1 背景

服务调用层级很多,如何快速定位故障,处理异常。
某个用户报响应很慢,怎么排查?
某笔业务交易出现异常,怎么分析?
怎么防止推诿扯皮,互相甩锅?
2 理论依据--Google Dapper
http://bigbully.github.io/Dapper-translation/
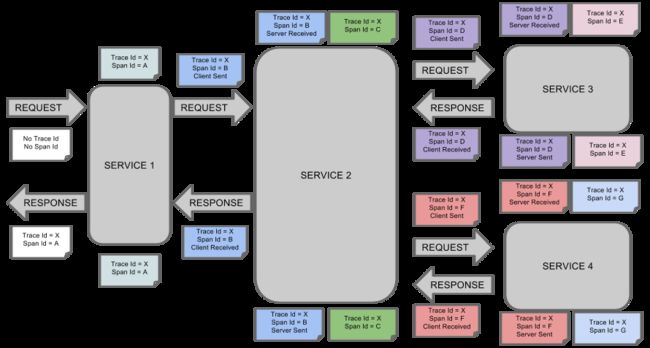
方案基本思路是在服务调用的请求、响应中加入跟踪ID--traceid,traceid用于唯一标识一次链路调用。怎么实现的呢?逻辑很简单,参与者实现在httpheader中加入traceid信息,通过httpheader传输,如果存在则沿用发起者的traceid,否则新建。
标识服务调用上下游关系,通过代表自身节点id的--spanid,代表父节点的parentid。从而将整个链路串联起来。
可集合的信息包括:traceid,spanid,url,httpcode,exception等,用户还可以自定义字段。
对于调用端来说:发出请求的时间戳,收到信息的时间戳;
对于服务端来说:收到请求的时间戳、处理完响应时间戳。
贴一张链路跟踪处理流程图:
3 实现方案
现成的方案:pinpoint、zipkin、阿里鹰眼、大众CAT
各个方案的优缺点:
pinpoint 字节码注入,对代码完全无侵入,在部署的时候java -jar pinpoint。缺点是生态不大好,个性化较弱,只支持java
zipkin:代码侵入较低,侵入到:配置文件、拦截器。生态好,多语言客户端,个性化较强
阿里鹰眼:牛逼但闭源,高级功能较多,没啥好讲的。人傻钱多速来买
cat:侵入性最强,不建议使用。
综上所述,选zipkin。
官方github:https://github.com/openzipkin/zipkin
3.1 架构图

reporter:zipkin客户端,没有实现reporter的应用当然推不了链路监控数据了。
transport:http 、kafka,生产环境用kafka,异步解耦高性能
collector:zipkin-server后台任务,接收处理链路监控数据
storage:内存、Cassandra、ES、mysql,推荐用ES
api&ui:ui查询分析工具
可用于生产环境的架构: brave + kafka + zipkin server +es
理由 为何不选spring cloud sleuth,有点厌恶过渡封装,出了问题难以排查,对于生产环境并不是足够稳定。brave足够简单直接,个性化定制能力很强。
为何不用http来传输span跟踪信息?做监控,应当尽量不影响正常的业务代码运行,监控代码不要与业务代码耦合在一起,为什么呢?保证可读性,将来迁移改造很便利,保证业务代码是独立纯粹的,同理不能与常见的日志,异常,参数检验等耦合。
kafka的有点,异步高并发高性能解耦。
为何选es,而不是MySQL或者cassandra.日志采集量大,一天上亿条轻轻松松,一定要具备大容量,便于做日志聚合分析,es绝对首选。而且我们的技术栈也是采用了elk搭建日志体系。便于与业务日志聚合。
4 zipkin客户端:Brave
数据推送方式:HTTP KAFKA scribe
TraceContext中有以下一些属性
traceIdHigh - 唯一标识trace的16字节id,即128-bit
traceId - 唯一标识trace的8字节id
parentId - 父级Span的spanId
spanId - 在某个trace中唯一标识span的8字节id
shared - 如果为true,则表明需要从其他tracer上共享span信息
extra - 在某个trace中相关的额外数据集

