域,单例的话需要全局实例化一次,原型每次创建都需要重新实例化。
依赖关系。一个 Bean 如果有依赖,我们需要初始化依赖,然后进行关联。如果多个 Bean 之间存在着循环依赖,A 依赖 B,B 依赖 C,C 又依赖 A,需要解这种循环依赖问题。
Spring 进行了抽象和封装,使得作用域和依赖关系的配置对开发者透明,我们只需要知道当初在配置里已经明确指定了它的生命周期和依赖了谁,至于是怎么实现的,依赖如何注入,托付给了 Spring 工厂来管理。
Spring 只暴露了很简单的接口给调用者,比如 getBean :
ApplicationContext context = new ClassPathXmlApplicationContext("hello.xml");
HelloBean helloBean = (HelloBean) context.getBean("hello");
helloBean.sayHello();
那我们就从 getBean 方法作为入口,去理解 Spring 加载的流程是怎样的,以及内部对创建信息、作用域、依赖关系等等的处理细节。
2. 总体流程
Bean 加载流程图
上面是跟踪了 getBean 的调用链创建的流程图,为了能够很好地理解 Bean 加载流程,省略一些异常、日志和分支处理和一些特殊条件的判断。
从上面的流程图中,可以看到一个 Bean 加载会经历这么几个阶段(用绿色标记):
- 获取 BeanName,对传入的 name 进行解析,转化为可以从 Map 中获取到 BeanDefinition 的 bean name。
- 合并 Bean 定义,对父类的定义进行合并和覆盖,如果父类还有父类,会进行递归合并,以获取完整的 Bean 定义信息。
- 实例化,使用构造或者工厂方法创建 Bean 实例。
- 属性填充,寻找并且注入依赖,依赖的 Bean 还会递归调用 getBean 方法获取。
- 初始化,调用自定义的初始化方法。
- 获取最终的 Bean,如果是 FactoryBean 需要调用 getObject 方法,如果需要类型转换调用 TypeConverter 进行转化。
整个流程最为复杂的是对循环依赖的解决方案,后续会进行重点分析。
3. 细节分析
3.1. 转化 BeanName
而在我们解析完配置后创建的 Map,使用的是 beanName 作为 key。见 DefaultListableBeanFactory:
/** Map of bean definition objects, keyed by bean name */
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<String, BeanDefinition>(256);
BeanFactory.getBean 中传入的 name,有可能是这几种情况:
- bean name,可以直接获取到定义 BeanDefinition。
- alias name,别名,需要转化。
- factorybean name, 带 & 前缀,通过它获取 BeanDefinition 的时候需要去除 & 前缀。
为了能够获取到正确的 BeanDefinition,需要先对 name 做一个转换,得到 beanName。

name转beanName
见 AbstractBeanFactory.doGetBean:
protected <T> T doGetBean ... {
...
// 转化工作
final String beanName = transformedBeanName(name);
...
}
如果是 alias name,在解析阶段,alias name 和 bean name 的映射关系被注册到 SimpleAliasRegistry 中。从该注册器中取到 beanName。见 SimpleAliasRegistry.canonicalName:
public String canonicalName(String name) {
...
resolvedName = this.aliasMap.get(canonicalName);
...
}
如果是 factorybean name,表示这是个工厂 bean,有携带前缀修饰符 & 的,直接把前缀去掉。见 BeanFactoryUtils.transformedBeanName :
public static String transformedBeanName(String name) {
Assert.notNull(name, "'name' must not be null");
String beanName = name;
while (beanName.startsWith(BeanFactory.FACTORY_BEAN_PREFIX)) {
beanName = beanName.substring(BeanFactory.FACTORY_BEAN_PREFIX.length());
}
return beanName;
}
3.2. 合并 RootBeanDefinition
我们从配置文件读取到的 BeanDefinition 是 GenericBeanDefinition。它的记录了一些当前类声明的属性或构造参数,但是对于父类只用了一个 parentName 来记录。
public class GenericBeanDefinition extends AbstractBeanDefinition {
...
private String parentName;
...
