内存管理
1.什么情况使用weak关键字,相比assign有什么不同?
-
什么情况使用 weak 关键字?
在 ARC 中,在有可能出现循环引用的时候,往往要通过让其中一端使用 weak 来解决,比如: delegate 代理属性
自身已经对它进行一次强引用,没有必要再强引用一次,此时也会使用 weak,自定义 IBOutlet 控件属性一般也使用 weak;当然,也可以使用strong。在下文也有论述:《IBOutlet连出来的视图属性为什么可以被设置成weak?》
-
不同点:
weak 此特质表明该属性定义了一种“非拥有关系” (nonowning relationship)。为这种属性设置新值时,设置方法既不保留新值,也不释放旧值。此特质同assign类似, 然而在属性所指的对象遭到摧毁时,属性值也会清空(nil out)。 而 assign 的“设置方法”只会执行针对“纯量类型” (scalar type,例如 CGFloat 或 NSlnteger 等)的简单赋值操作。
assign 可以用非 OC 对象,而 weak 必须用于 OC 对象
2.如何让自己的类用copy修饰符?如何重写带copy关键字的setter?
-
若想令自己所写的对象具有拷贝功能,则需实现 NSCopying 协议。如果自定义的对象分为可变版本与不可变版本,那么就要同时实现 NSCopying 与 NSMutableCopying 协议。
具体步骤:
需声明该类遵从 NSCopying 协议
实现 NSCopying 协议。该协议只有一个方法:
- (id)copyWithZone:(NSZone *)zone;注意:一提到让自己的类用 copy 修饰符,我们总是想覆写copy方法,其实真正需要实现的却是 “copyWithZone” 方法。
-
重写带 copy 关键字的 setter,例如:
- (void)setName:(NSString *)name { //[_name release]; _name = [name copy]; }
3.深拷贝与浅拷贝
浅拷贝只是对指针的拷贝,拷贝后两个指针指向同一个内存空间,深拷贝不但对指针进行拷贝,而且对指针指向的内容进行拷贝,经深拷贝后的指针是指向两个不同地址的指针。
当对象中存在指针成员时,除了在复制对象时需要考虑自定义拷贝构造函数,还应该考虑以下两种情形:
当函数的参数为对象时,实参传递给形参的实际上是实参的一个拷贝对象,系统自动通过拷贝构造函数实现;
当函数的返回值为一个对象时,该对象实际上是函数内对象的一个拷贝,用于返回函数调用处。
copy方法:如果是非可扩展类对象,则是浅拷贝。如果是可扩展类对象,则是深拷贝。
mutableCopy方法:无论是可扩展类对象还是不可扩展类对象,都是深拷贝。
4.@property的本质是什么?ivar、getter、setter是如何生成并添加到这个类中的
-
@property 的本质是实例变量(ivar)+存取方法(access method = getter + setter),即 @property = ivar + getter + setter;
“属性” (property)作为 Objective-C 的一项特性,主要的作用就在于封装对象中的数据。 Objective-C 对象通常会把其所需要的数据保存为各种实例变量。实例变量一般通过“存取方法”(access method)来访问。其中,“获取方法” (getter)用于读取变量值,而“设置方法” (setter)用于写入变量值。
-
ivar、getter、setter 是自动合成这个类中的
完成属性定义后,编译器会自动编写访问这些属性所需的方法,此过程叫做“自动合成”(autosynthesis)。需要强调的是,这个过程由编译 器在编译期执行,所以编辑器里看不到这些“合成方法”(synthesized method)的源代码。除了生成方法代码 getter、setter 之外,编译器还要自动向类中添加适当类型的实例变量,并且在属性名前面加下划线,以此作为实例变量的名字。在前例中,会生成两个实例变量,其名称分别为 _firstName 与 _lastName。也可以在类的实现代码里通过 @synthesize 语法来指定实例变量的名字.
5.@protocol和category中如何使用@property
在 protocol 中使用 property 只会生成 setter 和 getter 方法声明,我们使用属性的目的,是希望遵守我协议的对象能实现该属性
category 使用 @property 也是只会生成 setter 和 getter 方法的声明,如果我们真的需要给 category 增加属性的实现,需要借助于运行时的两个函数:objc_setAssociatedObject和objc_getAssociatedObject
6.简要说一下@autoreleasePool的数据结构??
简单说是双向链表,每张链表头尾相接,有 parent、child指针
每创建一个池子,会在首部创建一个 哨兵 对象,作为标记
最外层池子的顶端会有一个next指针。当链表容量满了,就会在链表的顶端,并指向下一张表。
7.BAD_ACCESS在什么情况下出现?
访问了悬垂指针,比如对一个已经释放的对象执行了release、访问已经释放对象的成员变量或者发消息。 死循环
8.使用CADisplayLink、NSTimer有什么注意点?
CADisplayLink、NSTimer会造成循环引用,可以使用YYWeakProxy或者为CADisplayLink、NSTimer添加block方法解决循环引用
9.iOS内存分区情况
-
栈区(Stack)
由编译器自动分配释放,存放函数的参数,局部变量的值等
栈是向低地址扩展的数据结构,是一块连续的内存区域
-
堆区(Heap)
由程序员分配释放
是向高地址扩展的数据结构,是不连续的内存区域
-
全局区
全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域
程序结束后由系统释放
-
常量区
常量字符串就是放在这里的
程序结束后由系统释放
-
代码区
存放函数体的二进制代码
-
注:
在 iOS 中,堆区的内存是应用程序共享的,堆中的内存分配是系统负责的
系统使用一个链表来维护所有已经分配的内存空间(系统仅仅记录,并不管理具体的内容)
变量使用结束后,需要释放内存,OC 中是判断引用计数是否为 0,如果是就说明没有任何变量使用该空间,那么系统将其回收
当一个 app 启动后,代码区、常量区、全局区大小就已经固定,因此指向这些区的指针不会产生崩溃性的错误。而堆区和栈区是时时刻刻变化的(堆的创建销毁,栈的弹入弹出),所以当使用一个指针指向这个区里面的内存时,一定要注意内存是否已经被释放,否则会产生程序崩溃(也即是野指针报错)
10.iOS内存管理方式
-
Tagged Pointer(小对象)
Tagged Pointer 专门用来存储小的对象,例如 NSNumber 和 NSDate
Tagged Pointer 指针的值不再是地址了,而是真正的值。所以,实际上它不再是一个对象了,它只是一个披着对象皮的普通变量而已。所以,它的内存并不存储在堆中,也不需要 malloc 和 free
在内存读取上有着 3 倍的效率,创建时比以前快 106 倍
objc_msgSend 能识别 Tagged Pointer,比如 NSNumber 的 intValue 方法,直接从指针提取数据
使用 Tagged Pointer 后,指针内存储的数据变成了 Tag + Data,也就是将数据直接存储在了指针中
-
NONPOINTER_ISA (指针中存放与该对象内存相关的信息)
苹果将 isa 设计成了联合体,在 isa 中存储了与该对象相关的一些内存的信息,原因也如上面所说,并不需要 64 个二进制位全部都用来存储指针。isa 的结构:
// x86_64 架构 struct { uintptr_t nonpointer : 1; // 0:普通指针,1:优化过,使用位域存储更多信息 uintptr_t has_assoc : 1; // 对象是否含有或曾经含有关联引用 uintptr_t has_cxx_dtor : 1; // 表示是否有C++析构函数或OC的dealloc uintptr_t shiftcls : 44; // 存放着 Class、Meta-Class 对象的内存地址信息 uintptr_t magic : 6; // 用于在调试时分辨对象是否未完成初始化 uintptr_t weakly_referenced : 1; // 是否被弱引用指向 uintptr_t deallocating : 1; // 对象是否正在释放 uintptr_t has_sidetable_rc : 1; // 是否需要使用 sidetable 来存储引用计数 uintptr_t extra_rc : 8; // 引用计数能够用 8 个二进制位存储时,直接存储在这里 }; // arm64 架构 struct { uintptr_t nonpointer : 1; // 0:普通指针,1:优化过,使用位域存储更多信息 uintptr_t has_assoc : 1; // 对象是否含有或曾经含有关联引用 uintptr_t has_cxx_dtor : 1; // 表示是否有C++析构函数或OC的dealloc uintptr_t shiftcls : 33; // 存放着 Class、Meta-Class 对象的内存地址信息 uintptr_t magic : 6; // 用于在调试时分辨对象是否未完成初始化 uintptr_t weakly_referenced : 1; // 是否被弱引用指向 uintptr_t deallocating : 1; // 对象是否正在释放 uintptr_t has_sidetable_rc : 1; // 是否需要使用 sidetable 来存储引用计数 uintptr_t extra_rc : 19; // 引用计数能够用 19 个二进制位存储时,直接存储在这里 };这里的 has_sidetable_rc 和 extra_rc,has_sidetable_rc 表明该指针是否引用了 sidetable 散列表,之所以有这个选项,是因为少量的引用计数是不会直接存放在 SideTables 表中的,对象的引用计数会先存放在 extra_rc 中,当其被存满时,才会存入相应的 SideTables 散列表中,SideTables 中有很多张 SideTable,每个 SideTable 也都是一个散列表,而引用计数表就包含在 SideTable 之中。
-
散列表(引用计数表、弱引用表)
引用计数要么存放在 isa 的 extra_rc 中,要么存放在引用计数表中,而引用计数表包含在一个叫 SideTable 的结构中,它是一个散列表,也就是哈希表。而 SideTable 又包含在一个全局的 StripeMap 的哈希映射表中,这个表的名字叫 SideTables。
当一个对象访问 SideTables 时:
首先会取得对象的地址,将地址进行哈希运算,与 SideTables 中 SideTable 的个数取余,最后得到的结果就是该对象所要访问的 SideTable
在取得的 SideTable 中的 RefcountMap 表中再进行一次哈希查找,找到该对象在引用计数表中对应的位置
如果该位置存在对应的引用计数,则对其进行操作,如果没有对应的引用计数,则创建一个对应的 size_t 对象,其实就是一个 uint 类型的无符号整型
弱引用表也是一张哈希表的结构,其内部包含了每个对象对应的弱引用表 weak_entry_t,而 weak_entry_t 是一个结构体数组,其中包含的则是每一个对象弱引用的对象所对应的弱引用指针。
11.循环引用
循环引用的实质:多个对象相互之间有强引用,不能释放让系统回收。
如何解决循环引用?
1、避免产生循环引用,通常是将 strong 引用改为 weak 引用。 比如在修饰属性时用weak 在block内调用对象方法时,使用其弱引用,这里可以使用两个宏
define WS(weakSelf) __weak __typeof(&*self)weakSelf = self; // 弱引用
define ST(strongSelf) __strong __typeof(&*self)strongSelf = weakSelf; //使用这个要先声明weakSelf
还可以使用__block来修饰变量 在MRC下,__block不会增加其引用计数,避免了循环引用 在ARC下,__block修饰对象会被强引用,无法避免循环引用,需要手动解除。
2、在合适时机去手动断开循环引用。 通常我们使用第一种。
-
代理(delegate)循环引用属于相互循环引用
delegate 是iOS中开发中比较常遇到的循环引用,一般在声明delegate的时候都要使用弱引用 weak,或者assign,当然怎么选择使用assign还是weak,MRC的话只能用assign,在ARC的情况下最好使用weak,因为weak修饰的变量在释放后自动指向nil,防止野指针存在
-
NSTimer循环引用属于相互循环使用
在控制器内,创建NSTimer作为其属性,由于定时器创建后也会强引用该控制器对象,那么该对象和定时器就相互循环引用了。 如何解决呢? 这里我们可以使用手动断开循环引用: 如果是不重复定时器,在回调方法里将定时器invalidate并置为nil即可。 如果是重复定时器,在合适的位置将其invalidate并置为nil即可
3、block循环引用
一个简单的例子:
@property (copy, nonatomic) dispatch_block_t myBlock;
@property (copy, nonatomic) NSString *blockString;
- (void)testBlock {
self.myBlock = ^() {
NSLog(@"%@",self.blockString);
};
}
由于block会对block中的对象进行持有操作,就相当于持有了其中的对象,而如果此时block中的对象又持有了该block,则会造成循环引用。 解决方案就是使用__weak修饰self即可
__weak typeof(self) weakSelf = self;
self.myBlock = ^() {
NSLog(@"%@",weakSelf.blockString);
};
并不是所有block都会造成循环引用。 只有被强引用了的block才会产生循环引用 而比如dispatch_async(dispatch_get_main_queue(), ^{}),[UIView animateWithDuration:1 animations:^{}]这些系统方法等 或者block并不是其属性而是临时变量,即栈block
[self testWithBlock:^{
NSLog(@"%@",self);
}];
- (void)testWithBlock:(dispatch_block_t)block {
block();
}
还有一种场景,在block执行开始时self对象还未被释放,而执行过程中,self被释放了,由于是用weak修饰的,那么weakSelf也被释放了,此时在block里访问weakSelf时,就可能会发生错误(向nil对象发消息并不会崩溃,但也没任何效果)。 对于这种场景,应该在block中对 对象使用__strong修饰,使得在block期间对 对象持有,block执行结束后,解除其持有。
__weak typeof(self) weakSelf = self;
self.myBlock = ^() {
__strong __typeof(self) strongSelf = weakSelf;
[strongSelf test];
};
消息传递的方式
1.KVC实现原理
KVC,键-值编码,使用字符串直接访问对象的属性。
-
底层实现,当一个对象调用setValue方法时,方法内部会做以下操作:
1.检查是否存在相应key的set方法,如果存在,就调用set方法
2.如果set方法不存在,就会查找与key相同名称并且带下划线的成员属性,如果有,则直接给成员属性赋值
3.如果没有找到_key,就会查找相同名称的属性key,如果有就直接赋值
4.如果还没找到,则调用valueForUndefinedKey:和setValue:forUndefinedKey:方法
2.KVO的实现原理
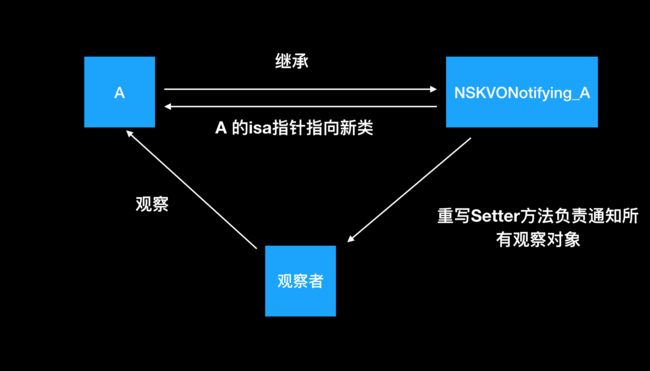
KVO-键值观察机制,原理如下:
1.当给A类添加KVO的时候,runtime动态的生成了一个子类NSKVONotifying_A,让A类的isa指针指向NSKVONotifying_A类,重写class方法,隐藏对象真实类信息
2.重写监听属性的setter方法,在setter方法内部调用了Foundation 的 _NSSetObjectValueAndNotify 函数
-
3._NSSetObjectValueAndNotify函数内部
a) 首先会调用 willChangeValueForKey
b) 然后给属性赋值
c) 最后调用 didChangeValueForKey
d) 最后调用 observer 的 observeValueForKeyPath 去告诉监听器属性值发生了改变 .
