RDF提供一种简单的方式表示分布式数据。三原子是表示另两个事物之间联系的最简单方法。但是如果没有某种读取数据 方法,数据表示也是无意义的。读取RDF数据的标准方法是使用查询语言SPARQL。代表 SPARQL Protocol And RDF Query Language。SPARQL查询语言与RDF本身的结构密切相关,SPARQL查询体系由不同的Turtle表示。查询的RDF图可以从一种数据创建,也可以从多种数据合并;无论哪种情况,SPARQL都是查询它的方法。
这一章列出了SPARQL查询语言的很多例子。大多数例子基于1.0版本,2008年发布。在写这本书的时候,新的版本正在开发中。高级示例将使用新标准(版本1.1)中的特性,并在每个部分的标题中显示为(SPARQL 1.1)。在没有此指示的部分中描述的特性在SPARQL 1.0和SPARQL 1.1中都可用。由于这一建议仍在进行中,最终版本可能会与这里给出的示例略有偏离。
SPARQL是一种查询语言,与XQUERY和SQL等其他查询语言共享许多特性。但是它与这些查询语言在重要方面有所不同(因为它们彼此不同)。由于我们不希望假定读者具有任何特定查询语言(甚至完全没有查询语言)的背景知识,所以我们先简单介绍一下查询数据。我们从最基本的信息检索系统开始,我们称之为“问答系统”。
Tell-and-Ask Systems(问答系统)
问答系统是一个简答的系统:你陈述一些事实,系统根据你提出的问题给出答案。看下面这个简单的例子。

就像我们看到的一样,实际上大多数的问答系统不要用自然语言处理做任何事情,在更复杂的问答系统中,对于你真正想问的问题,要非常具体是相当困难的,所以他们通常使用非常精确和技术性的语言。
从表面上看,问答系统似乎不是很有趣。他们不知道任何你没有告诉他们的事情。他们不做任何计算,不做任何分析。但这一判断还为时过早;即使是非常简单的问答系统也非常有用。让我们看一看—一个简单的通讯录。
你可能在生活中使用过通讯录。即使是纸笔通讯录也是一个“问答”系统,尽管告诉它一些事情的过程。(比如,写下一个地址)以及向它提出问题的过程(查找地址)需要很多人力。让我们想想代替一个计算机程序来做地址簿的工作。它是如何工作的?
就像一本纸质通讯录,你写下名字和地址(可能的电话号码,邮件地址和其他信息)。不像示例中的问答系统,我们习惯于告诉James Dean and movies,你可能不会用和英语一点都不像的语言和你的地址簿交谈;您可能要填写一个表单,其中一个字段用于名称,另一个字段用于地址的部分,等等。您可以通过填写表单来“告诉”它一个地址。你怎么来提问?如果你想知道某人的地址,你敲出来他的名字,可能用另外一种格式,很像你一开始填写的信息。一旦你输入了名字,你就得到了地址。
地址簿只会把你说的话告诉你,它不会计算,也不会得出结论。这怎么会是一个有趣的系统呢?即使没有计算能力,地址簿也是有用的系统。它们帮助我们组织对我们有用的特定类型的信息,并在我们需要的时候找到它。这是一个简单的问答系统——你告诉它事情,然后问问题。
甚至地址簿也比最简单的问答系统要先进一些。当你在地址簿中查找一个地址时,你通常会得到比地址多得多的信息。就好像你问了一大堆问题:
Ask: What is the address of Maggie Smith?
Ask: What is the phone number of Maggie Smith?
Ask: What is the email address of Maggie Smith?
怎样才能让我们的通讯录系统变得更有用?有一系列的方法可以加强他的表现。其中一种方法让通讯录更智能,就是对提问的用户要求更少。比如,找Maggie Smith的地址,系统可能会让你只是输入“Maggie,系统会寻找名字里包含“Maggie的人的地址。
Ask: What is the address of everyone whose name includes “Maggie”?
你这样做可能会得到更多的答案,比如,你还有一个 Maggie King的地址,即将会得到这两个地址。
你也可以做的更多,你可以根据其他一些信息来提问,你可以问地址而不是名字,通过在地址字段中填写信息:
Ask: Who lives at an address that contains “Downing”?
Common tell-and-ask infrastructure—spreadsheets(普通的问答基础-电子表格)
地址簿是一个特殊用途的问答系统的例子,他用于单一任务,对信息有一个固定的结构你可以告诉它并询问它。电子表格是一个可高度配置的问答系统的例子,可以应用于许多情况,电子表格经常被称为有史以来最成功的“杀手级应用程序”,把数据管理交到有智慧的人手中,而不需要学习任何繁重的技术技能。电子表格将所见即所得的概念应用于数据管理;数据的可视化表示。
用于向电子表格告知信息和询问电子表格信息的“语言”是可视化的;信息输入到特定的行和列中,并通过可视地检查表来检索。
由于电子表格主要是数据的可视化表示,所以您不需要使用任何特定的语言与它们通信——更不用说自然语言了。你不会写“玛吉住在哪里?”“电子表格;相反,您在“Name”列中搜索Maggie,然后查看“address”列来回答您的问题。
如果数据不能方便地用一个表表示,电子表格就会变得更麻烦。不适合放入表中的数据的最简单示例可能是多个值。假设我们有不止一个Maggie Smith的电子邮件地址。我们如何处理这个问题?我们可以有多个电子邮件列,像这样:



只要没有人有三个电子邮件地址,这个解决方案就可以工作。另一个解决方案是为Maggie的每个电子邮件地址创建一个新行,这有点令人困惑,因为我们不清楚是有一个名为“Maggie Smith”的联系人同时拥有两封电子邮件,还是有两个恰好同名的联系人,每个联系人都有一个电子邮件地址。
当应用程序需要高度互连的数据时,电子表格也开始崩溃。考虑一个联系人列表,其中保存了人员及其工作公司的名称。然后他们为公司维护独立的信息——帐单信息、合同官员等。如果将该信息放入单个表中,则该公司与其信息之间的关系将为在该公司工作的每个联系人复制,如下表所示:
两个Maggies都在ACME工作,ACME的合同工是Cynthia,总部位于匹兹堡。以这种方式复制信息既容易出错又浪费资源;例如,如果ACME获得了一个新的契约官员,那么需要更改为ACME工作的人员的所有联系人记录。

这种解决方案在现代电子表格软件中是可行的,但开始削弱电子表格的主要优势;我们不能再用可视化来回答问题。它的结构依赖于通过检查电子表格不容易看到的交叉引用。事实上,这种解决方案将问答系统从电子表格转移到更结构化的问答系统(关系数据库)。
Advanced tell-and-ask infrastructure—relational database(高级的问答基础-关系数据库)
关系数据库是大多数大规模问答系统的基础。它们与电子表格共享数据的表格表示,但包括一个强大的正式系统(基于一种称为“关系代数”的数学形式),该系统提供了一种将表链接在一起的系统方法。这个工具,加上一些定义良好的方法支持,允许关系数据库表示高度结构化的数据,并响应非常详细的结构化问题。