}
接下来会发现一个问题,在后续实例化 Bean 的时候,使用的 BeanDefinition 是 RootBeanDefinition 类型而非 GenericBeanDefinition。这是为什么?
答案很明显,GenericBeanDefinition 在有继承关系的情况下,定义的信息不足:
如果不存在继承关系,GenericBeanDefinition 存储的信息是完整的,可以直接转化为 RootBeanDefinition。
如果存在继承关系,GenericBeanDefinition 存储的是 增量信息 而不是 全量信息。
为了能够正确初始化对象,需要完整的信息才行。需要递归 合并父类的定义:

合并BeanDefinition
见 AbstractBeanFactory.doGetBean :
protected <T> T doGetBean ... {
...
// 合并父类定义
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
...
// 使用合并后的定义进行实例化
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
...
}
在判断 parentName 存在的情况下,说明存在父类定义,启动合并。如果父类还有父类怎么办?递归调用,继续合并。
见AbstractBeanFactory.getMergedBeanDefinition 方法:
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, BeanDefinition containingBd)
throws BeanDefinitionStoreException {
...
String parentBeanName = transformedBeanName(bd.getParentName());
...
// 递归调用,继续合并父类定义
pbd = getMergedBeanDefinition(parentBeanName);
...
// 使用合并后的完整定义,创建 RootBeanDefinition
mbd = new RootBeanDefinition(pbd);
// 使用当前定义,对 RootBeanDefinition 进行覆盖
mbd.overrideFrom(bd);
...
return mbd;
}
每次合并完父类定义后,都会调用 RootBeanDefinition.overrideFrom 对父类的定义进行覆盖,获取到当前类能够正确实例化的 全量信息。
3.3. 处理循环依赖
什么是循环依赖?
举个例子,这里有三个类 A、B、C,然后 A 关联 B,B 关联 C,C 又关联 A,这就形成了一个循环依赖。如果是方法调用是不算循环依赖的,循环依赖必须要持有引用。
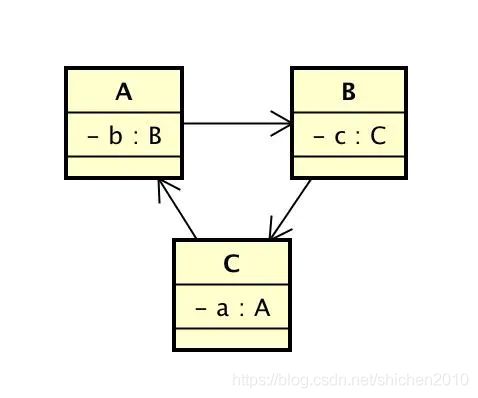
循环依赖
循环依赖根据注入的时机分成两种类型:
- 构造器循环依赖。依赖的对象是通过构造器传入的,发生在实例化 Bean 的时候。
- 设值循环依赖。依赖的对象是通过 setter 方法传入的,对象已经实例化,发生属性填充和依赖注入的时候。
如果是构造器循环依赖,本质上是无法解决的。比如我们准调用 A 的构造器,发现依赖 B,于是去调用 B 的构造器进行实例化,发现又依赖 C,于是调用 C 的构造器去初始化,结果依赖 A,整个形成一个死结,导致 A 无法创建。
如果是设值循环依赖,Spring 框架只支持单例下的设值循环依赖。Spring 通过对还在创建过程中的单例,缓存并提前暴露该单例,使得其他实例可以引用该依赖。
3.3.1. 原型模式的循环依赖
Spring 不支持原型模式的任何循环依赖。检测到循环依赖会直接抛出 BeanCurrentlyInCreationException 异常。
使用了一个 ThreadLocal 变量 prototypesCurrentlyInCreation 来记录当前线程正在创建中的 Bean 对象,见 AbtractBeanFactory#prototypesCurrentlyInCreation:
/** Names of beans that are currently in creation */
private final ThreadLocal<Object> prototypesCurrentlyInCreation =
new NamedThreadLocal<Object>("Prototype beans currently in creation");
在 Bean 创建前进行记录,在 Bean 创建后删除记录。见 AbstractBeanFactory.doGetBean:
...
