[TOC]
简介
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing execution to be suspended and resumed. Coroutines are well-suited for implementing familiar program components such as cooperative tasks, exceptions, event loops, iterators, infinite lists and pipes.
协程(英语:coroutine)是计算机程序的一类组件,推广了协作式多任务的子程序,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
以上是维基百科对协程的定义。
简单来讲,协程是一种轻量级线程。
相对于线程切换是由操作系统进行调度的,程序员无法进行控制。
而协程的调度是由程序员在代码层面上进行控制的,程序员可以通过控制suspend函数的挂起和恢复,从而控制程序运行流程,这在代码的展示上,相当于用同步的代码书写异步程序,代码逻辑非常简洁易懂。
理论上,由于协程不涉及到操作系统调度,因此只是在用户态上进行操作,而线程需要经历用户态与内核态之间的切换,所以协程性能更佳。
但是不同的语言在实现上可能存在差异,比如本文所要介绍的 Kotlin 下的协程,其在 JVM 平台上的内部实现也是基于线程,因此如果其进行了协程调度,存在一定的可能是进行了线程切换。
协程经常拿来与线程进行对比,它们彼此很相似,但是也很不同。
可以简单理解如下:
- 一个进程可以包含多个线程
- 一个线程可以包含多个协程
由于一个线程可以包含多个协程,而协程具备挂起和恢复功能,也因此让我们具备了在一个线程上执行多个异步任务的能力。
注:还是如上文所言,Kotlin 协程的底层实现存在线程切换,因此异步任务可能执行在另一条线程上。
名词释义
在具体介绍协程之前,需要先了解一下以下几个概念:
同步:执行一个任务时,调用者调用后即可获取返回结果
异步:执行一个任务时,调用者调用后直接返回,不关心结果,而是等到任务结束时,通过回调等方式通知调用者结果
同步与异步是针对返回结果来说的,
对于同步调用,由调用者主动获取结果。
对于异步调用,调用者是通过回调等方式被动获取结果的。
简单理解,比如对于一个函数调用,
同步调用就是调用函数后,直接就可以获取结果。
异步调用就是调用函数后,不关心结果,等函数体内的任务结束时,通过回调等方式通知调用者结果。
阻塞:执行一个任务时,当前调用线程调用后立即被挂起,无法执行后续代码
非阻塞:执行一个任务时,当前调用线程调用后立即返回,可继续执行后续代码
阻塞和非阻塞是针对当前线程是否具备 CPU 执行权来说的,
对于阻塞调用,调用不立即返回,当前线程被挂起,失去 CPU 执行权,直至调用任务完成,返回结果。
对于非阻塞调用,调用立即返回,当前线程仍然拥有 CPU 执行权,可继续执行后续代码。
注:可以讲上述描述中的 任务 理解为 函数,更加直观。
协程涉及到的一些概念
-
挂起函数:即
suspend函数,如下代码所示即为一个挂起函数:suspend fun delay(timeMillis: Long): Unit{ ... }Kotlin 中,
suspend关键字具备如下几层含义:- Kotlin 中规定:挂起函数只能在协程或者其他
suspend函数中使用,其实就相当于挂起函数只能直接或间接地在协程中进行调用。 -
suspend关键字只是起一个标识作用,用以表明被suspend修饰的函数(也即挂起函数)内部存在耗时操作,因此必须放置在协程中进行调用。 -
suspend关键字标识一个挂起点,挂起点具备挂起和恢复执行作用。当协程调用suspend函数时,会挂起当前协程,开启一个异步任务,当异步任务完成后,就会在当前挂起点恢复协程,继续该协程后续任务。
- Kotlin 中规定:挂起函数只能在协程或者其他
-
协程上下文(Coroutine Context):协程上下文是一系列规则和配置的集合,它决定了协程的运行方式。
kotlinx.coroutines 提供的协程构造器(Coroutine Builder),比如launch、async等,都会接收一个协程上下文对象,主要用于设置协程异步任务的执行线程策略。如下代码所示:suspend fun main() { GlobalScope.launch(context = Dispatchers.Default) { println("run inside: ${Thread.currentThread().name}") }.join() } -
结构化并发(Structured concurrency):如果一个协程内部创建了一个或多个子协程,只要所有子协程在父协程作用域结束前执行完成,就认为当前协程具备结构化并发。如下图所示:
 Structured concurrency
Structured concurrency更具体来说,当父协程结束时,如果其子协程仍在运行,则父协程会阻塞自己(即当前协程),让子协程运行完成后才退出,也就是无需显示使用
join来确保子协程运行结束。举个例子,如果我们使用
GlobalScope.launch创建一个全局协程,然后为其添加几个子协程,那么我们必须手动对所有子协程进行管理,如下所示:suspend fun main() { GlobalScope.launch { // 创建一个子协程 val job1 = launch { delay(100) println("Hello World") } // 再创建一个子协程 val job2 = launch { delay(200) println("Hello World again!!") } job1.join() job2.join() } // 延迟程序退出 delay(500) }可以看到,上述代码中,为了实现结构化并发,我们必须手动维护所有子协程协程状态,这样才能确保在父协程退出前,子协程能完成任务。
注:事实上,上述例子并未实现结构化并发,因为父协程
GlobalScope作用域其实已经退出了,只是通过delay让子协程运行,造成子协程都能运行完成效果,但事实上子协程生命周期超过了父协程。如果需要自己手动维护结构化并发,操作会相对繁琐,因此,Kotlin 已经为我们提供了具备结构化并发功能协程构造器,比如
coroutineScope,如下所示:suspend fun main() { GlobalScope.launch { // 子协程:具备结构化并发 coroutineScope { // 创建一个子协程 val job1 = launch { delay(100) println("Hello World") } // 再创建一个子协程 val job2 = launch { delay(200) println("Hello World again!!") } } } // 延迟程序退出 delay(500) }coroutineScope创建的协程具备结构化并发功能,因此只有等到其子协程完成时,父协程才可以退出,这样我们就无需维护各个子协程的状态了。结构化并发强调的是子协程的生命周期小于或等于父协程生命周期,因此,结构化并发的一个最大的好处就是可以很方便地管理协程,比如只要父协程被取消,其内所有协程也都会被自动取消。
基本使用
下面用代码来创建一个最简单的协程,了解一下基本的使用。具体步骤如下:
-
导入依赖:Kotlin 协程的官方框架为kotlinx.coroutines,该框架未集成在 Kotlin 的标准库中,因此需要我们手动进行导入:
// project: build.gradle buildscript { ext.kotlin_coroutines = "1.3.8" } // app: build.gradle dependencies { implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:$kotlin_coroutines" // Android 平台需要额外导入 kotlinx-coroutines-android implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:$kotlin_coroutines" } -
创建协程:以下代码使用
runBlocking函数创建了一个协程:fun main() { runBlocking { println("coroutineScope starts: ${Thread.currentThread().name}") launch { delay(1000) println("son coroutine: ${Thread.currentThread().name}") } println("coroutineScope ends: ${Thread.currentThread().name}") } }运行上述代码,可得到如下输出:
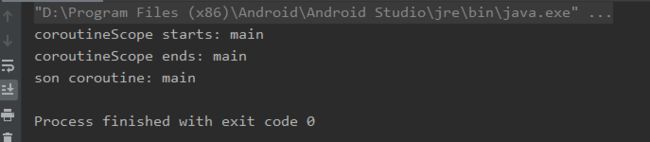
可以看到,我们在主线程中通过协程以非阻塞方式完成了异步任务。
协程作用域
每个协程都拥有自己的作用域范围,kotlinx.coroutines 提供了多种协程作用域,以下介绍常见的几种:
-
CoroutineScope:创建一个协程通用作用域。其文档如下图所示: CoroutineScope
CoroutineScope最佳的协程作用域实例创建是通过
CoroutineScope和MainScope内置的工厂方法(比如CoroutineScope()、MainScope())进行创建,
额外的上下文元素可以通过+操作符进行添加(因为 kotlinx.coroutines 覆写了plus操作符)
-
