VGG网络
VGG网络是2014年ILSVRC竞赛的第二名(第一名是GoogleNet,即后来的inception),由牛津大学的计算机视觉实验组提出。原始论文地址https://arxiv.org/abs/1409.1556
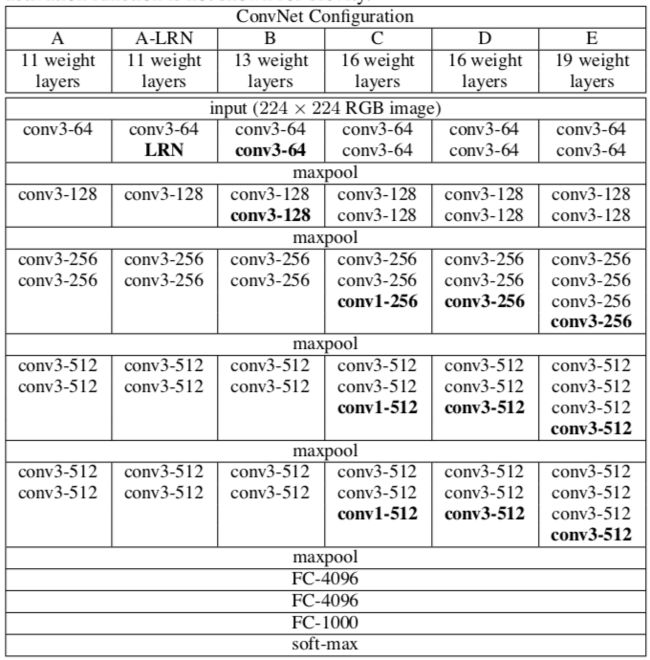
VGG的出现证明了网络深度的增加可以提升模型的效果,它由一系列的卷积、池化堆叠而成,在论文中作者搭建了不同深度的6种VGG模型,命名A-E,网络深度依次加深。通常VGG16和VGG19是指D、E两个版本。
下表是原始论文中的6个版本VGG结构,A-LRN是在A版本的基础上使用了AlexNet中的LRN层,用来对比。
VGG的另一个特点是使用的卷积只有1*1和3*3的卷积,2个3*3的卷积代替5*5卷积,3个3*3卷积代替7*7的卷积,尽管它们的感受野相同,但使用多个小卷积代替大卷积,在保证感受野不变的情况下可以使参数量减小,且提升了网络的深度。比如5*5的卷积需要的参数量是25个,而用2个小的3*3卷积代替只需要18个。
此外VGG中使用了1*1的卷积,作者认为1x1卷积可以增加决策函数的非线性能力,非线性是由激活函数决定的,1x1卷积是线性映射,在同样的维度上映射特征图。
VGG的输入是224*224尺寸的图像,且经过特殊处理后才输入网络,处理不仅包括归一化等常规操作,并且每个像素值还减去了在总的训练集的均值。
在Keras中内置了处理输入的函数。
from keras.applications.imagenet_utils import preprocess_input
img = preprocess_input(img) # img是要输入的图像
# 查看preprocess_input函数的部分源码如下
# 该函数针对TensorFlow、caffe、Torch的处理并不相同,对tf只需将图像像素值缩放到-1和1之间,caffe则将图片通道变为BGR,做中心化但不缩放像素值范围,Torch缩放像素值在0到1之间,然后标准化。
if mode == 'tf':
x /= 127.5
x -= 1.
return x
if mode == 'torch':
x /= 255.
