1, 编译:redis源码是基于makefile构建的,在ide里调试很麻烦,不能符号跳转,所以就根据makefile里描述的编译过程,用cmake重新写一遍,导入到clion里调试分析。
编译c / c++,不管怎么构建,不管用什么ide (eclipse cdt,visual studio,xcode,clion),都要设置几个关键的东西:头文件路径,依赖的lib路径,lib名,编译器选项,源码中编译相关的宏。
编译redis server的CMakeLists.txt
编译redis-server
aux_source_directory(. DIR_REDIS_SERVER_SRCS)
add_executable(redis-server ${DIR_REDIS_SERVER_SRCS})
target_include_directories(redis-server PRIVATE
./include
../lua
../hiredis
../jemalloc)
target_link_libraries(redis-server
m dl hiredis lua jemalloc)
编译redis-cli
set(REDIS_CLI_SRCS anet.c adlist.c redis-cli/redis-cli.c zmalloc.c release.c anet.c ae.c crc64.c)
add_executable(redis-cli ${REDIS_CLI_SRCS})
target_include_directories(redis-cli PRIVATE
.
../hiredis
../linenoise)
target_link_libraries(redis-cli
m dl hiredis linenoise jemalloc)
//target_compile_options() 添加编译选项 -Wall之类的
//target_compile_definitions() 添加预定义宏
//PRIVATE依赖:头文件不依赖,源文件依赖
//INTERFACE:头文件依赖 源文件不依赖
//PUBLIC 头文件和源文件都依赖
2,c/c++指令的项目,直接搜索main方法。
redis-server的main方法在server.c文件里。下面开始描述server启动的整个过程。
整个server的主要状态都保存在redisServer server这个结构体里,先看一眼:
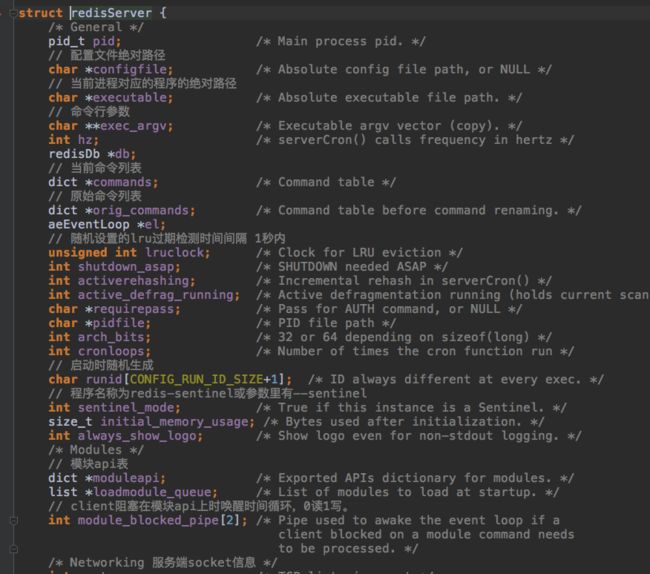
首先初始化server,c语言中变量不初始化,值是不确定的。
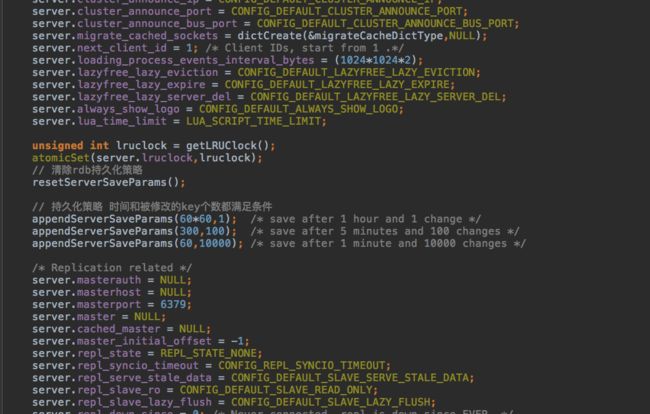
值得注意的是默认的持久化策略。
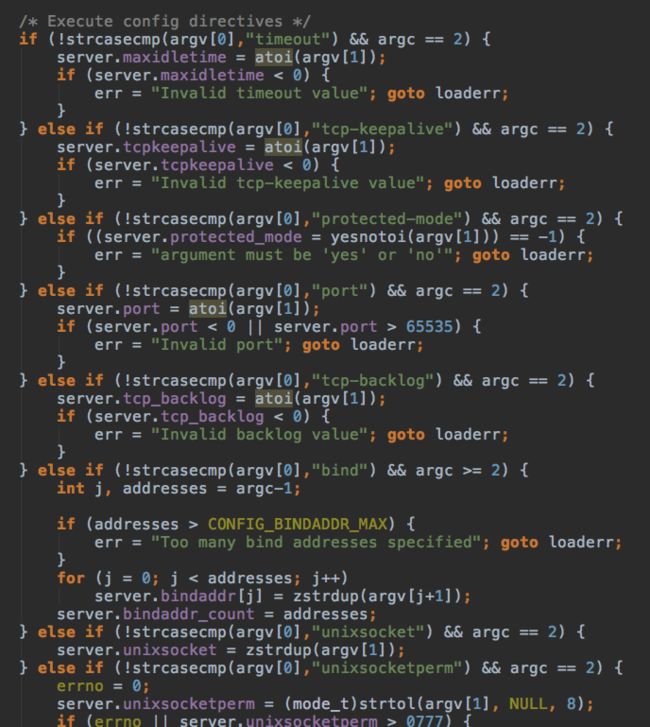
然后是命令行参数解析:
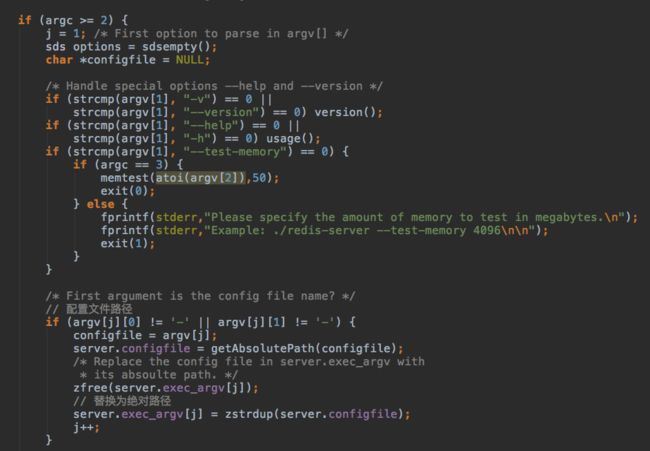
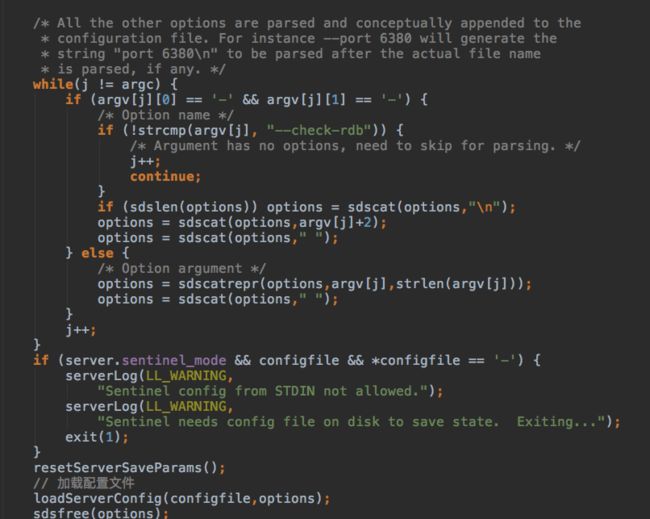