4.重写了dealloc做一些 KVO 内存释放
3.如何手动触发KVO方法
手动调用willChangeValueForKey和didChangeValueForKey方法
键值观察通知依赖于 NSObject 的两个方法: willChangeValueForKey: 和 didChangeValueForKey。在一个被观察属性发生改变之前, willChangeValueForKey: 一定会被调用,这就 会记录旧的值。而当改变发生后, didChangeValueForKey 会被调用,继而 observeValueForKey:ofObject:change:context: 也会被调用。如果可以手动实现这些调用,就可以实现“手动触发”了
有人可能会问只调用didChangeValueForKey方法可以触发KVO方法,其实是不能的,因为willChangeValueForKey: 记录旧的值,如果不记录旧的值,那就没有改变一说了
4.通知和代理有什么区别
通知是观察者模式,适合一对多的场景
代理模式适合一对一的反向传值
通知耦合度低,代理的耦合度高
5.block和delegate的区别
-
delegate运行成本低,block的运行成本高
block出栈需要将使用的数据从栈内存拷贝到堆内存,当然对象的话就是加计数,使用完或者block置nil后才消除。delegate只是保存了一个对象指针,直接回调,没有额外消耗。就像C的函数指针,只多做了一个查表动作。
delegate更适用于多个回调方法(3个以上),block则适用于1,2个回调时。
6.为什么Block用copy关键字
Block在没有使用外部变量时,内存存在全局区,然而,当Block在使用外部变量的时候,内存是存在于栈区,当Block copy之后,是存在堆区的。存在于栈区的特点是对象随时有可能被销毁,一旦销毁在调用的时候,就会造成系统的崩溃。所以Block要用copy关键字。
多线程
1.进程与线程
-
进程:
1.进程是一个具有一定独立功能的程序关于某次数据集合的一次运行活动,它是操作系统分配资源的基本单元.
2.进程是指在系统中正在运行的一个应用程序,就是一段程序的执行过程,我们可以理解为手机上的一个app.
3.每个进程之间是独立的,每个进程均运行在其专用且受保护的内存空间内,拥有独立运行所需的全部资源
-
线程
1.程序执行流的最小单元,线程是进程中的一个实体.
2.一个进程要想执行任务,必须至少有一条线程.应用程序启动的时候,系统会默认开启一条线程,也就是主线程
-
进程和线程的关系
1.线程是进程的执行单元,进程的所有任务都在线程中执行
2.线程是 CPU 分配资源和调度的最小单位
3.一个程序可以对应多个进程(多进程),一个进程中可有多个线程,但至少要有一条线程
4.同一个进程内的线程共享进程资源
2.什么是多线程?
多线程的实现原理:事实上,同一时间内单核的CPU只能执行一个线程,多线程是CPU快速的在多个线程之间进行切换(调度),造成了多个线程同时执行的假象。
如果是多核CPU就真的可以同时处理多个线程了。
多线程的目的是为了同步完成多项任务,通过提高系统的资源利用率来提高系统的效率。
3.多线程的优点和缺点
-
优点:
能适当提高程序的执行效率
能适当提高资源利用率(CPU、内存利用率)
-
缺点:
开启线程需要占用一定的内存空间(默认情况下,主线程占用1M,子线程占用512KB),如果开启大量的线程,会占用大量的内存空间,降低程序的性能
线程越多,CPU在调度线程上的开销就越大
程序设计更加复杂:比如线程之间的通信、多线程的数据共享
4.多线程的 并行 和 并发 有什么区别?
并行:充分利用计算机的多核,在多个线程上同步进行
并发:在一条线程上通过快速切换,让人感觉在同步进行
5.iOS中实现多线程的几种方案,各自有什么特点?