这种详细的结构是有代价的——提问变成了一个非常详细的过程,需要专门的语言。这种语言称为查询语言。
在关系数据库的查询语言中,从一个表到另一个表的链接是通过交叉引用上面问题的更接近的呈现来完成的,在关系数据库的查询语言中是:
Ask: What is the email address for the person matched by the “contract officer” reference for the company matched by the “works for” reference for the person whose name is “Maggie King”?
Answer: [email protected]
这似乎是一种不必要的冗长的提问方式,但这是您提出问题的方式,足以从复杂的数据库结构中恢复信息。
RDF as a Tell-and-Ask System
RDF可以表示复杂的结构化数据,也是一个问答系统,RDF需要一种精确的查询语言来指定问题。与关系数据库不同,交叉引用对最终用户不可见,并且不需要在查询语言中显式地表示它们,如前几章所讨论的,在RDF中,关系表示为三元组。断言三元组相当于告诉三元组存储一个事实。
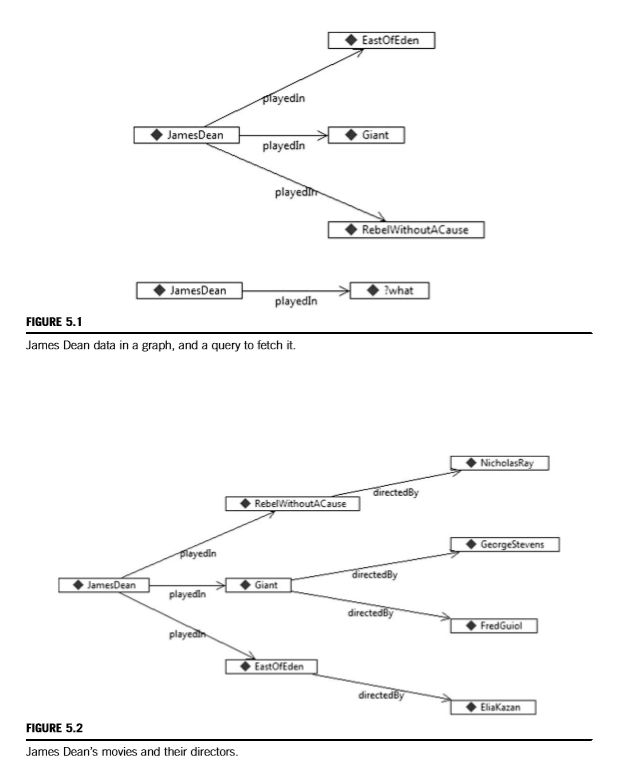
Tell: James Dean played in the movie Giant.
我们可以怎样问呢?即使只用简单的三元组,我们也有很多问题可以问:
Ask: What did James Dean play in?
Ask: Who played in Giant?
Ask: What did James Dean do in Giant?
这些问题SPARQL都能用简单的方式提问, 用疑问词代替三元组的一部分,比如谁,什么,哪里等等。SPARQL实际上并不区分疑问词,所以我们可以选择在英语中有意义的词。在SPARQL中,疑问词开头有个问号。
Ask: James Dean played in ?what
Answer: Giant
Ask: ?who played in Giant
Answer: James Dean
Ask: James Dean ?what Giant
Answer: played in
这是SPARQL背后的基本思想——你可以写一个看起来很像数据的问题,用一个疑问词代替你想知道的东西。像电子表格和关系数据库中的查询语言一样,SPARQL没有试图模仿自然语言的语法,但是它确实使用了这样的思想,即一个问题可以看起来像一个语句,但是要用一个疑问词来表示我们想知道的内容。
SPARQL—Query Language for RDF
SPARQL的语法和Turtle很像。
Tell: :JamesDean :playedIn :Giant .
Ask: :JamesDean :playedIn ?what .
Answer: :Giant Ask: ?who :playedIn :Giant .
Answer::JamesDean
Ask: :JamesDean ?
what :Giant . Answer: :playedIn
看一下SPARQL查询的语法,先看select查询。熟悉SQL的读者可能会注意到两种查询语言有些地方一样,select和where。这不是巧合,SPARQL在设计的时候就考虑到要让SQL用户容易学习
一个SPARQL SELECT查询包含两部分,一组疑问词,和一个提问句型,关键词WHERE显示这是一个疑问句,写在大括号里,我们来看几个疑问句,
WHERE {:JamesDean :playedIn ?what .}
WHERE {?who :playedIn :Giant .}
WHERE {:JamesDean ?what :Giant .}
查询以单词SELECT开始,然后是问题单词列表。所以对上面问题的查询是:
SELECT ?what WHERE {:JamesDean ?playedIn ?what .}
SELECT ?who WHERE {?who :playedIn :Giant .}
SELECT ?what WHERE {:JamesDean ?what :Giant .}
在SELECT部分中列出疑问词似乎是多余的——毕竟,它们已经出现在疑问句中了。在某种程度上,这是正确的,但是我们稍后将看到如何修改这个列表是有用的。
RDF(和SPARQL)可以很好地处理多重值。如果我们告诉系统James Dean在多部电影中扮演的角色,我们就可以做到这一点,而不需要在表示中做任何考虑:
Tell::JamesDean :playedIn :Giant .
Tell::JamesDean :playedIn :EastOfEden .
Tell::JamesDean :playedIn :RebelWithoutaCause .
如果我们用SPARQL提问:
Ask: SELECT ?what WHERE {:JamesDean :playedIn ?what}
Answer: :Giant, :EastOfEden, :RebelWithoutaCause.
SPARQL查询的WHERE子句可以看作是一个图形模式,也就是说,与数据图匹配的模式。在本例中,模式只有一个三元组:JamesDean作为主语,:playedIn作为谓语,一个疑问词作为宾语。查询引擎的作用是查找数据中模式的所有匹配项,并返回问题单词匹配的所有值。

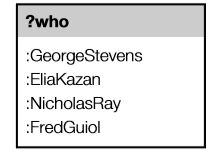
由于变量?what 在两个三元组中都出现了,图模式就会将这个点连接,我们可以用作图的方法来画图形。如图5.3,模式中有两个三元组,图表中也有两个三元组。这个图模式有两个疑问词,所以查询引擎会为模式找到所有的匹配,两个疑问词都可以自由匹配任何资源。这导致了几个匹配:
?what=:Giant ?who=:GeorgeStevens
?what=:Giant ?who=:FredGuiol
?what=:EastOfEden ?who=:EliaKazan
?what=:RebelWithoutaCause ?who=:NicholasRay
如果我们有更多的疑问词,实际上我们可能只能对其中一个感兴趣。这种情况下,我们可以询问James Dean曾与哪些导演共事,他演的电影只是达到这个目的的一种手段。这就是SELECT子句的细节所在——我们可以指定我们感兴趣的问题单词。因此,查找James Dean的导演的完整查询如下:

因为SPARQL中的一个查询可以有多个疑问词和多个答案,所以用表格来显示很方便,一列对应一个疑问词,一行对应一个答案。
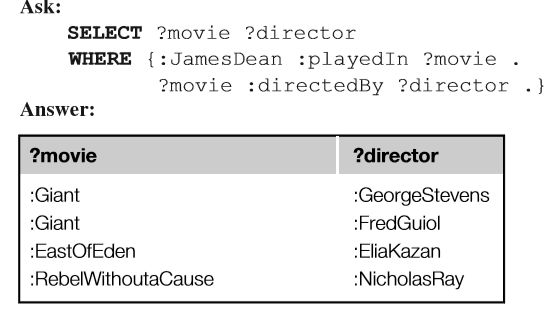
如果我们想在一个select语句中有多个疑问词,就可以给表格增加更多的列。比如:

Naming question words in SPARQL
英语中有少量的疑问词,who,what,where等。用别的词就没有疑问的意思。但是在SPARQL中,疑问词是那些只要用?开头的,任何其他词语都可以。我们来看上面的输出表格,疑问词?who和?what在描述正在进行的事情时并不是很有用,如果我们记住这个问题,我们就知道它的意思了。什么是电影?谁是导演?但是我们可以通过选择描述性的问题词,使表格更容易理解,即使是在问题的上下文中。在SPARQL中,习惯上是这样做的,将疑问词的意图传达给可能想要阅读查询的人。例如,我们可以将这个查询写成
我们现在看到的图模式是一个简单的链,James Dean演过的被某个人导演的电影。SPARQL中的图模式可以像它们匹配的图形一样精细。举个例子,如果你对詹姆斯·迪恩的电影有更全面的了解,我们可以用图表模式找到和他合作过的女演员:


记住?actress是一个像?who一样的疑问词,这样写更具可读性;唯一的原因?actress不匹配:RockHudson 是因为数据不支持匹配。也就是说,?actress的含义并不是由它的名字给出的,而是由图形模式的结构给出的。
有人可能有疑问,?movie 怎么就能确定指的是movie?在这个例子中,James只演了电影,所以这不是个问题。但是在语义网中,我们可以会有很多关于James演的信息,所以我们是不是应该对疑问词的值进行一些限制?让movie的值是movie类的一个成员,我们可以给模式再加一个三元组:

这个三元组刚开始看起来有点疑惑,怎么会有两个movie这个词语,这是什么意思?但是现在我们知道了,?movie只是一个疑问词的名字,为了能够在表格中很好的现实,我们可以看到,这个三元组是我们告诉SPARQL我们?movie真正的意思是什么。真正的意义不在名字里,所以我们得把他放在三元组里。
你有时候会遇到这种情况:一个模型的属性名字,和他要指向的类实体的名字一样,在这个例子中,我们没有使用属性:directedBy模型,可以简单地称之为:director。在这种情况下,查找詹姆斯·迪恩电影导演的查询如下:

这看起来有点难, ?director and :director?有什么区别?像我们之前看到的一样, :director代表了特殊的资源(使用默认的命名空间)。另一方面, ?director是一个疑问词,-也可以是?foo或?bar,但我们选择了?director来提醒我们它与电影导演的联系,当我们在查询的上下文中看到它时。如果你必须写一个模型的查询,就这样命名它的属性即可,不必恐慌。只要记住?代表了疑问词,?director只是让你知道 ?director预计的意思。如果你要建立自己的模型,我们建议你使用:directedBy这样的属性名,而不是:director,这样使用你的模型来查询数据的人就不会有这种困惑了。
Query structure vs. data structure

