把Stream流学透了你也能写出简洁高效的代码,快来点击进来看看吧(建议收藏)
最近刚好有空给大家整理下JDK8的特性,这个在实际开发中的作用也是越来越重了,本文重点讲解下Stream API
文章目录
- Stream API
-
- 1.集合处理数据的弊端
- 2. Steam流式思想概述
- 3. Stream流的获取方式
-
- 3.1 根据Collection获取
- 3.1 通过Stream的of方法
- 4.Stream常用方法介绍
-
- 4.1 forEach
- 4.2 count
- 4.3 filter
- 4.4 limit
- 4.5 skip
- 4.6 map
- 4.7 sorted
- 4.8 distinct
- 4.9 match
- 4.10 find
- 4.11 max和min
- 4.12 reduce方法
- 4.13 map和reduce的组合
- 4.14 mapToInt
- 4.15 concat
- 4.16 综合案例
- 5.Stream结果收集
-
- 5.1 结果收集到集合中
- 5.2 结果收集到数组中
- 5.3 对流中的数据做聚合计算
- 5.4 对流中数据做分组操作
- 5.5 对流中的数据做分区操作
- 5.6 对流中的数据做拼接
- 6. 并行的Stream流
-
- 6.1 串行的Stream流
- 6.2 并行流
-
- 6.2.1 获取并行流
- 6.2.2 并行流操作
- 6.3 并行流和串行流对比
- 6.4 线程安全问题
- 7.Fork/Join框架
-
- 7.1 Fork/Join原理-分治法
- 7.2 Fork/Join原理-工作窃取算法
- 7.3 Fork/Join案例
Stream API
1.集合处理数据的弊端
当我们在需要对集合中的元素进行操作的时候,除了必需的添加,删除,获取外,最典型的操作就是集合遍历,
package com.bobo.jdk.stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class StreamTest01 {
public static void main(String[] args) {
// 定义一个List集合
List<String> list = Arrays.asList("张三","张三丰","成龙","周星驰");
// 1.获取所有 姓张的信息
List<String> list1 = new ArrayList<>();
for (String s : list) {
if(s.startsWith("张")){
list1.add(s);
}
}
// 2.获取名称长度为3的用户
List<String> list2 = new ArrayList<>();
for (String s : list1) {
if(s.length() == 3){
list2.add(s);
}
}
// 3. 输出所有的用户信息
for (String s : list2) {
System.out.println(s);
}
}
}
上面的代码针对与我们不同的需求总是一次次的循环循环循环.这时我们希望有更加高效的处理方式,这时我们就可以通过JDK8中提供的Stream API来解决这个问题了。
Stream更加优雅的解决方案:
package com.bobo.jdk.stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class StreamTest02 {
public static void main(String[] args) {
// 定义一个List集合
List<String> list = Arrays.asList("张三","张三丰","成龙","周星驰");
// 1.获取所有 姓张的信息
// 2.获取名称长度为3的用户
// 3. 输出所有的用户信息
list.stream()
.filter(s->s.startsWith("张"))
.filter(s->s.length() == 3)
.forEach(s->{
System.out.println(s);
});
System.out.println("----------");
list.stream()
.filter(s->s.startsWith("张"))
.filter(s->s.length() == 3)
.forEach(System.out::println);
}
}
上面的SteamAPI代码的含义:获取流,过滤张,过滤长度,逐一打印。代码相比于上面的案例更加的简洁直观
2. Steam流式思想概述
注意:Stream和IO流(InputStream/OutputStream)没有任何关系,请暂时忘记对传统IO流的固有印象!
