GPT模型
GPT全称Generative Pre-Training,出自2018年OpenAi发布的论文《Improving Language Understandingby Generative Pre-Training》,论文地址:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf。
在自然语言处理问题中,可从互联网上下载大量无标注数据,而针对具体问题的有标注数据却非常少,GPT是一种半监督学习方法,它致力于用大量无标注数据让模型学习“常识”,以缓解标注信息不足的问题。其具体方法是在针对有标签数据训练Fine-tune之前,用无标签数据预训练模型Pretrain,并保证两种训练具有同样的网络结构。
GPT底层也基于Transformer模型,与针对翻译任务的Transformer模型不同的是:它只使用了多个Deocder层。
下图展示了在不修改模型主体结构的情况下,如何使用模型适配多分类、文本蕴含、相似度、多项选择这几类问题。
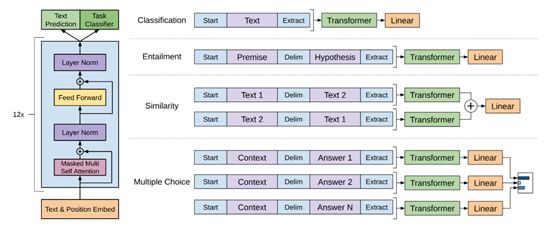
其左侧展示了12层的Transformer Decoder模型,与Transformer基础模型一致。右侧展示了在Fine-Tune时,先将不同任务通过数据组合,代入Transformer模型,然后在基础模型输出的数据后加全连接层(Linear)以适配标注数据的格式。
例如其中最简单的分类任务,如对于句子的感情色彩识别问题,只涉及单个句子,结果是二分类。因此,只需要代入句子,其在最后加一个全连接层即可;而判断相似度问题,由于两句之间没有相互关系,则需要将两句用加入定界符按不同前后顺序连接,分别输入模型,生成不同的隐藏层数据再代入最终的全连接层。
模型实现
在预训练Pretrain部分,用u表示每一个token(词),当设置窗口长度为k,预测句中的第i个词时,则使用第i个词之前的k个词,同时也根据超参数Θ,来预测第i个词最可能是什么。简言之,用前面的词预测后面的词。
具体方法是代入Transformer模型,下式中的模型由l组(组也可称为块block)隐藏层组成,最初输入隐藏层的数据是词编码U乘词嵌入参数We加上位置参数Wp;后面经过l个层(如上图左侧的Transformer组)处理。
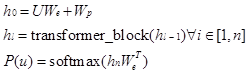
在有监督训练Fine-tune部分,比如判断句子感情色彩(二分类问题)的句子中包含m个词x1…xm,在pretain训练好的模型之加后再加一个全连接层,用于学习描述输入信息x与目标y关系的参数Wy,最终预测目标y。
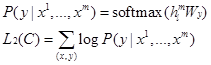
兼顾上式中的L1和L2,加入权重参数λ控制其比例计算出L3,作为优化的依据。
GPT与基本的Transformer相比,还进行了以下修改:
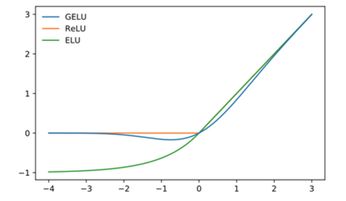
- 将GLUE(Gaussian Error Linear Unit)作为误差函数 GLUE可视为ReLU的改进方法,ReLU将小于1的数据转换成0,大于1的部分不变,而GELU对其稍做调整,如下图所示:
- 位置编码,基础Transformer使用正余弦函数构造位置信息,位置信息不需要训练相应的参数;而GPT将绝对位置信息作为编码。
模型效果
GPT基于Transformer修改,在一个8亿单词的语料库上训练,12个Decoder层,12个attention头,隐藏层维度为768。
GPT在自然语言推理、分类、问答、对比相似度的多种测评中均超越了之前的模型(具体的测试以及对比效果详见论文)。且从小数据集如STS-B(约5.7k训练数据实例)到大数据集(550k训练数据)都表现优异。甚至通过预训练,也能实现一些Zero-Shot任务。但由于无标签数据与具体问题的契合度低,因此,学起来更慢,需要的算力也更多。