redis-server的第一个参数如果不是以一个或两个减号开头就表示配置文件路径,
后续的可选参数会跟读到内存中的配置文件内容合到一起解析。然后就是一行一行的处理配置文件了。
server状态加载完毕,可以初始化socket准备接收client连接了,毫无疑问使用IO多播,但是跟netty又不太一样,netty是使用jdk里的nio,jdk为了可移植,使用了所有系统都支持且行为一致的select/poll。但是select/poll由于每次都要把监控的fd和关联event传入内核,然后内核再把IO可用的fd和event返回给调用方,性能较差,select比poll性能更差,select只能指定最大fd,poll可以精确指定fd。所以像redis和nginx这种支持超高并发的系统都会使用各个系统特定的性能更高的api。linux上使用epoll,osx上使用kqueue,unix上使用/dev/poll。
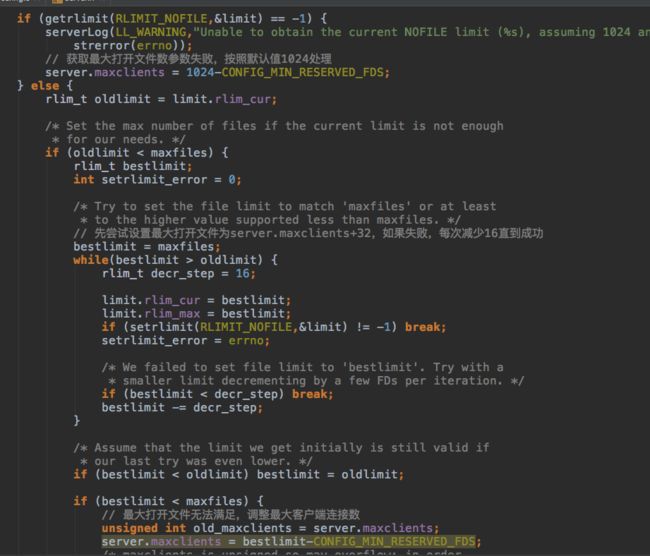
先解释一下fd这个东西:file descriptor,文件描述符,linux/unix系统中号称一切都是文件,每个文件都有一个fd,类似windows上的Handle,打开文件时获取fd,操作文件时指定fd。linux系统上有一个配置,指定了fd_set的大小。fd_set表示一个进程打开的所有fd,顺序增加,0,1,2分别表示stdin/stdout/stderr。每次打开文件,从0开始查找fd_set中第一个未被占用的fd作为新打开文件的fd。fd_set默认大小1024。所以第一步是根据设置的client连接数最大值调整fd_set。