Stream流式思想类似于工厂车间的“生产流水线”,Stream流不是一种数据结构,不保存数据,而是对数据进行加工
处理。Stream可以看作是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商品。



Stream API能让我们快速完成许多复杂的操作,如筛选、切片、映射、查找、去除重复,统计,匹配和归约。
3. Stream流的获取方式
3.1 根据Collection获取
首先,java.util.Collection 接口中加入了default方法 stream,也就是说Collection接口下的所有的实现都可以通过steam方法来获取Stream流。
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.stream();
Set<String> set = new HashSet<>();
set.stream();
Vector vector = new Vector();
vector.stream();
}
但是Map接口别没有实现Collection接口,那这时怎么办呢?这时我们可以根据Map获取对应的key value的集合。
public static void main(String[] args) {
Map<String,Object> map = new HashMap<>();
Stream<String> stream = map.keySet().stream(); // key
Stream<Object> stream1 = map.values().stream(); // value
Stream<Map.Entry<String, Object>> stream2 = map.entrySet().stream(); // entry
}
3.1 通过Stream的of方法
在实际开发中我们不可避免的还是会操作到数组中的数据,由于数组对象不可能添加默认方法,所有Stream接口中提供了静态方法of
public class StreamTest05 {
public static void main(String[] args) {
Stream<String> a1 = Stream.of("a1", "a2", "a3");
String[] arr1 = {
"aa","bb","cc"};
Stream<String> arr11 = Stream.of(arr1);
Integer[] arr2 = {
1,2,3,4};
Stream<Integer> arr21 = Stream.of(arr2);
arr21.forEach(System.out::println);
// 注意:基本数据类型的数组是不行的
int[] arr3 = {
1,2,3,4};
Stream.of(arr3).forEach(System.out::println);
}
}
4.Stream常用方法介绍
Stream常用方法
Stream流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法:返回值类型不再是 Stream 类型的方法,不再支持链式调用。本小节中,终结方法包括 count 和 forEach 方法。
非终结方法:返回值类型仍然是 Stream 类型的方法,支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
Stream注意事项(重要)
- Stream只能操作一次
- Stream方法返回的是新的流
- Stream不调用终结方法,中间的操作不会执行
4.1 forEach
forEach用来遍历流中的数据的
void forEach(Consumer<? super T> action);
该方法接受一个Consumer接口,会将每一个流元素交给函数处理
public static void main(String[] args) {
Stream.of("a1", "a2", "a3").forEach(System.out::println);;
}
4.2 count
Stream流中的count方法用来统计其中的元素个数的
long count();
该方法返回一个long值,代表元素的个数。
public static void main(String[] args) {
long count = Stream.of("a1", "a2", "a3").count();
System.out.println(count);
}
4.3 filter
filter方法的作用是用来过滤数据的。返回符合条件的数据

可以通过filter方法将一个流转换成另一个子集流
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个Predicate函数式接口参数作为筛选条件
public static void main(String[] args) {
Stream.of("a1", "a2", "a3","bb","cc","aa","dd")
.filter((s)->s.contains("a"))
.forEach(System.out::println);
}
输出:
a1
a2
a3
aa
4.4 limit
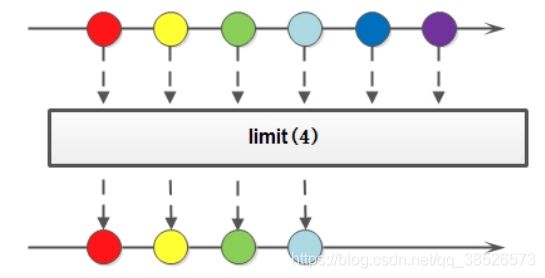
limit方法可以对流进行截取处理,支取前n个数据,
Stream<T> limit(long maxSize);
参数是一个long类型的数值,如果集合当前长度大于参数就进行截取,否则不操作:
public static void main(String[] args) {
Stream.of("a1", "a2", "a3","bb","cc","aa","dd")
.limit(3)
.forEach(System.out::println);
}
输出:
a1
a2
a3
4.5 skip
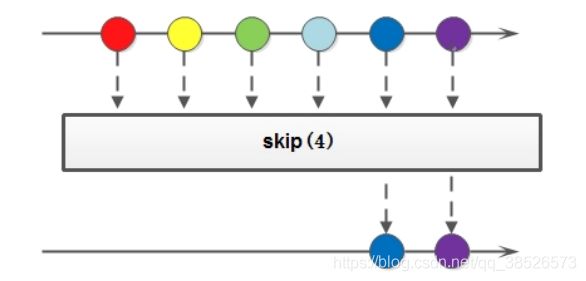
如果希望跳过前面几个元素,可以使用skip方法获取一个截取之后的新流:
Stream<T> skip(long n);
操作:
public static void main(String[] args) {
Stream.of("a1", "a2", "a3","bb","cc","aa","dd")
.skip(3)
.forEach(System.out::println);
}
输出:
bb
cc
aa
dd
4.6 map
如果我们需要将流中的元素映射到另一个流中,可以使用map方法:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