NSThread 面向对象的,需要程序员手动创建线程,但不需要手动销毁。子线程间通信很难。
GCD c语言,充分利用了设备的多核,自动管理线程生命周期。比NSOperation效率更高。
NSOperation 基于gcd封装,更加面向对象,比gcd多了一些功能。
6.多个网络请求完成后执行下一步
-
使用GCD的dispatch_group_t
创建一个dispatch_group_t
每次网络请求前先dispatch_group_enter,请求回调后再dispatch_group_leave,enter和leave必须配合使用,有几次enter就要有几次leave,否则group会一直存在。
当所有enter的block都leave后,会执行dispatch_group_notify的block。
NSString *str = @"http://xxxx.com/"; NSURL *url = [NSURL URLWithString:str]; NSURLRequest *request = [NSURLRequest requestWithURL:url]; NSURLSession *session = [NSURLSession sharedSession]; dispatch_group_t downloadGroup = dispatch_group_create(); for (int i=0; i<10; i++) { dispatch_group_enter(downloadGroup); NSURLSessionDataTask *task = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) { NSLog(@"%d---%d",i,i); dispatch_group_leave(downloadGroup); }]; [task resume]; } dispatch_group_notify(downloadGroup, dispatch_get_main_queue(), ^{ NSLog(@"end"); }); -
使用GCD的信号量dispatch_semaphore_t
dispatch_semaphore信号量为基于计数器的一种多线程同步机制。如果semaphore计数大于等于1,计数-1,返回,程序继续运行。如果计数为0,则等待。dispatch_semaphore_signal(semaphore)为计数+1操作,dispatch_semaphore_wait(sema, DISPATCH_TIME_FOREVER)为设置等待时间,这里设置的等待时间是一直等待。
创建semaphore为0,等待,等10个网络请求都完成了,dispatch_semaphore_signal(semaphore)为计数+1,然后计数-1返回
NSString *str = @"http://xxxx.com/"; NSURL *url = [NSURL URLWithString:str]; NSURLRequest *request = [NSURLRequest requestWithURL:url]; NSURLSession *session = [NSURLSession sharedSession]; dispatch_semaphore_t sem = dispatch_semaphore_create(0); for (int i=0; i<10; i++) { NSURLSessionDataTask *task = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) { NSLog(@"%d---%d",i,i); count++; if (count==10) { dispatch_semaphore_signal(sem); count = 0; } }]; [task resume]; } dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER); dispatch_async(dispatch_get_main_queue(), ^{ NSLog(@"end"); });
7.多个网络请求顺序执行后执行下一步
-
使用信号量semaphore
每一次遍历,都让其dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER),这个时候线程会等待,阻塞当前线程,直到dispatch_semaphore_signal(sem)调用之后
NSString *str = @"http://www.jianshu.com/p/6930f335adba"; NSURL *url = [NSURL URLWithString:str]; NSURLRequest *request = [NSURLRequest requestWithURL:url]; NSURLSession *session = [NSURLSession sharedSession]; dispatch_semaphore_t sem = dispatch_semaphore_create(0); for (int i=0; i<10; i++) { NSURLSessionDataTask *task = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) { NSLog(@"%d---%d",i,i); dispatch_semaphore_signal(sem); }]; [task resume]; dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER); } dispatch_async(dispatch_get_main_queue(), ^{ NSLog(@"end"); });
8.异步操作两组数据时, 执行完第一组之后, 才能执行第二组
-
这里使用dispatch_barrier_async栅栏方法即可实现
dispatch_queue_t queue = dispatch_queue_create("test", DISPATCH_QUEUE_CONCURRENT); dispatch_async(queue, ^{ NSLog(@"第一次任务的主线程为: %@", [NSThread currentThread]); }); dispatch_async(queue, ^{ NSLog(@"第二次任务的主线程为: %@", [NSThread currentThread]); }); dispatch_barrier_async(queue, ^{ NSLog(@"第一次任务, 第二次任务执行完毕, 继续执行"); }); dispatch_async(queue, ^{ NSLog(@"第三次任务的主线程为: %@", [NSThread currentThread]); }); dispatch_async(queue, ^{ NSLog(@"第四次任务的主线程为: %@", [NSThread currentThread]); });
9.多线程中的死锁?
死锁是由于多个线程(进程)在执行过程中,因为争夺资源而造成的互相等待现象,你可以理解为卡主了。产生死锁的必要条件有四个:
互斥条件 : 指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
请求和保持条件 : 指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
不可剥夺条件 : 指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
-
环路等待条件 : 指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
最常见的就是 同步函数 + 主队列 的组合,本质是队列阻塞。
dispatch_sync(dispatch_get_main_queue(), ^{ NSLog(@"2"); }); NSLog(@"1"); // 什么也不会打印,直接报错
10.GCD执行原理?
GCD有一个底层线程池,这个池中存放的是一个个的线程。之所以称为“池”,很容易理解出这个“池”中的线程是可以重用的,当一段时间后这个线程没有被调用胡话,这个线程就会被销毁。注意:开多少条线程是由底层线程池决定的(线程建议控制再3~5条),池是系统自动来维护,不需要我们程序员来维护(看到这句话是不是很开心?)
而我们程序员需要关心的是什么呢?我们只关心的是向队列中添加任务,队列调度即可。如果队列中存放的是同步任务,则任务出队后,底层线程池中会提供一条线程供这个任务执行,任务执行完毕后这条线程再回到线程池。这样队列中的任务反复调度,因为是同步的,所以当我们用currentThread打印的时候,就是同一条线程。
如果队列中存放的是异步的任务,(注意异步可以开线程),当任务出队后,底层线程池会提供一个线程供任务执行,因为是异步执行,队列中的任务不需等待当前任务执行完毕就可以调度下一个任务,这时底层线程池中会再次提供一个线程供第二个任务执行,执行完毕后再回到底层线程池中。
这样就对线程完成一个复用,而不需要每一个任务执行都开启新的线程,也就从而节约的系统的开销,提高了效率。在iOS7.0的时候,使用GCD系统通常只能开58条线程,iOS8.0以后,系统可以开启很多条线程,但是实在开发应用中,建议开启线程条数:35条最为合理。
Runloop
1.Runloop 和线程的关系?
一个线程对应一个 Runloop。
主线程的默认就有了 Runloop。
子线程的 Runloop 以懒加载的形式创建。
Runloop 存储在一个全局的可变字典里,线程是 key ,Runloop 是 value。
2.RunLoop的运行模式
-
RunLoop的运行模式共有5种,RunLoop只会运行在一个模式下,要切换模式,就要暂停当前模式,重写启动一个运行模式
- kCFRunLoopDefaultMode, App的默认运行模式,通常主线程是在这个运行模式下运行 - UITrackingRunLoopMode, 跟踪用户交互事件(用于 ScrollView 追踪触摸滑动,保证界面滑动时不受其他Mode影响) - kCFRunLoopCommonModes, 伪模式,不是一种真正的运行模式 - UIInitializationRunLoopMode:在刚启动App时第进入的第一个Mode,启动完成后就不再使用 - GSEventReceiveRunLoopMode:接受系统内部事件,通常用不到
3.runloop内部逻辑?
