hadoop单机及完全分布式集群的安装
1. hadoop
我Hadoop的安装目录为/usr/local/workspace/hadoop
2.hdfs
2.1 单机模式
单机模式即不使用分布式模式,无需启动namenode和datanode,自动使用linux文件系统
即其配置如下,该配置也是hdfs的默认配置,file协议就是使用当前系统的文件系统
fs.defaultFS
file:///
会遇到的问题:
- 上传文件时,可能会报无权限,例如下面这个命令,将a.txt上传到 / 目录下
hadoop fs -put /usr/local/workspace/a.txt /原因是:当前用户对 / 目录没有写的权限
2.2 伪分布式模式
伪分布式模式即在一个机器上布置整个namenode和datanode
2.2.1 启动namenode
1. 修改配置
/usr/local/workspace/hadoop/etc/hadoop目录下的core-site.xml文件,配置如下所示
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/usr/local/workspace/hadoop/data/tmp
A base for other temporary directories.
2. 创建目录
必须使用hadoop.tmp.dir属性指定hadoop运行时产生文件的目录,且该目录不能自己手动创建,必须使用hadoop自带的格式化命令,执行命令后,hadoop会自动帮你创建该目录,且目录下还会创建hadoop自身所需要的文件,命令如下:
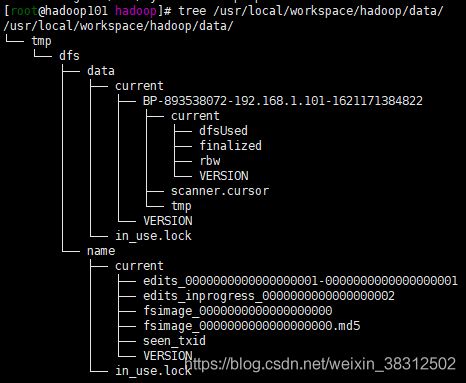
hadoop namenode -format执行命令后,我们可以使用tree命令查看文件目录结构,如果没有安装tree,可以自己安装,sudo yum -y install tree,创建的目录结果如下:

3. 启动namenode
# 启动namenode
hadoop-daemon.sh start namenode
#查看namenode是否启动成功
jps2.2.2 启动DataNode
# 启动datanode
hadoop-daemon.sh start datanode
#查看datanode是否启动成功
jps启动datanode后,hadoop也会自动创建其自身所需要的有关datanode的 目录及文件了,即hadoop namenode -format 格式化命令只需要在初始化hadoop时执行一次即可,之后重启等操作都无需再执行
关闭防火墙,且不允许开机启动
sudo chkconfig iptables off2.2.4 通过网页查看hdfs
打开浏览器,访问http://192.168.1.101:9870/
注意:hadoop3.x之前,访问端口号为50070,3.x以后端口变更为9870
2.2.5 上传文件
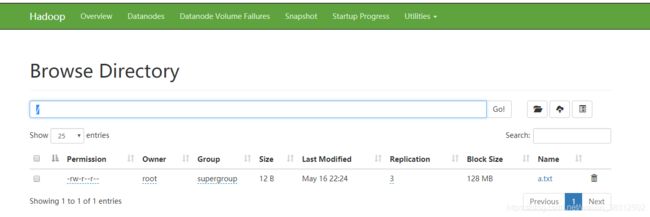
hadoop fs -put /usr/local/workspace/a.txt / 同样使用该命令上传,我们会发现a.txt并没有上传到我们linux系统的 / 目录下了,而是上传到hdfs自身的文件系统了,其自身文件系统结构也是类似linux的文件系统,即以 / 为根目录
2.2 完全分布式模式
完全分布式模式是指Hadoop在多台机器上运行。
集群的规划:
HDFS: 1个namenode+N个datanode,N个SecondNameNode
YARN:1个ResourceManager+N个NodeManager
为了避免单点故障,NN和RM建议分散到多台机器!且需要注意负载均衡,所以最终方案如下:

2.2.1 启动前的准备
- scp命令:安全拷贝命令,可以跨主机全量复制文件,即直接覆盖。
使用:scp -r 源文件用户名A@主机名1:path1 目标文件用户名B@主机名2:path2 ( -r: 递归,复制目录)
要求: 用户名A@主机名1 对path1有读权限,用户名B@主机名2 对path2有写权限
说明:当用户为当前登录shell的用户时,可以省略用户名@主机名,例如:
1. scp -r root@hadoop101:/root/ab.txt root@hadoop102:/root/hello
2. scp -r root@hadoop102:/root/hello/ab.txt /root/hello
3. scp -r /ab.txt root@hadoop102:/root/hello
- rsync:相比scp,可以只同步变化的文件(对比文件的修改时间)!增量同步!