GPT-2模型
GPT-2模型来自OpenAi的论文《Language Models are Unsupervised Multitask Learners》无监督的多任务学习语言模型,论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf。
尽管目前很多有监督学习NLP模型效果已经很好,但都需要有针对单个任务训练使用大量有标注数据训练,当目标的分布稍有变化则不能继续使用,因此只能在狭窄的领域中起作用。GPT-2希望通过海量数据和庞大的模型参数训练出一个类似百科全书的模型,无需标注数据也能解决具体问题。
GPT-2希望在完全不理解词的情况下建模,以便让模型可以处理任何编码的语言。GPT-2主要针对zero-shot问题。它在解决多种无监督问题时有很大提升,但是对于有监督学习则差一些。
无监督学习和有监督学习的效果对比,就像两个小孩子学习,一个博览群书,但看的不一定考;另一个专看考点,定点优化。结果就是一个在考试里面成绩更好,另一个能力更强,能解决各种问题,尤其适用于无确定答案的问题。它们在不同的领域各具特长。
目前翻译、问答、阅读理解、总结等以文字作答的领域都可使用GPT-2生成答案,其中最热门的是续写故事模型,其续写水平达到人类水平,具体使用方法是给出文章开头,让模型续写接下来的故事。由于无法控制接下来故事的内容,也有人将其称为造谣神器,从而引发了一些可能出现的道德问题,以致于在论文发表初期并没有发布效果最好的模型,以免被人滥用。这也提示人们:写作如果空话连篇言之无物,人还不如机器。
模型实现
GPT-2的结构类似于GPT模型(也称GPT-1.0),仍然使用单向的Transformer模型,只做了一些局部修改:如将归一化层移到Block的输入位置;在最后一个自注意力块之后加了一层归一化;增大词汇量等等。
与之前的实现方法最大的不同是:GPT-2的训练数据在数量、质量、广泛度上都有大幅度提高:抓取了大量不同类型的网页,并且经过筛选去重生成高质量的训练数据,同时训练出体量更巨大的模型。
在Pretrain部分基本与GPT方法相同,在Fine-tune部分把第二阶段的Fine-tuning有监督训练具体NLP任务,换成了无监督训练具体任务,这样使得预训练和Fine-tuning的结构完全一致。当问题的输入和输出均为文字时,只需要用特定方法组织不同类型的有标注数据即可代入模型,如对于问答使用“问题+答案+文档”的组织形式,对于翻译使用“英文+法文”形式。用前文预测后文,而非使用标注数据调整模型参数。这样既使用了统一的结构做训练,又可适配不同类型的任务。虽然学习速度较慢,但也能达到相对不错的效果。
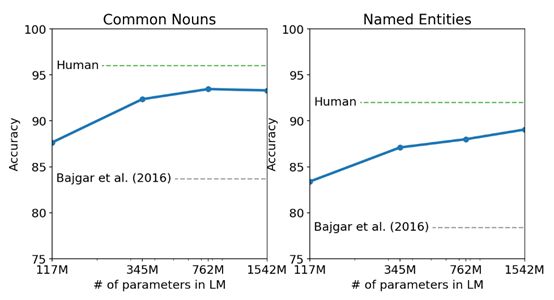
对于Zero-Shot问题,则需要考虑目标的风格以及分布情况,并实现一些训练集到测试集的映射(如处理特殊符号、缩写等),从而实现从已知领域到未知领域的迁移学习。GPT-2在Zero-Shot(尤其是小数据集Zero-Shot)以及长文本(长距离依赖)中都表现优异。下图为GPT-2在童书词性识别测试中的成绩:位于人类水平之下,但超过了之前模型的水平。
模型效果
GPT-2是一个在海量数据集上训练的基于 transformer 的巨大模型。它从网络上爬取800万网页40G的超大数据集「WebText」作为语言模型的训练数据,并训练了大小不同的多个模型。

最小的模型堆叠了 12 层与GPT正常模型大小一样,中号24 层与BERT大模型等大,大号36 层,特大号堆叠了 48 层仍能继续fit,特大号的模型被称为GPT-2,它有1600维隐藏层,参数规模达1.5G,还支持比之前更长的序列,和更长的batch_size。涵盖更多的知识,更大的存储空间。特大模型在32个TPU上也需要约一周时间才能训练完成。海量的训练数据,庞大的网络参数,昂贵的算力,模型优化逐渐变成了资本战争,使普通人在该方向已经很难超越。