GlobalScope:全局协程作用域。具体内容如下图所示: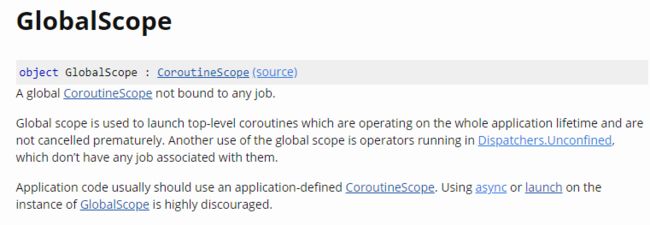 GlobalScope
GlobalScope从文档可以看到,
GlobalScope实现了CoroutineScope,并自行实现了全局功能。一个全局协程的生命周期与应用的生命周期一致。
-
MainScope:创建一个 UI 组件的协程作用域。其文档如下图所示: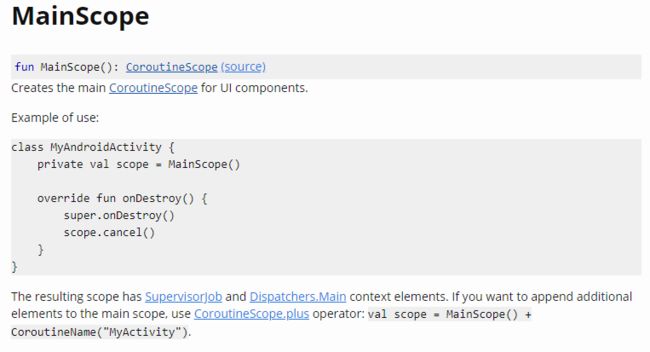 MainScope
MainScopeMainScope自带SupervisorJob和Dispatchers.Main上下文元素。
可以通过+操作符为其作用域范围增添新元素:val scope = MainScope() + CoroutineName("MyActivity")注:如果在 Android 平台上,可以通过
MainScope()方法创建一个主线程作用域(Dispatchers.Main)协程,然后通过为其创建子协程来执行异步任务,然后在资源释放出直接关闭协程即可,这样就将界面与异步任务连接了起来,会很方便进行管理。如下所示:class Activity { private val mainScope = MainScope() fun onCreate(){ // 执行异步任务 this.mainScope.launch(Dispatchers.IO) { // ... } } fun destroy() { mainScope.cancel() } }事实上,其实 Android 已经对具备生命周期的组件实体都内置了相应的协程作用域支持,具体内容可查看:lifecyclescope
创建协程
kotlinx.coroutines 提供了多种协程构造器让我们创建协程。以下列举一些常见的协程创建方式:
-
launch:CoroutineScope的扩展方法,用于创建一个新协程。其文档如下图所示: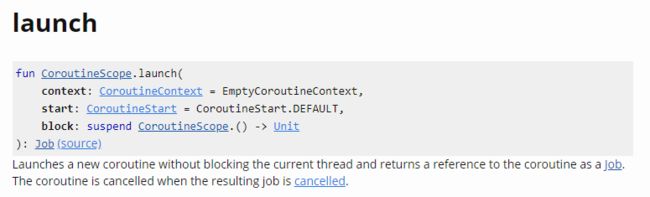 CoroutineScope.lauch
CoroutineScope.lauchlaunch函数启动的新协程不会阻塞当前线程,同时会返回一个Job对象,可通过该对象取消当前协程执行。launch函数启动的协程会继承父协程所在的协程上下文context,如果其上下文context不包含任意协程调度器dispatcher或者ContinuationInterceptor,则默认使用Dispatchers.default,即异步任务会在运行在一条 CPU 密集型线程上。如果
launch函数创建的协程内部抛出未捕获异常,那么默认情况下会导致其父协程取消(除非显式设置了CoroutineExceptionHandler)。默认情况下,
launch函数会立即执行协程,可以通过参数start来控制其启动选项,比如设置为CoroutineStart.LAZY,则launch函数创建的协程不会立即启动(懒加载),可通过返回对象的Job.start()显示进行启动,或者当调用Job.join()方法时,则会隐式启动该协程。
如下代码所示:suspend fun main() { val job = GlobalScope.launch(context = Dispatchers.Default) { println("${Thread.currentThread().name} --> 启动协程") launch { // 1 println("${Thread.currentThread().name} --> 开启一个子协程...1") } println("${Thread.currentThread().name} --> 创建懒加载子协程") val job1 = launch(start = CoroutineStart.LAZY) { // 2 println("${Thread.currentThread().name} --> 开启一个懒加载子协程...2") } val job2 = launch(start = CoroutineStart.LAZY) { // 3 println("${Thread.currentThread().name} --> 开启一个懒加载子协程...3") } println("${Thread.currentThread().name} --> 显式启动懒加载子协程") job1.start() // 4 println("${Thread.currentThread().name} --> 隐式启动懒加载子协程") job2.join() // 5 } job.join() }上述代码的运行结果如下所示:
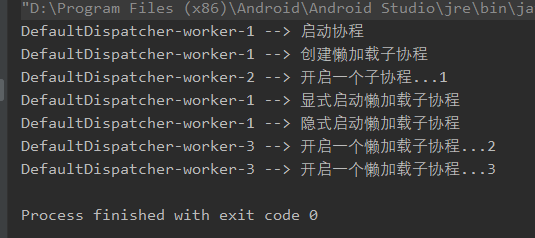
运行结果分析:首先我们通过
GlobalScope.launch函数创建了一个全局协程,并在该协程内部创建了 3 个子协程,分别位于上述代码的1、2和3位置,其中,1位置创建了一个立即执行的子协程,且该协程会继承父协程上下文,因此launch(..)函数内异步任务会立即自动分发到Dispatchers.Default线程上进行执行。
而由于launch函数不会阻塞当前线程,我们创建的父协程位于线程池中的DefaultDispatcher-worker-1,因此父协程会立即执行后续代码。
然后父协程继续往下执行,经历2和3过程,分别创建了两个懒加载子协程。
然后再代码4处,显示启动了子协程job1,则此时会立即将异步任务分发给Dispatchers.Default线程进行执行。
Job.start()是一个非阻塞调用,因此父协程代码会继续执行到5处,通过Job.join()方法隐式启动子协程job2,同样此时会将协程job2的异步任务分发到Dispatchers.Default线程进行执行。
以上就得到上图的最终输出。 -
async:CoroutineScope的扩展方法,用于创建一个新协程。其文档如下图所示: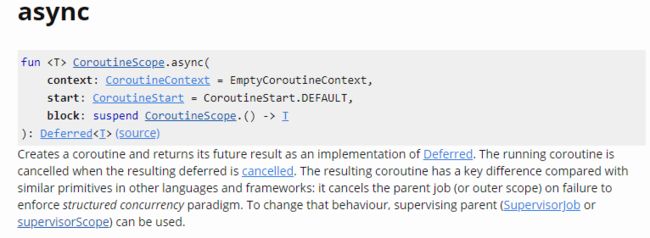 CoroutineScope.async
CoroutineScope.asyncasync函数的大部分性质与launch函数一致,比如:- 为了确保结构化并发,
async与launch一样,当其运行失败时,会导致父协程被取消。 - 其同样继承父协程上下文
context,如果其上下文context不包含任意协程调度器dispatcher或者ContinuationInterceptor,则默认使用Dispatchers.default。 - 默认创建就自动立即执行,也可通过
start参数控制其行为,比如CoroutineStart.LAZY来延时执行。
此时,可以通过Deferred.start()函数来显示启动协程,
也可以通过Deferred.join()、Deferred.await()和Deferred.awaitAll等函数隐式启动协程。
另外,
async与launch主要的区别有以下两个:异常处理:
launch内部可能会抛出异常,因此需用户手动进行处理。而async默认不会抛出异常,因为它会认为你最终必须调用await来获取结果,因此,async内部如果出现异常,用户需要在await处进行捕获。
更多异常处理内容,请查看后文:异常处理返回值:一个最重大的区别就是,
launch函数返回的是一个Job对象,该对象主要用于取消协程运行,而async函数返回的是一个Deferred对象,该对象不仅可以用于取消协程,更重要的是可以获取异步任务返回结果!这是相当有用的一个特性,如下代码所示:
注:实际上,
Deferred继承于Job:public interface Deferred: Job suspend fun main() = coroutineScope { val deferred = async { // 模拟耗时异步任务 delay(1000) // 返回 100 100 } val result = deferred.await() println("异步任务结果为:${result}") }上述代码执行结果如下图所示:

可以看到,我们成功获取得到异步任务返回的结果。
需要注意的是,对于
async开启的协程,我们使用的是Deferred.await()函数来获取异步任务返回结果。其文档如下所示: await()
await()await()会阻塞当前协程(即async的父协程),直至async协程完成异步任务返回结果,
或者当取消协程时,则会抛出一个CancellationException异常。await()函数会阻塞当前协程,但是不会阻塞当前线程,因此当当前线程存在多个协程时,await()会让出执行权,当前线程的其他协程就有机会得到执行。如下代码所示:suspend fun main() { coroutineScope { launch { // 1 val deferred = async { // 模拟耗时异步任务 delay(1000) // 返回 100 100 } val result = deferred.await() println("异步任务结果为:${result}") } launch { // 2 println("hello world") } } }当
1处子协程处于await()状态时,2处子协程就可以得到运行,结果如下所示:

- 为了确保结构化并发,
-
coroutineScope:创建一个通用作用域的新协程,并在该协程作用域范围内调用block块。其文档如下图所示: coroutineScope