-
实际上 RunLoop 就是这样一个函数,其内部是一个 do-while 循环。当你调用 CFRunLoopRun() 时,线程就会一直停留在这个循环里;直到超时或被手动停止,该函数才会返回。
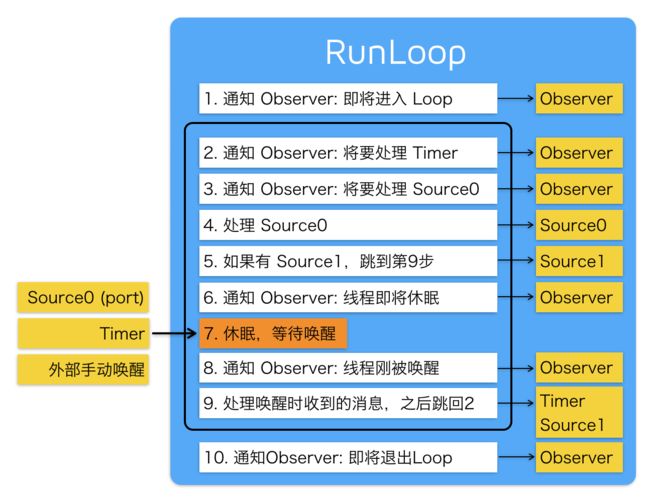 RunLoop
RunLoop -
内部逻辑:
通知 Observer 已经进入了 RunLoop
通知 Observer 即将处理 Timer
通知 Observer 即将处理非基于端口的输入源(即将处理 Source0)
处理那些准备好的非基于端口的输入源(处理 Source0)
如果基于端口的输入源准备就绪并等待处理,请立刻处理该事件。转到第 9 步(处理 Source1)
通知 Observer 线程即将休眠
-
将线程置于休眠状态,直到发生以下事件之一
事件到达基于端口的输入源(port-based input sources)(也就是 Source0)
Timer 到时间执行
外部手动唤醒
为 RunLoop 设定的时间超时
通知 Observer 线程刚被唤醒(还没处理事件)
-
处理待处理事件
如果是 Timer 事件,处理 Timer 并重新启动循环,跳到第 2 步
如果输入源被触发,处理该事件(文档上是 deliver the event)
如果 RunLoop 被手动唤醒但尚未超时,重新启动循环,跳到第 2 步
4.autoreleasePool 在何时被释放?
App启动后,苹果在主线程 RunLoop 里注册了两个 Observer,其回调都是 _wrapRunLoopWithAutoreleasePoolHandler()。
第一个 Observer 监视的事件是 Entry(即将进入Loop),其回调内会调用 _objc_autoreleasePoolPush() 创建自动释放池。其 order 是 -2147483647,优先级最高,保证创建释放池发生在其他所有回调之前。
第二个 Observer 监视了两个事件: BeforeWaiting(准备进入休眠) 时调用_objc_autoreleasePoolPop() 和 _objc_autoreleasePoolPush() 释放旧的池并创建新池;Exit(即将退出Loop) 时调用 _objc_autoreleasePoolPop() 来释放自动释放池。这个 Observer 的 order 是 2147483647,优先级最低,保证其释放池子发生在其他所有回调之后。
在主线程执行的代码,通常是写在诸如事件回调、Timer回调内的。这些回调会被 RunLoop 创建好的 AutoreleasePool 环绕着,所以不会出现内存泄漏,开发者也不必显示创建 Pool 了。
5.GCD 在Runloop中的使用?
- GCD由 子线程 返回到 主线程,只有在这种情况下才会触发 RunLoop。会触发 RunLoop 的 Source 1 事件。
6.AFNetworking 中如何运用 Runloop?
-
AFURLConnectionOperation 这个类是基于 NSURLConnection 构建的,其希望能在后台线程接收 Delegate 回调。为此 AFNetworking 单独创建了一个线程,并在这个线程中启动了一个 RunLoop:
+ (void)networkRequestThreadEntryPoint:(id)__unused object { @autoreleasepool { [[NSThread currentThread] setName:@"AFNetworking"]; NSRunLoop *runLoop = [NSRunLoop currentRunLoop]; [runLoop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode]; [runLoop run]; } } + (NSThread *)networkRequestThread { static NSThread *_networkRequestThread = nil; static dispatch_once_t oncePredicate; dispatch_once(&oncePredicate, ^{ _networkRequestThread = [[NSThread alloc] initWithTarget:self selector:@selector(networkRequestThreadEntryPoint:) object:nil]; [_networkRequestThread start]; }); return _networkRequestThread; } -
RunLoop 启动前内部必须要有至少一个 Timer/Observer/Source,所以 AFNetworking 在 [runLoop run] 之前先创建了一个新的 NSMachPort 添加进去了。通常情况下,调用者需要持有这个 NSMachPort (mach_port) 并在外部线程通过这个 port 发送消息到 loop 内;但此处添加 port 只是为了让 RunLoop 不至于退出,并没有用于实际的发送消息。
- (void)start { [self.lock lock]; if ([self isCancelled]) { [self performSelector:@selector(cancelConnection) onThread:[[self class] networkRequestThread] withObject:nil waitUntilDone:NO modes:[self.runLoopModes allObjects]]; } else if ([self isReady]) { self.state = AFOperationExecutingState; [self performSelector:@selector(operationDidStart) onThread:[[self class] networkRequestThread] withObject:nil waitUntilDone:NO modes:[self.runLoopModes allObjects]]; } [self.lock unlock]; } 当需要这个后台线程执行任务时,AFNetworking 通过调用 [NSObject performSelector:onThread:..] 将这个任务扔到了后台线程的 RunLoop 中。
7.PerformSelector 的实现原理?
当调用 NSObject 的 performSelecter:afterDelay: 后,实际上其内部会创建一个 Timer 并添加到当前线程的 RunLoop 中。所以如果当前线程没有 RunLoop,则这个方法会失效。
当调用 performSelector:onThread: 时,实际上其会创建一个 Timer 加到对应的线程去,同样的,如果对应线程没有 RunLoop 该方法也会失效。
8.PerformSelector:afterDelay:这个方法在子线程中是否起作用?
- 不起作用,子线程默认没有 Runloop,也就没有 Timer。可以使用 GCD的dispatch_after来实现
9.事件响应的过程?
苹果注册了一个 Source1 (基于 mach port 的) 用来接收系统事件,其回调函数为 __IOHIDEventSystemClientQueueCallback()。
当一个硬件事件(触摸/锁屏/摇晃等)发生后,首先由 IOKit.framework 生成一个 IOHIDEvent 事件并由 SpringBoard 接收。这个过程的详细情况可以参考这里。SpringBoard 只接收按键(锁屏/静音等),触摸,加速,接近传感器等几种 Event,随后用 mach port 转发给需要的 App 进程。随后苹果注册的那个 Source1 就会触发回调,并调用 _UIApplicationHandleEventQueue() 进行应用内部的分发。
_UIApplicationHandleEventQueue() 会把 IOHIDEvent 处理并包装成 UIEvent 进行处理或分发,其中包括识别 UIGesture/处理屏幕旋转/发送给 UIWindow 等。通常事件比如 UIButton 点击、touchesBegin/Move/End/Cancel 事件都是在这个回调中完成的。
10.手势识别的过程?