if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
// 添加记录
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
// 删除记录
afterPrototypeCreation(beanName);
}
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
见 AbtractBeanFactory.beforePrototypeCreation 的记录操作:
protected void beforePrototypeCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
if (curVal == null) {
this.prototypesCurrentlyInCreation.set(beanName);
}
else if (curVal instanceof String) {
Set<String> beanNameSet = new HashSet<String>(2);
beanNameSet.add((String) curVal);
beanNameSet.add(beanName);
this.prototypesCurrentlyInCreation.set(beanNameSet);
}
else {
Set<String> beanNameSet = (Set<String>) curVal;
beanNameSet.add(beanName);
}
}
见 AbtractBeanFactory.beforePrototypeCreation 的删除操作:
protected void afterPrototypeCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
if (curVal instanceof String) {
this.prototypesCurrentlyInCreation.remove();
}
else if (curVal instanceof Set) {
Set<String> beanNameSet = (Set<String>) curVal;
beanNameSet.remove(beanName);
if (beanNameSet.isEmpty()) {
this.prototypesCurrentlyInCreation.remove();
}
}
}
为了节省内存空间,在单个元素时 prototypesCurrentlyInCreation 只记录 String 对象,在多个依赖元素后改用 Set 集合。这里是 Spring 使用的一个节约内存的小技巧。
了解了记录的写入和删除过程好了,再来看看读取以及判断循环的方式。这里要分两种情况讨论。
- 构造函数循环依赖。
- 设置循环依赖。
这两个地方的实现略有不同。
如果是构造函数依赖的,比如 A 的构造函数依赖了 B,会有这样的情况。实例化 A 的阶段中,匹配到要使用的构造函数,发现构造函数有参数 B,会使用 BeanDefinitionValueResolver 来检索 B 的实例。见 BeanDefinitionValueResolver.resolveReference:
private Object resolveReference(Object argName, RuntimeBeanReference ref) {
...
Object bean = this.beanFactory.getBean(refName);
...
}
我们发现这里继续调用 beanFactory.getBean 去加载 B。
如果是设值循环依赖的的,比如我们这里不提供构造函数,并且使用了 @Autowire 的方式注解依赖(还有其他方式不举例了):
public class A {
@Autowired
private B b;
...
}
加载过程中,找到无参数构造函数,不需要检索构造参数的引用,实例化成功。接着执行下去,进入到属性填充阶段 AbtractBeanFactory.populateBean ,在这里会进行 B 的依赖注入。
为了能够获取到 B 的实例化后的引用,最终会通过检索类 DependencyDescriptor 中去把依赖读取出来,见 DependencyDescriptor.resolveCandidate :
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory)
throws BeansException {
return beanFactory.getBean(beanName, requiredType);