使用: rsync -rvlt path1 目标文件用户名B@主机名2:path2(-r: 递归,复制目录, -v: 显示复制的过程,-l: 同步软连接,-t: 基于文件的修改时间进行对比,只同步修改时间不同的文件)
说明: 只能将本机的文件同步到其他机器
1. path1是个目录,且目录以/结尾,只会同步目录中的内容,不会同步目录本身!
2. path1是个目录,目录不以/结尾,同步目录中的内容,也会同步目录本身!
(假设 /tmp 中有1个文件hello.txt, 且同步到目标主机的/usr目录时,当使用 /tmp/ 时,/usr目录下会出现hello.txt, 当不使用 / 时,/usr目录会出现一个tmp文件夹,且/usr/tmp目录下存在hello.txt.)
- 免密登录(在使用scp或rsync命令时不用再输入用户密码)
A机器的a用户,希望在A机器上,使用b用户的身份登录到B机器!
实现:
①A机器的a用户,在A机器上生成一对密钥
ssh-keygen -t rsa②通过命令将A机器上的公钥拷贝到B上
ssh-copy-id b@B
- 编写同步脚本xsync
可以将当前机器的文件,同步到集群所有机器的相同路径下!(rsync命令中具体的用户名和主机名根据自己需求进行修改)
#!/bin/bash
#校验参数是否合法
if(($#==0))
then
echo 请输入要分发的文件!
exit;
fi
#获取分发文件的绝对路径
dirpath=$(cd `dirname $1`; pwd -P)
filename=`basename $1`
echo 要分发的文件的路径是:$dirpath/$filename
#循环执行rsync分发文件到集群的每条机器
for((i=101;i<=103;i++))
do
echo ---------------------hadoop$i---------------------
rsync -rvlt $dirpath/$filename root@hadoop$i:$dirpath
done
用法:bash xsync /root/hello。
如果你想 不管在哪个目录都能调用该脚本,那么需要配置环境变量。其实可以利用已存在的/etc/profile默认配置好的环境变量。

有一个家目录下的bin目录,由于我用的root用户,所以即/root/bin。我们将脚本放到这个目录下即可。
执行权限及分发文件:
#赋予权限
chmod u+x xsync
#将xsync文件分发至集群中的每个主机,分发前注意其他主机需要先创建bin文件夹。
xsync /root/bin/xsync
#或者最便捷的办法直接分发bin文件夹
xsync /root/bin
- 编写xcall脚本
作用:在集群的所有机器上批量执行同一条命令
使用ssh跨主机执行执行命令有两种方式:
1. ssh 目标机器 ,属于Login-shell,会自动读取目标主机的 /etc/profile文件中定义的所有的变量!
2. ssh 目标机器 命令,属于non-login-shell,不会读取目标主机的/etc/profile,当执行某些命令时就会报错
例如:在主机A上执行主机B的命令,ssh 主机B hadoop version ,即查看主机B的hadoop版本号,会发现提示报错hadoop 命令找不到,这就是因为non-login-shell时,主机A并没有读取主机B的/etc/profile文件。
而使用 ssh 主机B 的命令登录到主机B的shell后,再调用hadoop version就是可以的,因为这种Login-shell,主机A会自动读取主机B的/etc/profile文件。
解决:虽然non-login-shell的方式,主机A不会读取主机B的/etc/profile文件,但是却会读取~/.bashrc文件,所以只需要在目标机器的对应的用户的家目录/.bashrc中添加如下代码即可
source /etc/profile
注意:~/.bashrc是一个隐藏文件,需要 ll -af 才能查看到
接着将.bashrc文件的改动分发到其他机器上:xsync ~/.bashrc
编写xcall脚本:
#!/bin/bash
#在集群的所有机器上批量执行同一条命令
if(($#==0))
then
echo 请输入您要操作的命令!