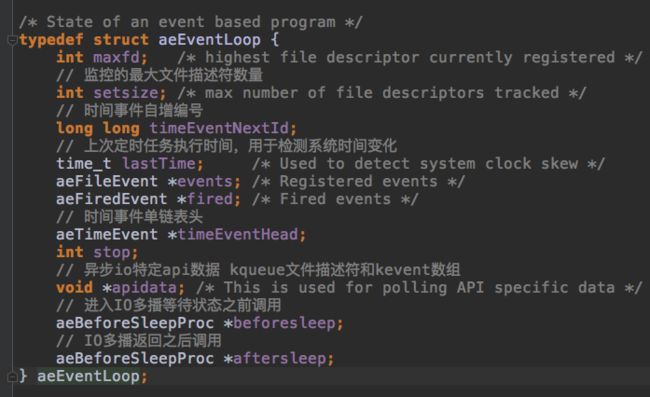
之后是调用kqueue系统api初始化aeEventLoop结构体,绑定到指定端口。aeEventLoop中主要有两类字段:timeEventNextId,lastTime,timeEventHead跟定时任务有关,其他的跟IO多播有关。
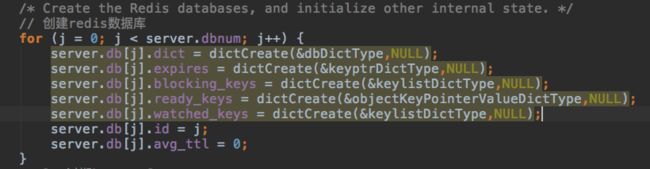
之后是初始化redis的16个db。dict是hash table结构,之后统一描述各种数据结构。
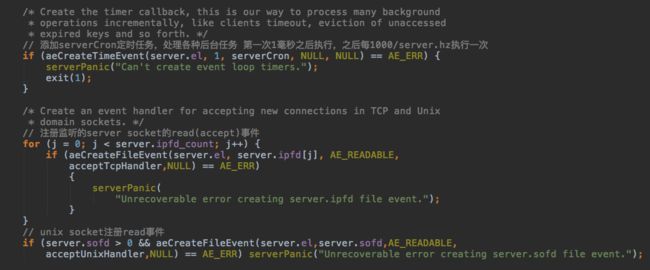
之后会把一个非常重要的定时任务添加到EventLoop上,然后把server socket的fd注册到kqueue的监控列表里。
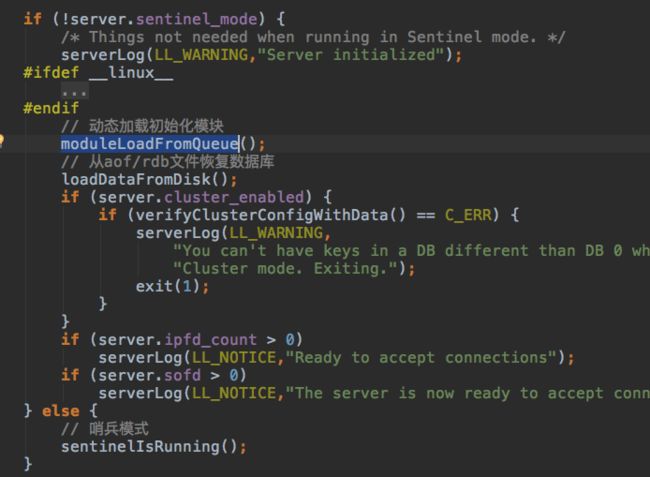
之后是加载动态模块和从aof/rdb里恢复状态。redis有一套扩展用的api,server启动时可以加载实现里这些api的动态库。有一个很明显很有用的扩展点:通过实现api往EventLoop里添加定时任务。
最后进入主循环:
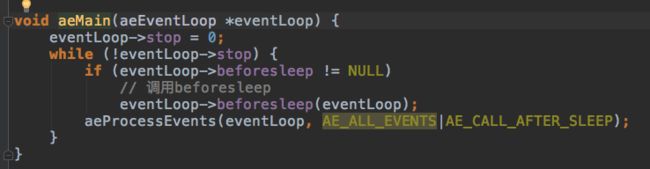
主循环的核心流程如下:
先计算多少毫秒之后要触发最早的定时任务,利用定时任务触发的间隙检查是否用io可用的fd,定时任务都在EventLoop的单链表里。如果没有定时任务要执行,直接阻塞直到有fd可用。
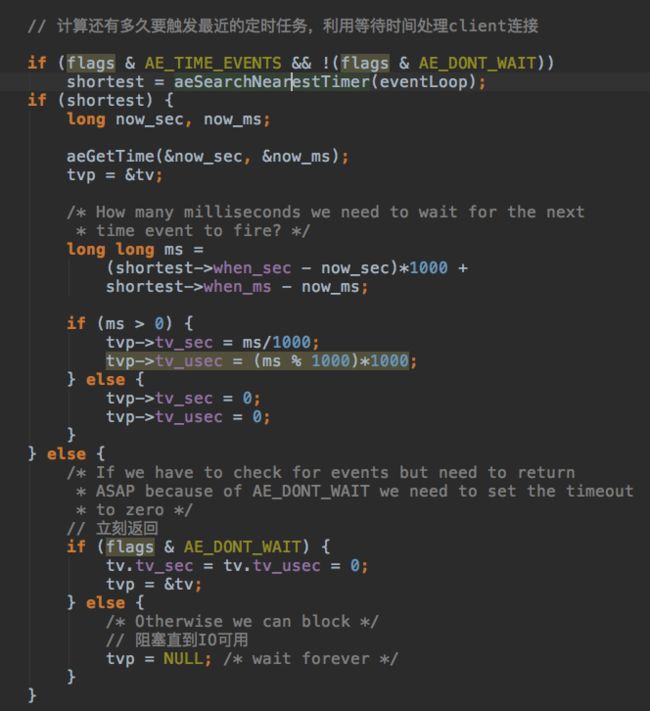
使用kqueue在指定时间段内检查可用的fd,调用关联的函数
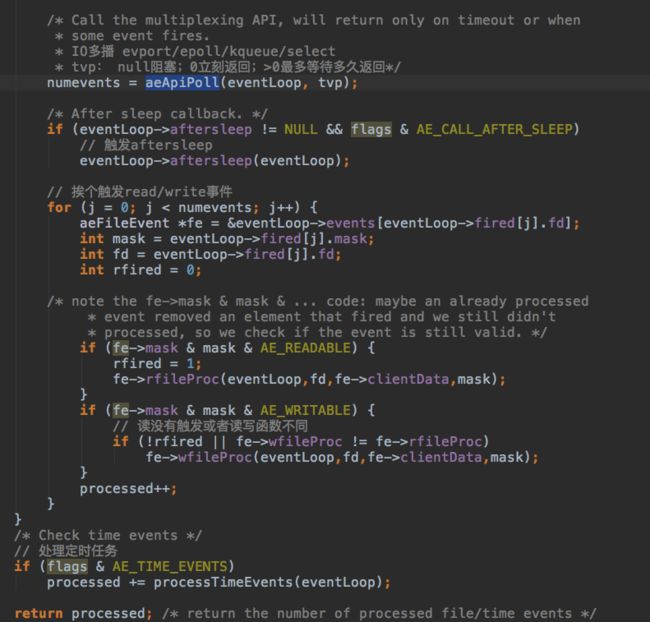
一共有三种情况:accept client连接;client请求可读,client可以接收响应。
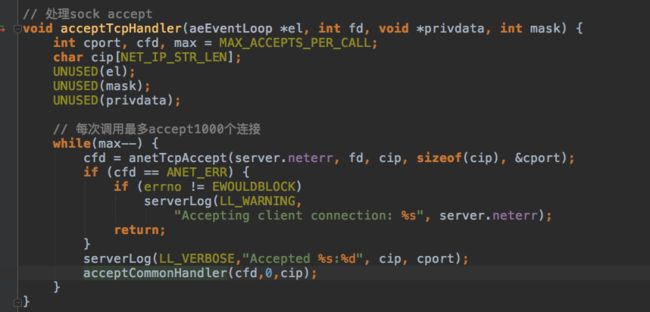
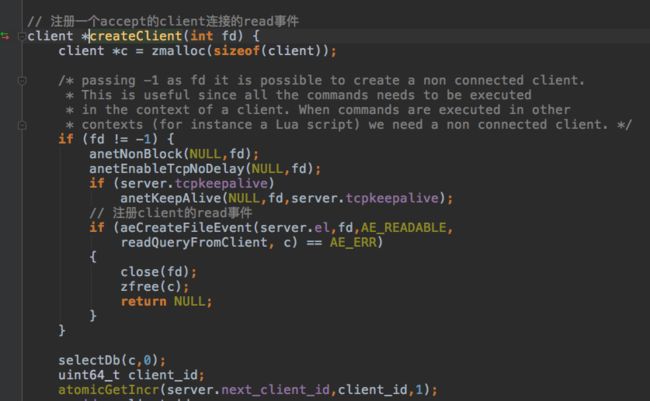
accept client是之前绑定到指定端口的server socket注册的,触发时会把收到的client连接注册到kqueue里。client结构体保存每个client相关的状态,所有的client都保存在server.clients的双链表里。
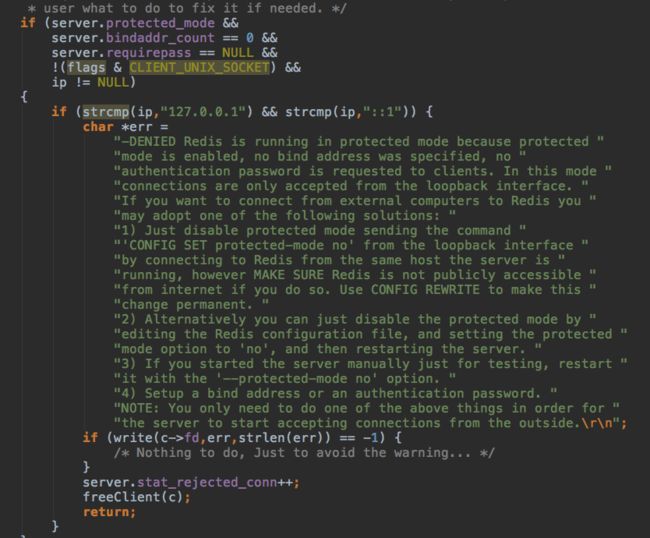
保护模式下,只有跟server ip相同的client才能连接。
client发送请求fd触发时:
先把请求缓存在client的querybuf里。
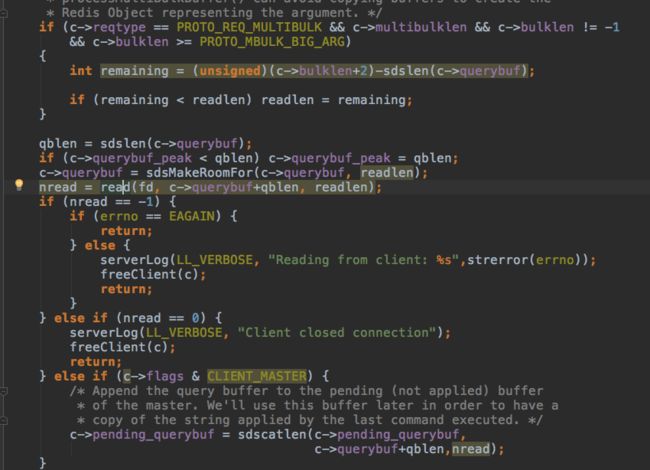
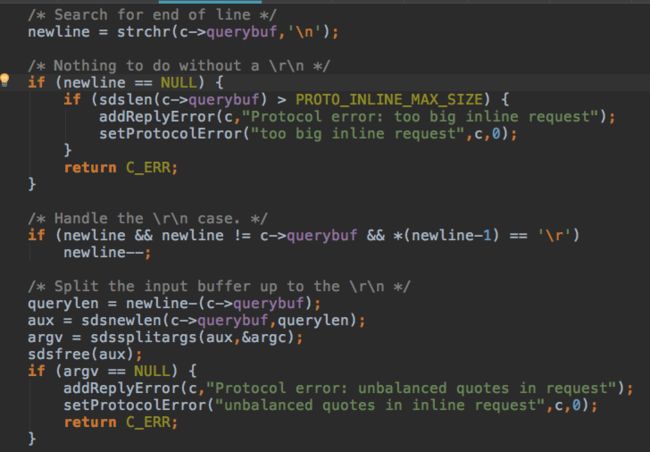
redis client协议:先按换行符拆分,每行是一个指令,每个指令再按空格拆分,保存到client里
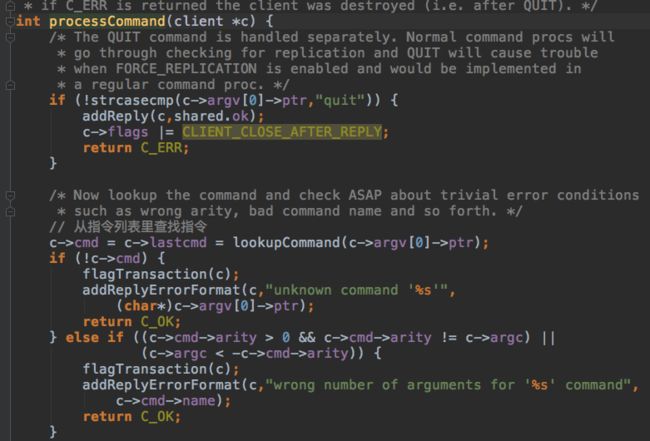
然后就是根据指令列表里每个指令关联的函数,执行指令。
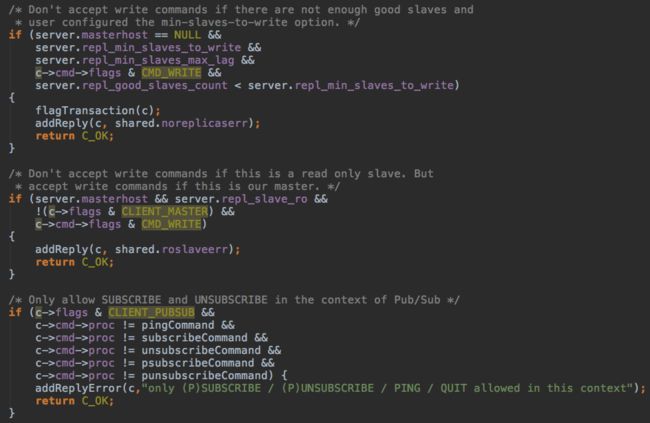
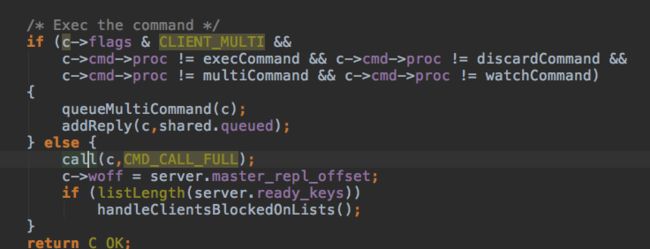
以简单的get key为例分析响应过程:
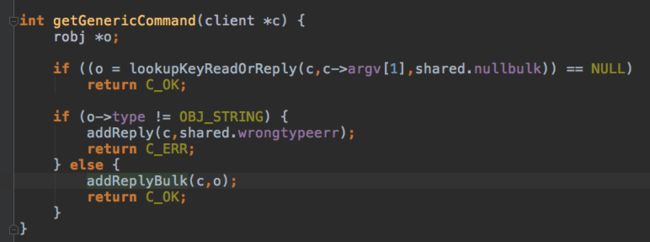
响应信息放入client的buf,放不下里放入replay链表.
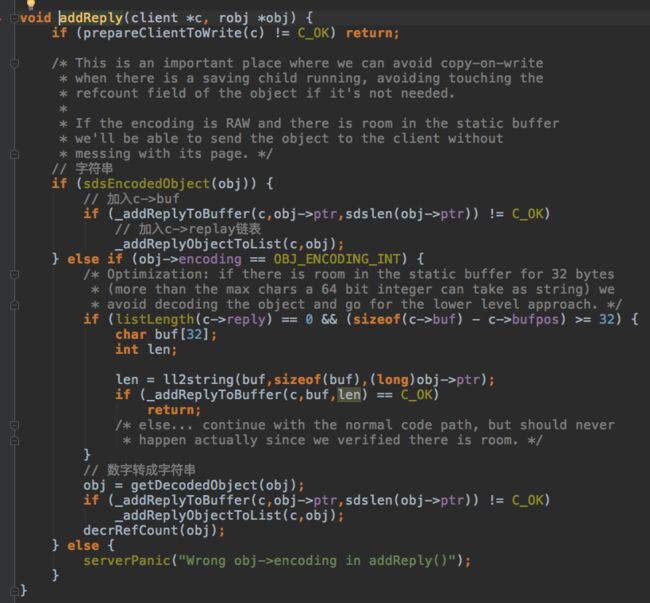
有响应信息要返回的client,加入server.clients_pending_write链表
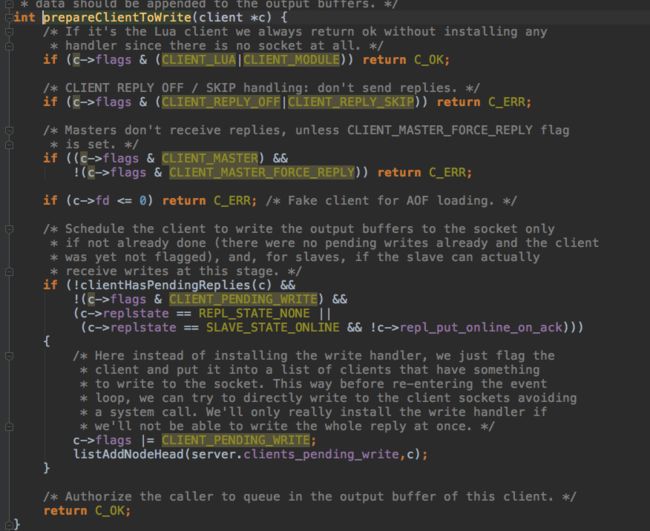
每次调用kqueue等待IO之前都会先调用beforeSleep,beforeSleep会检查上个循环有响应信息待处理的client,注册write事件。
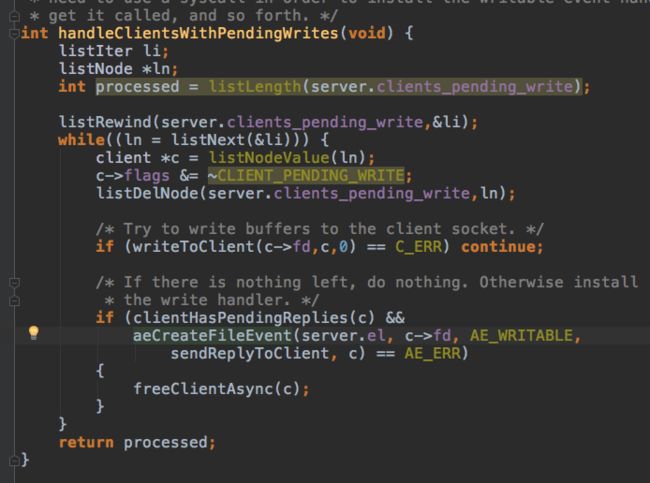
当本次事件循环,发现write可用时,
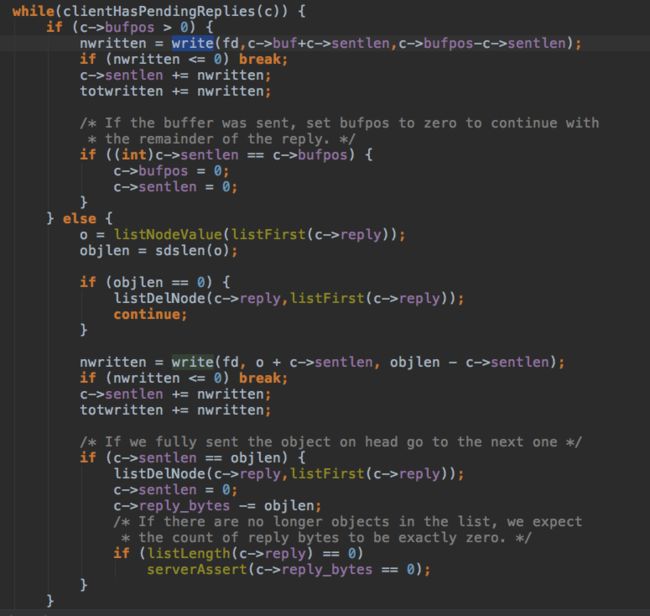
完整的指令处理过程结束了,可以发现目前只有一个线程,一个线程干了很多活,避免了多线程中线程切换和锁相关的开销,这也是另一个redis高性能的原因。