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
else:
if data_format == 'channels_first':
# 'RGB'->'BGR'
if backend.ndim(x) == 3:
x = x[::-1, ...]
else:
x = x[:, ::-1, ...]
else:
# 'RGB'->'BGR'
x = x[..., ::-1]
mean = [103.939, 116.779, 123.68]
std = None
Keras搭建VGG16并进行花卉分类
一个在线可视化vgg16结构的网站: https://dgschwend.github.io/netscope/#/preset/vgg-16
数据集来自谷歌的一个鲜花数据集,网址http://download.tensorflow.org/example_image/flower_photo.tgz
该数据集比较小,包含五类鲜花的照片,Diasy(小雏菊)、 tulip(郁金香)、rose(玫瑰)、sunflower(向日葵)、dandelion(蒲公英),每一类图片有800张左右,且大小不一,但图像都比较小约为,400x300。


对数据集的处理,采用npy格式存储数据。OpenCV读取图像后,直接使用preprocess_input 函数处理,然后存入npy文件。标签采用to_categorical进行独热编码转换标签。
使用Keras搭建VGG16,比较方便,按照论文中的结构一层层累积即可。每层卷积使用relu激活函数,最后输出softmax分类,类别为5,优化器采用sgd(在网上一个博客看到说采用Adam优化效果更好,但我试了没有sgd效果好?),分类交叉熵损失categorical_crossentropy。
Keras的另一个好处是keras.applications模块内置了许多模型,包括VGG、ResNet、InceptionV3、DenseNet121等。因此我们可以使用内置的VGG16,只需修改最后的全连接层输出类别即可。
import numpy as np
from keras.models import Model, load_model
from keras.layers import Dropout, Flatten, Dense, Input
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils import plot_model,to_categorical
from keras import optimizers
import os
import cv2
from keras.applications import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.callbacks import TensorBoard
class vgg():
def __init__(self, shape, num_classes, data_path, label_path, model_path):
self.shape = shape
self.num_classes = num_classes
self.data_path = data_path
self.label_path = label_path
self.model_path = model_path
self.log_path = "./logs"
self.classes = self.classname()
def classname(self, prepath="D://Datasets//flower_photos//flower_photos//"):
# 数据集的类别序号和对应名称,注意的是序号是从1开始,而label中编码实际是从0开始
classes = os.listdir(prepath) # 类别序号和名称
class_dict = {int(Class.split(".")[0]): Class.split(".")[1] for Class in classes[0:5]}
return class_dict
def generate_data(self, prepath="D://Datasets//flower_photos//flower_photos//"):
classes = os.listdir(prepath) # 类别序号和名称
data_path = self.data_path
label_path = self.label_path
datas = []
labels = []
for i, abspath in enumerate(classes): # prepath的每一个文件目录
img_names = os.listdir(prepath + abspath)
for img_name in img_names: # 子目录中的每一张图片
img = cv2.imread(os.path.join(prepath + abspath, img_name)) # cv2读取
if not isinstance(img, np.ndarray):
print("read img error")
continue
img = cv2.resize(img, (224, 224)) # 尺寸变换224*224
# img = img.astype(np.float32) # 类型转换为float32
img = preprocess_input(img)
label = to_categorical(i, self.num_classes)
labels.append(label)
datas.append(img)
datas = np.array(datas)
labels = np.array(labels)
np.save(data_path, datas)
np.save(label_path, labels)
return True
def vgg_model(self): # 自行构建VGG16
input_1 = Input(shape=self.shape) # 输入224*224*3
# 第一部分
# 卷积 64深度,大小是3*3 步长为1 使用零填充 激活函数relu
# 2次卷积 一次池化 池化尺寸2*2 步长2*2
x = Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(input_1)
x = Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x) # 64 224*224
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="SAME")(x) # 64 112*112
# 第二部分 2次卷积 一次池化
# 卷积 128深度 大小是3*3 步长1 零填充
x = Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x) # 128 112*112
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="SAME")(x) # 128 56*56
# 第三部分 3次卷积 一次池化 卷积256 3*3
x = Conv2D(filters=256, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=256, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=256, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x) # 256 56*56
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="SAME")(x) # 256 28*28
# 第四部分 3次卷积 一次池化 卷积 512 3*3
x = Conv2D(filters=512, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x) # 512 28*28
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="SAME")(x) # 512 14*14
# 第五部分 3次卷积 一次池化 卷积 512 3*3
x = Conv2D(filters=512, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=(1, 1), padding="SAME", activation="relu")(x) # 512 14*14
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="SAME")(x) # 512 7*7
x = Flatten()(x) # 扁平化,用在全连接过渡
# 第六部分 三个全连接
# 第一个和第二个全连接相同 输出4096 激活relu 使用dropout,随机丢弃一半
x = Dense(4096, activation="relu")(x)
Dropout(0.5)(x)
x = Dense(4096, activation="relu")(x)
Dropout(0.5)(x) # 输出 4096 1*1
# 第三个全连接层 输出 softmax分类
out_ = Dense(self.num_classes, activation="softmax")(x)
model = Model(inputs=input_1, outputs=out_)
# print(model.summary())
sgd = optimizers.sgd(lr=0.001, momentum=0.9, nesterov=True)
model.compile(sgd, loss="categorical_crossentropy", metrics=["accuracy"])
# plot_model(model,"model.png")
return model
def pretrain_vgg(self): # 采用预训练的VGG16,修改最后一层
model_vgg = VGG16(include_top=False, weights='imagenet', input_shape=(224, 224, 3)) # 不包含最后一层
model = Flatten(name='Flatten')(model_vgg.output)
model = Dense(self.num_classes, activation='softmax')(model) # 最后一层自定义
model_vgg = Model(inputs=model_vgg.input, outputs=model, name='vgg16')
sgd = optimizers.SGD(lr=0.001, momentum=0.9, nesterov=True)
# sgd效果比Adam更好
# adam = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model_vgg.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
# model_vgg.summary()
return model_vgg
def train(self, load_pretrain=False, batch_size=32, epoch=50):
if load_pretrain:
model = self.pretrain_vgg()
else:
model = self.vgg_model()
# TensorBoard查看日志
logs = TensorBoard(log_dir=self.log_path, write_graph=True, write_images=True)
data_path = self.data_path
label_path = self.label_path
save_path = self.model_path
x = np.load(data_path)
y = np.load(label_path)
# 必须打乱 否则验证集loss和acc会出问题
np.random.seed(200)
np.random.shuffle(x)
np.random.seed(200)
np.random.shuffle(y)
model.fit(x, y, batch_size=batch_size, epochs=epoch, verbose=1, validation_split=0.3,
callbacks=[logs])
model.save(save_path)
def predict(self, img_path="test.jpg"):
# model = vgg_model((224,224,3),5)
model_path = self.model_path
model = load_model(model_path)
test_img = cv2.imread(img_path)
test_img = cv2.resize(test_img, (224, 224))
test_img = preprocess_input(test_img)
ans = model.predict(test_img.reshape(1, 224, 224, 3))
max_index = np.argmax(ans, axis=1) # 预测结果是值范围0-4的行向量,因此对应的类别序号要+1
print("预测结果是%s"%(self.classes[max_index[0] + 1]))
data = r"D:\Datasets\flower_photos\flower_photos\train_data.npy"
label = r"D:\Datasets\flower_photos\flower_photos\labels.npy"
mode_path = r"D:\Datasets\flower_photos\flower_photos\flowers_5classes.h5"
vgg16 = vgg((224,224,3), 5, data, label, mode_path)
# vgg16.generate_data()
# vgg16.train(batch_size=32,epoch=50)
# vgg16.predict(imgpath)
为了节省时间只训练了30轮,收敛挺快。
TensorBoard查看模型结构如下:

训练过程acc和loss变化曲线:

预测也基本可以成功,懒得放图了。
此外遇到的一个问题记录一哈,刚开始在model.fit之前没有加入打乱data和label,我想着fit本身有个参数shuffle=True,结果训练过程中训练集的acc不断提高,甚至会稳持续在1.000,loss降不下来,始终在十点多,验证集更离谱,有时acc为0,loss保持不变,有时则是acc稳定在0.2,loss降不下。
后来查了发现这个打乱是打乱一个batch里面的数据顺序,在投入数据集训练之前,整个数据集的顺序应该被随机打乱才行。
np.random.seed(200)
np.random.shuffle(x)
np.random.seed(200)
np.random.shuffle(y)