代码
推荐Pytorch版本的https://github.com/huggingface/transformers,其中包括各种基于Transformer的模型实现,也包括GPT-2模型,代码共700多行。既可训练模型,也可使用现成模型。由于GPT与GPT-2逻辑变化不大,因此也可参考该代码学习GPT。
推荐GPT-2中文版本:https://github.com/Morizeyao/GPT2-Chinese,也由Pytorch工具开发,其核心基于上面介绍的GIT项目transformers,并在外层做了一些封装,主体是用于训练的train.py和用于生成文章的generate.py,程序都在200行左右,非常适合用来学习调用Transformer模型以及实现中文模型的方法,其README中列出了各个文件对应的具体功能。使用其核心代码开发的诗歌生成器地址:https://jiuge.thunlp.cn/lvshi.html,下面为藏头诗功能示例:
使用方法:
- 安装
$ git clone https://github.com/Morizeyao/GPT2-Chinese
安装requirements.txt中列出的支持工具,如:
$ pip install transformers==2.1.1
- 训练
创建data目录,将训练数据写入该目录中的train.json文件中。 $ mkdir data
$ mv train.json data/ # 根目录下有train.json示例文件
$ python train.py --raw # 开始训练train.py
如能正常运行,训练之后model目录下生成对应模型。
使用已有模型
训练模型用时较长,可下载现成模型。下载GPT2-Chinese git项目的README中展示的散文模型,它是使用130MB语料,Batch size 16,深度10层,训练10轮得到的散文模型,将下载的文件复制到model/final_model/目录中(默认模型位置)。生成文章
$ python ./generate.py --length=300 --nsamples=4 --prefix=秋日午后 --fast_pattern --save_samples --save_samples_path=/tmp/a
生成以“秋日午后”开头,长度为300个字符的散文,抓取其中一段如下:

解决具体问题
这里训练一个模仿小学生写作文的模型,具体步骤如下:
写程序从某作文网站抓取四年级作文1000篇,以每篇500字计算,数据约1M多。
数据清洗,去掉一些特殊字符。 * 在散文模型的基础上继续训练,命令形如:
$ python train.py --raw --batch_size=3 --pretrained_model=model/model_base/
- 使用第3轮训练的模型,生成以“秋日午后”为开头的300字作文
$ python ./generate.py --length=300 --nsamples=3 --prefix=秋日午后 --fast_pattern --save_samples --save_samples_path=/tmp/a/ --model_path=model/model_epoch3/

如果不使用预训练模型,只使用1000篇小学生作文训练3轮的模型几乎连不成句。这里将散文模型作为预训练模型Pretrain,用小学生作文Fine-tune,相对于独立的散文模型,内容中多了一些学校相关的内容,由于二次训练的数据太少和训练次数都较少,生成文章的效果不如之前的模型。
增加语料以及训练次数之后,模型将越发成熟:一开始的模型可能会重复一些常用字比如“我我的的”;然后逐渐形成通畅地表达;去掉重复以及相互矛盾的部分;掌握更高级表达技巧……以上的结果只使用了1M-130M语料训练,可以想见,当语料增加到几十G且使用更大模型时的效果。