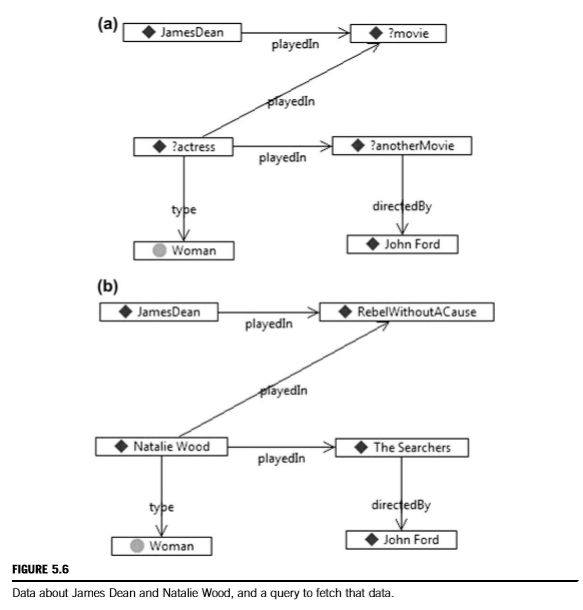
图5.6以图的方式显示了这个查询。在查询的文字描述中我们可以看到,同样的疑问词出现在了多个三元组中,并且它们中的一些也指向了同样的事物(?movie, ?anotherMovie)。在图显示中,我们可以看到两个三元组中的这些点必须指向同一个地方。比如,我们知道 James Dean和?actress共同出演了电影,因为两个三元组都使用了同样的疑问词(?movie)。类似的, ?actress 也是?anotherMovie里表演的演员,因为同样的疑问词?actress 在哪两个三元组中都出现了。所有的这些联系都可以在图5.6中看清楚,我们可以看到?movie是 James Dean and ?actress之间的联系, ?actress是?movie and ?anotherMovie之间的联系,?anotherMovie是 ?actress and John Ford之间的联系。
我们来看一下所有支持答案“Natalie Wood的信息,我们可以看到数据图和图模式看起来很像,这不用惊讶,因为这就是模式的原理。但是我们可以使用这种特点作为写查询的优势,写图5.6这样复杂的查询时,通过我们想回答的问题,写下三元组,直到得到所有的查询。但是还有另外一种方法从数据入手。假设我们有一个例子,关于我们想要查找的东西,比如,我们知道 Natalie Wood出演了The Searchers,John Ford导演。下一步,我们展示了如何使用图和模式之间的紧密匹配从示例构建模式。
由于数据图中的示例与图模式triple for triple匹配,所以我们已经了解了很多关于要创建的图模式的信息。我们需要指定的惟一一件事是,希望将示例中的哪些值保留为模式中的文字值,以及希望用疑问词替换哪些值。在图5.7(a)中,某些资源(James Dean、John Ford和Woman)上的框x表示将保持原样,其他的资源将会被疑问词替换。我们必须决定该用哪个疑问词。记住迄今为止我们关注的是SPARQL查询引擎,疑问词的名字并不重要。所以我们可以随便叫它们什么,只要我们确保当我们需要在答案中使用相同的值时使用相同的疑问词。在这个例子中,我们叫它们?q1,?q2,等等。图5.7(b)以图形方式显示了查询模式。


为了实现查询,简单的实用Select疑问词,或者你可以给另外一个有意义的名字。这让我们回到了与原始查询非常相似的查询(只在未选择的问题单词的名称上有所不同),但这一次,它是由数据中的模式生成的。


这个查询比之前少一个三元组,如果我们运行这个查询会发生什么呢?我们会得到另外一个结果,Raymond Massey。在这种情况下,将这个问题单词命名为?actor可能会产生误导(但是从SPARQL查询语言的角度来看,这样做非常好)——我们可能想将它改为?actor(按照约定,女性也可以成为演员;如果我们不喜欢这种约定,我们可能只保留无意义的名称q3)。
所以当我们说我们想要匹配娜塔莉·伍德(Natalie Wood)的例子“更像这样”时,在第一个例子中,我们指的是“在某些电影中与詹姆斯·迪恩(James Dean)合作过的女性,以及在约翰·福特(John Ford)执导的电影中饰演过的女性”。在第二种情况下,我们只是要求“在某部电影中与詹姆斯迪恩(James Dean)合作过的人,以及在约翰福特(John Ford)执导的一部电影中合作过的人”。“我们是如何区分的呢?”通过包括(或排除)认定娜塔莉·伍德是女性的三分之一。当我们把它包括在内时,“更像这样”包括了这样一个事实:结果一定是一个女人。当我们排除它时,“更像这样”并不包括这一规定。
Ordering of triples in SPARQL queries


这个查询的结果一样,和前一个查询匹配相同的三元组。但是在这个查询中,这个查询中的第一个三元组将匹配所有人在其中出演的?q3和?q1的值对。如果有N个人和N部电影,这就是N*M 对。第二个三元组使大量这些变量失效,因为对于其中许多变量,?q1不匹配(即,詹姆斯·迪恩(James Dean)没有在那部电影中出演)。但是查询引擎必须记住NxM中间结果——这一差异可能会在查询的执行时间上造成很大的差异。即使詹姆斯·迪恩(James Dean)出演过更多的电影,这个数字也很可能远低于m。这就为在查询中排序三元组提供了一个简单的启发: