Python网络爬虫基础
已写章节
第一章 网络爬虫入门
第二章 基本库的使用
第三章 解析库的使用
第四章 数据存储
第五章 动态网页的抓取
文章目录
-
-
- 已写章节
-
- 第一章 网络爬虫入门
-
- 1.1 为什么要学习爬虫
-
- 1.1.1 爬虫是什么
- 1.1.2 网络爬虫能干什么
- 1.1.3 能获得什么样的数据
- 1.2 网络爬虫的约束
-
- 1.2.1 网络爬虫的合法性
- 1.2.2 Robots协议
- 1.2.3 网络爬虫约束
- 1.3 爬虫基本知识
-
- 1.3.1 HTTP基本原理
-
- 1.3.1.1 URI和URL
- 1.3.1.2. 超文本
- 1.3.1.3. HTTP和HTTPS
- 1.3.1.4 HTTP请求过程
- 1.3.1.5 请求
-
- 1. 请求方法
- 2. 请求的网址
- 3. 请求头
- 1.3.1.6 响应
-
- 1. 响应状态码
- 2. 响应头
- 3. 响应体
- 1.3.2 Python爬虫爬取网页流程
- 1.3.3 Python爬虫的技术实现
第一章 网络爬虫入门
1.1 为什么要学习爬虫
1.1.1 爬虫是什么
爬虫又被称为网页蜘蛛、网页机器人,爬虫是一种按照一定的规则,自动的抓取互联网信息的程序或脚本。网络爬虫是搜索引擎系统中十分重要的组成部分,它负责从互联网中收集网页,采集信息,这些网页信息用于建立索引,从而为搜索引擎提供支持,它决定了整个搜索引擎的内容是否丰富,信息是否及时,因此爬虫的性能的高低直接决定了搜索引擎的效果。
1.1.2 网络爬虫能干什么
- 兴趣爱好
- 了解竞争对手
- 抓取某个网站或应用中的内容,提取有用的价值
- 提取数据,帮助做出更好的决策
1.1.3 能获得什么样的数据
- 电影排名及详细信息
- 社交媒体的帖子
- 购物网站的商品价格和点评
- 招聘网站的招聘信息
- …
1.2 网络爬虫的约束
1.2.1 网络爬虫的合法性
一般来说,在互联网中展示的信息可以说是公共的,不能被爬取的信息都写在网站的Robots协议中了,但并不代表遵守Robots协议就一定没有问题,爬虫的行为还要“类似人的操作”,不能不限制爬虫的速度。
1.2.2 Robots协议
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。该协议是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应该遵守该协议。
下面是淘宝网的Robots协议:
打开https://www.taobao.com/robots.txt:

京东的robots协议:

1.2.3 网络爬虫约束
爬虫除了要遵守Robots协议外,我们使用网络爬虫时还要对自己进行约束:
-
过于快速的爬取或者爬取频繁都会对服务器造成巨大的压力
-
有些服务器上的数据有产权归属,爬取后用数据来牟利将带来法律风险
-
网络爬虫具有一定的突防能力,使用爬虫获取被保护的数据会导致信息泄露
1.3 爬虫基本知识
1.3.1 HTTP基本原理
1.3.1.1 URI和URL
URI (Uniform Resource Identifier) :统一资源标志符
URL (Universar Resource Locator) : 统一资源定位符
例如:https://github.com/favicon.ico即是一个URl,也是一个URL,即有这样一个图标资源,用URL/URI来唯一指定了它的访问方式,这其中包含了访问协议HTTPS、访问路径(即根目录)和资源名称favicon.ico。通过这个链接,我们就可以在互联网中找到这样一个资源。
url格式:
基本格式如下:
schema://host[:port#]/path/…/[?query-string][#anchor]
schema: 协议(例如:http,https,ftp)
host:服务器的IP或域名
port#:服务器的端口
path:访问资源的路径
query:string参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
下面给个例子:http://localhost:8888/hello
http是协议,localhost是服务器的主机名,8888是端口号,hello是资源的路径
URL是URI的一个子集,也就是说每一个URL都是URI,但不是每一个 URI都是URL,URI还包括一个子类叫做URN(Universal Resource Name),它是统一资源名称:
URN:只命名资源而不指定如何定位资源,比如:
urn:isbn:1203102348
它只是指定了一本书的ISBN,可以唯一标识这本书,但是没有指定到哪里定位这本书
URI包括URL和URN。
现在的URN用得比较少,几乎所有的URI是URL,所以,一般的网页链接可以认为是URI,也可以认为是URL。
1.3.1.2. 超文本
超文本(Hypertext):浏览器里看到的网页就是超文本解析而成的,其网页源代码是一系列的HTML代码,里面包含了一系列的标签,比如:
- img 标签显示图片
- p 标签指定显示段落
- a标签指定链接
浏览器将解析这些标签后,便形成了我们平常看到的网页,而网页的源代码HTML就可以称作超文本。在浏览器中打开任意网页界面,鼠标在任意位置右击,点击“检查”,在弹出的界面上方的选项框中点击“Elements”就可以查看网页的源代码了,那一个个标签就是超文本。
- 查看网页源代码的功能几乎是每一个浏览器必备的功能,前端人员可以利用该功能查看网页效果、找bug。
- 在浏览器中,也使用F12(有些电脑是Fn+F2)快捷键来打开调试界面
- 你学会了这个调试功能,下次遇到某些网页禁止复制网页内容,你想到了解决办法吗?
1.3.1.3. HTTP和HTTPS
在https://www.baidu.com这个链接中,URL的开头会有https或http,这个就是访问资源所需要的协议类型,有时还会看到ftp、sftp、smb开头的URL,这些也是协议类型,常用的协议是HTTP和HTTPS。
HTTP(Hyper Text Transfer Protocol)的中文名字叫超文本传输协议,用于从网络传输超文本数据到本地浏览器的传输协议,能保证高效而准确的传送超文本文档。由万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)共同合作和制定的规范。
HTTPS(Hyper Test Transfer protocol over Secure Socket Layer)是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,简称为HTTPS,安全基础是SSL,因此通过它传输的内容都是经过SSL加密。
HTTPS的主要作用分为两种:
-
建立一个信息安全通道,来保证数据传输的安全
-
确认网站的真实性
越来越多的网站和App都在向HTTPS方向发展,因此,HTTPS流行是大势所趋。
1.3.1.4 HTTP请求过程
在浏览器中输入一个url,回车之后便可以在浏览器中观察到页面内容,这个过程是浏览器向网站所在的服务器发送了一个请求,网站的服务器接收到这个请求后进行处理和解析,然后将对应的响应传回给浏览器。
在浏览器的调试界面查看请求的详细信息:
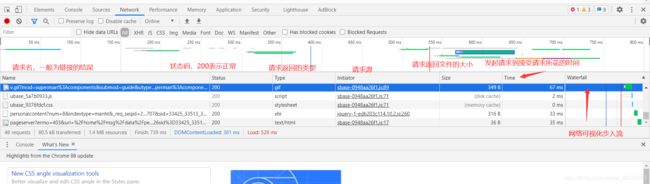
下面是点击请求资源列表中任意一个后展示的更详细的信息,其中包括General(总览),Response Headers(返回头),**Request Headers(请求头)**这三部分。各个部分下都是它的详细信息:
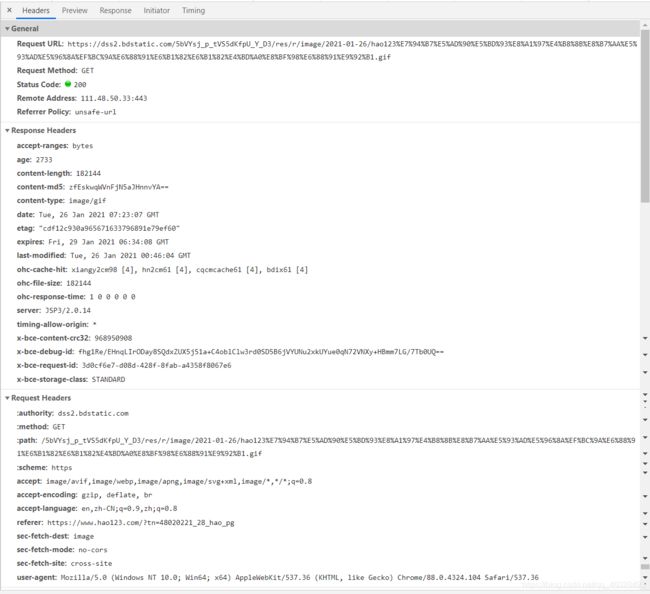
1.3.1.5 请求
请求大致包含4部分:
- 请求方法(Request Method)
- 请求的网址(Request URL)
- 请求头 (Request Headers)
- 请求体 (Request Body)
1. 请求方法
请求方法有很多,但最常见的请求只有GET和POST:
GET:
在浏览器中直接输入URL并回车,便发起了一个GET请求,请求的参数会包含在URL中,例如:在百度中搜索Python,这就是一个GET请求,请求链接为https://www.baidu.com/s?wd=Python,URL中包含了请求的参数信息,这里wd(word)参数表示要搜索的关键字,它的值(Python)就是搜索的内容。
POST:
POST请求大多数在表单提交时发起,例如:对于一个登录表单,输入用户名和密码后,点击“登录”按钮,这通常会发起一个POST请求,起数据通常以表单的形式传输,而不会体现在URL中。
GET和POST的区别:
GET请求中的参数包含在URL中,数据可以在URL中看到,而POST请求的URL不会包含这些数据,数据都是通过表单的形式传输的,会包含在请求体中GET请求提交的数据最多只有1024字节,而POST请求没有限制
常用请求汇总:
| 方法 | 描述 |
|---|---|
| GET | 请求页面,并返回页面内容 |
| HEAD | 类似于GET请求,只不过返回的响应体中没有具体的内容,用于获取报头 |
| POST | 大多用在提交表单或上传文件,数据包含在请求体中 |
| PUT | 从客户端向服务器传送的数据取代指定文档中的内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT | 把服务器当作跳板,让服务器代替客户端访问其它页面 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
2. 请求的网址
请求的网址:即统一资源定位符URL,可以唯一确定我们想要请求的资源
3. 请求头
请求头:用来说明服务器要使用的附加信息,比较重要的信息有Cookie、Referer、User-Agent
下面是一些常用的请求头的信息:
-
Accept:请求报头域,用于指定客户端可接受那些类型的信息。
-
Accept-Language:指定客户端可接受的语言类型。
-
Accept-Encoding:指定客户端可接受的内容编码。
-
Host:用于指定请求资源的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置,从HTTP1.1开始,请求必须包含此项内容。
-
Cookie:也常用复数形式Cookies,这是网站为了辨别用户进行会话跟踪而存储在本地的数据,它的主要功能是维持当前访问会话。例如:我们输入用户名和密码成功登陆到某个网站后,服务器会用会话保存登陆状态信息,后面我们每次刷新或请求该站点的其它页面时,会发现都是登陆状态,这就是Cookie的功劳。Cookies里面有信息标识了我们所对应的服务器的会话,每次在请求该站点时,都会在请求头长加上Cookies并将其发送给服务器,服务器通过Cookies识别出是我们自己,并且查出当前状态是登陆状态,所以返回结果就是登陆之后才能看到的网页内容。
-
Referer:此内容用来识别这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等
-
User-Agent:简称UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本信息等。在做爬虫是加上此信息,可以将爬虫伪装成浏览器,如果不加,将会是默认的爬虫的UA,很有可能会被识别为爬虫。
-
Content-Type:也叫做互联网媒体信息(Internet Media Type)或者MIME类型,在HTTP协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html代表HTML格式,image/gif代表GIF图片,application/json代表JSON类型,更多的对应关系大家可以查看这张表:http://tool.oschina.net/commons
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求服务器会认为是新的客户端,为了维护它们之间的联系,让服务器知道这次请求和上一次请求是同一个用户,必须在一个地方保存客户端的信息,
- Cookie通过在客户端记录信息确定用户身份
- Session通过在服务器端记录信息确定用户身份
所以,请求头是请求中的重要组成部分,一般爬虫都要处理请求头。
1.3.1.6 响应
响应由服务器端返回给客户端,可以分为三部分:
- 响应状态码(Response Status Code)
- 响应头(Response Headers)
- 响应体(Response Body)
1. 响应状态码
响应状态码表示服务器的响应状态:
| 响应状态码 | 含义 |
|---|---|
| 200 | 正常 |
| 301 | 本网页永久性转移达到另一个地址 |
| 302 | 请求的资源暂时驻留在不同的URI下 |
| 304 | 服务器已近执行了GET,但文件未变化 |
| 400 | 请求出现语法错误 |
| 403 | 客户端未能获得授权 |
| 404 | 在指定位置不存在所申请的资源 |
| 500 | 服务器遇到了意料不到的情况 |
| 503 | 服务器由于维护或者负载过重未能应答 |
2. 响应头
响应头包含了服务器对请求的应答信息,如Content-Type、Server、Set-Cookie等,下面是一些常用的响应头信息:
- Date:标识响应产生的时间
- Last-Modified:指定资源最后修改时间
- Content-Encoding:指定响应内容的编码
- Server:包含服务器的信息,比如名称、版本号等
- Content-Type:文档类型,指定放回的数据类型是什么,如text/jepg这代表图片
- Set-Cookie:设置Cookie。响应头中的Set-Cookie告诉浏览器需要将此内容放在Cookie中,下次请求携带Cookie请求
- Exprice:指定响应的过期时间,可以使代理服务器或浏览器将所加载的内容更新到缓存中,如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间
3. 响应体
响应中最重要的当属响应体的内容,响应的正文数据都在响应体中,
比如:
- 请求网页时,它的响应体就是HTML代码
- 请求一张图片时,它的响应体就是图片的二进制数据
在爬虫中,我们获得的就是HTML代码,通过解析HTML代码来获取我们想要的内容。
1.3.2 Python爬虫爬取网页流程
网络爬虫的流程主要分为以下三步:
- 获取网页
- 解析网页
- 存储数据
获取网页:给一个网址发送请求,该网址就会返回网页数据,类似于在浏览器中输入一个网址后按下回车出现网页。
解析网页:从返回的页面数据中提取想要的信息。类似于在网页中找到商品的价格。
存储数据:把提取出的信息保存下来,可以保存为文件,也可以存储到数据库中。
1.3.3 Python爬虫的技术实现
获取页面:urllib、requests(重点),selenium(重点)、多线程、登录抓取、突破IP封禁
解析网页:re(重点)、BeautifulSoup、lxml(重点)、pyquare
存储数据:txt文件(重点)、csv文件(重点)、图片文件、MySQL数据库(重点)
框架:Selenium、Scrapy