redis除了响应client请求外,还有很多其他的要做:最明显的就是缓存持久化,过期key清除等。这些任务都集中在server初始化时注册到EventLoop上的定时任务里。之前说过请求处理任务是在定时任务触发的间隙中处理的。
现在分析一下定时任务都干了啥:很简单,循环EventLoop上定时任务单链表,触发时间过期的任务,调用对应的定时任务函数,如果timeProc不返回-1,表示定时任务还需要触发,计算好下次触发时间,否则id设置为-1,等待下次从定时任务链表里删除。
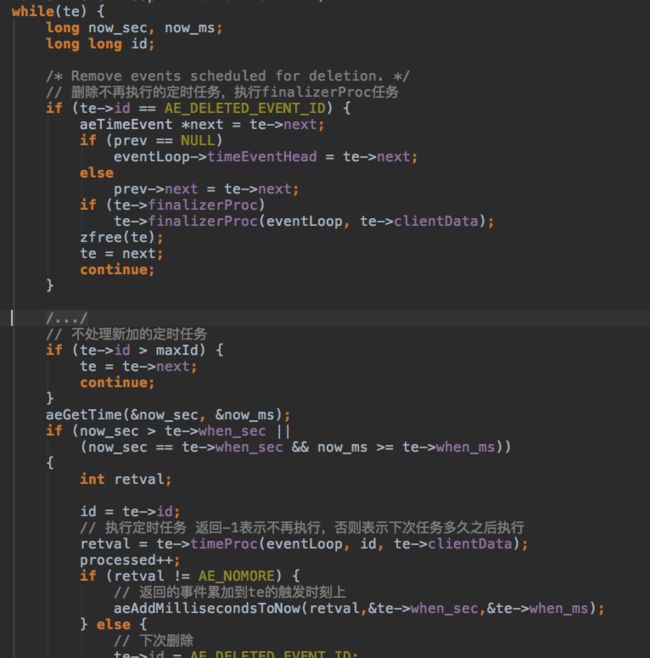
目前redis只有一个定时任务:serverCron,根据配置文件里server.hz的值,决定serverCron每秒执行 1000 / server.hz 个周期
serverCron的子任务如下:
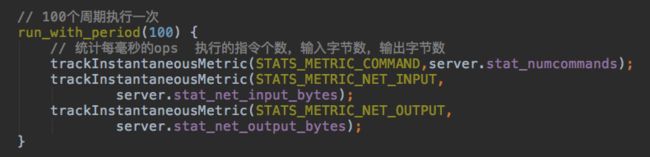
首先是100个周期执行一次的统计任务:
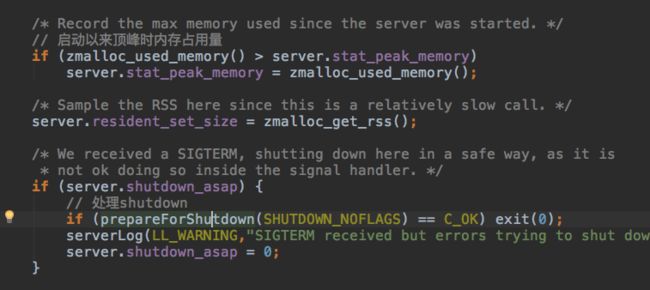
然后是记录内存占用的峰值,如果收到了shutdown指令,关闭子进程
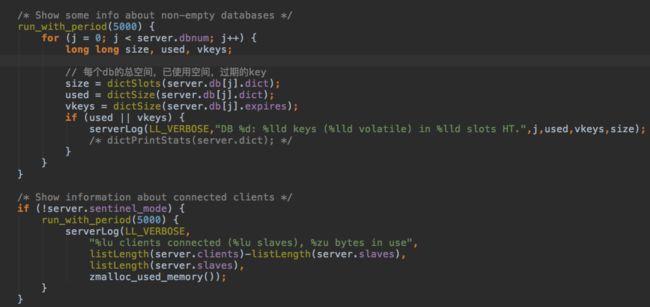
每5000个周期打印一次状态log
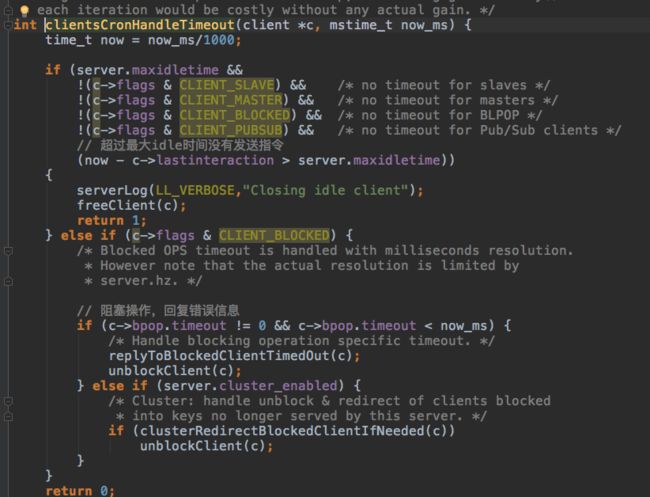