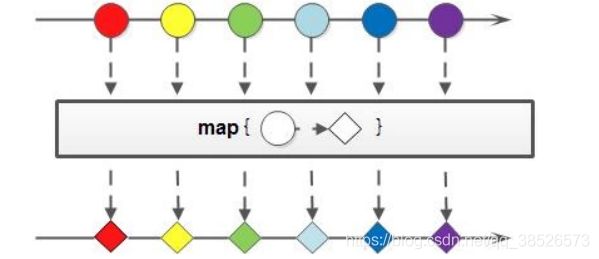
该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的数据
public static void main(String[] args) {
Stream.of("1", "2", "3","4","5","6","7")
//.map(msg->Integer.parseInt(msg))
.map(Integer::parseInt)
.forEach(System.out::println);
}
4.7 sorted
如果需要将数据排序,可以使用sorted方法:
Stream<T> sorted();
在使用的时候可以根据自然规则排序,也可以通过比较强来指定对应的排序规则
public static void main(String[] args) {
Stream.of("1", "3", "2","4","0","9","7")
//.map(msg->Integer.parseInt(msg))
.map(Integer::parseInt)
//.sorted() // 根据数据的自然顺序排序
.sorted((o1,o2)->o2-o1) // 根据比较强指定排序规则
.forEach(System.out::println);
}
4.8 distinct
如果要去掉重复数据,可以使用distinct方法:
Stream<T> distinct();
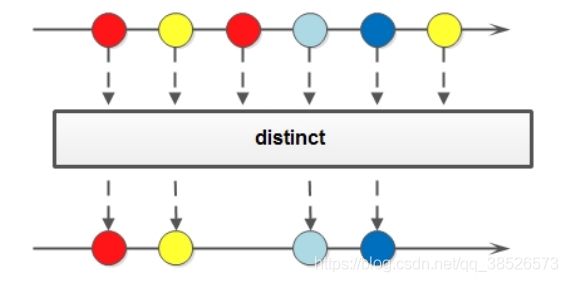
使用:
public static void main(String[] args) {
Stream.of("1", "3", "3","4","0","1","7")
//.map(msg->Integer.parseInt(msg))
.map(Integer::parseInt)
//.sorted() // 根据数据的自然顺序排序
.sorted((o1,o2)->o2-o1) // 根据比较强指定排序规则
.distinct() // 去掉重复的记录
.forEach(System.out::println);
System.out.println("--------");
Stream.of(
new Person("张三",18)
,new Person("李四",22)
,new Person("张三",18)
).distinct()
.forEach(System.out::println);
}
Stream流中的distinct方法对于基本数据类型是可以直接出重的,但是对于自定义类型,我们是需要重写hashCode和equals方法来移除重复元素。
4.9 match
如果需要判断数据是否匹配指定的条件,可以使用match相关的方法
boolean anyMatch(Predicate<? super T> predicate); // 元素是否有任意一个满足条件
boolean allMatch(Predicate<? super T> predicate); // 元素是否都满足条件
boolean noneMatch(Predicate<? super T> predicate); // 元素是否都不满足条件
使用
public static void main(String[] args) {
boolean b = Stream.of("1", "3", "3", "4", "5", "1", "7")
.map(Integer::parseInt)
//.allMatch(s -> s > 0)
//.anyMatch(s -> s >4)
.noneMatch(s -> s > 4)
;
System.out.println(b);
}
注意match是一个终结方法
4.10 find
如果我们需要找到某些数据,可以使用find方法来实现
Optional<T> findFirst();
Optional<T> findAny();
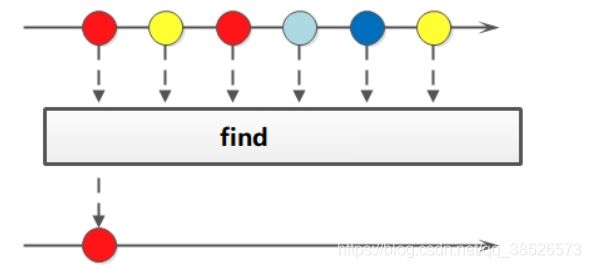
使用:
public static void main(String[] args) {
Optional<String> first = Stream.of("1", "3", "3", "4", "5", "1", "7").findFirst();
System.out.println(first.get());
Optional<String> any = Stream.of("1", "3", "3", "4", "5", "1", "7").findAny();
System.out.println(any.get());
}
4.11 max和min

如果我们想要获取最大值和最小值,那么可以使用max和min方法
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
使用
public static void main(String[] args) {
Optional<Integer> max = Stream.of("1", "3", "3", "4", "5", "1", "7")
.map(Integer::parseInt)
.max((o1,o2)->o1-o2);
System.out.println(max.get());
Optional<Integer> min = Stream.of("1", "3", "3", "4", "5", "1", "7")
.map(Integer::parseInt)
.min((o1,o2)->o1-o2);
System.out.println(min.get());
}
4.12 reduce方法

如果需要将所有数据归纳得到一个数据,可以使用reduce方法
T reduce(T identity, BinaryOperator<T> accumulator);
使用:
public static void main(String[] args) {
Integer sum = Stream.of(4, 5, 3, 9)
// identity默认值
// 第一次的时候会将默认值赋值给x
// 之后每次会将 上一次的操作结果赋值给x y就是每次从数据中获取的元素
.reduce(0, (x, y) -> {
System.out.println("x="+x+",y="+y);
return x + y;
});
System.out.println(sum);
// 获取 最大值
Integer max = Stream.of(4, 5, 3, 9)
.reduce(0, (x, y) -> {
return x > y ? x : y;
});
System.out.println(max);
}
4.13 map和reduce的组合
在实际开发中我们经常会将map和reduce一块来使用
public static void main(String[] args) {
// 1.求出所有年龄的总和
Integer sumAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).map(Person::getAge) // 实现数据类型的转换
.reduce(0, Integer::sum);
System.out.println(sumAge);
// 2.求出所有年龄中的最大值
Integer maxAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).map(Person::getAge) // 实现数据类型的转换,符合reduce对数据的要求
.reduce(0, Math::max); // reduce实现数据的处理
System.out.println(maxAge);
// 3.统计 字符 a 出现的次数
Integer count = Stream.of("a", "b", "c", "d", "a", "c", "a")
.map(ch -> "a".equals(ch) ? 1 : 0)
.reduce(0, Integer::sum);
System.out.println(count);
}
输出结果
87
22
3
4.14 mapToInt
如果需要将Stream中的Integer类型转换成int类型,可以使用mapToInt方法来实现

使用
public static void main(String[] args) {
// Integer占用的内存比int多很多,在Stream流操作中会自动装修和拆箱操作
Integer arr[] = {
1,2,3,5,6,8};
Stream.of(arr)
.filter(i->i>0)
.forEach(System.out::println);
System.out.println("---------");
// 为了提高程序代码的效率,我们可以先将流中Integer数据转换为int数据,然后再操作
IntStream intStream = Stream.of(arr)
.mapToInt(Integer::intValue);
intStream.filter(i->i>3)
.forEach(System.out::println);
}
4.15 concat
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}
使用:
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("a","b","c");
Stream<String> stream2 = Stream.of("x", "y", "z");
// 通过concat方法将两个流合并为一个新的流
Stream.concat(stream1,stream2).forEach(System.out::println);
}
4.16 综合案例
定义两个集合,然后在集合中存储多个用户名称。然后完成如下的操作:
- 第一个队伍只保留姓名长度为3的成员
- 第一个队伍筛选之后只要前3个人
- 第二个队伍只要姓张的成员
- 第二个队伍筛选之后不要前两个人
- 将两个队伍合并为一个队伍
- 根据姓名创建Person对象
- 打印整个队伍的Person信息
package com.bobo.jdk.stream;
import com.bobo.jdk.lambda.domain.Person;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class StreamTest21Demo {
/**
* 1. 第一个队伍只保留姓名长度为3的成员
* 2. 第一个队伍筛选之后只要前3个人
* 3. 第二个队伍只要姓张的成员
* 4. 第二个队伍筛选之后不要前两个人
* 5. 将两个队伍合并为一个队伍
* 6. 根据姓名创建Person对象
* 7. 打印整个队伍的Person信息
* @param args
*/
public static void main(String[] args) {
List<String> list1 = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子", "洪七 公");
List<String> list2 = Arrays.asList("古力娜扎", "张无忌", "张三丰", "赵丽颖", "张二狗", "张天爱", "张三");
// 1. 第一个队伍只保留姓名长度为3的成员
// 2. 第一个队伍筛选之后只要前3个人
Stream<String> stream1 = list1.stream().filter(s -> s.length() == 3).limit(3);
// 3. 第二个队伍只要姓张的成员
// 4. 第二个队伍筛选之后不要前两个人
Stream<String> stream2 = list2.stream().filter(s -> s.startsWith("张")).skip(2);
// 5. 将两个队伍合并为一个队伍
// 6. 根据姓名创建Person对象
// 7. 打印整个队伍的Person信息
Stream.concat(stream1,stream2)
//.map(n-> new Person(n))
.map(Person::new)
.forEach(System.out::println);
}
}
输出结果:
Person{
name='宋远桥', age=null, height=null}
Person{
name='苏星河', age=null, height=null}
Person{
name='张二狗', age=null, height=null}
Person{
name='张天爱', age=null, height=null}
Person{
name='张三', age=null, height=null}
5.Stream结果收集
5.1 结果收集到集合中
/**
* Stream结果收集
* 收集到集合中
*/
@Test
public void test01(){
// Stream stream = Stream.of("aa", "bb", "cc");