4 与springboot集成
详细代码参考:https://github.com/wuzuquan/microservice
4.1引入jar包
io.zipkin.brave
brave-context-slf4j
4.9.1
zipkin
io.zipkin.java
io.zipkin.reporter2
zipkin-sender-kafka11
2.7.3
io.zipkin.brave
brave-instrumentation-okhttp3
4.9.1
io.zipkin.brave
brave-instrumentation-spring-webmvc
4.9.1
4.2初始化zipkin 客户端配置
初始化一个kafkasender,对httptracing做一些个性化配置
@Autowired
private ZipkinProperties zipkinProperties;
@Bean
KafkaSender sender() {
Map pro = new HashMap<>();
pro.put("acks", "1");
// pro.put("linger.ms","50");
pro.put("retries", "1");
// pro.put("compression.type","gzip");
// pro.put("producer.type","async");
return KafkaSender.newBuilder().overrides(pro)
.bootstrapServers(zipkinProperties.getKafkaHosts())
.topic(zipkinProperties.getTopic())
.encoding(Encoding.PROTO3)
.build();
}
@Bean
AsyncReporter spanReporter() {
return AsyncReporter.builder(sender())
.closeTimeout(500, TimeUnit.MILLISECONDS)
.messageMaxBytes(200000)
.queuedMaxSpans(500)
.build();
}
@Bean
Tracing tracing() {
return Tracing.newBuilder()
.localServiceName(zipkinProperties.getServiceName())
.sampler(Sampler.ALWAYS_SAMPLE)
.propagationFactory(ExtraFieldPropagation.newFactory(B3Propagation.FACTORY, "user-name"))
.currentTraceContext(MDCCurrentTraceContext.create()) // puts trace IDs into logs
.spanReporter(spanReporter()).build();
}
@Bean
HttpTracing httpTracing(Tracing tracing) {
return HttpTracing.newBuilder(tracing)
.clientParser(new HttpClientParser() {
@Override
protected String spanName(HttpAdapter adapter, Req req) {
return adapter.url(req).toString();
}
@Override
public void request(HttpAdapter adapter, Req req, SpanCustomizer customizer) {
customizer.name(spanName(adapter, req)); // default span name
customizer.tag("url", adapter.url(req)); // the whole url, not just the path
super.request(adapter, req, customizer);
}
})
.serverParser(new HttpServerParser() {
@Override
protected String spanName(HttpAdapter adapter, Req req) {
return adapter.url(req).toString();
}
@Override
public void request(HttpAdapter adapter, Req req, SpanCustomizer customizer) {
customizer.name(spanName(adapter, req)); // default span name
customizer.tag("url", adapter.url(req)); // the whole url, not just the path
super.request(adapter, req, customizer);
}
})
.build();
}
初始化完后在webconfig中配置tracing拦截器,当别人来调我的服务时,此时是server的角色,记录 server receive 、server send信息
在resttemplate中配置tracing拦截器,去调别人的http服务的时候,此时是client角色,记录client send、client receive信息
4.3在webconfig中配置拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(serverZipkinInterceptor)
.excludePathPatterns("/metrics/**")
.excludePathPatterns("/v2/api-docs","/configuration/**","/swagger-resources/**");
registry.addInterceptor(new PrometheusMetricsInterceptor()).addPathPatterns("/**");
}
4.4 在resttemplate中配置
resttemplate可用httpclient、okhttp、netty初始化,我们选用的是okhttp。
看看okhttp怎么初始化的吧
@Bean
public OkHttpClient okHttpClient() {
//注意:使用http2.0协议,只有明确知道服务端支持H2C协议的时候才能使用。添加H2C支持,
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.protocols(Collections.singletonList(Protocol.H2_PRIOR_KNOWLEDGE));
Dispatcher dispatcher=new Dispatcher(
httpTracing.tracing().currentTraceContext()
.executorService(new Dispatcher().executorService())
);
//设置连接池大小
dispatcher.setMaxRequests(1000);
dispatcher.setMaxRequestsPerHost(200);
ConnectionPool pool = new ConnectionPool(20, 30, TimeUnit.MINUTES);
builder.connectTimeout(250, TimeUnit.MILLISECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.writeTimeout(10, TimeUnit.SECONDS)
.connectionPool(pool)
.dispatcher(dispatcher)
//链路监控埋点
.addNetworkInterceptor(TracingInterceptor.create(httpTracing))
//.addInterceptor(new OkHttpInterceptor())
.retryOnConnectionFailure(false);
return builder.build();
}
RestTemplate restTemplate= new RestTemplate(OkHttp3Factory());
4.5 数据处理过程
并不是每来一个span数据就往kafka推,这样效率必然是最差的。
批量优化处理嘛,内存建一个span队列,当堆积的量达到设定的最大值,一次性往kafka推span数组。
zipkinserver监听kafka“zipkin”这个topic。收到span数组后,进行拆分,索引,校验等操作,再调ES的restful接口写入ES。
zipkinserver提供的查询分析工具就可以去ES取数据,进行链路监控分析了。
5 融合ELK日志体系
单单只有zipkin的数据还是不够的,zipkin的作用是将一个完整的调用链路串联起来。但缺乏详细的业务日志信息,怎么搞?
每个brave tracing会把traceid spanid等信息插入 MDC,实现了标准日志接口的日志工具既可以从MDC中读取traceid,在log.info中将traceid一并写入,从而将链路与每个服务的业务日志关联起来。
我要记录DB\MQ\NOSQL的日志能支持吗?对不起我不支持,把zipkin定位于一个纯粹的串联链路工具,不与业务代码耦合。
log.info会支持就好。
我们记录的结构化log数据格式:
LogEntity logEntity=new LogEntity();
logEntity.setTraceId(MDC.get("traceId"));
logEntity.setSpanId(MDC.get("spanId"));
logEntity.setIP(ip);
logEntity.setAppName(getAppname());
logEntity.setLevel(event.getLevel().levelStr);
logEntity.setLogger(event.getLoggerName());
logEntity.setLocation(event.getCallerData()[0].toString());
logEntity.setTimestamp(LocalDateTime.now());
logEntity.setMessage(event.getFormattedMessage());
代码详解core模块下的logback+kafka相关配置与数据结构