}
发现 beanFactory.getBean 方法又被调用到了。
在这里,两种循环依赖达成了同一。无论是构造函数的循环依赖还是设置循环依赖,在需要注入依赖的对象时,会继续调用 beanFactory.getBean 去加载对象,形成一个递归操作。
而每次调用 beanFactory.getBean 进行实例化前后,都使用了 prototypesCurrentlyInCreation 这个变量做记录。按照这里的思路走,整体效果等同于 建立依赖对象的构造链。
prototypesCurrentlyInCreation 中的值的变化如下:
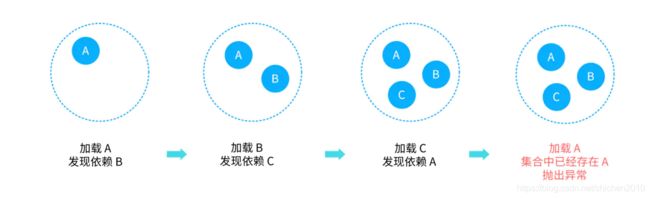
原型模式的循环依赖
调用判定的地方在 AbstractBeanFactory.doGetBean 中,所有对象的实例化均会从这里启动。
// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
判定的实现方法为 AbstractBeanFactory.isPrototypeCurrentlyInCreation :
protected boolean isPrototypeCurrentlyInCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
return (curVal != null &&
(curVal.equals(beanName) || (curVal instanceof Set && ((Set<?>) curVal).contains(beanName))));
}
所以在原型模式下,构造函数循环依赖和设值循环依赖,本质上使用同一种方式检测出来。Spring 无法解决,直接抛出 BeanCurrentlyInCreationException 异常。
3.3.2. 单例模式的构造循环依赖
Spring 也不支持单例模式的构造循环依赖。检测到构造循环依赖也会抛出 BeanCurrentlyInCreationException 异常。
和原型模式相似,单例模式也用了一个数据结构来记录正在创建中的 beanName。见 DefaultSingletonBeanRegistry:
/** Names of beans that are currently in creation */
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>(16));
会在创建前进行记录,创建化后删除记录。
见 DefaultSingletonBeanRegistry.getSingleton
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
...
// 记录正在加载中的 beanName
beforeSingletonCreation(beanName);
...
// 通过 singletonFactory 创建 bean
singletonObject = singletonFactory.getObject();
...
// 删除正在加载中的 beanName
afterSingletonCreation(beanName);
}
记录和判定的方式见 DefaultSingletonBeanRegistry.beforeSingletonCreation :
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
这里会尝试往 singletonsCurrentlyInCreation 记录当前实例化的 bean。我们知道 singletonsCurrentlyInCreation 的数据结构是 Set,是不允许重复元素的,所以一旦前面记录了,这里的 add 操作将会返回失败。
比如加载 A 的单例,和原型模式类似,单例模式也会调用匹配到要使用的构造函数,发现构造函数有参数 B,然后使用 BeanDefinitionValueResolver 来检索 B 的实例,根据上面的分析,继续调用 beanFactory.getBean 方法。
所以拿 A,B,C 的例子来举例 singletonsCurrentlyInCreation 的变化,这里可以看到和原型模式的循环依赖判断方式的算法是一样:
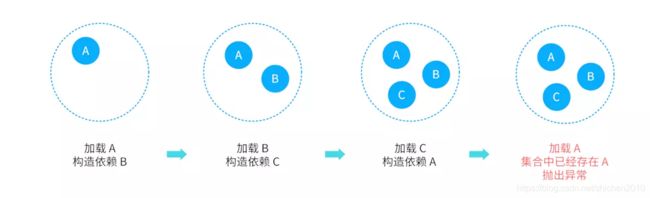
单例模式的构造循环依赖
- 加载 A。记录 singletonsCurrentlyInCreation = [a],构造依赖 B,开始加载 B。
- 加载 B,记录 singletonsCurrentlyInCreation = [a, b],构造依赖 C,开始加载 C。