exit
fi
echo 要执行的命令是$*
#循环执行此命令
for((i=101;i<=103;i++))
do
echo ---------------------hadoop$i-----------------
ssh hadoop$i $*
done赋予脚本权限及分发文件:
#赋予权限
chmod u+x xcall
#分发到集群的其他主机,分发前注意其他主机需要先创建bin文件夹。
xync /root/bin/xcall
#或者最便捷的办法直接分发bin文件夹
xsync /root/bin结果:

2.2.2 hadoop配置
先在hadoop101主机上安装hadoop,然后修改配置文件
- 修改core-site.xml文件
进入/usr/local/workspace/hadoop/etc/hadoop目录,修改core-site.xml文件,配置如下所示
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/usr/local/workspace/hadoop/data/tmp
- 修改hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop103:50090
-
修改yarn-site.xml
yarn.resourcemanager.hostname
hadoop102
yarn.nodemanager.aux-services
mapreduce_shuffle
- 新增以下mapred-site.xml配置
mapreduce.framework.name
yarn
自行配置/etc/profile环境变量
export HADOOP_HOME=/usr/local/workspace/hadoop
export JAVA_HOME=/usr/java/jdk1.8.0_291
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH分发/etc/profile和hadoop文件夹至服务器各个主机
xync /etc/profile
xync /usr/local/workspace/hadoop2.2.3 格式化命令
由于nameNode是安装在hadoop101的,所以在hadoop101上格式化
hadoop namenode -format 2.2.4 不同的节点启动不同的进程
- hadoop101启动namenode
hadoop-daemon.sh start namenode- 在hadoop101,102,103启动datanode
xcall hadoop-daemon.sh start datanode- 在hadoop103上启动SecondNameNode
hadoop-daemon.sh start secondarynamenode2.2.5 关闭防火墙且不允许开机自启
xcall service iptables stop
xcall sudo chkconfig iptables off2.2.6 在hadoop102上启动ResourceManager
yarn-daemon.sh start resourcemanager2.2.7 三个节点都起nodeManager
xcall yarn-daemon.sh start nodemanager2.2.8 查看结果
1. NameNode:http://hadoop101:9870/
2. ResourceManager: http://hadoop102:8088/
3. SecondNameNode: http://hadoop103:50090/
2.2.9 测试
测试hdfs
#创建目录
hadoop fs -mkdir /wcinput
#上传文件
hadoop fs -put a.txt /wcinput测试map-reduce(第三大节给出)
2.2.10 群起脚本
脚本位于/usr/local/workspace/hadoop/sbin
start-all.sh时,其实分别调用了start-dfs.sh和start-yarn.sh
start-dfs.sh可以在集群的任意一台机器使用!可以启动HDFS中的所有进程!
start-yarn.sh在集群的非RM所在的机器使用,不会启动resourcemanager!
- 修改hadoop-env.sh
如果不修改此文件,使用脚本时会报错。
原理:获取集群中所有的节点的主机名,并批量执行 ssh 主机名 hadoop-daemon.sh start xxx 命令.通过修改hadoop-env.sh配置,可以指定当前用户可以执行哪些命令,即给命令加上执行权限
该文件在/usr/local/workspace/hadoop/etc/hadoop目录下:
# 由于批量脚本的执行方式采用no-login-shell,即不读取目标主机的/etc/profile文件,而启动hadoop时又是需要读取java_home的,所以这里需要配置JAVA_HOME,不过我们在写xcall脚本时已经解决了no-login-shell的这个问题,所以JAVA_HOME不写也可以
export JAVA_HOME=/usr/java/jdk1.8.0_291
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root- 修改workers
作用是指定DataNode节点和NodeManager需要在哪些主机上启动。如果不修改此文件,那么即使使用了start-all.sh脚本命令,也只会在你运行命令的那台主机上启动一个DataNode和NodeManager服务,其他主机不会启动这两个服务。
该文件位于/usr/local/workspace/hadoop/etc/hadoop:
#不要有空行和空格
hadoop101
hadoop102
hadoop103注意:start-yarn.sh在集群的非RM所在的机器使用,不会启动resourcemanager!,所以最好在resourcemanager所在的主机上执行群起脚本。
2.2.11 mapReduce日志
当执行mapReduce计算时,此过程产生的日志我们肯定是需要记录并查看的
进入/usr/local/workspace/hadoop/etc/hadoop目录
- 新增mapred-site.xml配置
mapreduce.jobhistory.address
hadoop101:10020
mapreduce.jobhistory.webapp.address
hadoop101:19888
yarn.log.server.url
http://hadoop101:19888/jobhistory/logs
- 新增yarn-site.xml配置
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
-
启动hadoop101上的日志服务
cd /usr/local/workspace/hadoop/sbin
mr-jobhistory-daemon.sh start historyserver-
重启服务,查看http://hadoop102:8088/,Applications中每一条记录都代表着一次MapReduce应用操作

2.2.12 同步集群时间
使用ntp时间同步服务直接获取目标时间,我们这里取阿里云的时间
sudo ntpdate -u ntp.aliyun.com定时获取,执行命令,crontab -e,并编辑如下,每一小时同步一次:
* */1 * * * ntpdate -u ntp.aliyun.com
3. MapReduce
有两种运行模式, 取决于参数: mapreduce.framework.name=local(默认)。
1. 本地模式(在本机上运行MR) mapreduce.framework.name=local。在本机使用多线程的方式,运行多个Task!