当 _UIApplicationHandleEventQueue() 识别了一个手势时,其首先会调用 Cancel 将当前的 touchesBegin/Move/End 系列回调打断。随后系统将对应的 UIGestureRecognizer 标记为待处理。
苹果注册了一个 Observer 监测 BeforeWaiting (Loop即将进入休眠) 事件,这个 Observer 的回调函数是 _UIGestureRecognizerUpdateObserver(),其内部会获取所有刚被标记为待处理的 GestureRecognizer,并执行GestureRecognizer 的回调。
当有 UIGestureRecognizer 的变化(创建/销毁/状态改变)时,这个回调都会进行相应处理。
11.CADispalyTimer和Timer哪个更精确
CADisplayLink 更精确
iOS设备的屏幕刷新频率是固定的,CADisplayLink在正常情况下会在每次刷新结束都被调用,精确度相当高。
NSTimer的精确度就显得低了点,比如NSTimer的触发时间到的时候,runloop如果在阻塞状态,触发时间就会推迟到下一个runloop周期。并且 NSTimer新增了tolerance属性,让用户可以设置可以容忍的触发的时间的延迟范围。
CADisplayLink使用场合相对专一,适合做UI的不停重绘,比如自定义动画引擎或者视频播放的渲染。NSTimer的使用范围要广泛的多,各种需要单次或者循环定时处理的任务都可以使用。在UI相关的动画或者显示内容使用 CADisplayLink比起用NSTimer的好处就是我们不需要在格外关心屏幕的刷新频率了,因为它本身就是跟屏幕刷新同步的。
Runtime
1.Category 的实现原理?
Category 实际上是 Category_t的结构体,在运行时,新添加的方法,都被以倒序插入到原有方法列表的最前面,所以不同的Category,添加了同一个方法,执行的实际上是最后一个。
Category 在刚刚编译完的时候,和原来的类是分开的,只有在程序运行起来后,通过 Runtime ,Category 和原来的类才会合并到一起。
2.isa指针的理解,对象的isa指针指向哪里?isa指针有哪两种类型?
-
isa 等价于 is kind of
实例对象的 isa 指向类对象
类对象的 isa 指向元类对象
元类对象的 isa 指向元类的基类
-
isa 有两种类型
纯指针,指向内存地址
NON_POINTER_ISA,除了内存地址,还存有一些其他信息
3.Objective-C 如何实现多重继承?
Object-c的类没有多继承,只支持单继承,如果要实现多继承的话,可使用如下几种方式间接实现
-
通过组合实现
A和B组合,作为C类的组件
-
通过协议实现
C类实现A和B类的协议方法
-
消息转发实现
forwardInvocation:方法
4.runtime 如何实现 weak 属性?
weak 此特质表明该属性定义了一种「非拥有关系」(nonowning relationship)。为这种属性设置新值时,设置方法既不持有新值(新指向的对象),也不释放旧值(原来指向的对象)。
runtime 对注册的类,会进行内存布局,从一个粗粒度的概念上来讲,这时候会有一个 hash 表,这是一个全局表,表中是用 weak 指向的对象内存地址作为 key,用所有指向该对象的 weak 指针表作为 value。当此对象的引用计数为 0 的时候会 dealloc,假如该对象内存地址是 a,那么就会以 a 为 key,在这个 weak 表中搜索,找到所有以 a 为键的 weak 对象,从而设置为 nil。
runtime 如何实现 weak 属性具体流程大致分为 3 步:
1、初始化时:runtime 会调用 objc_initWeak 函数,初始化一个新的 weak 指针指向对象的地址。
2、添加引用时:objc_initWeak 函数会调用 objc_storeWeak() 函数,objc_storeWeak() 的作用是更新指针指向(指针可能原来指向着其他对象,这时候需要将该 weak 指针与旧对象解除绑定,会调用到 weak_unregister_no_lock),如果指针指向的新对象非空,则创建对应的弱引用表,将 weak 指针与新对象进行绑定,会调用到 weak_register_no_lock。在这个过程中,为了防止多线程中竞争冲突,会有一些锁的操作。
3、释放时:调用 clearDeallocating 函数,clearDeallocating 函数首先根据对象地址获取所有 weak 指针地址的数组,然后遍历这个数组把其中的数据设为 nil,最后把这个 entry 从 weak 表中删除,最后清理对象的记录。
5.讲一下 OC 的消息机制
OC中的方法调用其实都是转成了objc_msgSend函数的调用,给receiver(方法调用者)发送了一条消息(selector方法名)
objc_msgSend底层有3大阶段,消息发送(当前类、父类中查找)、动态方法解析、消息转发
6.runtime具体应用
利用关联对象(AssociatedObject)给分类添加属性
遍历类的所有成员变量(修改textfield的占位文字颜色、字典转模型、自动归档解档)
交换方法实现(交换系统的方法)
利用消息转发机制解决方法找不到的异常问题
KVC 字典转模型
7.runtime如何通过selector找到对应的IMP地址?
每一个类对象中都一个对象方法列表(对象方法缓存)
类方法列表是存放在类对象中isa指针指向的元类对象中(类方法缓存)。
方法列表中每个方法结构体中记录着方法的名称,方法实现,以及参数类型,其实selector本质就是方法名称,通过这个方法名称就可以在方法列表中找到对应的方法实现。
当我们发送一个消息给一个NSObject对象时,这条消息会在对象的类对象方法列表里查找。
当我们发送一个消息给一个类时,这条消息会在类的Meta Class对象的方法列表里查找。
8.简述下Objective-C中调用方法的过程
Objective-C是动态语言,每个方法在运行时会被动态转为消息发送,即:objc_msgSend(receiver, selector),整个过程介绍如下:
objc在向一个对象发送消息时,runtime库会根据对象的isa指针找到该对象实际所属的类
然后在该类中的方法列表以及其父类方法列表中寻找方法运行
如果,在最顶层的父类(一般也就NSObject)中依然找不到相应的方法时,程序在运行时会挂掉并抛出异常unrecognized selector sent to XXX
但是在这之前,objc的运行时会给出三次拯救程序崩溃的机会,这三次拯救程序奔溃的说明见问题《什么时候会报unrecognized selector的异常》中的说明。
9.load和initialize的区别
两者都会自动调用父类的,不需要super操作,且仅会调用一次(不包括外部显示调用).
load和initialize方法都会在实例化对象之前调用,以main函数为分水岭,前者在main函数之前调用,后者在之后调用。这两个方法会被自动调用,不能手动调用它们。
load和initialize方法都不用显示的调用父类的方法而是自动调用,即使子类没有initialize方法也会调用父类的方法,而load方法则不会调用父类。
load方法通常用来进行Method Swizzle,initialize方法一般用于初始化全局变量或静态变量。
load和initialize方法内部使用了锁,因此它们是线程安全的。实现时要尽可能保持简单,避免阻塞线程,不要再使用锁。
10.怎么理解Objective-C是动态运行时语言。
主要是将数据类型的确定由编译时,推迟到了运行时。这个问题其实浅涉及到两个概念,运行时和多态。
简单来说, 运行时机制使我们直到运行时才去决定一个对象的类别,以及调用该类别对象指定方法。
多态:不同对象以自己的方式响应相同的消息的能力叫做多态。
意思就是假设生物类(life)都拥有一个相同的方法-eat;那人类属于生物,猪也属于生物,都继承了life后,实现各自的eat,但是调用是我们只需调用各自的eat方法。也就是不同的对象以自己的方式响应了相同的消 息(响应了eat这个选择器)。因此也可以说,运行时机制是多态的基础.