- 加载 C,记录 singletonsCurrentlyInCreation = [a, b, c],构造依赖 A,又开始加载 A。
- 加载 A,执行到 DefaultSingletonBeanRegistry.beforeSingletonCreation ,singletonsCurrentlyInCreation 中 a 已经存在了,检测到构造循环依赖,直接抛出异常结束操作。
3.3.3. 单例模式的设值循环依赖
单例模式下,构造函数的循环依赖无法解决,但设值循环依赖是可以解决的。
这里有一个重要的设计:提前暴露创建中的单例。
我们理解一下为什么要这么做。
还是拿上面的 A、B、C 的的设值依赖做分析,
=> 1. A 创建 -> A 构造完成,开始注入属性,发现依赖 B,启动 B 的实例化
=> 2. B 创建 -> B 构造完成,开始注入属性,发现依赖 C,启动 C 的实例化
=> 3. C 创建 -> C 构造完成,开始注入属性,发现依赖 A
重点来了,在我们的阶段 1中, A 已经构造完成,Bean 对象在堆中也分配好内存了,即使后续往 A 中填充属性(比如填充依赖的 B 对象),也不会修改到 A 的引用地址。
所以,这个时候是否可以 提前拿 A 实例的引用来先注入到 C ,去完成 C 的实例化,于是流程变成这样。
=> 3. C 创建 -> C 构造完成,开始注入依赖,发现依赖 A,发现 A 已经构造完成,直接引用,完成 C 的实例化。
=> 4. C 完成实例化后,B 注入 C 也完成实例化,A 注入 B 也完成实例化。
这就是 Spring 解决单例模式设值循环依赖应用的技巧。流程图为:
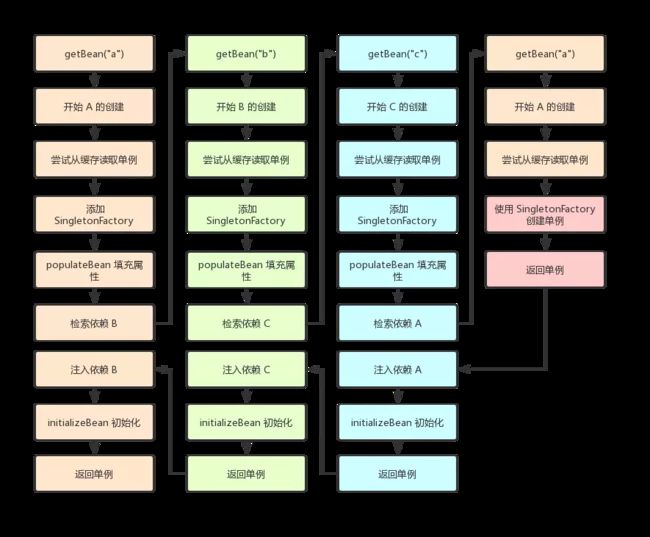
单例模式创建流程
为了能够实现单例的提前暴露。Spring 使用了三级缓存,见 DefaultSingletonBeanRegistry:
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
这三个缓存的区别如下:
- singletonObjects,单例缓存,存储已经实例化完成的单例。
- singletonFactories,生产单例的工厂的缓存,存储工厂。
- earlySingletonObjects,提前暴露的单例缓存,这时候的单例刚刚创建完,但还会注入依赖。
从 getBean(“a”) 开始,添加的 SingletonFactory 具体实现如下:
protected Object doCreateBean ... {
...
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
...
}
可以看到如果使用该 SingletonFactory 获取实例,使用的是 getEarlyBeanReference 方法,返回一个未初始化的引用。
读取缓存的地方见 DefaultSingletonBeanRegistry :
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
先尝试从 singletonObjects 和 singletonFactory 读取,没有数据,然后尝试 singletonFactories 读取 singletonFactory,执行 getEarlyBeanReference 获取到引用后,存储到 earlySingletonObjects 中。
这个 earlySingletonObjects 的好处是,如果此时又有其他地方尝试获取未初始化的单例,可以从 earlySingletonObjects 直接取出而不需要再调用 getEarlyBeanReference。
从流程图上看,实际上注入 C 的 A 实例,还在填充属性阶段,并没有完全地初始化。等递归回溯回去,A 顺利拿到依赖 B,才会真实地完成 A 的加载。
3.4. 创建实例
获取到完整的 RootBeanDefintion 后,就可以拿这份定义信息来实例具体的 Bean。
具体实例创建见 AbstractAutowireCapableBeanFactory.createBeanInstance ,返回 Bean 的包装类 BeanWrapper,一共有三种策略:
- 使用工厂方法创建,instantiateUsingFactoryMethod 。
- 使用有参构造函数创建,autowireConstructor。
- 使用无参构造函数创建,instantiateBean。
使用工厂方法创建,会先使用 getBean 获取工厂类,然后通过参数找到匹配的工厂方法,调用实例化方法实现实例化,具体见ConstructorResolver.instantiateUsingFactoryMethod :
public BeanWrapper instantiateUsingFactoryMethod ... (
...