coroutineScopecoroutineScope函数会继承其父协程的上下文coroutineContext,但会覆盖父协程上下文的Job对象。coroutineScope函数主要设计用于并发分解任务。但该协程内任一子协程运行失败时,该协程就会失败,并会取消其内所有子协程。coroutineScope函数具备结构化并发,它会阻塞当前协程,直至其函数体block执行完毕和其所有子协程运行完成时,才会返回。举个例子:代码如下所示:
suspend fun main() = coroutineScope { // 1 coroutineScope { // 2 delay(1000) println("World") } println("Hello") // 3 }上述代码的执行结果如下所示:

结果解析:上述代码中,如
1处代码所示,我们首先通过coroutineScope函数创建一个协程。
然后协程执行,代码会进行到2处,此时又通过coroutineScope函数创建了一个子协程,又因为coroutineScope函数会阻塞当前协程,直到其内部执行完成,因此3处代码暂时未能执行,必须等到2处代码内部执行完毕,最终的结果就如上图所示。 -
supervisorScope:创建一个新协程,并在该协程作用域范围内调用block块。其文档如下图所示: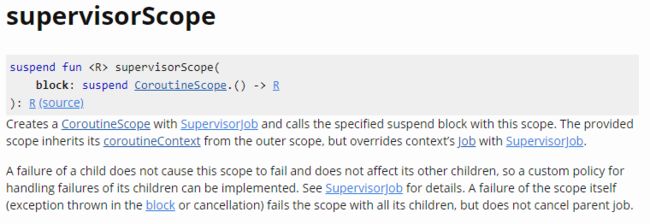 supervisorScope
supervisorScopesupervisorScope函数会继承其父协程的上下文coroutineContext,但会使用SupervisorJob覆盖父协程上下文的Job对象。对于
supervisorScope函数创建的协程,如果其内任一子协程运行失败,不会导致该协程失败,对其他子协程也不会造成影响,因此可以自定义子协程失败处理机制。如果是
supervisorScope创建的协程自身出现错误(比如block块抛异常或取消该协程),那么就导致该协程及其内所有子协程失败,但是不会取消父协程任务。supervisorScope具备结构化并发。 -
withContext:该函数会创建一个新协程,协程的异步任务会运行在指定上下文对应的线程中。其文档如下所示: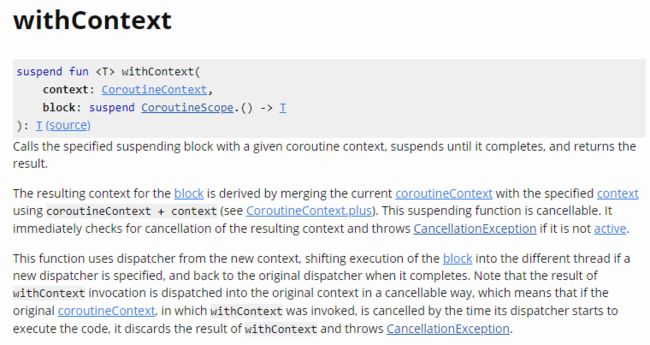 withContext
withContextwithContext函数的执行模型为:当调用withContext函数创建一个协程时,必须强制指定一个协程上下文context,然后withContext函数会立即在指定的上下文中执行其block块内容,同时会阻塞当前协程(即父协程),直至其block块运行完成(结构化并发),然后将block块最末尾的代码会作为异步任务的返回值。其执行模型类似于async(...).await()。举个例子:如下代码所示:
suspend fun main() = coroutineScope { println("${Thread.currentThread().name} --> 开启协程") val result = withContext(Dispatchers.Default){ println("${Thread.currentThread().name} --> 模拟耗时任务") delay(1000) println("${Thread.currentThread().name} --> 耗时任务结束") 10*10 } println("${Thread.currentThread().name} --> 异步任务结果:${result}") }上述代码的运行结果如下图所示:

从上图中可以看出,
withContext函数在设置上下文时候,不仅会对其内部的异步任务起作用,还会对coroutineScope后续协程作用域起改变上下文效果。withContext强制我们必须为其指定一个协程上下文,其实最主要的目的是指定协程调度器(上下文包含了调度器),具体调度器取值可参考后文:协程上下文与调度器 -
withTimeout:创建一个超时协程,当协程运行时间超过给定时间后,抛出一个TimeoutCancellationException。其文档如下图所示: withTimeout
withTimeout与其相似的还有一个函数
withTimeoutOrNull,该函数功能与withTimeout一样,只是在超时后,不抛出异常,而是直接返回null。withTimeout/withTimeoutOrNull具备结构化并发。 -
CoroutineScope(context)):工厂方法,用于创建一个新的协程。其文档如下所示: CoroutineScope(context)
CoroutineScope(context)CoroutineScope(context)参数context如果不包含一个Job元素,则会使用一个默认的Job()元素。这样子,协程取消或者任一子协程运行失败时,在该作用域范围内的其他所有协程都会被取消,其行为与coroutineScope函数一致。CoroutineScope(context)不具备结构化并发。 -
runBlocking:创建一个新协程,并阻塞当前线程,直至协程运行完成。其文档如下图所示: runBlocking
runBlocking注:由于
runBlocking会阻塞当前线程,因此在实际开发中,建议不要使用runBlocking创建协程。
该函数主要是设计用于在main函数或测试代码中用于运行带有suspend函数的库接口。
协程上下文与调度器(Coroutine Context and Dispatchers)
协程上下文是一系列不同元素的集合。其中主要元素是协程的Job。
协程会一直运行在某个协程上下文CoroutineContext中。
-
调度器和线程:协程上下文包含一个 协程调度器
CoroutineDispatcher,该调度器决定了协程异步任务的执行线程。Kotlin 提供了如下调度器可供我们选择:
-
Dispatchers.Default:表示使用一种低并发的线程策略,该策略适合 CPU 密集型计算任务。
所有的标准协程构造器,比如launch,async,它们默认的CoroutineDispatcher都为Dispatchers.Default -
Dispatchers.IO:表示使用一种较高并发的线程策略,适用于网络请求,文件读写等多 IO 操作的场景。 -
Dispatchers.UnConfined:表示一个未绑定到特定线程的协程调度器。它会首先在调用者线程执行协程,当遇到suspend函数恢复时,线程又会切换到该suspend函数对应的协程上下文中。Dispatchers.UnConfined不强制使用任何线程策略,随遇而安。开发中建议慎重使用该策略,因为会导致线程切换不可控。 -
Dispatchers.Main:表示运行在 UI 主线程上。比如在 Android 平台上,就表示不会开启子线程,而是直接将任务运行在主线程中。
kotlinx.coroutines 中所有的协程构造器,比如launch,async都可以接收一个可选参数CoroutineContext,为协程显示指定运行环境。
注:除了以上默认调度器外,Kotlin 还提供相关函数可以让我们创建其他类型的调度器,比如一个很好用的基于单线程运行环境的调度器:
newSingleThreadContext(name) -
当launch/async等协程构造器未显示指定CoroutineContext时,它会继承父协程的上下文,且异步任务会运行在父协程上下文指定的线程环境中。
GlobalScope.launch默认使用的调度器为Dispatchers.Default。
注:为了更好地查看调度器调度结果,可以在执行代码时,为 JVM 选项添加开启协程调式模式:-Dkotlinx.coroutines.debug,然后使用如下代码就可以在运行时打印出协程实例和其运行所在的线程:
fun log(msg: T) = println("[${Thread.currentThread().name}] $msg")
为了更方便查看协程,在开启协程调式模式后,也可以通过CoroutineName为新创建的协程添加名称,如下所示:
suspend fun main() {
coroutineScope {
log("set name for a coroutine")
launch(CoroutineName("son-routine")) {
log("this coroutine name is son-routine")
}
}
}
其运行结果如下图所示:

注:协程上下文CoroutineContext覆写了plus操作符,因此我们可以通过+号连接多个协程上下文元素,如下所示:
launch(Dispatchers.Default + CoroutineName("test")) {
println("I'm working in thread ${Thread.currentThread().name}")
}
取消机制
kotlinx.coroutines 提供的所有的suspend函数都是可以进行 取消(cancellable) 的。他们会检测协程取消状态,当检测到取消操作时,就会抛出CancellationException异常,我们可在代码块中对该异常进行捕获。
如下所示:
suspend fun main() = coroutineScope {
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L) // delay will detect cancellation for coroutine
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancel() // cancels the job
job.join() // waits for job's completion
println("main: Now I can quit.")