2. 在YARN上运行 mapreduce.framework.name=yarn。将MR提交给YARN,由YARN将Job中的多个task分配到多台机器中,启动container运行task!
3.1 在本机上运行MapReduce程序(mapreduce .framework.name=local)
需求:使用mapReduce计算根目录/下的所有文件的单词出现的次数
#进入jar包所在目录
cd /usr/local/workspace/hadoop/share/hadoop/mapreduce
#语法Hadoop jar 指定mapreducejar包 执行的功能 输入目录(该目录下必须全为文件) 值的输出路径
hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount / /wc说明:hadoop-mapreduce-examples-3.2.2.jar该jar包位于$HADOOP_HOME/share/hadoop/mapreduce.
结果:
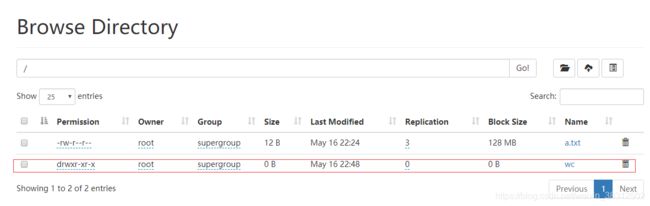
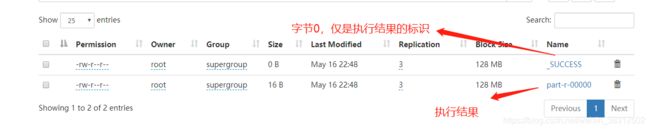
查看结果有两种方式:
1. 通过命令来查看该文件内容
hadoop fs -cat /wc /part-r-000002. 点击wc,可以看到有两个文件,下载有size的文件查看
3.2 在yarn上运行MapReduce(完全分布式已经给出配置)
3.2.1 新增mapred-site.xml配置
指定mapreduce使用yarn运行
mapreduce.framework.name
yarn
3.2.2 修改yarn-site.xml配置
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件,如下:
yarn.resourcemanager.hostname
hadoop101
yarn.nodemanager.aux-services
mapreduce_shuffle
配置说明:
yarn.resourcemanager.hostname的valuehadoop101 是我本机linux的hostname,可通过shell命令hostname查看自己主机的hostname
yarn.nodemanager.aux-services:计算分为map和reduce,map是将任务分解为多个task分别执行,reduce是将多个task执行的结果合并起来统一处理,所以reduce是需要分别获取到map的执行结果的,而这个操作需要shuffle服务来支持,如果不配置该配置项,在reduce计算时就会报错。
3.2.3 启动yarn
#启动resourcemanager
yarn-daemon.sh start resourcemanager
#启动nodemanager
yarn-daemon.sh start nodemanager
#查看进程
jps3.2.4 访问ResourceManager
http://192.168.1.101:8088
3.2.5 再次计算,并通过hdfs查看输出目录
#进入jar包所在目录
/usr/local/workspace/hadoop/share/hadoop/mapreduce
#不能再输出到wc,因为该目录已被使用,且输入目录中必须全部是文件,即不能直接用/了,要直接指定/a.txt文件
hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /a.txt /wc2