List<String> list = Stream.of("aa", "bb", "cc","aa")
.collect(Collectors.toList());
System.out.println(list);
// 收集到 Set集合中
Set<String> set = Stream.of("aa", "bb", "cc", "aa")
.collect(Collectors.toSet());
System.out.println(set);
// 如果需要获取的类型为具体的实现,比如:ArrayList HashSet
ArrayList<String> arrayList = Stream.of("aa", "bb", "cc", "aa")
//.collect(Collectors.toCollection(() -> new ArrayList<>()));
.collect(Collectors.toCollection(ArrayList::new));
System.out.println(arrayList);
HashSet<String> hashSet = Stream.of("aa", "bb", "cc", "aa")
.collect(Collectors.toCollection(HashSet::new));
System.out.println(hashSet);
}
输出:
[aa, bb, cc, aa]
[aa, bb, cc]
[aa, bb, cc, aa]
[aa, bb, cc]
5.2 结果收集到数组中
Stream中提供了toArray方法来将结果放到一个数组中,返回值类型是Object[],如果我们要指定返回的类型,那么可以使用另一个重载的toArray(IntFunction f)方法
/**
* Stream结果收集到数组中
*/
@Test
public void test02(){
Object[] objects = Stream.of("aa", "bb", "cc", "aa")
.toArray(); // 返回的数组中的元素是 Object类型
System.out.println(Arrays.toString(objects));
// 如果我们需要指定返回的数组中的元素类型
String[] strings = Stream.of("aa", "bb", "cc", "aa")
.toArray(String[]::new);
System.out.println(Arrays.toString(strings));
}
5.3 对流中的数据做聚合计算
当我们使用Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作,比如获得最大值,最小值,求和,平均值,统计数量。
/**
* Stream流中数据的聚合计算
*/
@Test
public void test03(){
// 获取年龄的最大值
Optional<Person> maxAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.maxBy((p1, p2) -> p1.getAge() - p2.getAge()));
System.out.println("最大年龄:" + maxAge.get());
// 获取年龄的最小值
Optional<Person> minAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.minBy((p1, p2) -> p1.getAge() - p2.getAge()));
System.out.println("最新年龄:" + minAge.get());
// 求所有人的年龄之和
Integer sumAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
)
//.collect(Collectors.summingInt(s -> s.getAge()))
.collect(Collectors.summingInt(Person::getAge))
;
System.out.println("年龄总和:" + sumAge);
// 年龄的平均值
Double avgAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).collect(Collectors.averagingInt(Person::getAge));
System.out.println("年龄的平均值:" + avgAge);
// 统计数量
Long count = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).filter(p->p.getAge() > 18)
.collect(Collectors.counting());
System.out.println("满足条件的记录数:" + count);
}
5.4 对流中数据做分组操作
当我们使用Stream流处理数据后,可以根据某个属性将数据分组
/**
* 分组计算
*/
@Test
public void test04(){
// 根据账号对数据进行分组
Map<String, List<Person>> map1 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.groupingBy(Person::getName));
map1.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v));
System.out.println("-----------");
// 根据年龄分组 如果大于等于18 成年否则未成年
Map<String, List<Person>> map2 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.groupingBy(p -> p.getAge() >= 18 ? "成年" : "未成年"));
map2.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v));
}
输出结果:
k=李四 v=[Person{name='李四', age=22, height=177}, Person{name='李四', age=15, height=166}]
k=张三 v=[Person{name='张三', age=18, height=175}, Person{name='张三', age=14, height=165}, Person{name='张三', age=19, height=182}]
-----------
k=未成年 v=[Person{name='张三', age=14, height=165}, Person{name='李四', age=15, height=166}]
k=成年 v=[Person{name='张三', age=18, height=175}, Person{name='李四', age=22, height=177}, Person{name='张三', age=19, height=182}]
多级分组: 先根据name分组然后根据年龄分组
/**
* 分组计算--多级分组
*/
@Test
public void test05(){
// 先根据name分组,然后根据age(成年和未成年)分组
Map<String,Map<Object,List<Person>>> map = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.groupingBy(
Person::getName
,Collectors.groupingBy(p->p.getAge()>=18?"成年":"未成年"
)
));
map.forEach((k,v)->{
System.out.println(k);
v.forEach((k1,v1)->{
System.out.println("\t"+k1 + "=" + v1);
});
});
}
输出结果:
李四
未成年=[Person{name='李四', age=15, height=166}]
成年=[Person{name='李四', age=22, height=177}]
张三
未成年=[Person{name='张三', age=14, height=165}]
成年=[Person{name='张三', age=18, height=175}, Person{name='张三', age=19, height=182}]
5.5 对流中的数据做分区操作
Collectors.partitioningBy会根据值是否为true,把集合中的数据分割为两个列表,一个true列表,一个false列表
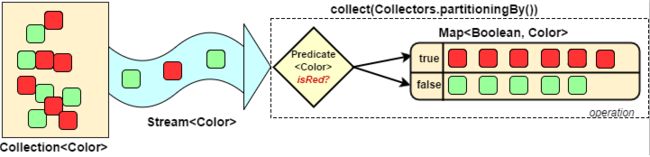
/**
* 分区操作
*/
@Test
public void test06(){
Map<Boolean, List<Person>> map = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).collect(Collectors.partitioningBy(p -> p.getAge() > 18));
map.forEach((k,v)-> System.out.println(k+"\t" + v));
}
输出结果:
false [Person{name='张三', age=18, height=175}, Person{name='张三', age=14, height=165}, Person{name='李四', age=15, height=166}]
true [Person{name='李四', age=22, height=177}, Person{name='张三', age=19, height=182}]
5.6 对流中的数据做拼接
Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
/**
* 对流中的数据做拼接操作
*/
@Test
public void test07(){
String s1 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).map(Person::getName)
.collect(Collectors.joining());
// 张三李四张三李四张三
System.out.println(s1);
String s2 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).map(Person::getName)
.collect(Collectors.joining("_"));
// 张三_李四_张三_李四_张三
System.out.println(s2);
String s3 = Stream.of(
new Person("张三", 18, 175)
, new Person("李四", 22, 177)
, new Person("张三", 14, 165)
, new Person("李四", 15, 166)
, new Person("张三", 19, 182)
).map(Person::getName)
.collect(Collectors.joining("_", "###", "$$$"));
// ###张三_李四_张三_李四_张三$$$
System.out.println(s3);
}
6. 并行的Stream流
6.1 串行的Stream流
我们前面使用的Stream流都是串行,也就是在一个线程上面执行。
/**
* 串行流
*/
@Test
public void test01(){
Stream.of(5,6,8,3,1,6)
.filter(s->{
System.out.println(Thread.currentThread() + "" + s);
return s > 3;
}).count();
}
输出:
Thread[main,5,main]5
Thread[main,5,main]6
Thread[main,5,main]8
Thread[main,5,main]3
Thread[main,5,main]1
Thread[main,5,main]6
6.2 并行流
parallelStream其实就是一个并行执行的流,它通过默认的ForkJoinPool,可以提高多线程任务的速度。
6.2.1 获取并行流
我们可以通过两种方式来获取并行流。
- 通过List接口中的parallelStream方法来获取
- 通过已有的串行流转换为并行流(parallel)
实现:
/**
* 获取并行流的两种方式
*/
@Test
public void test02(){
List<Integer> list = new ArrayList<>();
// 通过List 接口 直接获取并行流
Stream<Integer> integerStream = list.parallelStream();
// 将已有的串行流转换为并行流
Stream<Integer> parallel = Stream.of(1, 2, 3).parallel();
}
6.2.2 并行流操作
/**
* 并行流操作
*/
@Test
public void test03(){
Stream.of(1,4,2,6,1,5,9)
.parallel() // 将流转换为并发流,Stream处理的时候就会通过多线程处理
.filter(s->{
System.out.println(Thread.currentThread() + " s=" +s);
return s > 2;
}).count();
}
效果
Thread[main,5,main] s=1
Thread[ForkJoinPool.commonPool-worker-2,5,main] s=9
Thread[ForkJoinPool.commonPool-worker-6,5,main] s=6
Thread[ForkJoinPool.commonPool-worker-13,5,main] s=2
Thread[ForkJoinPool.commonPool-worker-9,5,main] s=4
Thread[ForkJoinPool.commonPool-worker-4,5,main] s=5
Thread[ForkJoinPool.commonPool-worker-11,5,main] s=1
6.3 并行流和串行流对比
我们通过for循环,串行Stream流,并行Stream流来对500000000亿个数字求和。来看消耗时间
package com.bobo.jdk.res;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.stream.LongStream;
public class Test03 {
private static long times = 500000000;
private long start;
@Before
public void befor(){
start = System.currentTimeMillis();
}
@After
public void end(){
long end = System.currentTimeMillis();
System.out.println("消耗时间:" + (end - start));
}
/**
* 普通for循环 消耗时间:138
*/
@Test
public void test01(){
System.out.println("普通for循环:");
long res = 0;
for (int i = 0; i < times; i++) {
res += i;
}
}
/**
* 串行流处理
* 消耗时间:203
*/
@Test
public void test02(){
System.out.println("串行流:serialStream");
LongStream.rangeClosed(0,times)
.reduce(0,Long::sum);
}
/**
* 并行流处理 消耗时间:84
*/
@Test
public void test03(){
LongStream.rangeClosed(0,times)
.parallel()
.reduce(0,Long::sum);
}
}
通过案例我们可以看到parallelStream的效率是最高的。
Stream并行处理的过程会分而治之,也就是将一个大的任务切分成了多个小任务,这表示每个任务都是一个线程操作。
6.4 线程安全问题
在多线程的处理下,肯定会出现数据安全问题。如下:
@Test
public void test01(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(i);
}
System.out.println(list.size());
List<Integer> listNew = new ArrayList<>();
// 使用并行流来向集合中添加数据
list.parallelStream()
//.forEach(s->listNew.add(s));
.forEach(listNew::add);
System.out.println(listNew.size());
}
运行效果:
839
或者直接抛异常
java.lang.ArrayIndexOutOfBoundsException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at java.util.concurrent.ForkJoinTask.getThrowableException(ForkJoinTask.java:598)
....
Caused by: java.lang.ArrayIndexOutOfBoundsException: 366
at java.util.ArrayList.add(ArrayList.java:463)
针对这个问题,我们的解决方案有哪些呢?
- 加同步锁
- 使用线程安全的容器
- 通过Stream中的toArray/collect操作
实现:
/**
* 加同步锁
*/
@Test
public void test02(){
List<Integer> listNew = new ArrayList<>();
Object obj = new Object();
IntStream.rangeClosed(1,1000)
.parallel()
.forEach(i->{
synchronized (obj){
listNew.add(i);
}
});
System.out.println(listNew.size());
}
/**
* 使用线程安全的容器
*/
@Test
public void test03(){
Vector v = new Vector();
Object obj = new Object();
IntStream.rangeClosed(1,1000)
.parallel()
.forEach(i->{
synchronized (obj){
v.add(i);
}
});
System.out.println(v.size());
}
/**
* 将线程不安全的容器转换为线程安全的容器
*/
@Test
public void test04(){
List<Integer> listNew = new ArrayList<>();
// 将线程不安全的容器包装为线程安全的容器
List<Integer> synchronizedList = Collections.synchronizedList(listNew);
Object obj = new Object();
IntStream.rangeClosed(1,1000)
.parallel()
.forEach(i->{
synchronizedList.add(i);
});
System.out.println(synchronizedList.size());
}
/**
* 我们还可以通过Stream中的 toArray方法或者 collect方法来操作
* 就是满足线程安全的要求
*/
@Test
public void test05(){
List<Integer> listNew = new ArrayList<>();
Object obj = new Object();
List<Integer> list = IntStream.rangeClosed(1, 1000)
.parallel()
.boxed()
.collect(Collectors.toList());
System.out.println(list.size());
}
7.Fork/Join框架
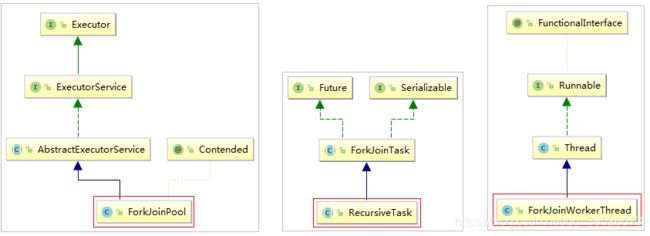
parallelStream使用的是Fork/Join框架。Fork/Join框架自JDK 7引入。Fork/Join框架可以将一个大任务拆分为很多小任务来异步执行。 Fork/Join框架主要包含三个模块:
- 线程池:ForkJoinPool
- 任务对象:ForkJoinTask
- 执行任务的线程:ForkJoinWorkerThread
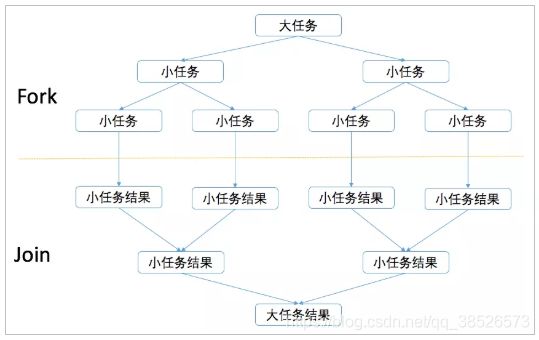
7.1 Fork/Join原理-分治法
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
7.2 Fork/Join原理-工作窃取算法
Fork/Join最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个Fork/Join框架的核心理念Fork/Join工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
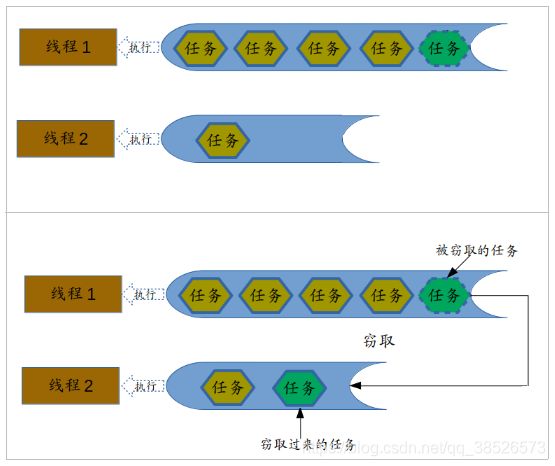
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,
比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。上文中已经提到了在Java 8引入了自动并行化的概念。它能够让一部分Java代码自动地以并行的方式执行,也就是我们使用了ForkJoinPool的ParallelStream。
对于ForkJoinPool通用线程池的线程数量,通常使用默认值就可以了,即运行时计算机的处理器数量。可以通过设置系统属性:java.util.concurrent.ForkJoinPool.common.parallelism=N (N为线程数量),来调整ForkJoinPool的线程数量,可以尝试调整成不同的参数来观察每次的输出结果。
7.3 Fork/Join案例
需求:使用Fork/Join计算1-10000的和,当一个任务的计算数量大于3000的时候拆分任务。数量小于3000的时候就计算

案例的实现
package com.bobo.jdk.res;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class Test05 {
/**
* 使用Fork/Join计算1-10000的和,
* 当一个任务的计算数量大于3000的时候拆分任务。
* 数量小于3000的时候就计算
* @param args
*/
public static void main(String[] args) {
long start = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
SumRecursiveTask task = new SumRecursiveTask(1,10000l);
Long result = pool.invoke(task);
System.out.println("result="+result);
long end = System.currentTimeMillis();
System.out.println("总的耗时:" + (end-start));
}
}
class SumRecursiveTask extends RecursiveTask<Long>{
// 定义一个拆分的临界值
private static final long THRESHOLD = 3000l;
private final long start;
private final long end;
public SumRecursiveTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end -start;
if(length <= THRESHOLD){
// 任务不用拆分,可以计算
long sum = 0;
for(long i=start ; i <= end ;i++){
sum += i;
}
System.out.println("计算:"+ start+"-->" + end +",的结果为:" + sum);
return sum;
}else{
// 数量大于预定的数量,那说明任务还需要继续拆分
long middle = (start+end)/2;
System.out.println("拆分:左边 " + start+"-->" + middle+", 右边" + (middle+1) + "-->" + end);
SumRecursiveTask left = new SumRecursiveTask(start, middle);
left.fork();
SumRecursiveTask right = new SumRecursiveTask(middle + 1, end);
right.fork();
return left.join()+right.join();
}
}
}
输出结果:
拆分:左边 1-->5000, 右边5001-->10000
拆分:左边 5001-->7500, 右边7501-->10000
拆分:左边 1-->2500, 右边2501-->5000
计算:1-->2500,的结果为:3126250
计算:5001-->7500,的结果为:15626250
计算:2501-->5000,的结果为:9376250
计算:7501-->10000,的结果为:21876250
result=50005000
总的耗时:19
~好了,Stream流的内容就介绍到这儿,如果对你有帮助,欢迎点赞关注加收藏哦 V_V