}
上述代码运行结果如下:

注:取消操作能成功的前提是:协程内部会对取消状态进行检测。
因此,并不是说我们调用cancel后,就一定能取消协程运行,比如,对于协程内部进行 CPU 密集型计算的操作,就无法进行取消,如下所示:
suspend fun outputTwicePerSecond(){
var startTime = System.currentTimeMillis()
var nextPrintTime = startTime
var i = 0
while (i < 5) { // computation loop, just wastes CPU
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
suspend fun main() = coroutineScope {
val job = launch(Dispatchers.Default) {
outputTwicePerSecond()
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
}
上述代码运行结果如下:
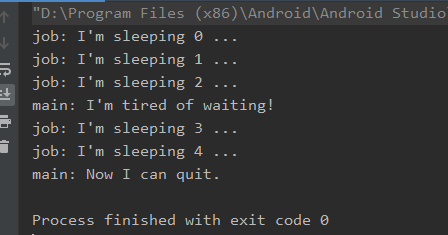
可以看到,在我们调用了cancel操作后,子协程异步任务仍继续执行,直到完成。
其原因就是子协程异步任务中没有对取消状态进行检测。解决的方法就是要么在异步任务循环部分中调用suspend函数(yield是一个不错的选择),要么就手动对取消状态进行检测,如下所示:
// 调用 suspend 函数
suspend fun outputTwicePerSecond(){
var startTime = System.currentTimeMillis()
var nextPrintTime = startTime
var i = 0
while (i < 5) { // computation loop, just wastes CPU
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
yield()
}
}
// 或者对 取消状态 进行检测
fun CoroutineScope.outputTwicePerSecond() {
var startTime = System.currentTimeMillis()
var nextPrintTime = startTime
var i = 0
while (this.isActive) { // computation loop, just wastes CPU
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
异常处理
前面内容讲过,要关闭一个协程,使用的是cancel操作,实质上,取消操作与异常是紧密联系的,当我们调用cancel时,协程内部其实是抛出了一个CancellationException异常,从而打断协程运行,但是这个异常默认会被异常处理器CoroutineExceptionHandler忽略,不过我们可以通过catch块进行捕获,如下所示:
fun main() = runBlocking {
val child = launch {
try {
delay(Long.MAX_VALUE)
} finally {
log("子协程停止运行!")
}
}
// 让子协程启动
yield()
log("取消子协程")
child.cancel()
child.join()
// 释放父协程执行权
delay(TimeUnit.SECONDS.toMillis(1))
log("父协程仍在运行")
}
上述代码运行结果如下:
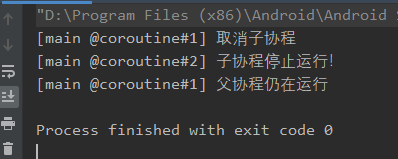
根据上图可以直到,对于取消操作,实质上就是抛出了一个CancellationException异常,所以可以捕获得到,且子协程抛出的CancellationException不会阻断父协程的执行。
以上我们已经知道协程对于CancellationException异常的处理,那么对于协程内部抛出的其他异常,或者是子协程发生异常,则又是怎样个处理方法呢?如下代码所示:
suspend fun main() {
GlobalScope.launch {
log("父协程启动")
val child = launch {
log("子协程抛出异常")
throw ArithmeticException("Div 0")
}
// 让子协程启动
yield()
child.join()
// 释放父协程执行权
delay(TimeUnit.SECONDS.toMillis(1))
log("父协程仍在运行")
}.join()
}
这次抛出的是普通异常ArithmeticException,其运行结果如下所示:
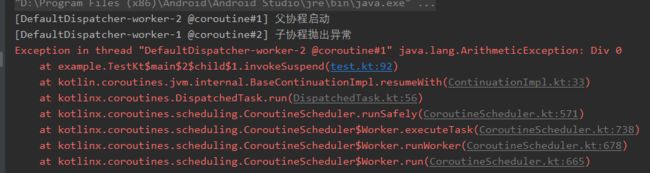
可以看到,子协程抛出非CancellationException异常,会打断父协程(取消父协程)运行。具体的过程涉及的内容如下:
-
异常传播(Exception propagation):协程构造器对于异常传播存在两种机制:
- 向上传播:即与普通异常处理机制一致,当出现未捕获异常时,自动向上传播该异常,比如
launch,actor - 自动包裹:即协程内部不处理该协程,而是将异常包裹到返回对象上,在用户进行特定动作时暴露给用户进行捕获,比如
async,produce
当创建的是根协程时,向上传播异常机制会将异常当作未捕获异常(uncaught exception),捕获机制类似于 Java 的
Thread.uncaughtExceptionHandler类似,
而自动包裹异常机制说的是,即使协程内部出现异常,但是不会直接抛出,而是等到用户调用相关方法时(比如await),才进行抛出。如下例子所示:
fun main() = runBlocking { // 向上传播 val job = GlobalScope.launch { // root coroutine with launch println("Throwing exception from launch") throw IndexOutOfBoundsException() // Will be printed to the console by Thread.defaultUncaughtExceptionHandler } job.join() println("Joined failed job") // 自动包裹 val deferred = GlobalScope.async { // root coroutine with async println("Throwing exception from async") throw ArithmeticException() // Nothing is printed, relying on user to call await } try { deferred.await() println("Unreached") } catch (e: ArithmeticException) { println("Caught ArithmeticException") } }可以看到,向上传播异常直接抛出,而自动包裹异常需要用户在特定点上进行异常捕获。
- 向上传播:即与普通异常处理机制一致,当出现未捕获异常时,自动向上传播该异常,比如
-
自定义异常处理器(CoroutineExceptionHandler):对于未捕获异常,我们可以通过为根协程绑定一个CoroutineExceptionHandler来对根协程及其子协程进行异常捕获,其功能类似于Thread.uncaughtExceptionHandler。注:
CoroutineExceptionHandler只对未捕获异常起作用。特别是,当子协程出现未捕获异常时,它会一级一级向上传播该异常,直至根协程,也因此,对子协程安装CoroutineExceptionHandler是没有作用的。但是对于Supervisor,其异常传播机制为:向下传播,即父协程发生异常,会传播给所有子协程,导致协程全部取消;而子协程发生异常,不会向上传播,也不会影响其他子协程和父协程。子协程需要自己处理自己的异常,因此为Supervisor作用域下的子协程安装CoroutineExceptionHandler是有效的。注:
asnyc函数对异常的作用机制是:async会将其内所有异常进行捕获,然后放置到返回值Deferred中,因此,为async安装CoroutineExceptionHandler也不会有任何作用。注:在 JVM 平台上,可以通过
ServiceLoader为所有协程注册一个全局异常处理器CoroutineExceptionHandler,全局异常处理器类似于Thread.defaultUncaughtExceptionHandler,在系统没有其他处理器的情况下进行使用。
在 Android 平台上,有一个默认以安装的全局异常处理器:uncaughtExceptionPreHandler例子如下所示:
suspend fun main() { // 创建一个异常处理器 val handler = CoroutineExceptionHandler { _, exception -> println("CoroutineExceptionHandler got $exception") } val job = GlobalScope.launch(handler) { // 安装异常处理器 log("父协程开启") val child = launch { // 子协程抛出异常 log("子协程抛出异常") throw AssertionError() } delay(TimeUnit.SECONDS.toMillis(1)) log("父协程仍在运行") } job.join() }上述代码执行结果如下图所示:
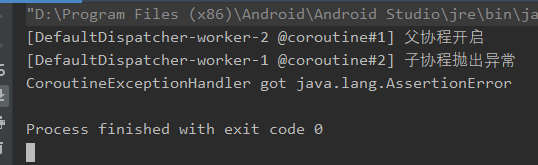
可以看到,为根协程安装了
CoroutineExceptionHandler后,成功捕获到子协程异常。
同时可以看到的是,CoroutineExceptionHandler只是对异常进行了捕获显示,不会对协程有实质影响,子协程抛出异常后,同样会取消父协程。注:对于
CoroutineExceptionHandler,不要将其安装到runBlocking中,因为runBlocking在子协程异常结束时,就会自动cancel,CoroutineExceptionHandler不会起作用。 -
异常聚合:如果多个子协程都抛出异常,那么一般规则是:第一个抛出的异常胜出,异常处理器会处理第一个异常,其他异常会作为次级信息附加到第一个异常后面。如下代码所示:
fun main() = runBlocking { val handler = CoroutineExceptionHandler { _, exception -> println("CoroutineExceptionHandler got $exception with suppressed ${exception.suppressed.contentToString()}") } val job = GlobalScope.launch(handler) { launch { try { delay(Long.MAX_VALUE) // it gets cancelled when another sibling fails with IOException } finally { throw ArithmeticException() // the second exception } } launch { delay(100) throw IOException() // the first exception } delay(Long.MAX_VALUE) } job.join() }其运行结果如下所示:

通道(Channel)
Channel 可以让数据流动在不同的协程中,提供了协程间通信机制。
本质上,Channel 底层就是一个线程安全的队列(类似BlockingQueue),一个协程可以往里面发送数据,另一个协程就可以在里面获取数据,完成通信过程。如下所示:
suspend fun main() {
val channel = Channel()
var producer = GlobalScope.launch {
for (i in 1..10) {
log("channel send $i")
channel.send(i)
}
}
var consumer = GlobalScope.launch {
repeat(10) {
val value = channel.receive()
log("channel receiver $value")
}
}
producer.join()
consumer.join()
}
上述代码是基于Channel实现的一个简单的生产者-消费者模式。
注:send和receive函数都是suspend函数,因此:
- 如果
Channel未发送数据,或者底层队列已满,则send会被挂起 - 如果
Channel无法读取到数据,则receive会挂起,直到新元素到来
下面对Channel的一些基本操作进行简介:
-
迭代
Channel:我们上面的例子是手动指定接收次数,并使用channel.receive进行数据接收,这种方式不够灵活。
Channel本身提供了迭代器操作:channel.iterator(),这种写法可以简化成for...in...操作,更加简洁方便。如下所示:var consumer = GlobalScope.launch { for (element in channel){ log("channel receive $element") } } 指定缓冲区大小:前面说过,
Channel本质上是一个队列,发送数据时,会把数据存储到到队列缓冲区中,接收数据时,会从该队列缓冲区中进行读取。
默认情况下,缓冲区大小为 0,但是我们可以通过在创建Channel时,手动指定该缓冲区大小,比如:Channel(4),表示缓冲区大小为 4。-
创建
Channel:前面我们都是通过Channel构造函数单独创建一个Channel,然后嵌套到生产者协程和消费者协程中,这种做法很直观,但是代码量略大。Kotlin 提供了一些扩展方法,可以很方便地让我们创建Channel。如下所示:suspend fun main() = coroutineScope { val receiveChannel = produce{ for (i in 1..10) { log("send $i") send(i) } } receiveChannel.consumeEach { log("receive $it") } } 使用扩展函数
produce来创建一个Channel,使用consumeEach来消费Channel。 关闭
Channel:Channel是可以进行关闭的,其关闭方法为close。close方法的底层实现其实就是通过发送一个特殊的 token 给到Channel,当Channel读取到该 token 时,就会进行关闭操作。因此,close方法其实不是立即关闭Channel,而是会等到Channel底层队列缓冲区数据完全被消费完毕后,才会进行关闭操作。
-
单发多收:多个协程可以从同一个
Channel中接收数据,此时接收协程竞争该Channel数据。如下所示:fun CoroutineScope.launchProcessor(id: Int, channel: ReceiveChannel) = launch { for (msg in channel) { log("Processor #$id received $msg") } } suspend fun main() = coroutineScope { val singleChannel = produce { var count: Int = 0 while (true) { send(++count) delay(100) } } repeat(5) { launchProcessor(it, singleChannel) } delay(950) singleChannel.cancel() } 注:
for...in...即使在多个协程中同时对同一个Channel进行遍历操作,也是非常安全的。上述代码运行结果如下图所示:

-
单收多发:多个协程可同时向同一个
Channel发送数据,这个很好理解,就是队列入数据。如下所示:fun CoroutineScope.sendString(channel: SendChannel, data: String, time: Long) = launch { while (true) { delay(time) log("send $data") channel.send(data) } } suspend fun main() = coroutineScope { val channel = Channel () // 开辟两个协程发送数据 sendString(channel, "hello", 200L) sendString(channel, "world", 500L) // 只接收 6 次 repeat(6) { val data = channel.receive() log("receive $data") } // 关闭所有子协程 coroutineContext.cancelChildren() } 上述代码运行结果如下图所示:

-
广播
Channel:前面我们提到过,Channel发送端和接收端可以存在一对多的情形,此时发送端的数据被接收端竞争,一个数据只会被一个接收端获取。
而如果想实现的是一个数据可以被所有的接收端获取得到,则可以使用广播通道BroadcastChannel,如下所示:fun CoroutineScope.register(id: Int, channel: BroadcastChannel) = launch { val receiverChannel = channel.openSubscription() for (i in receiverChannel) { log("receive broadcast:$id -> $i") } } suspend fun main() = coroutineScope { // 创建广播通道 val channel = BroadcastChannel (Channel.BUFFERED) // 创建两个协程,注册到该 channel repeat(2) { register(it, channel) } // 发送广播 for (i in 1..3) { delay(100) log("send broadcast: $i") channel.send(i) } coroutineContext.cancelChildren() } 注:最好是先进行注册,然后再发送数据,否则可能存在数据接收不完整问题,因为
BroadcastChannel在发送数据时,如果发现没有订阅者,则会直接抛弃到该条数据。上述代码中,使用函数
BroadcastChannel来创建一个广播通道,然后需要数据的协程可以通过openSubscription来进行注册,其结果如下图所示:
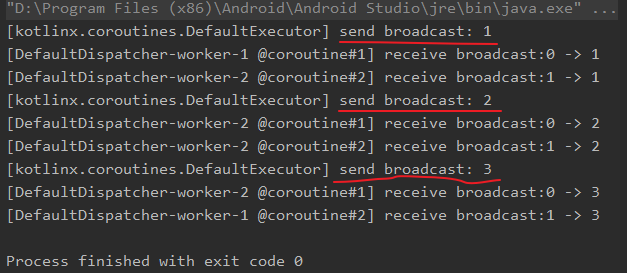
可以看到,每个注册到广播通道的协程都接收到每个数据。
注:除了使用
BroadcastChannel创建广播通道外,还可以将现成的Channel转换成广播:Channel,这种方法其实是通过对源(3).broadcast(4) Channel进行一个读取操作,转换为一个全局广播GlobalScope.broadcast,如果此时还有其他协程读取该源Channel,则可能产生如下结果:- 只有源
Channel发送数据:此时接收协程和注册广播的协程会竞争这些数据 - 只使用广播通道发送数据:此时则只有注册广播的协程能接收到这些数据
- 同时使用源
Channel和广播发送数据:此时数据十分混乱,不建议使用
- 只有源
冷数据流 Flow
一个suspend函数可以异步返回一个数值,而借助 异步流,我们就可以返回多个数值。
Kotlin 中提供了以下方法可以让我们返回多个数值:
-
Sequence:对于 CPU 密集型的异步任务,我们可以使用 序列 来返回多个值,如下所示:
fun simple(): Sequence= sequence { // sequence builder for (i in 1..3) { Thread.sleep(100) // pretend we are computing it yield(i) // yield next value } } fun main() { simple().forEach { value -> println(value) } } 上述代码在序列内部通过
yield函数将值传递出去,从而完成多个值的传递。
但是任务运行在主线程中,会卡住主线程,此时可通过suspend函数进行解决。 -
suspend函数:suspend函数直接或间接运行在协程中,使用得当则可解决异步任务卡主线程问题,如下所示:suspend fun simple(): List{ delay(1000) // pretend we are doing something asynchronous here return listOf(1, 2, 3) } fun main() = runBlocking { simple().forEach { value -> println(value) } } 由于一个
suspend函数只能返回一个值,上述代码通过返回集合的方式,虽然返回了多个值,但是是一次性的,对于数据量较大或是无限数据流的情况不太适用,此时可采用数据流Flow方式进行解决。 -
冷数据流 Flow:
Flow是响应式编程(比如:RxJava)与 Kotlin 协程结合而成的产物,将数据以流的方式进行发送。fun simple(): Flow= flow { // flow builder for (i in 1..3) { delay // pretend we are doing something useful here emit(i) // emit next value } } fun main() = runBlocking { // Collect the flow simple().collect { value -> println(value) } } 上述代码通过
flow函数生成一个异步数据流Flow,在其block块内同通过emit发送数据,每次调用emit的同时,也会同样调用ensureActive函数,对协程取消状态进行检测。最后是通过collect函数对数据进行获取消费。注:
Flow流是冷数据流,也即在调用flow创建一个Flow时,只有在消费时(比如:collect),才会真正执行数据生成逻辑。
下面对Flow的一些特性进行简介:
-
Flow构造器:Kotlin 提供了多种用于创建Flow的方法,以下介绍常用的几个:-
flow:该方法是用于创建Flow最基础的方法,其参数block内可通过emit函数发送数据,但是不能直接在其内进行线程切换,如下所示:flow{ emit(1) withContext(Dispatchers.IO) { // BAD!! emit(2) } }.collect { println(it) } channelFlow:如果想在生成元素时切换调度器,可以通过该函数来创建Flow:
channelFlow{ send(1) withContext(Dispatchers.IO) { // BAD!! send(2) } }.collect { log(it) } -
flowOf:该方法可接收可变数量类型参数,将其转化为Flow:
flowOf(1,2,3,4) -
asFlow:集合或者序列可以通过.asFlow()方法转化为Flow,如下所示:
sequence{ yield(1) }.asFlow().collect { log("sequence: $it") } listOf (1, 2, 3).asFlow().collect { log("listOf: $it") } setOf (1, 2, 3).asFlow().collect { log("setOf: $it") } -
-
取消发送数据:
Flow的消费依赖于终端操作符(比如collect),终端操作符必须在协程中进行调用,只要终端操作符所在的协程被取消时,Flow内部检测到取消状态,就会进行取消操作。因此,取消协程,只需取消它所在的协程即可。如下所示:suspend fun main() { val job = GlobalScope.launch { val intFlow = flow { (1..3).forEach { delay(1000) log("emit $it") emit(it) } } intFlow.collect { log("receive $it") } } delay(2500) log("cancel outter coroutine!!") job.cancelAndJoin(); }上述代码运行结果如下图所示:

-
操作符:由于
Flow是在协程上实现的响应式编程模型,因此它与 RxJava 一样,都有着很多的操作符,可以对Flow进行转换,下面简单列举几个常见的操作符:-
map/filter/take..:转换操作符suspend fun main() { val value = (1..10).asFlow() .filter { it % 2 == 0 } .take(3) .map { delay(1000) log("map value: $it") it + 1 }.reduce { a, b -> a + b } println("result is $value") } -
flattenConcat:该函数用于将嵌套Flow类型进行打平,转换为Flow。如下所示:suspend fun main() { flow{ List(5) { emit(it) } }.map { // it = Int flow { List(it) { emit(it) } } }.onEach { // it = Flow it.collect { value -> log(value) } }.collect() } 注:
flattenConcat不会打乱拼接顺序,结果仍然是生产时的顺序。
如果想并发拼接,则可以使用flattenMerge,这将产生无序结果。
其实,flattenConcat在概念上等同于flattenMerge(concurrency = 1),但具备更好的性能。 transform:该操作符是最通用的一种操作符,可用它模拟其他简单转换的操作符,比如map,filter,或者一些更加复杂的转换。
使用transform操作符,我们可以对任意数值重复发送emit任意次数。如下所示:
suspend fun main() { flowOf(100) .transform { value -> repeat(3) { emit("send $value") // 重复发送 3 次 } }.collect { log(it) } }-
collect/toList/toSet/first/single/reduce/fold:终端操作符,对Flow流进行消费。如下所示:
val sum = (1..5).asFlow() .map { it * it } // squares of numbers from 1 to 5 .reduce { a, b -> a + b } // sum them (terminal operator) println(sum)注:由于
Flow的消费端必须运行在协程中,因此终端操作符一定是suspend函数。-
flowOn:该操作符可以为Flow指定数据流生产所需的调度器,如下所示:
flow { /*数据生产*/ }.flowOn(Dispatchers.IO).collect {...}主要就是使用
flowOn进行线程切换,因此会导致开辟一个新的协程。
需要注意的是,flowOn只会对其前面的操作产生效果,这里也就是对flow {...}产生影响,对collect没有影响。-
buffer:该操作符为数据流生产和终端操作符消费各自开辟一个协程,这样两者就能并发运行,然后通过一个Channel将生产的数据流发送给终端消费,完成整套操作。默认情况下,
Flow流是顺序操作的,也即所有操作符都作用在同一个协程中,如下所示:flowOf("A", "B", "C") .onEach { println("1$it") } .collect { println("2$it") }上述代码的运行流程如下所示:
Q : -->-- [1A] -- [2A] -- [1B] -- [2B] -- [1C] -- [2C] -->--可以看到,元素是一个一个按生产先后顺序依次进行操作的,这样子的话,如果数据流生产和消费都存在耗时操作时,总时间就是所有操作耗时总合,如下所示:
suspend fun main() { val time = measureTimeMillis { flowOf("A", "B", "C") .onEach {// 每生产一个数据,耗时 100 ms delay(100) log("generate : $it") } .collect { delay(300) // 每消费一个数据,耗时 300 ms log("consume: $it") } } println("Collected in $time ms") }上述代码中,每生产一个数据耗时 100 ms,每消费一个数据耗时 300 ms,如果以默认的按顺序消费,则总时间耗费为:(100 + 300)*3 = 1200 ms 左右。
实际运行结果如下图所示:
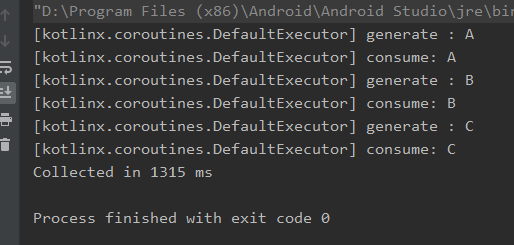 no buffer
no buffer但是如果我们在数据和生产消费中间添加一个
buffer操作,如下所示:suspend fun main() { val time = measureTimeMillis { flowOf("A", "B", "C") .onEach {// 每生产一个数据,耗时 100 ms delay(100) log("generate : $it") } .buffer() // 分割生产和消费 .collect { delay(300) // 每消费一个数据,耗时 300 ms log("consume: $it") } } println("Collected in $time ms") }上述代码运行结果如下图所示:

可以看到,仅仅只发送 3 个数据,就有将近 60 ms 的时间节省,如果数据量更大点,节省的时间会更加客观。
但更重要的是,从上图中可以看到,数据生产和消费是并行运行的,因为就如我们上述所说的,buffer会将其上和其下的操作放置到两个独立的协程中,从而增加了并发,节省时间。这里借用官网的一副示意图,会更加清晰整个过程:
 buffer
buffer综上:当数据生产和终端消费都存在耗时操作时,使用
buffer可以提高并发,节省时间。 -
catch:Flow提供了catch操作符,可以很方便对异常进行捕获。如下所示:suspend fun main() { flow { emit(1) // 手动抛出异常 throw ArithmeticException("divide 0") }.catch { t: Throwable -> log("caught error: $t") }.collect { log(it) } }注:
catch只能捕获它上游的异常,因此,通常将catch放置在最后操作符位置,也即终端操作符前一个。
但是对于终端操作符发生的异常,catch无法捕捉得到。此时,其实可以通过将数据消费转移到onEach进行处理,如下所示:suspend fun main() { flow { emit(1) // 手动抛出异常 throw ArithmeticException("divide 0") }.onEach { log(it) }.catch { t: Throwable -> log("caught error: $t") }.collect() }注意
catch需要放置到onEach前面,这样才能捕获到onEach出现的异常。
同时,我们使用的终端操作符函数为collect(),它会触发数据消费过程,但本身不对数据进行处理。
-
cancelable:让Flow流可以被取消。上文我们介绍过,如果未在协程异步任务中对取消状态进行检测,那么协程是无法响应
cancel的,而对于Flow流来说,也是一样的。
如果Flow流内部是通过emit进行数据发送,由于本身就是一个suspend函数(其实质是其内部会通过ensureActive对取消状态进行检测),故可以响应cancle操作。但是如果是由比如intRange.asFlow这类直接生成Flow,其内部未对取消状态进行检测,故无法响应cancel操作,当然我们可以通过onEach操作符为其手动添加检测:.onEach { currentCoroutineContext().ensureActive() },但是使用cancelable操作符会更加简洁方便,如下所示:fun main() = runBlocking{ (1..5).asFlow() .cancellable() .collect { value -> if (value == 3) cancel() println(value) }
-
更多操作符内容,,请参考:Asynchronous Flow
协程并发安全
由于 Kotlin 协程在 JVM 上的底层实现是基于线程的,因此协程间状态共享存在数据竞争问题,此时需要进行数据同步操作。
如果协程运行不同的调度器中(或者运行在多线程调度器中,比如Dispatchers.Default),则其异步任务实际上运行在不同的线程上,此时通过 Java 自带的一些线程安全操作(比如加锁,原子类...),就可以保证协程并发安全。
但是协程本身也提供了一些并发安全措施,主要有如下几方面内容:
-
线程细粒度控制:如果说很多个协程(假设运行在不同的线程中)对同一个数据进行修改,其实就是线程并发读写数据,这样数据就不安全。
其实我们可以将对数据的修改行为都调度到同一条线程中,这样就不会出现竞争导致数据出错问题。如下所示:suspend fun massiveRun(action: suspend () -> Unit) { val n = 100 // number of coroutines to launch val k = 1000 // times an action is repeated by each coroutine val time = measureTimeMillis { coroutineScope { // scope for coroutines repeat(n) { // 创建 100 个协程 launch { // 执行 1000 次动作 repeat(k) { action() } } } } } println("Completed ${n * k} actions in $time ms") } // 任务调度器:单一线程 val counterContext = newSingleThreadContext("CounterContext") // 共享数据 var counter = 0 fun main() = runBlocking { withContext(Dispatchers.Default) { massiveRun { // confine each increment to a single-threaded context withContext(counterContext) { counter++ } } } println("Counter = $counter") }上述代码在所有协程中,通过
withContext将对数据的修改都切换到全局唯一的一条线程上,保证了数据并发安全。结果如下:
 single thread
single thread -
线程粗粒度控制:直接在一条线程上开启多个协程,这样就自然保证了数据并发安全。如下所示:
// 任务调度器:单一线程 val counterContext = newSingleThreadContext("CounterContext") // 共享数据 var counter = 0 fun main() = runBlocking { // confine everything to a single-threaded context withContext(counterContext) { massiveRun { counter++ } } println("Counter = $counter") }执行结果如下所示:
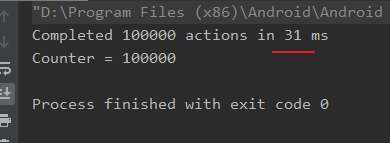
可以看到,效果比细粒度控制快了两个量级。一个是因为线程细粒度控制其实开辟了很多不必要的线程,系统开销很大,然后各个协程会把数据修改工作分发到另一个全局唯一的任务协程中,这就涉及到线程切换问题...而粗粒度是直接在一条线程上开启很多个协程,异步完成数据修改(由于在同一条线程上修改数据,天然线程安全),几乎不占用系统资源,因此速度很快。这从一方面也验证了:协程是轻量级线程。
-
互斥(Mutual exclusion):互斥方案就是使用永不并发的 关键部分(critical section) 来保护共享状态修改。
在阻塞调用中,通常使用synchronized或ReentrantLock来控制线程互斥。而在协程中,提供的加锁机制为Mutex,可以使用Mutex.lock和Mutex.unlock来划定关键部分。Mutext相对synchronized等锁的最大区别是:Mutext.lock方法是一个suspend方法,因此它不会阻塞线程。注:
Mutext提供了一个简便方法withLock,其相当于mutext.lock(); try{ ... } finally {mutext.unlock()}。下面使用
Mutext来修改上面代码,如下所示:// 共享数据 var counter = 0 // 创建一个协程互斥锁 val mutex = Mutex() fun main() = runBlocking { withContext(Dispatchers.Default) { massiveRun { // protect each increment with lock mutex.withLock { counter++ } } } println("Counter = $counter") }直接对修改部分加锁即可,其运行结果如下所示:
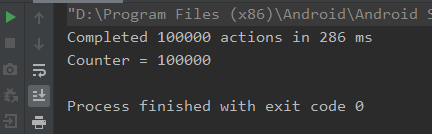
直观看来,加锁的效率不如单线程创建多协程,一方面加锁的确会更慢,但是这里更多的开销应该是调度器默认开启的线程池。
-
Actors:一个
actor实体是由一个协程,被封装到协程的状态和一个通道Channel组合而成的。
Kotlin 提供了actor协程构造器,可用于方便创建带有可以接收消息的邮箱Channel,同时将发送Channel合并进返回的Job当中。使用
actor来达到数据安全的方式如下:- 通过
actor方法创建的协程,发送的信息会被其内部代码块接收得到,因此首先需要定义一个消息体:
// Message types for counterActor sealed class CounterMsg object IncCounter : CounterMsg() // one-way message to increment counter class GetCounter(val response: CompletableDeferred) : CounterMsg() // a request with reply - 然后,创建一个发送和接收消息体的
actor:
// This function launches a new counter actor fun CoroutineScope.counterActor() = actor{ var counter = 0 // actor state for (msg in channel) { // iterate over incoming messages when (msg) { is IncCounter -> counter++ is GetCounter -> msg.response.complete(counter) } } } 注:
actor内部包含状态,对应我们上面的例子,这个状态就是被修改的数据counter。- 并发修改数据的协程直接使用
actor对象发送修改信息即可:
fun main() = runBlocking{ val sendChannel = counterActor() // create the actor withContext(Dispatchers.Default) { massiveRun { sendChannel.send(IncCounter) } } // send a message to get a counter value from an actor val response = CompletableDeferred () sendChannel.send(GetCounter(response)) println("Counter = ${response.await()}") sendChannel.close() // shutdown the actor } 上述代码运行结果如下所示:

其实,
actor的本质就是一个 多对一 的Channel,多个协程通过Channel发送修改事件给到actor,actor修改自身内部状态即可,所有的修改操作都发生在actor本身的协程中,故数据安全,不用考虑线程同步。注:
actor是一个双重的produce协程构造器,actor与接收通道相关联(内部代码块接收信息),produce与发送通道相关联(内部代码用于发送消息)。 - 通过
Select Expression (experimental)
Select 表达式,即 多路复用,与 Unix 中的 IO 多路复用功能相似。
Kotlin 中的 多路复用select,可以对多个协程某些操作进行复用,比如:
-
复用多个
await:通常使用async来创建一个协程,那么就必须使用await来获取协程结果,这是同步调用。
但是借助多路复用select,我们可以使用onAwait来自动获取结果,无需显示调用await,避免了阻塞协程操作,这是异步调用。具体代码如下所示:fun main() = runBlocking { val deferred = async { delay(200) "Hello World" } val result = select{ deferred.onAwait { result -> "onAwait receive async result: $result" } } log("result: $result") } 结果如下所示:

多路复用select 除了能将同步调用转化为异步调用外,他还具备事件竞争机制,即自动获取最先发生的事件。
比如,如果我们现在有两个协程进行网络请求,我们希望获取第一个最先返回的结果,那么就可以使用多路复用
await,如下所示:@ExperimentalTime fun main() = runBlocking { val deferred1 = async { val time = DurationUnit.SECONDS.toMillis(Random.nextLong(5)) log("1 ---> delay: $time") delay(time) log("1 ---> done") "Hello World" } val deferred2 = async { val time = DurationUnit.SECONDS.toMillis(Random.nextLong(3)) log("2 ---> delay: $time") delay(time) log("2 ---> done") "Hi Select" } val result = select{ deferred1.onAwait { "1111 first --> result: $it" } deferred2.onAwait { "2222 first --> result: $it" } } log("result: $result") } 多次运行上述代码,得到的结果始终返回最快的协程结果,如下所示:

可以看到,
select返回值是其某一分支的返回值,且select返回结果后,并不会取消其他仍在运行的协程。 -
多路复用
Channel:即多个Channel发送事件,使用onReceive可以选择最先发送成功的数据。@ExperimentalTime fun randomDelay(until: Long = 5): Long { return DurationUnit.SECONDS.toMillis(Random.nextLong(until)) } @ExperimentalTime fun main() = runBlocking { val channel1 = produce{ while (true) { val time = randomDelay() log("channel1 --> delay: $time") delay(time) send("send by channel 1111") } } val channel2 = produce { while (true) { val time = randomDelay() log("channel2 --> delay: $time") delay(time) send("send by channel 2222") } } repeat(5) { log("------- start select -------") val result = select { channel1.onReceive { it } channel2.onReceiveOrNull { it ?: "Channel2 is closed" } } log("result: $result") } delay(2000) coroutineContext.cancelChildren() } 注:对于
onReceive,当对应的Channel被关闭时,select会直接抛出异常。
对于onReceiveOrNull,当对应的Channel被关闭时,直接返回null。
多路复用select 除了支持上述的onAwait和onReceive事件外,它还支持很多其他事件,比如onJoin,onSend...
事实上,所有能被select支持的事件都是SelectClasueN类型,具体包含以下几种:
SelectClasue0:表示对应事件没有返回值。比如join没有返回值,其对应的SelectClasueN类型事件即为onJoinSelectClasue1:表示对应事件有返回值。比如onAwait,onReceive...-
SelectClasue2:表示对应事件有返回值,且还带有一个额外的参数。比如onSend,其第一参数表示要发送的值,第二个参数sendChannel表示数据发送到的Channel对象。如下所示:fun main() = runBlocking { val channel = Channel() launch { val result = channel.receive() log("receive: $result") } select { channel.onSend("1") { sendChannel -> log("send to Channel: $sendChannel") sendChannel.send(Random.nextInt().toString()) } } }
...
更多具体内容,请参考:Select Expression
综上,多路复用select 的主要作用就是可以同时等待多个协程,并选择获取最先可用协程的结果。
一些注意点
-
对一个父协程进行取消操作,会自动取消它作用域内所有的协程:
suspend fun showStatus(type: String) { log("$type starts") try { delay(100) log("$type done") } finally { log("$type cancelled") } } fun main() = runBlocking { val scope = CoroutineScope(Dispatchers.Default) scope.launch { launch { showStatus("launch") } launch { async { showStatus("async") }.await() } launch { withContext(Dispatchers.IO) { showStatus("withContext") } } coroutineScope { showStatus("coroutineScope") } // ... } delay(80) log("父协程取消") // 取消父协程,导致其作用域内所有协程取消 scope.cancel() }当调用最外层
scope.cancel()时,其作用域内所有子协程、子子协程...都会被取消。结果如下图所示: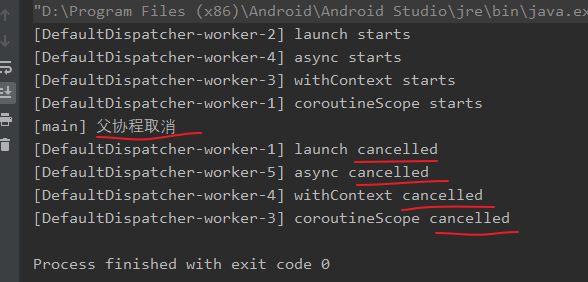
-
创建一个协程时,可以为其上下文对象添加一个
Job对象,对该Job对象调用取消操作时,与该Job绑定的协程及其子协程都会被取消:fun main() = runBlocking { val job = Job() // 将协程与 Job 绑定 val scope = CoroutineScope(Dispatchers.Default + job) scope.launch { // ... } delay(80) // 取消 Job 绑定的协程,导致其作用域内所有协程取消 job.cancel() }上述代码与第 1 点的代码基本一致,只是将
CoroutineScope与Job绑定了起来,因此,调用Job.cancel()就可以取消与其绑定的协程,从而该协程作用域内的所有协程也都会被取消。 -
协程作用域内应当使用
launch、async、coroutineScope、supervisorScope这些能继承父协程上下文对象或者withContext等具备结构化并发特性的协程构造器来创建子协程,这样才能满足上述 1,2 条目结果,不要使用GlobalScope.launch,CoroutineScope.launch等创建子协程,因为这些操作创建的协程运行在其他作用域内,跳脱了当前协程作用域,导致当前协程无法对其进行控制:fun main() = runBlocking { val scope = CoroutineScope(Dispatchers.Default) scope.launch { GlobalScope.launch { showStatus("GlobalScope") } CoroutineScope(Dispatchers.Default).launch { showStatus("CoroutineScope") } } delay(80) log("父协程取消") scope.cancel() // 避免程序退出 delay(1000) }结果如下图所示:
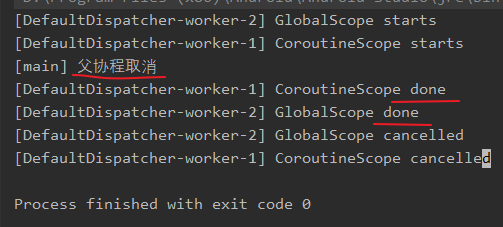
可以看到,父协程取消,子协程仍在运行,父协程不具备控制子协程能力。
参考
- 官方文档 - coroutines-guide
- 深入理解Kotlin协程