网络
1.网络七层协议
-
应用层:
1.用户接口、应用程序;
2.Application典型设备:网关;
3.典型协议、标准和应用:TELNET、FTP、HTTP
-
表示层:
1.数据表示、压缩和加密presentation
2.典型设备:网关
3.典型协议、标准和应用:ASCLL、PICT、TIFF、JPEG|MPEG
4.表示层相当于一个东西的表示,表示的一些协议,比如图片、声音和视频MPEG。
-
会话层:
1.会话的建立和结束;
2.典型设备:网关;
3.典型协议、标准和应用:RPC、SQL、NFS、X WINDOWS、ASP
-
传输层:
1.主要功能:端到端控制Transport;
2.典型设备:网关;
3.典型协议、标准和应用:TCP、UDP、SPX
-
网络层:
1.主要功能:路由、寻址Network;
2.典型设备:路由器;
3.典型协议、标准和应用:IP、IPX、APPLETALK、ICMP;
-
数据链路层:
1.主要功能:保证无差错的疏忽链路的data link;
2.典型设备:交换机、网桥、网卡;
3.典型协议、标准和应用:802.2、802.3ATM、HDLC、FRAME RELAY;
-
物理层:
1.主要功能:传输比特流Physical;
2.典型设备:集线器、中继器
3.典型协议、标准和应用:V.35、EIA/TIA-232.
2.Http 和 Https 的区别?Https为什么更加安全?
-
区别
1.HTTPS 需要向机构申请 CA 证书,极少免费。
2.HTTP 属于明文传输,HTTPS基于 SSL 进行加密传输。
3.HTTP 端口号为 80,HTTPS 端口号为 443 。
4.HTTPS 是加密传输,有身份验证的环节,更加安全。
-
安全
SSL(安全套接层) TLS(传输层安全)
以上两者在传输层之上,对网络连接进行加密处理,保障数据的完整性,更加的安全。
3.HTTPS的连接建立流程
HTTPS为了兼顾安全与效率,同时使用了对称加密和非对称加密。在传输的过程中会涉及到三个密钥:
服务器端的公钥和私钥,用来进行非对称加密
-
客户端生成的随机密钥,用来进行对称加密
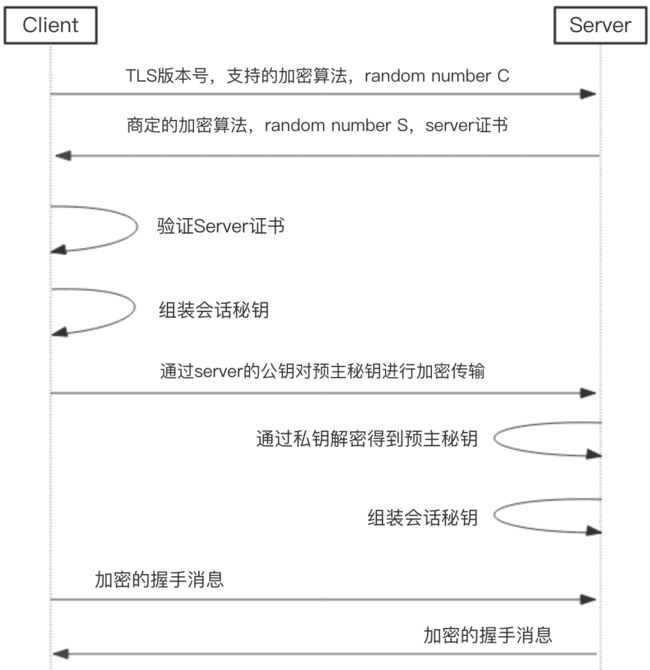 https
https
如上图,HTTPS连接过程大致可分为八步:
-
1、客户端访问HTTPS连接。
客户端会把安全协议版本号、客户端支持的加密算法列表、随机数C发给服务端。
-
2、服务端发送证书给客户端
服务端接收密钥算法配件后,会和自己支持的加密算法列表进行比对,如果不符合,则断开连接。否则,服务端会在该算法列表中,选择一种对称算法(如AES)、一种公钥算法(如具有特定秘钥长度的RSA)和一种MAC算法发给客户端。
服务器端有一个密钥对,即公钥和私钥,是用来进行非对称加密使用的,服务器端保存着私钥,不能将其泄露,公钥可以发送给任何人。
在发送加密算法的同时还会把数字证书和随机数S发送给客户端
-
3、客户端验证server证书
会对server公钥进行检查,验证其合法性,如果发现发现公钥有问题,那么HTTPS传输就无法继续。
-
4、客户端组装会话秘钥
如果公钥合格,那么客户端会用服务器公钥来生成一个前主秘钥(Pre-Master Secret,PMS),并通过该前主秘钥和随机数C、S来组装成会话秘钥
-
5、客户端将前主秘钥加密发送给服务端
是通过服务端的公钥来对前主秘钥进行非对称加密,发送给服务端
-
6、服务端通过私钥解密得到前主秘钥
服务端接收到加密信息后,用私钥解密得到主秘钥。
-
7、服务端组装会话秘钥
服务端通过前主秘钥和随机数C、S来组装会话秘钥。
至此,服务端和客户端都已经知道了用于此次会话的主秘钥。
-
8、数据传输
客户端收到服务器发送来的密文,用客户端密钥对其进行对称解密,得到服务器发送的数据。
同理,服务端收到客户端发送来的密文,用服务端密钥对其进行对称解密,得到客户端发送的数据。
4.解释一下 三次握手 和 四次挥手
-
三次握手
1.由客户端向服务端发送 SYN 同步报文。
2.当服务端收到 SYN 同步报文之后,会返回给客户端 SYN 同步报文和 ACK 确认报文。
3.客户端会向服务端发送 ACK 确认报文,此时客户端和服务端的连接正式建立。
-
建立连接
1.这个时候客户端就可以通过 Http 请求报文,向服务端发送请求
2.服务端接收到客户端的请求之后,向客户端回复 Http 响应报文。
-
四次挥手
当客户端和服务端的连接想要断开的时候,要经历四次挥手的过程,步骤如下:
1.先由客户端向服务端发送 FIN 结束报文。
2.服务端会返回给客户端 ACK 确认报文 。此时,由客户端发起的断开连接已经完成。
3.服务端会发送给客户端 FIN 结束报文 和 ACK 确认报文。
4.客户端会返回 ACK 确认报文到服务端,至此,由服务端方向的断开连接已经完成。
5.TCP 和 UDP的区别
TCP:面向连接、传输可靠(保证数据正确性,保证数据顺序)、用于传输大量数据(流模式)、速度慢,建立连接需要开销较多(时间,系统资源)。
UDP:面向非连接、传输不可靠、用于传输少量数据(数据包模式)、速度快。
6.Cookie和Session
cookie
-
1.用户与服务器的交互
cookie主要是用来记录用户状态,区分用户,状态保存在客户端。cookie功能需要浏览器的支持。如果浏览器不支持cookie(如大部分手机中的浏览器)或者把cookie禁用了,cookie功能就会失效。
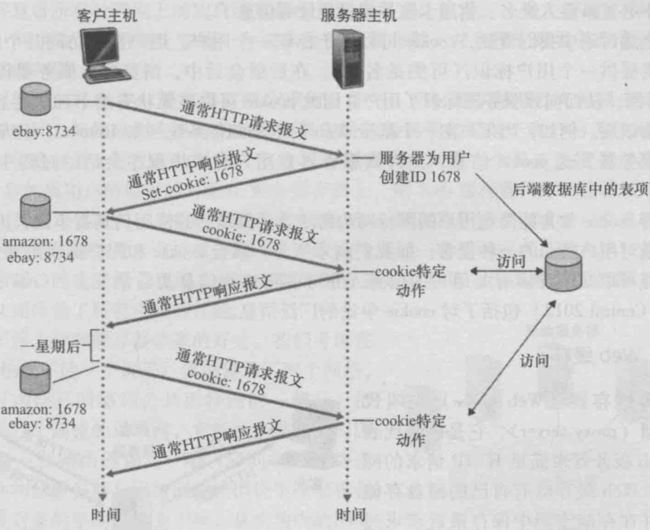 cookie
cookiea).首次访问amazon时,客户端发送一个HTTP请求到服务器端 。服务器端发送一个HTTP响应到客户端,其中包含Set-Cookie头部
b).客户端发送一个HTTP请求到服务器端,其中包含Cookie头部。服务器端发送一个HTTP响应到客户端
c).隔段时间再去访问时,客户端会直接发包含Cookie头部的HTTP请求。服务器端发送一个HTTP响应到客户端
-
2.cookie的修改和删除
