面试中的网红虚拟DOM,你知多少呢?深入解读diff算法

深入浅出虚拟DOM和diff算法
- 一、虚拟DOM(Vitual DOM)
-
- 1、虚拟DOM(Vitual DOM)和diff的关系
- 2、真实DOM的渲染过程
- 3、虚拟DOM是什么?
- 4、解决方案 - vdom
-
- (1)问题引出
- (2)vdom如何解决问题:将真实DOM转为JS对象的计算
- 5、用JS模拟一个DOM结构
- 6、通过snabbdom学习vdom
-
- (1)snabbdom是什么
- (2)snabbdom浅析
- (2)snabbdom演示
- 7、vdom总结
- 二、diff算法
-
- 1、diff算法
- 2、diff算法概述
- 3、树diff的时间复杂度O(n3)
- 4、优化时间复杂度到O(n)
- 三、深入diff算法源码
-
- 1、生成vnode
- 2、patch函数
- 3、patchVnode函数
- 4、updateChildren函数
- 四、结束语
众所周知,在前端的面试中,面试官非常爱考vdom和diff算法。比如,可能会出现在以下场景
滴滴滴,面试官发来一个面试邀请。接受邀请
面试官:你知道 key 的作用吗?
我:key 的作用是保证数据的唯一性。
面试官:怎么保证数据的唯一性?
我:就…
面试官:你知道虚拟dom吗?
我:虚拟dom就是……balabala
面试官:(好像有点道理)那你知道diff算法吗?
我:(心里:what……diff算法是什么??)
面试官:本次面试结束,回去等面试结果通知。
我们都知道, key 的作用在前端的面试是一道很普遍的题目,但是呢,很多时候我们都只浮于知识的表面,而没有去深挖其原理所在,这个时候我们的竞争力就在这被拉下了。所以呢,深入学习原理对于提升自身的核心竞争力是一个必不可少的过程。
在接下来的这篇文章中,我们将讲解面试中很爱考的虚拟DOM以及其背后的diff算法。
一、虚拟DOM(Vitual DOM)
1、虚拟DOM(Vitual DOM)和diff的关系
我们都知道 DOM 操作是非常耗费性能的,早期我们用 JQuery 来自行控制 DOM 操作的时机,也就是手动调整,这样子其实也不是特别方便。因此就出现了虚拟 DOM ,即 Vitual DOM (下文简称为 vdom ),来解决 DOM 操作的问题。 vdom 是现如今的一个热门话题,也是面试中的热门话题,基本上在前端的面试中都会问到 虚拟DOM 的问题。
而为什么会问到 vdom 的问题呢,原因在于现在流行的 vue 和 react 框架,都是数据驱动视图,并且是基于 vdom 实现的,可以说 vdom 是实现 vue 和 react 的重要基石。
谈到 vdom ,我们不明觉厉的还会想到 diff算法 。那 diff算法 和 vdom 是什么关系呢?
其实, vdom 是一个大的概念,而 diff算法 是 vdom 的一部分, vdom 的核心价值在于最大程度的减少DOM的使用范围, vdom 通过把 DOM 用JS的方式进行模拟,之后进行计算和对比,最后找出最小的更新范围去更新。那么这个对比的过程就是 diff 算法 。也就是说他们两者是包含关系,如下图所示:
可以说,diff 算法是 vdom 中最核心、最关键的部分,整个 vdom 的核心包围着大量的 diff算法 。
有了这几个概念的基础铺垫,接下来我们来开始了解 虚拟DOM 是什么。
2、真实DOM的渲染过程
在开始讲解 虚拟DOM 之前,我们先来了解真实的 DOM 在浏览器中是怎么解析的。浏览器渲染引擎工作流程大致分为以下4个步骤:
创建DOM树 → 创建CSSOM树 → 生成render树 → 布局render树 → 绘制render树 。
- 第一步:创建
DOM树。渲染引擎首先解析HTML代码,并生成DOM树。 - 第二步:创建
CSSOM树。浏览为获得外部css文件的数据后,就会像构建DOM树一样开始构建CSSOM树,这个过程与第一步没什么差别。 - 第三步:生成
Render树。将DOM树和CSSOM树关联起来,生成一棵Render(渲染)树。 - 第四步:布局
Render树。有了Render树之后,浏览器开始对渲染树的每个节点进行布局处理,确定其在屏幕上的显示位置。 - 第五步:绘制
Render树。将每个节点绘制到屏幕上。
引用网上的一张图来呈现真实DOM的渲染过程:

3、虚拟DOM是什么?
