Deep learning:十五(Self-Taught Learning练习)
前言:
本次实验主要是练习soft- taught learning的实现。参考的资料为网页:http://deeplearning.stanford.edu/wiki/index.php/Exercise:Self-Taught_Learning。Soft-taught leaning是用的无监督学习来学习到特征提取的参数,然后用有监督学习来训练分类器。这里分别是用的sparse autoencoder和softmax regression。实验的数据依旧是手写数字数据库MNIST Dataset.
实验基础:
从前面的知识可以知道,sparse autoencoder的输出应该是和输入数据尺寸大小一样的,且很相近,那么我们训练出的sparse autoencoder模型该怎样提取出特征向量呢?其实输入样本经过sparse code提取出特征的表达式就是隐含层的输出了,首先来看看前面的经典sparse code模型,如下图所示:
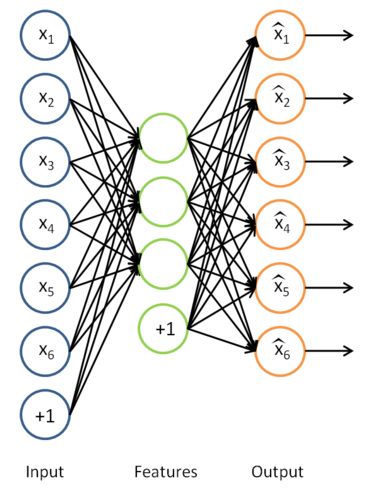
拿掉那个后面的输出层后,隐含层的值就是我们所需要的特征值了,如下图所示:
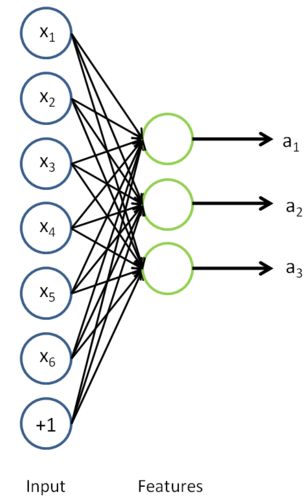
从教程中可知,在unsupervised learning中有两个观点需要特别注意,一个是self-taught learning,一个是semi-supervised learning。Self-taught learning是完全无监督的。教程中有举了个例子,很好的说明了这个问题,比如说我们需要设计一个系统来分类出轿车和摩托车。如果我们给出的训练样本图片是自然界中随便下载的(也就是说这些图片中可能有轿车和摩托车,有可能都没有,且大多数情况下是没有的),然后使用的是这些样本来特征模型的话,那么此时的方法就叫做self-taught learning。如果我们训练的样本图片都是轿车和摩托车的图片,只是我们不知道哪张图对应哪种车,也就是说没有标注,此时的方法不能叫做是严格的unsupervised feature,只能叫做是semi-supervised learning。
一些matlab函数:
numel:
比如说n = numel(A)表示返回矩阵A中元素的个数。
unique:
unique为找出向量中的非重复元素并进行排序后输出。
实验结果:
采用数字5~9的样本来进行无监督训练,采用的方法是sparse autoencoder,可以提取出这些数据的权值,权值转换成图片显示如下:

但是本次实验主要是进行0~4这5个数字的分类,虽然进行无监督训练用的是数字5~9的训练样本,这依然不会影响后面的结果。只是后面的分类器设计是用的softmax regression,所以是有监督的。最后据官网网页上的结果精度是98%,而直接用原始的像素点进行分类器的设计不仅效果要差(才96%),而且训练的速度也会变慢不少。
实验主要部分代码:
stlExercise.m:
%% CS294A/CS294W Self-taught Learning Exercise % Instructions % ------------ % % This file contains code that helps you get started on the % self-taught learning. You will need to complete code in feedForwardAutoencoder.m % You will also need to have implemented sparseAutoencoderCost.m and % softmaxCost.m from previous exercises. % %% ====================================================================== % STEP 0: Here we provide the relevant parameters values that will % allow your sparse autoencoder to get good filters; you do not need to % change the parameters below. inputSize = 28 * 28; numLabels = 5; hiddenSize = 200; sparsityParam = 0.1; % desired average activation of the hidden units. % (This was denoted by the Greek alphabet rho, which looks like a lower-case "p", % in the lecture notes). lambda = 3e-3; % weight decay parameter beta = 3; % weight of sparsity penalty term maxIter = 400; %% ====================================================================== % STEP 1: Load data from the MNIST database % % This loads our training and test data from the MNIST database files. % We have sorted the data for you in this so that you will not have to % change it. % Load MNIST database files mnistData = loadMNISTImages('train-images.idx3-ubyte'); mnistLabels = loadMNISTLabels('train-labels.idx1-ubyte'); % Set Unlabeled Set (All Images) % Simulate a Labeled and Unlabeled set labeledSet = find(mnistLabels >= 0 & mnistLabels <= 4); unlabeledSet = find(mnistLabels >= 5); %%增加的一行代码 unlabeledSet = unlabeledSet(1:end/3); numTest = round(numel(labeledSet)/2);%拿一半的样本来训练% numTrain = round(numel(labeledSet)/3); trainSet = labeledSet(1:numTrain); testSet = labeledSet(numTrain+1:2*numTrain); unlabeledData = mnistData(:, unlabeledSet);%%为什么这两句连在一起都要出错呢? % pack; trainData = mnistData(:, trainSet); trainLabels = mnistLabels(trainSet)' + 1; % Shift Labels to the Range 1-5 % mnistData2 = mnistData; testData = mnistData(:, testSet); testLabels = mnistLabels(testSet)' + 1; % Shift Labels to the Range 1-5 % Output Some Statistics fprintf('# examples in unlabeled set: %d\n', size(unlabeledData, 2)); fprintf('# examples in supervised training set: %d\n\n', size(trainData, 2)); fprintf('# examples in supervised testing set: %d\n\n', size(testData, 2)); %% ====================================================================== % STEP 2: Train the sparse autoencoder % This trains the sparse autoencoder on the unlabeled training % images. % Randomly initialize the parameters theta = initializeParameters(hiddenSize, inputSize); %% ----------------- YOUR CODE HERE ---------------------- % Find opttheta by running the sparse autoencoder on % unlabeledTrainingImages opttheta = theta; addpath minFunc/ options.Method = 'lbfgs'; options.maxIter = 400; options.display = 'on'; [opttheta, loss] = minFunc( @(p) sparseAutoencoderLoss(p, ... inputSize, hiddenSize, ... lambda, sparsityParam, ... beta, unlabeledData), ... theta, options); %% ----------------------------------------------------- % Visualize weights W1 = reshape(opttheta(1:hiddenSize * inputSize), hiddenSize, inputSize); display_network(W1'); %%====================================================================== %% STEP 3: Extract Features from the Supervised Dataset % % You need to complete the code in feedForwardAutoencoder.m so that the % following command will extract features from the data. trainFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ... trainData); testFeatures = feedForwardAutoencoder(opttheta, hiddenSize, inputSize, ... testData); %%====================================================================== %% STEP 4: Train the softmax classifier softmaxModel = struct; %% ----------------- YOUR CODE HERE ---------------------- % Use softmaxTrain.m from the previous exercise to train a multi-class % classifier. % Use lambda = 1e-4 for the weight regularization for softmax lambda = 1e-4; inputSize = hiddenSize; numClasses = numel(unique(trainLabels));%unique为找出向量中的非重复元素并进行排序 % You need to compute softmaxModel using softmaxTrain on trainFeatures and % trainLabels % You need to compute softmaxModel using softmaxTrain on trainFeatures and % trainLabels options.maxIter = 100; softmaxModel = softmaxTrain(inputSize, numClasses, lambda, ... trainFeatures, trainLabels, options); %% ----------------------------------------------------- %%====================================================================== %% STEP 5: Testing %% ----------------- YOUR CODE HERE ---------------------- % Compute Predictions on the test set (testFeatures) using softmaxPredict % and softmaxModel [pred] = softmaxPredict(softmaxModel, testFeatures); %% ----------------------------------------------------- % Classification Score fprintf('Test Accuracy: %f%%\n', 100*mean(pred(:) == testLabels(:))); % (note that we shift the labels by 1, so that digit 0 now corresponds to % label 1) % % Accuracy is the proportion of correctly classified images % The results for our implementation was: % % Accuracy: 98.3% % %
feedForwardAutoencoder.m:
function [activation] = feedForwardAutoencoder(theta, hiddenSize, visibleSize, data) % theta: trained weights from the autoencoder % visibleSize: the number of input units (probably 64) % hiddenSize: the number of hidden units (probably 25) % data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example. % We first convert theta to the (W1, W2, b1, b2) matrix/vector format, so that this % follows the notation convention of the lecture notes. W1 = reshape(theta(1:hiddenSize*visibleSize), hiddenSize, visibleSize); b1 = theta(2*hiddenSize*visibleSize+1:2*hiddenSize*visibleSize+hiddenSize); %% ---------- YOUR CODE HERE -------------------------------------- % Instructions: Compute the activation of the hidden layer for the Sparse Autoencoder. activation = sigmoid(W1*data+repmat(b1,[1,size(data,2)])); %------------------------------------------------------------------- end %------------------------------------------------------------------- % Here's an implementation of the sigmoid function, which you may find useful % in your computation of the costs and the gradients. This inputs a (row or % column) vector (say (z1, z2, z3)) and returns (f(z1), f(z2), f(z3)). function sigm = sigmoid(x) sigm = 1 ./ (1 + exp(-x)); end
参考资料:
http://deeplearning.stanford.edu/wiki/index.php/Exercise:Self-Taught_Learning