检查很久不发指令的client,关闭连接,检查阻塞在b开头的指令的client,阻塞指定时间后返回timeout错误信息。
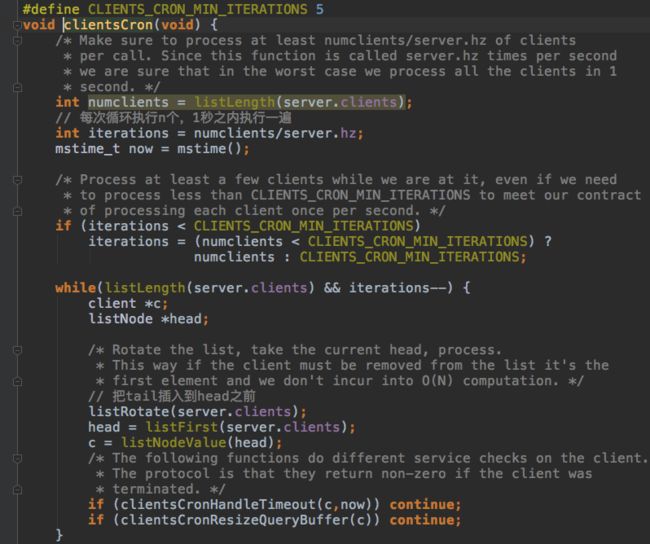
如果client太多,一次全部检查一遍很阻塞很长时间,所以分散压力,每次只执行一部分。一秒之内全部检查一遍,其实这个时间是非常不精确又无法保证的。
检查过期key,如果key很多,一个一个检查肯定会阻塞很久,所以每次都花定量的时间随机删除过期的key,如果多次随机都没有遇到过期key,密度很小,停止任务。
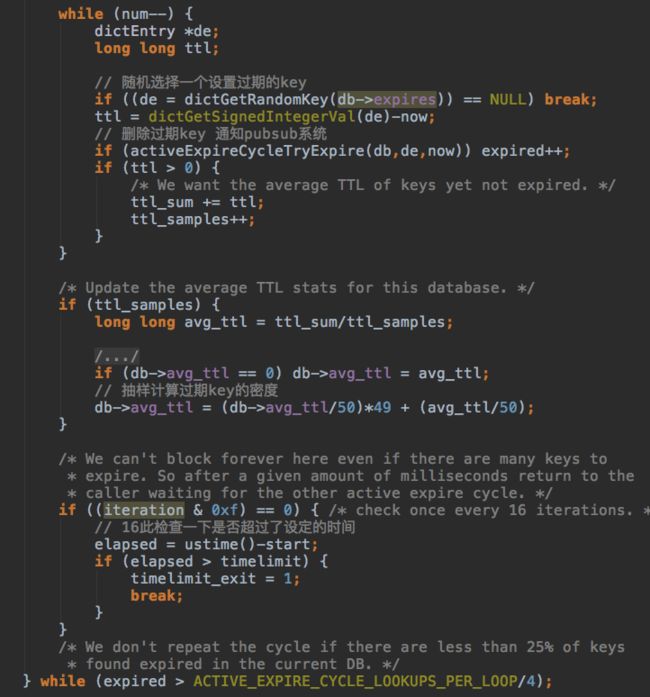
删除过期key竟然还有异步删除,原来是漏掉了一个地方:redis除了主线程,还有三个后台任务线程,用于处理各种异步操作。
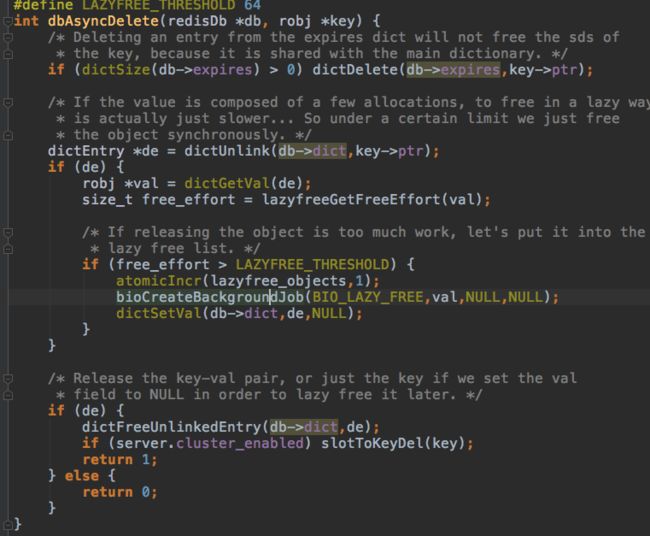
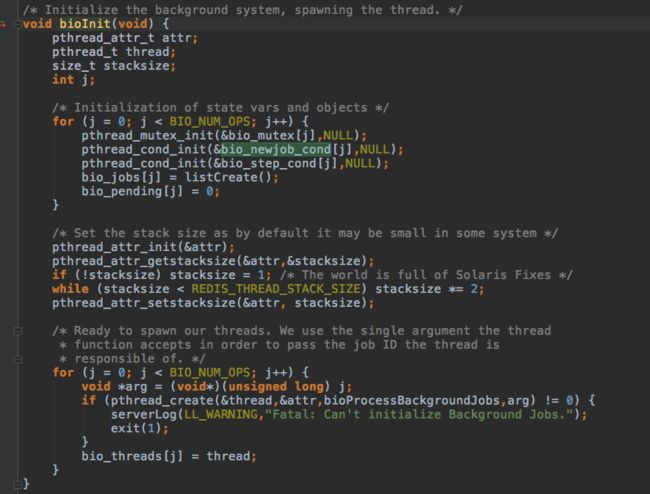
异步任务只有三种:异步关闭连接,异步同步aof,异步删除。

使用pthread创建线程,等待条件变量通知。
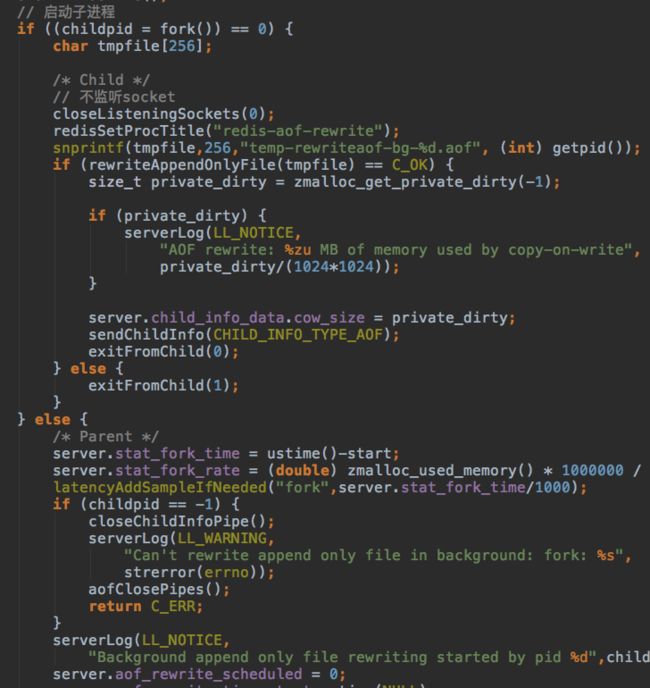
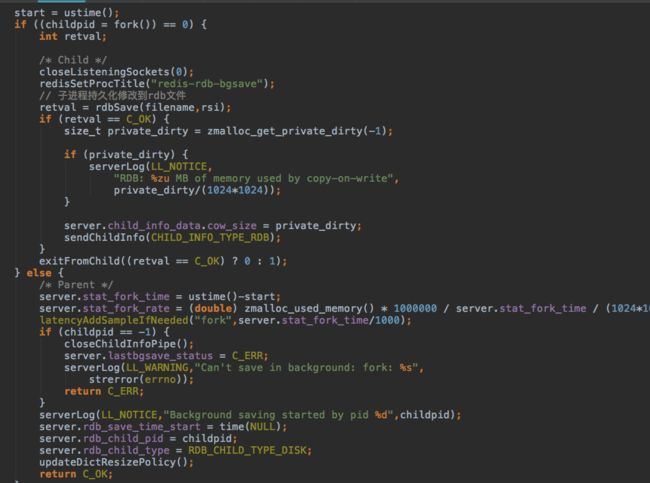
然后会fork两个子进程,分别用于处理aof和rdb持久化。
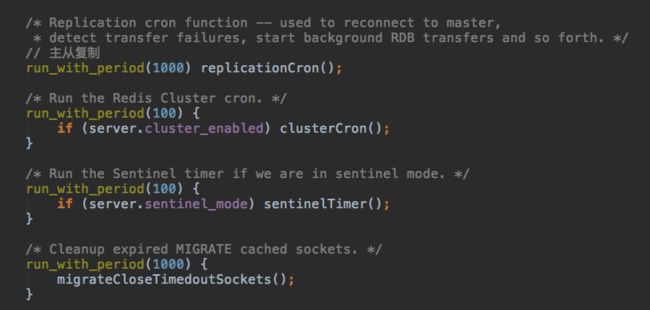
然后是一些跟集群和主从相关的任务,等待下回分解。
本节完!!!。