ECCV2020 TIDE: A General Toolbox for Identifying Object Detection Errors
ECCV2020 TIDE: A General Toolbox for Identifying Object Detection Errors论文翻译
-
-
- 摘要
- 1.介绍
- 2.工具
-
- 2.1 计算mAP
- 2.2 定义错误类型
- 2.3计算错误的限制
- 3.分析
-
- 3.1验证设计选择
- 3.2 比较目标属性进行精细分析
-
- 3.3 不同数据集之间的比较
- 3.4 不可避免的误差
- 4.结论
- 参考
-
论文地址:TIDE: A General Toolbox for Identifying Object Detection Errors
工具代码地址:https://github.com/dbolya/tide
摘要
我们介绍了TIDE,一个用于分析对象检测和实例分割算法中的误差来源的框架和相关的工具箱。重要的是,我们的框架是跨数据集适用的,可以直接应用到输出的预测文件,而不需要了解底层的预测系统。因此,我们的框架可以作为一个替代mAP计算,同时提供一个全面的分析,每个模型的优点和缺点。我们将错误划分为六种类型,而且最关键的是,我们首先引入了一种技术,以隔离错误对整体性能的影响的方式来度量每个错误的贡献。通过对4个数据集和7个识别模型的深入分析,我们表明这样的表示法对于得出准确、全面的结论至关重要。
1.介绍
目标检测和实例分割是计算机视觉的基本任务,应用范围从自动驾驶汽车[6]到肿瘤检测[9]。最近,目标检测领域取得了迅速的进展,部分得益于挑战性的基准竞赛,如CalTech行人[8]、Pascal[10]、COCO[20]、Cityscapes[6]和LVIS[12]。通常,这些基准测试的性能用一个数字来概括:mean Average Precision(mAP)。
然而,mAP有几个缺点,其中最重要的是它的复杂性。它被定义为在一个特定的交并比(IoU)阈值处检测到的精确召回率曲线下的面积,并具有一个正确分类的标签(GT),平均于所有类别。从COCO[20]开始,mAP超过10个IoU阈值(区间0.05)的平均值成为标准,最终得到mAP0.5:0.95。当我们希望在检测器中分析错误时,这个度量的复杂性带来了一个特殊的挑战,因为错误类型变得相互交织,很难衡量每种错误类型对mAP的影响有多大。
此外,仅对mAP进行优化,我们可能无意中忽略了错误类型的相对重要性,这些错误类型在不同的应用程序中可能会有所不同。例如,在肿瘤检测中,正确的分类可能比边框定位更重要;肿瘤的存在是必要的,但精确的位置可以通过人工纠正。相比之下,精确的定位对于机器人抓取来说是至关重要的,一些轻微的定位误差都会导致错误的结果。理解这些错误来源如何与总体mAP相关,对于设计新模型和为给定任务选择合适的模型至关重要。
因此,为了解决这些问题,我们引入了TIDE,一个用于识别检测和分割错误的通用工具包。我们认为,一个完整的工具箱应该:
- 简明地总结错误类型,以便一目了然地进行比较;
- 充分隔离各错误类型的贡献,不存在影响结论的混杂变量;
- 不需要特定数据的注释,允许数据集之间的比较;
- 结合一个模型的所有预测,因为只考虑一个子集就隐藏了信息;
- 考虑到所需的更精细的分析,以便能够分离出误差的来源。
为什么我们需要一个新的分析工具包. 很多研究都是针对目标检测和实例分割中的误差进行分析的[15,24,7,17,22],但只有少数研究对模型中所有的误差进行了有益的总结[14,1,4],没有一个研究具有上面列出的所有理想特性。
Hoiem等人介绍了基本工作中总结错误目标检测[14],然而他们总结只解释了false positives(false negatives需要单独分析),这取决于hyperparameter N考虑控制有多少错误,因此不履行(4)。此外,为了有效地使用这个总结,这需要扩展到2d绘图,很难解释(见[11,21]中误差分析),因此在实践中仅部分地解决(1)。他们的方法也不能满足(3),因为他们的错误类型需要手动定义超类,这不仅是主观的,而且很难对像LVIS[12]这样有超过1200个类的数据集进行有意义的定义。最后,它只是部分满足(2),因为分类错误的定义,如果检测是错误的定位和错误的分类,它将被认为是错误的分类,限制了分类和定位错误得出的结论的有效性。
COCO评估工具包[1]试图通过根据错误对精确召回曲线的影响来表示错误,从而更新Hoiem等人的工作(从而使它们更接近mAP)。这允许他们一次使用所有的检测结果(4),因为精确召回曲线隐式地根据可信度给每个错误赋予权重。但是,COCO toolkit生成了372个2d图,每个图有7条精确召回曲线,这需要大量的时间来消化,因此很难进行紧凑的比较模型(1)。然而,也许最关键的问题是COCO评估工具逐步计算错误,我们显示这些错误极大地歪曲了每个错误的贡献(2),潜在地导致不正确的结论(见第2.3节)。最后,工具箱需要为COCO特定的手工注释,但其他数据集不一定需要(3)。
作为并发工作,[4]试图找到这些数据集上AP的上限,并在这个过程中解决COCO toolkit的某些问题。然而,这项工作仍然将他们的错误报告建立在与COCO toolkit使用的相同的渐进方案上,这使得他们得出了一个可疑的结论,即背景错误比其他类型的错误重要得多(见图2)。正如后面将详细描述的那样,为了得出可靠的结论,我们的工具包必须致力于分离每种错误类型的贡献(2)。
贡献. 在我们的工作中,我们解决了所有5个目标,并提供了一个紧凑的,但详细的总结目标检测和实例分割中的错误。每一种错误类型都可以用一个有意义的数字(1)表示,这使得它足够紧凑,适合消融表(见表2),包含所有的检测(4),不需要任何额外的注释(3)。我们还根据误差对整体性能的影响来衡量误差,同时小心地避免mAP(2)中出现的混淆因素。虽然我们优先考虑容易解释,但我们的方法是模块化的,同样的错误集可以用于更细粒度的分析(5)。最终的结果是一个紧凑的、有意义的、表达性强的错误集,可以跨模型、数据集甚至任务使用。
我们通过比较最近几个基于cnn的目标检测器和多个数据集的实例分割器来证明我们的方法的价值。我们解释了如何将概述纳入消融研究,以定量地证明设计选择。我们还提供了一个示例,说明如何使用错误摘要来指导更细粒度的分析,以确定模型的特定优势或劣势。
我们希望这个工具箱可以成为未来工作的分析基础,引导模型设计者更好地理解他们当前方法的弱点,并允许未来的作者定量地和紧凑地证明他们的设计选择。为此,完整的工具包代码在https://dbolya.github.io/tide/上发布。开放予社会人士,以供日后发展。
2.工具
目标检测和实例分割主要使用一个指标来判断性能: mean Average Precision (mAP)。而简洁地总结了性能的模型映射在一个数字,从mAP中理清目标检测和实例分割中的错误很困难:一个false positive 可以是重复检测,错误分类,定位错误,与背景混乱,甚至是错误分类和定位错误都有。同样地,false negative可能是完全错过的GT,或者可能正确的预测可能只是分类错误或定位错误。这些错误类型会对mAP产生巨大的不同影响,使得仅使用mAP之外的模型来诊断问题变得非常棘手。
我们可以对所有这些类型的错误进行分类,但并不完全清楚如何衡量它们的相对重要性。Hoiem等人[14]加权 false positives的TOP N最有信心的错误并分开考虑 false negatives。然而,这忽略了许多低评分检测可能产生的影响(因此有效地使用它需要对N进行扩展),并且它不允许比较 false positives和 false negatives。
不过,有一种简单的方法可以确定给定错误对整个mAP的重要性:简单地修复该错误并观察mAP中的结果更改。Hoiem等人简要地探讨了这种方法对某些false positives的影响,但并没有以此为基础进行分析。这也类似于COCO评估工具[1]绘制错误的方式,但有一个关键的区别:COCO的实现是逐步计算错误。也就是说,它在修正一个错误后观察mAP的变化,但在修正下一个错误时保持这些错误不变。这很好,因为最终的结果是100 mAP,但我们发现,以这种方式逐步修正错误是有误导性的,可能会导致错误的结论(见2.3节)。
因此,我们定义错误的方式是,修复所有的错误仍然会得到100 mAP,但是我们从原始模型的性能开始,分别为每个错误赋值。这保留了在计算中包含置信度和false negatives的良好特性,同时保持每种错误类型的大小具有可比性。
2.1 计算mAP
在定义错误类型之前,我们将注意力集中在mAP的定义上,以理解什么可能导致它退化。为了计算mAP,我们首先由检测器给出对每张图像的一个预测列表。然后将图像中的每个ground truth最多匹配一个检测。为了符合正匹配,检测必须与ground truth具有相同的类别,且IoU重叠大于某个阈值tf,除非另有规定,我们将其视为0.5。如果多个检测都是合格的,选择重叠程度最高的为True positives,其余为false positives。
每次检测与GT匹配(真正TP)或不匹配(假正FP),将从数据集中的每张图像中收集所有检测结果,并按降序置信度排序。计算所有检测的累计精度和召回率为:
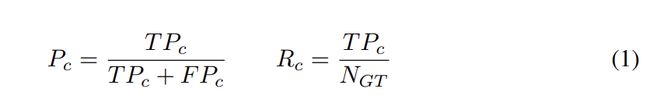
其中,对于所有检测结果的置信度≥c, Pc为准确率,Rc召回率,TPc为 true positives数,FPc为false positives数。NGT为当前类中GT例数。
然后对精度进行插值,使Pc单调下降,AP作为精度召回率曲线下的积分计算(以定长黎曼和近似)。最后,mAP被定义为所有类的平均AP。在COCO[20]的情况下,mAP在0.50到0.95之间的所有IoU阈值上取平均值,步长为0.05,得到mAP0.5:0.95。
2.2 定义错误类型
检查这个计算,我们的检测器可以影响mAP的3个地方:在匹配步骤中输出fp,在计算召回率时不输出tp(即,fn),以及有不正确的校准(即,输出fp的可信度比tp高)。

主要的错误类型. 为了创建捕获mAP组件的有意义的错误分布,我们将模型中所有的fp和fn归类为6种类型之一(见图1)。注意,对于某些错误类型(分类和定位),fp可以与fn配对。我们将使用IoUmax来表示fp的最大IoU与给定类别的ground truth的重叠。前景IoU阈值记为tf,背景阈值记为tb,除非另有说明,分别设置为0.5和0.1(如[14]中所示)。
- 分类错误:对于错误分类的,IoUmax ≥ tf(即定位正确但分类错误)。
- 定位错误:对于正确分类的,tb ≤ IoUmax ≤ tf(即分类正确但定位错误)。
- 分类和定位都错误:对于错误分类的,tb ≤ IoUmax ≤ tf (即分类错误并且定位错误)。
- 重复检测错误:分类正确且GTIoUmax ≥ tf ,但另一个较高得分的检测已经匹配了该GT(即,如果不是有较高得分的检测,则是正确的)。
- 背景错误:对所有的GT都IoUmax ≤ tb(将背景检测为前景)。
- 未检测到GT错误:未被分类或定位错误覆盖的所有未被检测到的ground truth(fn)。
它与[14]有几个重要的区别,首先,我们将sim和other错误合并为一个分类错误,因为Hoiem等人的sim和other要求都有手动注释,但并不是所有数据集都有且可以单独进行区别分析。然后,[14]中的两种分类错误均定义为 IoUmax ≥tb的检测,即使IoUmax ≤ tf。这就混淆了定位和分类错误,因为使用该定义,发现的错误定位和错误分类都被认为是错误分类。因此,我们将这些检测分为它们自己的类别。
加权错误. 仅仅计算每个箱子中错误的数量还不足以对错误类型进行直接比较,因为一个低分数的fp对整体表现的影响要小于一个高分数的fp。Hoiem等人[14]试图通过考虑前N个得分最高的错误来解决这个问题,但在实践中,需要对N进行扫描以获得全图,创建难以解释的2d图形(参见[11,21]的分析)。
理想情况下,我们希望有一个综合的数字来表示每种错误类型如何影响模型的整体性能。换句话说,对于每种类型的错误我们想要问的问题是,这类错误在多大程度上阻碍了我的模型的性能?为了回答这个问题,我们可以考虑模型的性能会是什么,如果它没有犯那个错误,并使用它如何改变mAP。
为此,我们需要为每个错误定义一个相应的oracle来修复该错误。例如,如果一个oracle o ∈ O 描述了如何将一些fp变为tp,我们可以调用应用oracle计算后的AP作为APo,然后将其与普通AP进行比较,以获得oracle(以及相应的错误)对性能的影响:

我们知道我们已经覆盖了模型中所有的错误,如果把所有的oracles放在一起得到100的mAP。换句话说,给定oracles O = {o1, . . . , on}:
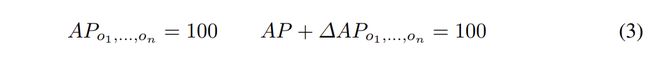
参考第2.1节中AP的定义,为了满足Eq. 3,一起使用的oracles必须修正所有的fp和fn。
考虑到这一点,我们为上面描述的每一种主要错误类型定义了下面的oracles:
- 分类 Oracle:纠正检测的类别(从而使它成为一个tp)。如果通过这种方式进行重复检测,请抑制较低的评分检测。
- 定位Oracle:将检测的定位设置为GT的定位(从而使它成为一个tp)。同样,如果要通过这种方式进行重复检测,请抑制较低的评分检测。
- 分类和定位Oracle:既然我们不能确定检测器试图匹配哪个GT,就抑制fp。
- 重复检测Oracle:禁止重复检测。
- 背景Oracle:抑制错误的背景检测
- 未检测到GTOracle:将mAP计算中的GT (NGT)数量按错过gt的数量减少。这样做的效果是,在较高的召回率下,精确召回曲线会被拉长,本质上就像检测器准确的找到未检测到的GT一样。另一种方法是增加新的检测,但是现在还不清楚新的检测的分数应该是多少,这样它就不会引入混淆变量。我们将在附录中进一步讨论这个选择。
其他错误类型. 虽然前面定义的类型完全解释了模型中的所有错误,但是如何定义错误并不能清楚地描述fp和fn错误(因为分类、定位和未检测到的错误都可以捕获为fn)。在某些情况下,明确划分是有用的,因此对于这些情况,我们通过oracle定义了两种独立的错误类型,并分别对它们进行处理:
- FP Oracle:抑制所有的fp检测。
- FN Oracle:设置NGT为TP检测的数量。
这两个Oracle加在一起就像之前的6个一样,占了100的mAP,但是他们以不同的方式存储错误。
2.3计算错误的限制
请注意,我们小心翼翼地分别计算错误(即,每个∆AP从没有修正错误的普通AP开始)。其他方法[1,4]逐步计算它们的错误(即,每个∆AP从最后一个修正的错误开始,这样修正最后一个错误的结果是100 AP)。虽然我们确保将所有的oracles应用在一起也会产生100 AP,但我们发现,一个渐进的∆AP会错误地表示每个错误类型的权重,并且强烈倾向于最后修正的错误类型。
为了具体说明这一点,我们可以将渐进式错误∆APa|b定义为在已经应用oracle b的情况下应用oracle a时AP的变化:
 然后,逐渐计算错误等于设置错误i的重要性为∆APoi|o1,…,oi−1。这有两个问题:精度的定义包括分母中的fp,这意味着如果您一开始就有更少的fp(就像已经修复了大多数fp的情况一样),精度的变化将会更高。此外,召回中的任何变化(例如修正定位或分类错误)都会放大mAP上的精度效果,因为积分现在有了更多的面积。
然后,逐渐计算错误等于设置错误i的重要性为∆APoi|o1,…,oi−1。这有两个问题:精度的定义包括分母中的fp,这意味着如果您一开始就有更少的fp(就像已经修复了大多数fp的情况一样),精度的变化将会更高。此外,召回中的任何变化(例如修正定位或分类错误)都会放大mAP上的精度效果,因为积分现在有了更多的面积。

如图2所示,图2a是原始的COCO评估PR曲线,图2b只是互换了计算背景和分类误差的顺序。仅仅首先计算背景就会导致其贡献的发生率惊人地下降(由阴影区域的面积给出),这意味着背景误差的真实权重很可能比COCO评估报告的要小得多。这使得通过这种方式进行的分析很难得出事实的结论。
此外,逐渐的计算错误没有直观的意义。当使用这些错误时,您将试图逐个解决它们,一次一个。永远不会有机会纠正所有的定位错误,然后开始处理分类错误,改进后的方法总会在每个类别中留下一定的误差,所以观察APa|b是没有用的,因为没有从APb开始的状态。
由于这些原因,我们完全避免了逐步计算错误。
3.分析
在本节中,我们通过提供跨各种目标检测和实例分割模型以及跨不同数据和注释集的详细分析,来演示分析工具箱的通用性和实用性。我们还比较了基于GT的常规性质的误差,例如物体大小,并找到了一些有用的见解。为了进一步解释复杂的错误情况,我们对某些错误类型提供了更细粒度的分析。本文中使用的所有分析模式都可以在我们的工具箱中找到。
模型. 基于它们的普遍性和/或独特性,我们选择了各种目标检测器和实例分割器,这使我们能够研究不同方法之间的性能权衡,并得出一些见解。我们使用Mask R-CNN[13]作为我们的基线,因为许多其他方法都建立在标准的R-CNN框架之上。另外我们还包括了三种这样的模型:Hybrid Task Cascades(HTC)[5]、TridentNet[18]和Mask Scoring R-CNN (MS-RCNN)[13]。我们选择HTC是因为其强劲的表现,获得了2018年COCO挑战赛的冠军。我们引入TridentNet[18],因为它特别关注于增加尺度不变性。最后,我们将MS R-CNN作为一种专门专注于修复基于校准的误差的方法。与 two-stage R-CNN风格的方法不同,我们还包括了三种 one-stage的方法,YOLACT/YOLACT++[3,2]来代表实时模型,RetinaNet[19]作为一个强大的anchor-based的模型,Fully Convolutional One-Stage目标检测(FCOS)[23]是一种anchor-free的方法。如有可能,我们使用ResNet101作为每个模型的主干。附录中给出了确切的模型。
数据集. 我们在MS-COCO[20]上展示了我们的核心跨模型分析,这是一个广泛使用和活跃的基准测试。此外,我们想展示我们工具箱的力量来执行cross-dataset分析包括三个额外的数据集:Pascal VOC[10]作为一个相对简单的目标检测数据集,Cityscapes[6]提供高分辨率,密集注释图像与许多小目标,和[12]使用与coco相同的图像,但有巨大多样性与1200 + 大部分稀少类别注释对象的LVIS。
3.1验证设计选择
每一个新的目标检测器或实例分割器的作者都会做出他们声称会以不同方式影响模型性能的设计选择。虽然我们的目标几乎总是要增加整体mAP,但仍然存在一个问题:设计选择的直观合理性是否站得住脚?在图3中,我们给出了我们在COCO[20]中考虑的所有目标检测器和实例分割器的错误分布,在本节中,我们将分析每个检测器的错误分布,看看我们的错误是否符合直观的理由。

基于R-CNN的方法. 首先,HTC[5]对Mask R-CNN做了两个主要的改进:1.)迭代地改进预测(即级联),并每次在模型的各个部分之间传递信息,2.)它引入了一个专门用于改进前景示例(看起来像背景)检测的模块。直观上,(1)将显著提高分类和定位,因为预测和用于预测的特征需要经过3次细化。的确,在图4中,对于实例分割和检测来说,HTC的分类和定位错误是我们考虑的模型中最低的。然后,(2)当背景中的某样东西被错误地归类为一个物体时,可能会增加误报,从而引发更高的召回率。而这正是我们的错误所揭示的:HTC的GT误差率最低,而背景误差率最高(不包括YOLACT++,它的错误分布非常独特)。

接下来,TridentNet[18]尝试通过为共享权重的小型、中型和大型目标创建单独的管道来创建尺度不变特征。理想情况下,这将提高不同尺度目标的分类和定位性能。HTC和TridentNet最终都拥有相同的分类和定位性能,因此我们在3.2节中进一步验证了这一假设。因为HTC和TridentNet的设计选择大多是正交的,他们很可能会互相恭维。
One-Stage方法. RetinaNet[19]引入了focal loss,降低置信样本的权重,以便能够在所有背景anchor上进行训练(而不是标准的3负1正的比率)。对所有negatives的训练本身应该会导致模型输出更少的背景误报,但代价是显著降低召回率(因为检测器会偏向于预测背景)。focal loss的目标是训练所有的negatives而不引起额外的漏检。我们观察到这是成功的,因为在图4a中,RetinaNet的背景误差是所有模型中最低的,而与Mask R-CNN相比,漏检的GT误差略少。然后,FCOS[23]作为一个背离传统的anchor-based的模型,在图像的每个位置预测一个新定义的框,而不是回归一个现有的先验。虽然这种设计选择的主要动机是简单,但摆脱anchor还有其他切实的好处。例如,anchor-based的检测器取决于它的先验:如果给定目标没有适用的先验,那么检测器很可能会完全忽略它。另一方面,FCOS对其检测没有基于先验的限制,这使得其漏检误差在我们考虑的所有模型中是最低的(图4a)。 注意,它还具有最高的重复错误,因为它使用的NMS阈值为0.6,而不是通常的0.5。
实时方法. YOLACT[3]是一种实时实例分割方法,它使用一个修改版的RetinaNet作为其主干检测器,没有focal loss。YOLACT++[2]迭代前者,并额外包括掩码评分(在表2中讨论)。从图3中观察误差的分布,可以看出为加速模型所采用的设计选择导致与RetinaNet的误差分布完全不同。观察图4a中的原始大小,这主要是由于YOLACT具有更高的定位和漏检误差。然而,当我们看到实例分割时,情况就不同了,尽管YOLACT的检测器性能很差,但它的定位几乎和mask R-CNN一样好(参见附录)。这证实了他们的说法,即YOLACT更适合制作高质量的mask,其性能可能受到劣质检测器的限制。
消融笔记. 为了演示此工具包在隔离错误贡献和调试方面的潜在有用性,我们将展示如何在仍然紧凑的情况下对错误类型而不是仅对mAP进行消融,从而提供有意义的见解。举个例子,考虑一下基于一个基本gt的iou来重新评估一个mask的置信度的趋势,就像在Mask Scoring R-CNN[16]和YOLACT++[2]。这次修改的目的是提高高质量mask的分数,降低低质量mask的分数,直观上应该可以得到更好的定位。为了证明他们的观点,这两篇论文的作者都提供了定性的例子来证明这种情况,但是限制了对mAP观察到的增加变化的定量支持。不幸的是,单是mAP上的变化并不能说明变化的原因,而且尽管方法有效,一些消融可能在mAP上显示出很少的变化。通过添加错误类型的影响改变消融表(例如,见表2),我们不仅为设计选择提供隐藏在原始增加的mAP中的定量证据,但也显示出副作用(比如分类的误差上升)。

3.2 比较目标属性进行精细分析
为了比较不同目标属性(如比例或高宽比)的性能,典型的方法是在具有指定属性的检测和GT的子集上计算mAP(有效的比较需要归一化的mAP[14])。虽然我们在工具包中提供了这种分析模式,但它并没有描述该属性对总体性能的影响,只是描述模型在该属性上的表现如何。因此,我们提出了一种附加的方法,基于我们先前定义的用于总结错误对整体性能影响的工具:简单地修复错误并像以前一样观察∆mAP,但是只观察那些具有所需属性的相关预测或GT的mAP。
不同尺度的比较. 作为跨不同尺度目标使用此方法的例子,我们回到第3.1节讨论的TridentNet与HTC的案例。这两个模型都有相同的分类和定位错误,如果有的话,我们想知道它们的区别在哪里。由于TridentNet特别关注尺度不变性,我们将注意力转向跨尺度的性能。我们定义像素区域在0到162之间的对象为超小目标(XS), 162到322为小目标(S), 322到962为中目标(M), 962到2882为大目标(L), 2882及以上为超大目标(XL)。在图5中,我们在HTC和TridentNet上应用了我们的方法(包含了mask R-CNN检测以供参考)。通过对比可以看出,TridentNet对于中等大小的对象的定位和分类效果要优于HTC,而HTC对于大型对象的定位和分类效果要优于HTC。这可能是TridentNet的作者发现他们可以通过评估中型对象[18]的分支来实现几乎相同的性能的潜在原因。其他检测子集之间的比较,如不同的长宽比、锚框、FPN层等,也可以使用相同的方法进行。

3.3 不同数据集之间的比较
我们的工具包是不基于特定数据集,允许我们在几个数据集上比较相同的模型,如图6所示,在图6中,我们比较了Mask R-CNN (Faster R-CNN for Pascal)在Pascal VOC[10]、COCO[20]、Cityscapes[6]和LVIS[12]。

在这种比较中,第一个显而易见的模式是,随着标签注释密度的增加,背景错误在总体分布(饼状图)和绝对数量(柱状图)方面都有所减少。LVIS和Cityscapes都有非常密集的注释,几乎没有背景错误。Faster R-CNN在Pascal上被背景错误所主导,但是在COCO上减少了。这可能表明,Pascal和COCO中的大部分背景错误都是由于没有注释的目标造成的(参见第3.4节)。
正如预期的那样,对于像Cityscapes这样被密集注释的数据集来说,漏检GT是一个大问题。Cityscapes的核心挑战是存在许多小物体,众所周知,这些小物体很难用现代算法检测到。另一方面,LVIS面临的挑战是无法正确地对检测结果进行分类,从而丢失了GT,这很可能是由于它有大量的类别和长尾造成的。在fp和fn误差分布(竖条)中,密集标注的数据集偏向于漏检GT的趋势也得到了体现。总的来说,Pascal严重偏向fp,COCO是混合的,LVIS和Cityscapes都偏向fn。请注意,尽管分类错误占主导地位,但LVIS偏向于fn,因为在AP计算中由于LVIS的评估方式,大多数fp都被忽略了,这意味着在LVIS中,您不会因为fp受到同样多的惩罚。
在COCO上,Mask R-CNN在定位Mask(图6b)方面比boxes(图6a)更困难,但LVIS的情况正好相反,可能是因为它的Mask质量更高,[12]专家研究证实了这一点。同样,这可能表明实例分割中的许多错误可能是由错误注释派生的。
3.4 不可避免的误差

我们在第3.3节中发现,许多背景和定位错误可能仅仅是由于错误或未注释的GT。更仔细地研究最上面的错误,我们发现事实上(至少在COCO中),许多最自信的错误实际上是错误地注释或模糊地错误地注释了GT(见图7)。例如,在Mask R-CNN检测中,前100个最有信心的定位错误中,有30个是由于错误的注释造成的,而背景错误的数量则飙升至50个。这些错误都是一些简单的错误,比如把方框弄得太大,或者忘记把方框标记为crowd注释。更多的例子是模棱两可的:应该把一个人体模型或动作玩偶注解为一个人吗?一个猫的雕塑应该被标注为猫吗?一个目标的反射应该被标注为那个对象吗?高度自信的错误会导致整体mAP发生较大的变化,因此错误标注的GT会大大降低一个合理模型所能获得的最大mAP。
这就引出了一个问题,mAP在这些数据集上的上限是多少?现有的对目标检测的潜在上限的分析,如[4],似乎没有解释大量的错误标记的例子。COCO挑战上的SOTA正在慢慢停滞不前,所以也许我们正在接近这些检测器的合理上限。我们把这个留给以后的工作来分析。
4.结论
在这项工作中,我们定义了有意义的错误类型,以及将这些错误类型与总体性能联系起来的方法,从而最小化任何混淆变量。然后我们应用得到的框架来评估设计决策,比较目标属性上的性能,并揭示几个数据集的属性,包括COCO中普遍错误注释的GT。我们希望我们的工具包不仅可以作为在检测中隔离和改进错误的方法,而且还可以导致在设计决策中有更多的可解释性,以及对模型的优缺点有更清晰的描述。
参考
- COCO Analysis Toolkit: http://cocodataset.org/#detection-eval, accessed:
2020-03-01 2, 4, 7 - Bolya, D., Zhou, C., Xiao, F., Lee, Y.J.: Yolact++: Better real-time instance segmentation.
arXiv:1912.06218 (2019) 9, 10, 11 - Bolya, D., Zhou, C., Xiao, F., Lee, Y.J.: Yolact: real-time instance segmentation. In: ICCV
(2019) 9, 11 - Borji, A., Iranmanesh, S.M.: Empirical upper-bound in object detection and more.
arXiv:1911.12451 (2019) 2, 3, 7, 14 - Chen, K., Pang, J., Wang, J., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Shi, J., Ouyang, W.,
et al.: Hybrid task cascade for instance segmentation. In: CVPR (2019) 9, 10 - Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U.,
Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In:
CVPR (2016) 1, 9, 12 - Divvala, S.K., Hoiem, D., Hays, J.H., Efros, A.A., Hebert, M.: An empirical study of context
in object detection. In: CVPR (2009) 2 - Dollar, P., Wojek, C., Schiele, B., Perona, P.: Pedestrian detection: A benchmark. In: CVPR ´
(2009) 1 - Dong, H., Yang, G., Liu, F., Mo, Y., Guo, Y.: Automatic brain tumor detection and segmentation using u-net based fully convolutional networks. In: MIUA (2017) 1
- Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual
object classes (voc) challenge. IJCV (2010) 1, 9, 12 - Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object
detection and semantic segmentation. In: CVPR (2014) 2, 6 - Gupta, A., Dollar, P., Girshick, R.: Lvis: A dataset for large vocabulary instance segmentation.
In: CVPR (2019) 1, 2, 9, 12, 13, 23 - He, K., Gkioxari, G., Dollar, P., Girshick, R.: Mask r-cnn. In: ICCV (2017) ´ 7, 9, 10
- Hoiem, D., Chodpathumwan, Y., Dai, Q.: Diagnosing error in object detectors. In: ECCV
(2012) 2, 4, 5, 6, 11 - Hosang, J., Benenson, R., Schiele, B.: How good are detection proposals, really? In: BMVC
(2014) 2 - Huang, Z., Huang, L., Gong, Y., Huang, C., Wang, X.: Mask scoring r-cnn. In: CVPR (2019)
11 - Kabra, M., Robie, A., Branson, K.: Understanding classifier errors by examining influential
neighbors. In: CVPR (2015) 2 - Li, Y., Chen, Y., Wang, N., Zhang, Z.: Scale-aware trident networks for object detection. In:
ICCV (2019) 9, 10, 12 - Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollar, P.: Focal loss for dense object detection. In: ´
CVPR (2017) 9, 10 - Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollar, P., Zitnick, C.L.: ´
Microsoft coco: Common objects in context. In: ECCV (2014) 1, 4, 9, 12 - Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.: Ssd: Single shot
multibox detector. In: ECCV (2016) 2, 6 - Pepik, B., Benenson, R., Ritschel, T., Schiele, B.: What is holding back convnets for detection?
In: GCPR (2015) 2 - Tian, Z., Shen, C., Chen, H., He, T.: Fcos: Fully convolutional one-stage object detection. In:
ICCV (2019) 9, 10 - Zhu, H., Lu, S., Cai, J., Lee, Q.: Diagnosing state-of-the-art object proposal methods.
arXiv:1507.04512 (2015) 2