当用原生 js 或者 jq 去操作真实 DOM 的时候,浏览器会从构建DOM树开始,从头到尾执行一遍流程。那这样的话,就很有可能导致操作次数过多。当操作次数过多时,之前计算的与 DOM 节点相关的坐标值等各种值就…不知不觉的浪费掉了其性能,因此呢,虚拟DOM由此产生。
4、解决方案 - vdom
(1)问题引出
大家都知道, DOM 树是具有一定的复杂度的,所以,在生成 DOM 树的过程中,会不断的进行计算操作,但难就难在,想要减少计算次数其实还是比较难的。
那换个思路考虑,我们都知道,JS 的执行速度很快很快,那能不能尝试着把这个计算,更多的转为JS计算呢?答案是肯定的。
(2)vdom如何解决问题:将真实DOM转为JS对象的计算
假设在一次操作中有1000个节点需要更新 DOM ,那么 虚拟DOM 不会立即去 操作DOM ,而是将这1000次更新的 diff 内容保存到本地的一个 JS 对象当中,之后将这个 JS对象一次性 attach 到 DOM 树上,最后再进行后续的操作,这样子就避免了大量没有必要的计算。
所以,用JS对象模拟DOM节点的好处是,先将页面的更新全部反映到虚拟 DOM 上,这样子就先**操作内存中的JS对象**。值得注意的是,操作内存中 JS 对象的速度是相当快的。因此,等到全部 DOM节点 更新完成之后,再将 最后的JS对象 映射到 真实的DOM 上,交由 浏览器 去绘制。
这样,就解决了真实 DOM 渲染速度慢,性能消耗大的问题。
5、用JS模拟一个DOM结构
根据下方的 html 代码,用 v-node 模拟出该 html 代码的 DOM 结构。
html代码:
<div id="div1" class="container">
<p>
vdom
p>
<ul style="font-size:20px;">
<li>ali>
ul>
div>
用JS模拟出以上代码的DOM结构:
{
tag: 'div',
props:{
className: 'container',
id: 'div1'
},
children: [
{
tag: 'p',
chindren: 'vdom'
},
{
tag: 'ul',
props:{
style: 'font-size: 20px' },
children: [
{
tag: 'li',
children: 'a'
}
// ....
]
}
]
}
通过以上代码我们可以分析出,我们用 tag , props 和 children 来模拟 DOM 树结构。用 JS 模拟 DOM 树的结构,这样做的好处在于,可以计算出最小的变更,操作最少的DOM。
6、通过snabbdom学习vdom
vue 的 vdom 和 diff算法 是参考 github 上的一个开源库 snabbdom 改造过来的,那么我们接下来就用这个库为例,来学习 vdom 的思想。
(1)snabbdom是什么
snabbdom是一个简洁又强大的vdom库,易学易用;Vue参考它实现的vdom和diff;Vue3.0重写了vdom的代码,优化了性能。
(2)snabbdom浅析
我们先来看 snabbdom 首页上的 example ,先简单了解其思想。下面先贴上代码:
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h,
} from "snabbdom";
const patch = init([
// Init patch function with chosen modules
classModule, // makes it easy to toggle classes
propsModule, // for setting properties on DOM elements
styleModule, // handles styling on elements with support for animations
eventListenersModule, // attaches event listeners
]);
const container = document.getElementById("container");
//h函数输入一个标签,之后再输入一个data,最周输入一个子元素
const vnode = h("div#container.two.classes", {
on: {
click: someFn } }, [
h("span", {
style: {
fontWeight: "bold" } }, "This is bold"),
" and this is just normal text",
h("a", {
props: {
href: "/foo" } }, "I'll take you places!"),
]);
//第一个patch函数
// Patch into empty DOM element – this modifies the DOM as a side effect
patch(container, vnode);
const newVnode = h(
"div#container.two.classes",
{
on: {
click: anotherEventHandler } },
[
h(
"span",
{
style: {
fontWeight: "normal", fontStyle: "italic" } },
"This is now italic type"
),
" and this is still just normal text",
h("a", {
props: {
href: "/bar" } }, "I'll take you places!"),
]
);
//第二个patch函数
// Second `patch` invocation
patch(vnode, newVnode); // Snabbdom efficiently updates the old view to the new state
通过官方的例子我们可以知道, h 函数输入一个标签,之后输入一个 data ,最后输入一个子元素。并且h函数是一个 vnode 的结构( vnode 结构见上述第5点),层级般的一层一层递进。最后就是 patch 函数,第一个patch 函数用来对元素进行渲染,第二个 patch 函数用来比较新旧节点。
(2)snabbdom演示
接下来我们用 cdn 的方式引入 snabbdom 的库,来演示一遍 snabbdom 是如何操作 vdom 的。附上代码:
DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Documenttitle>
head>
<body>
<div id="container">div>
<button id="btn-change">changebutton>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-class.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-props.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-style.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/snabbdom-eventlisteners.js">script>
<script src="https://cdn.bootcss.com/snabbdom/0.7.3/h.js">script>
<script>
const snabbdom = window.snabbdom
// 定义 patch
const patch = snabbdom.init([
snabbdom_class,
snabbdom_props,
snabbdom_style,
snabbdom_eventlisteners
])
// 定义 h
const h = snabbdom.h
const container = document.getElementById('container')
// 生成 vnode
const vnode = h('ul#list', {
}, [
h('li.item', {
}, 'Item 1'),
h('li.item', {
}, 'Item 2')
])
patch(container, vnode)
document.getElementById('btn-change').addEventListener('click', () => {
// 生成 newVnode
const newVnode = h('ul#list', {
}, [
h('li.item', {
}, 'Item 1'),
h('li.item', {
}, 'Item B'),
h('li.item', {
}, 'Item 3')
])
patch(vnode, newVnode) // vnode = newVnode → patch 之后,应该用新的覆盖现有的 vnode ,否则每次 change 都是新旧对比
})
script>
body>
html>
此时我们来看浏览器的显示效果:

我们可以看到,最终的效果是当我们点击时, DOM 树不会一整棵树重新渲染,而是只针对改变的值进行重新比较,最终只将改变的节点进行渲染。
通过这样的演示,相信大家对真实 DOM 和虚拟 DOM 的区别有了一定的了解。
7、vdom总结
讲到这里,我们来对vdom做一个总结:
- 可以通过
JS来模拟DOM结构(vnode); - 新旧
vnode对比,得出最小的更新范围,最后更新DOM; - 数据驱动视图的模式下,可以有效地控制DOM操作。
二、diff算法
我们在上述讲 vdom 的时候说过, vdom 的核心价值就在于最大程度的减少DOM的使用范围。那 vdom 是通过什么方式呢,它是通过把 DOM 用 JS 来去模拟,之后进行计算和进行对比,最后找出最小的更新范围去更新。那么这个对比的过程对应的就是我们经常听到的 diff 算法。
接下来就让我们一起来了解 vdom 的另外一个内容, diff 算法。
1、diff算法
-
diff算法是前端的一个热门话题,同时也是
vdom中最核心、最关键的部分。 -
diff算法在日常使用
vue和react中经常出现(如key)。
2、diff算法概述
diff即对比,是一个广泛的概念,如linux diff命令、git diff命令等。- 两个js对象也可以做
diff,如github上的jiff库,这个库可以直接用来给两个js对象做diff。 - 两棵树做
diff,如上述所说的vdom和diff。
我们来看个例子:

看到上面两棵树,我们可以想象下它是如何进行 diff 算法的。我们可以看到,右边这棵树要把左边的 E 改为 X ,同时要新增一个节点 H 。因此如果通过 diff 来实现的话,我们可以对其进行新旧节点的比较,如果比较完一样,则不动它;如果比较完不一样,则对它进行修改。这样处理的话,5个节点只需要修改2次,而不用修改5次,效率很是UpUp。
3、树diff的时间复杂度O(n3)
对于树来说,原始的时间复杂度有O(n3)。那么这个 O(n3) 是怎么来的呢?
首先,遍历tree1;其次,遍历tree2;最后,对树进行排序。这样 n*n*n ,就达到了O(n3)。
假设现在有1000个节点要操作,那1000的3次方就1亿次了,因此,树的这个算法不可用。那我们怎么解决呢?继续看下面。
4、优化时间复杂度到O(n)
因为树的时间复杂度是O(n3),因此,我们就想办法,优化其时间复杂度从O(n3)到O(n),以达到操作 vdom 节点,那这个优化过程其实我们所说的 diff 算法。通过 diff 算法,我们可以将时间复杂度从O(n3)优化到O(n)。diff算法的具体思想如下:
- 只比较同一层级,不跨级比较;
tag不相同,则直接删掉重建,不再深度比较;tag和key,两者都相同,则认为是相同节点,不再深度比较。
三、深入diff算法源码
1、生成vnode
我们先来回顾下上面讲的 snabbdom , diff 比较先是在 h 函数里面进行,这个 h 函数输入一个标签,之后输入一个 data ,最后输入一个子元素。并且 h 函数是一个 vnode 的结构,层级般的一层一层递进。最后就是 patch 函数, 第一个patch 函数用来对元素进行渲染,第二个 patch 函数用来比较新旧节点。
接下来我们来看下它是如何生成vnode的。
先克隆一份snabbdom的代码下来,打开 src|h.ts 文件,直接来看 h 函数,具体代码如下:
export function h(sel: string): VNode;
export function h(sel: string, data: VNodeData | null): VNode;
export function h(sel: string, children: VNodeChildren): VNode;
export function h(
sel: string,
data: VNodeData | null,
children: VNodeChildren
): VNode;
export function h(sel: any, b?: any, c?: any): VNode {
let data: VNodeData = {
};
let children: any;
let text: any;
let i: number;
if (c !== undefined) {
if (b !== null) {
data = b;
}
if (is.array(c)) {
children = c;
} else if (is.primitive(c)) {
text = c;
} else if (c && c.sel) {
children = [c];
}
} else if (b !== undefined && b !== null) {
if (is.array(b)) {
children = b;
} else if (is.primitive(b)) {
text = b;
} else if (b && b.sel) {
children = [b];
} else {
data = b;
}
}
if (children !== undefined) {
for (i = 0; i < children.length; ++i) {
if (is.primitive(children[i]))
children[i] = vnode(
undefined,
undefined,
undefined,
children[i],
undefined
);
}
}
if (
sel[0] === "s" &&
sel[1] === "v" &&
sel[2] === "g" &&
(sel.length === 3 || sel[3] === "." || sel[3] === "#")
) {
addNS(data, children, sel);
}
// 返回vnode,这个vnode对应patch下的vnode
return vnode(sel, data, children, text, undefined);
}
我们看到最后一行, h 函数返回的是一个 vnode 函数。之后我们继续找 vnode 的文件,在 src|vnode.ts 文件中。附上最关键部分代码:
export function vnode(
sel: string | undefined,
data: any | undefined,
children: Array<VNode | string> | undefined,
text: string | undefined,
elm: Element | Text | undefined
): VNode {
const key = data === undefined ? undefined : data.key;
// 返回一个对象
// elm表示vnode结构对应的是哪一个DOM元素
// key可以理解为v-for时我们使用的key
return {
sel, data, children, text, elm, key };
}
同样定位到最后一行,大家可以发现, vnode 实际上是返回一个对象。而这个对象里,有6个元素。其中, sel, data, children, text 四个元素对应我们上面讲 vnode 时对应的结构(第一点的第5点)。而 elm 表示 vnode 结构对应的是哪一个 DOM 元素,最后的 key 大家可以理解为是我们使用 v-for 时用的 key ,同时需要注意是, key 不一定只有在 v-for 时可以使用,在定义组件等各种场景时均可使用。
2、patch函数
看完 vnode ,我们来看下如何用patch函数来对比 vnode 。从官方文档中我们可以定位到, patch 函数在 src|init.ts 文件下,我们找到 init.ts 文件。同样,我们定位到 patch 函数部分,具体代码如下:
// 返回一个patch函数
return function patch(oldVnode: VNode | Element, vnode: VNode): VNode {
let i: number, elm: Node, parent: Node;
const insertedVnodeQueue: VNodeQueue = [];
// 执行pre hook,hook 即 DOM 节点的生命周期
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
// 第一个参数不是vnode,是一个DOM元素
if (!isVnode(oldVnode)) {
// 创建一个空的 vnode,关联到这个DOM元素
oldVnode = emptyNodeAt(oldVnode);
}
// 相同的vnode(key 和 sel 都相等)
if (sameVnode(oldVnode, vnode)) {
// vnode进行对比
patchVnode(oldVnode, vnode, insertedVnodeQueue);
}
// 不同的 vnode , 直接删掉重建
else {
elm = oldVnode.elm!;
parent = api.parentNode(elm) as Node;
// 重建
createElm(vnode, insertedVnodeQueue);
if (parent !== null) {
api.insertBefore(parent, vnode.elm!, api.nextSibling(elm));
removeVnodes(parent, [oldVnode], 0, 0);
}
}
for (i = 0; i < insertedVnodeQueue.length; ++i) {
insertedVnodeQueue[i].data!.hook!.insert!(insertedVnodeQueue[i]);
}
for (i = 0; i < cbs.post.length; ++i) cbs.post[i]();
return vnode;
};
阅读以上代码我们可以知道,我们刚开始创建时,第一个参数不是 vnode ,而是一个 DOM 元素,这个时候我们需要先创建一个空的 vnode ,来关联到这个 DOM 元素上。
有了第一个 vnode 之后,我们在第二次 patch 时,就可以对新旧节点进行比较。而新旧节点的比较是先判断 key 和 sel 是否相同,如果相同,则用 pathVNode 函数对新旧节点进行比较。如果是不同的 vnode ,则直接删掉重建。
3、patchVnode函数
上面我们说到了 patchVnode 函数进行新旧节点的比较,下面来对 patchVnode 进行详细剖析。同样在 src|init.ts 文件中,附上patchVnode函数的代码:
function patchVnode(
oldVnode: VNode,
vnode: VNode,
insertedVnodeQueue: VNodeQueue
) {
// 执行prepatch hook
const hook = vnode.data?.hook;
hook?.prepatch?.(oldVnode, vnode);
// 设置vnode.elem
const elm = (vnode.elm = oldVnode.elm)!;
// 旧的 children
const oldCh = oldVnode.children as VNode[];
// 新的children
const ch = vnode.children as VNode[];
// 当新旧节点相等时则返回
if (oldVnode === vnode) return;
// hook 相关
if (vnode.data !== undefined) {
for (let i = 0; i < cbs.update.length; ++i)
cbs.update[i](oldVnode, vnode);
vnode.data.hook?.update?.(oldVnode, vnode);
}
// vnode.text === undefined (vnode.children 一般有值;children和text只能存在一个,不能共存)
if (isUndef(vnode.text)) {
// 新旧vnode都有children
if (isDef(oldCh) && isDef(ch)) {
// updateChildren 两者都有children时要进行对比
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue);
// 新的vnode有chindren,旧的vnode没有children (旧的vnode有text)
} else if (isDef(ch)) {
// 清空旧的vnode的text
if (isDef(oldVnode.text)) api.setTextContent(elm, "");
// 添加children
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue);
// 旧的vnode有children,新的vnode没有children
} else if (isDef(oldCh)) {
// 移除旧vnode的children
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
// 旧的vnode有text
} else if (isDef(oldVnode.text)) {
api.setTextContent(elm, "");
}
// else: vnode.text != undefined (说明 vnode.text 有值,旧的vnode.children 没有值)
} else if (oldVnode.text !== vnode.text) {
// 移除旧vnode的children
if (isDef(oldCh)) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
}
// 设置新的text
api.setTextContent(elm, vnode.text!);
}
hook?.postpatch?.(oldVnode, vnode);
}
阅读以上源码我们可以知道:
(1) 当旧的 vnode 有 text 时,则说明旧的 children 没有值,且新的 vnode 的 text 有值。这个时候我们就把旧的 vnode 的 children 进行删除,删除结束给新的 vnode 设置 text ;
(2) 当新旧节点都有 children 时,我们需要对其进行更新操作,也就是操作 updateChildren 函数。这个我们将在下面进行讲解。
(3) 如果新的 vnode 有 children ,旧的 vnode 没有 children ,则说明旧的 vnode 有 text ,所以此时需要清空旧的 vnode 的 text ,并添加新的 children 上去。
(4) 如果旧的 vnode有 children ,新的 vnode 没有 children ,则移除旧的 vnode 的 children 。
(5) 如果新旧节点都有 text ,则直接把新的 vnode 的 text 值赋值给旧的 vnode 的 text 。
来看下图的呈现:

4、updateChildren函数
上面分析 pathVnode 时我们讲到了用 updateChildren 函数来更新新旧节点的 children 。接下来我们来看下这个函数:
function updateChildren(
parentElm: Node,
oldCh: VNode[],
newCh: VNode[],
insertedVnodeQueue: VNodeQueue
) {
let oldStartIdx = 0;
let newStartIdx = 0;
let oldEndIdx = oldCh.length - 1;
let oldStartVnode = oldCh[0];
let oldEndVnode = oldCh[oldEndIdx];
let newEndIdx = newCh.length - 1;
let newStartVnode = newCh[0];
let newEndVnode = newCh[newEndIdx];
let oldKeyToIdx: KeyToIndexMap | undefined;
let idxInOld: number;
let elmToMove: VNode;
let before: any;
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]; // Vnode might have been moved left
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx];
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx];
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx];
// 开始和开始进行对比
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
// 结束和结束进行对比
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue);
oldEndVnode = oldCh[--oldEndIdx];
newEndVnode = newCh[--newEndIdx];
// 开始和结束做对比
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue);
api.insertBefore(
parentElm,
oldStartVnode.elm!,
api.nextSibling(oldEndVnode.elm!)
);
oldStartVnode = oldCh[++oldStartIdx];
newEndVnode = newCh[--newEndIdx];
// 结束和开始做对比
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue);
api.insertBefore(parentElm, oldEndVnode.elm!, oldStartVnode.elm!);
oldEndVnode = oldCh[--oldEndIdx];
newStartVnode = newCh[++newStartIdx];
// 以上四个都未命中
} else {
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx);
}
// 拿新节点的key,能否对应上oldCh中的某个节点的key
idxInOld = oldKeyToIdx[newStartVnode.key as string];
// 没有对应上
if (isUndef(idxInOld)) {
// New element
api.insertBefore(
parentElm,
createElm(newStartVnode, insertedVnodeQueue),
oldStartVnode.elm!
);
// 对应上了
} else {
// 对应上key的节点
elmToMove = oldCh[idxInOld];
// sel是否相等(sameVnode的条件)
if (elmToMove.sel !== newStartVnode.sel) {
// sel不相等,可能只是key相等;那也没有用,只能重建 New Element
api.insertBefore(
parentElm,
createElm(newStartVnode, insertedVnodeQueue),
oldStartVnode.elm!
);
// sel 相等,key 相等;执行patchVnode函数
} else {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue);
oldCh[idxInOld] = undefined as any;
api.insertBefore(parentElm, elmToMove.elm!, oldStartVnode.elm!);
}
}
newStartVnode = newCh[++newStartIdx];
}
}
if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) {
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
before,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
} else {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}
}
我们先来看两张图:

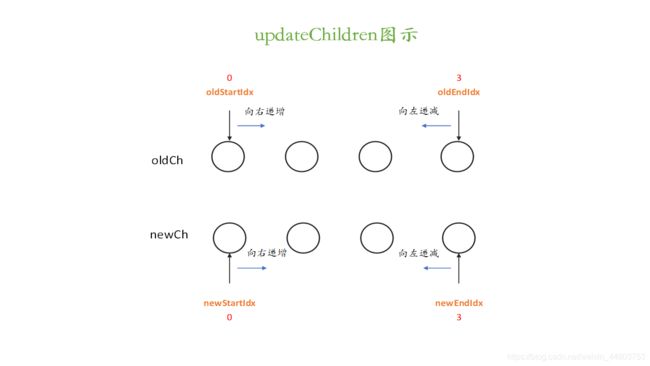
大家先看图1, updateChildren 要做得事情就是,将新旧节点进行对比,如果相同则不进行更新,如果不同则对其进行更新操作。
再看图2,而更新的方式就是,通过对oldStartIdx,newStartIdx,oldEndIdx和newEndIdx这四个值进行比较,来得出是否需要更新操作。
那这四个值如何进行比较呢?接下来我们继续看。
阅读源码我们可以分析出,通过对4种类型的节点进行比较,来判断如何更新节点。
第一种,旧的开始节点 oldStartIdx 和新的开始节点 newStartIdx 比较。第二种,旧的开始节点 oldStartIdx 和新的结束节点 newEndIdx 比较。第三种,旧的结束节点 oldEndIdx 和新的开始节点 newStartIdx 比较。第四种,旧的结束节点 oldEndIdx 和新的结束节点 newEndIdx 比较。
如果以上这四种比较都没有命中,则拿取新节点的key ,之后将这个 key 查看是否对应上 oldCh 中某个节点的 key 。如果没有对应上,则直接重建元素。如果对应上了,还要再判断 sel 和 key 是否相等,如果相等,则执行patchVnode函数,如果不相等,那跟前面一样,也只能重建元素。
四、结束语
vdom的核心概念主要在 h 、 vnode 、 patch 、 diff 、 key 这几个内容,个人觉得,整个 diff 的比较都在围绕着这几个函数进行,所以了解这几个核心概念很重要。同时,vdom存在的另一个更重要的价值莫过于数据驱动视图了, vdom 通过控制 DOM 的操作来使得数据可以去驱动视图。
关于虚拟DOM和diff的讲解到此就结束啦!如有不理解或有误的地方欢迎评论区评论或私信我交流~
- 关注公众号 星期一研究室 ,不定期分享学习干货,学习路上不迷路~
- 如果这篇文章对你有用,记得点个赞加个关注再走哦~