String factoryBeanName = mbd.getFactoryBeanName();
...
factoryBean = this.beanFactory.getBean(factoryBeanName);
...
// 匹配正确的工厂方法
...
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate(...);
...
bw.setBeanInstance(beanInstance);
return bw;
}
使用有参构造函数创建,整个过程比较复杂,涉及到参数和构造器的匹配。为了找到匹配的构造器,Spring 花了大量的工作,见 ConstructorResolver.autowireConstructor :
public BeanWrapper autowireConstructor ... {
...
Constructor<?> constructorToUse = null;
...
// 匹配构造函数的过程
...
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate(...);
...
bw.setBeanInstance(beanInstance);
return bw;
}
使用无参构造函数创建是最简单的方式,见 AbstractAutowireCapableBeanFactory.instantiateBean:
protected BeanWrapper instantiateBean ... {
...
beanInstance = getInstantiationStrategy().instantiate(...);
...
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
...
}
我们发现这三个实例化方式,最后都会走 getInstantiationStrategy().instantiate(…),见实现类 SimpleInstantiationStrategy.instantiate:
public Object instantiate ... {
if (bd.getMethodOverrides().isEmpty()) {
...
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
虽然拿到了构造函数,并没有立即实例化。因为用户使用了 replace 和 lookup 的配置方法,用到了动态代理加入对应的逻辑。如果没有的话,直接使用反射来创建实例。
创建实例后,就可以开始注入属性和初始化等操作。
但这里的 Bean 还不是最终的 Bean。返回给调用方使用时,如果是 FactoryBean 的话需要使用 getObject 方法来创建实例。见 AbstractBeanFactory.getObjectFromBeanInstance ,会执行到 doGetObjectFromFactoryBean :
private Object doGetObjectFromFactoryBean ... {
...
object = factory.getObject();
...
return object;
}
3.5. 注入属性
实例创建完后开始进行属性的注入,如果涉及到外部依赖的实例,会自动检索并关联到该当前实例。
Ioc 思想体现出来了。正是有了这一步操作,Spring 降低了各个类之间的耦合。
属性填充的入口方法在AbstractAutowireCapableBeanFactory.populateBean。
protected void populateBean ... {
PropertyValues pvs = mbd.getPropertyValues();
...
// InstantiationAwareBeanPostProcessor 前处理
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
...
// 根据名称注入
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// 根据类型注入
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
...
// InstantiationAwareBeanPostProcessor 后处理
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
...
// 应用属性值
applyPropertyValues(beanName, mbd, bw, pvs);
}
可以看到主要的处理环节有:
- 应用 InstantiationAwareBeanPostProcessor 处理器,在属性注入前后进行处理。假设我们使用了 @Autowire 注解,这里会调用到 AutowiredAnnotationBeanPostProcessor 来对依赖的实例进行检索和注入的,它是 InstantiationAwareBeanPostProcessor 的子类。
- 根据名称或者类型进行自动注入,存储结果到 PropertyValues 中。
- 应用 PropertyValues,填充到 BeanWrapper。这里在检索依赖实例的引用的时候,会递归调用 BeanFactory.getBean 来获得。
3.6. 初始化
3.6.1. 触发 Aware
如果我们的 Bean 需要容器的一些资源该怎么办?比如需要获取到 BeanFactory、ApplicationContext 等等。
Spring 提供了 Aware 系列接口来解决这个问题。比如有这样的 Aware:
- BeanFactoryAware,用来获取 BeanFactory。
- ApplicationContextAware,用来获取 ApplicationContext。
- ResourceLoaderAware,用来获取 ResourceLoaderAware。
- ServletContextAware,用来获取 ServletContext。
Spring 在初始化阶段,如果判断 Bean 实现了这几个接口之一,就会往 Bean 中注入它关心的资源。
见 AbstractAutowireCapableBeanFactory.invokeAwareMethos :
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
((BeanClassLoaderAware) bean).setBeanClassLoader(getBeanClassLoader());
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
3.6.2. 触发 BeanPostProcessor
在 Bean 的初始化前或者初始化后,我们如果需要进行一些增强操作怎么办?