在修改cookie的时候,只需要新cookie覆盖旧cookie即可,在覆盖的时候,由于Cookie具有不可跨域名性,注意name、path、domain需与原cookie一致
删除cookie也一样,设置cookie的过期时间expires为过去的一个时间点,或者maxAge = 0(Cookie的有效期,单位为秒)即可
-
3、cookie的安全
事实上,cookie的使用存在争议,因为它被认为是对用户隐私的一种侵害,而且cookie并不安全
HTTP协议不仅是无状态的,而且是不安全的。使用HTTP协议的数据不经过任何加密就直接在网络上传播,有被截获的可能。使用HTTP协议传输很机密的内容是一种隐患。
a).如果不希望Cookie在HTTP等非安全协议中传输,可以设置Cookie的secure属性为true。浏览器只会在HTTPS和SSL等安全协议中传输此类Cookie。
b).此外,secure属性并不能对Cookie内容加密,因而不能保证绝对的安全性。如果需要高安全性,需要在程序中对Cookie内容加密、解密,以防泄密。
c).也可以设置cookie为HttpOnly,如果在cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS(跨站脚本攻击)攻击
Session
Session是服务器端使用的一种记录客户端状态的机制,使用上比Cookie简单一些,相应的也增加了服务器的存储压力。
-
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。
客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。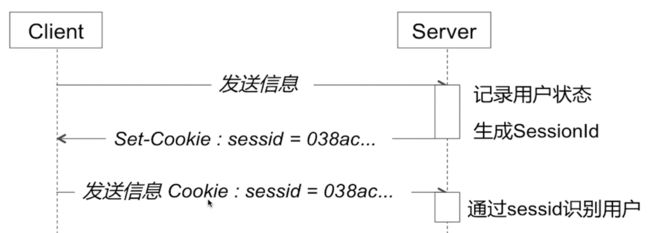 session
session -
如图:
当程序需要为某个客户端的请求创建一个session时,服务器首先检查这个客户端的请求里是否已包含了一个session标识(称为SessionId)
如果已包含则说明以前已经为此客户端创建过session,服务器就按照SessionId把这个session检索出来,使用(检索不到,会新建一个)
如果客户端请求不包含SessionId,则为此客户端创建一个session并且生成一个与此session相关联的SessionId,SessionId的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个SessionId将被在本次响应中返回给客户端保存。
保存这个SessionId的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发送给服务器。但cookie可以被人为的禁止,则必须有其他机制以便在cookie被禁止时仍然能够把SessionId传递回服务器。
Cookie 和Session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie相比session不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。而session存储在服务端,可以无限量存储
5、所以:将登录信息等重要信息存放为session;其他信息如果需要保留,可以放在cookie中
7.DNS是什么
因特网上的主机,可以使用多种方式标识,比如主机名或IP地址。一种标识方法就是用它的主机名(hostname),比如·www.baidu.com、www.google.com、gaia.cs.umass.edu等。这方式方便人们记忆和接受,但是这种长度不一、没有规律的字符串路由器并不方便处理。还有一种方式,就是直接使用定长的、有着清晰层次结构的IP地址,路由器比较热衷于这种方式。为了折衷这两种方式,我们需要一种能进行主机名到IP地址转换的目录服务。这就是域名系统(Domain Name System,DNS)的主要任务。
-
DNS是:
1、一个由分层的DNS服务器实现的分布式数据库
2、一个使得主机能够查询分布式数据库的应用层协议
DNS服务器通常是运行BIND软件的UNIX机器,DNS协议运行在UDP上,使用53号端口
DNS通常是由其他应用层协议所使用的,包括HTTP、SMTP等。其作用则是:将用户提供的主机名解析为IP地址
-
DNS的一种简单设计就是在因特网上只使用一个DNS服务器,该服务器包含所有的映射。很明显这种设计是有很大的问题的:
单点故障:如果该DNS服务器崩溃,全世界的网络随之瘫痪
通信容量:单个DNS服务器必须处理所有DNS查询
远距离的集中式数据库:单个DNS服务器必须面对所有用户,距离过远会有严重的时延。
维护:该数据库过于庞大,还需要对新添加的主机频繁更新。
所以,DNS被设计成了一个分布式、层次数据库
8.DNS解析过程
以www.163.com为例:
客户端打开浏览器,输入一个域名。比如输入www.163.com,这时,客户端会发出一个DNS请求到本地DNS服务器。本地DNS服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动。
查询www.163.com的DNS请求到达本地DNS服务器之后,本地DNS服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果。如果没有,本地DNS服务器还要向DNS根服务器进行查询。
根DNS服务器没有记录具体的域名和IP地址的对应关系,而是告诉本地DNS服务器,你可以到域服务器上去继续查询,并给出域服务器的地址。
本地DNS服务器继续向域服务器发出请求,在这个例子中,请求的对象是.com域服务器。.com域服务器收到请求之后,也不会直接返回域名和IP地址的对应关系,而是告诉本地DNS服务器,你的域名的解析服务器的地址。
最后,本地DNS服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP地址对应关系,本地DNS服务器不仅要把IP地址返回给用户电脑,还要把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。