这些增强操作比如打日志、做校验、属性修改、耗时检测等等。Spring 框架提供了 BeanPostProcessor 来达成这个目标。比如我们使用注解 @Autowire 来声明依赖,就是使用 AutowiredAnnotationBeanPostProcessor 来实现依赖的查询和注入的。接口定义如下:
public interface BeanPostProcessor {
// 初始化前调用
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
// 初始化后调用
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
实现该接口的 Bean 都会被 Spring 注册到 beanPostProcessors 中,见 AbstractBeanFactory :
/** BeanPostProcessors to apply in createBean */
private final List<BeanPostProcessor> beanPostProcessors = new ArrayList<BeanPostProcessor>();
只要 Bean 实现了 BeanPostProcessor 接口,加载的时候会被 Spring 自动识别这些 Bean,自动注册,非常方便。
然后在 Bean 实例化前后,Spring 会去调用我们已经注册的 beanPostProcessors 把处理器都执行一遍。
public abstract class AbstractAutowireCapableBeanFactory ... {
...
@Override
public Object applyBeanPostProcessorsBeforeInitialization ... {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
result = beanProcessor.postProcessBeforeInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
@Override
public Object applyBeanPostProcessorsAfterInitialization ... {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
result = beanProcessor.postProcessAfterInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
...
}
这里使用了责任链模式,Bean 会在处理器链中进行传递和处理。当我们调用 BeanFactory.getBean 的后,执行到 Bean 的初始化方法 AbstractAutowireCapableBeanFactory.initializeBean 会启动这些处理器。
protected Object initializeBean ... {
...
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
...
// 触发自定义 init 方法
invokeInitMethods(beanName, wrappedBean, mbd);
...
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
...
}
3.6.3. 触发自定义 init
自定义初始化有两种方式可以选择:
- 实现 InitializingBean。提供了一个很好的机会,在属性设置完成后再加入自己的初始化逻辑。
- 定义 init 方法。自定义的初始化逻辑。
见 AbstractAutowireCapableBeanFactory.invokeInitMethods :
protected void invokeInitMethods ... {
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
...
((InitializingBean) bean).afterPropertiesSet();
...
}
if (mbd != null) {
String initMethodName = mbd.getInitMethodName();
if (initMethodName != null && !(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
3.7. 类型转换
Bean 已经加载完毕,属性也填充好了,初始化也完成了。
在返回给调用者之前,还留有一个机会对 Bean 实例进行类型的转换。见 AbstractBeanFactory.doGetBean :
protected <T> T doGetBean ... {
...
if (requiredType != null && bean != null && !requiredType.isInstance(bean)) {
...
return getTypeConverter().convertIfNecessary(bean, requiredType);
...
}
return (T) bean;
}
4. 总结
抛开一些细节处理和扩展功能,一个 Bean 的创建过程无非是:
获取完整定义 -> 实例化 -> 依赖注入 -> 初始化 -> 类型转换。
作为一个完善的框架,Spring 需要考虑到各种可能性,还需要考虑到接入的扩展性。
所以有了复杂的循环依赖的解决,复杂的有参数构造器的匹配过程,有了 BeanPostProcessor 来对实例化或初始化的 Bean 进行扩展修改。
先有个整体设计的思维,再逐步击破针对这些特殊场景的设计,整个 Bean 加载流程迎刃而解。
作者:DestinLee
链接:https://www.jianshu.com/p/9ea61d204559
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。