LASSO近端梯度下降法Proximal Gradient Descent公式推导及代码
文章目录
- LASSO by Proximal Gradient Descent
-
- Proximal Gradient Descent Framework近端梯度下降算法框架
- Proximal Gradient Descent Details近端梯度下降细节推导
- Simplified Code简化版代码
- Speed Comparison计算速度比较
- 完整代码
LASSO by Proximal Gradient Descent
Prepare:
准备:
from itertools import cycle
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import lasso_path, enet_path
from sklearn import datasets
from copy import deepcopy
X = np.random.randn(100,10)
y = np.dot(X,[1,2,3,4,5,6,7,8,9,10])
Proximal Gradient Descent Framework近端梯度下降算法框架
- randomly set β ( 0 ) \beta^{(0)} β(0) for iteration 0
- For k k kth iteration:
----Compute gradient ∇ f ( β ( k − 1 ) ) \nabla f(\beta^{(k-1)}) ∇f(β(k−1))
----Set z = β ( k − 1 ) − 1 L ∇ f ( β ( k − 1 ) ) z = \beta^{(k-1)} - \frac{1}{L} \nabla f(\beta^{(k-1)}) z=β(k−1)−L1∇f(β(k−1))
----Update β ( k ) = sgn ( z ) ⋅ max [ ∣ z ∣ − λ L , 0 ] \beta^{(k)} = \text{sgn}(z)\cdot \text{max}[|z|-\frac{\lambda}{L}, \; 0] β(k)=sgn(z)⋅max[∣z∣−Lλ,0]
----Check convergence: if yes, end algorithm; else continue update
Endfor
Here f ( β ) = 1 2 N ( Y − X β ) T ( Y − X β ) f(\beta) = \frac{1}{2N}(Y-X\beta)^T (Y-X\beta) f(β)=2N1(Y−Xβ)T(Y−Xβ), and ∇ f ( β ) = − 1 N X T ( Y − X β ) \nabla f(\beta) = -\frac{1}{N}X^T(Y-X\beta) ∇f(β)=−N1XT(Y−Xβ),
where the size of X X X, Y Y Y, β \beta β is N × p N\times p N×p, N × 1 N\times 1 N×1, p × 1 p\times 1 p×1, which means N N N samples样本 and p p p features特征. Parameter L ≥ 1 L \ge 1 L≥1 can be chosen, and 1 L \frac{1}{L} L1 can be considered as step size步长.
Proximal Gradient Descent Details近端梯度下降细节推导
Consider optimization problem:
现考虑优化问题:
min x f ( x ) + λ ⋅ g ( x ) , \text{min}_x {f(x) + \lambda \cdot g(x)}, minxf(x)+λ⋅g(x),
where x ∈ R p × 1 x\in \mathbb{R}^{p\times 1} x∈Rp×1, f ( x ) ∈ R f(x) \in \mathbb{R} f(x)∈R. And f ( x ) f(x) f(x) is differentiable convex function, and g ( x ) g(x) g(x) is convex but may not differentiable.
f ( x ) f(x) f(x)是可微凸函数, g ( x ) g(x) g(x)是凸函数但不一定可微。
For f ( x ) f(x) f(x), according to Lipschitz continuity, for ∀ x , y \forall x, y ∀x,y, there always exists a constant L L L s.t.
对于 f ( x ) f(x) f(x),根据利普希茨连续性,对于任意 x , y x,y x,y,一定存在常数 L L L使得满足
∣ f ′ ( y ) − f ′ ( x ) ∣ ≤ L ∣ y − x ∣ . |f'(y) - f'(x)| \le L|y-x|. ∣f′(y)−f′(x)∣≤L∣y−x∣.
Then this problem can be solved using Proximal Gradient Descent.
可以用近似梯度下降来解决这种问题。
Denote x ( k ) x^{(k)} x(k) as the k k kth updated result for x x x, then for x → x ( k ) x\to x^{(k)} x→x(k), the proximation of f ( x ) f(x) f(x) can be a function of x x x and x ( k ) x^{(k)} x(k):
用 x ( k ) x^{(k)} x(k)来表示 x x x的第 k k k次更新后的结果,则对于 x x x逼近 x ( k ) x^{(k)} x(k)时, f ( x ) f(x) f(x)的近似可以用 x x x 和 x ( k ) x^{(k)} x(k)的函数来表示:
f ^ ( x , x ( k ) ) = f ( x ( k ) ) + ∇ f T ( x ( k ) ) ( x − x ( k ) ) + L 2 ∥ x − x ( k ) ∥ 2 = L 2 [ x − ( x ( k ) − 1 L ∇ f ( x ( k ) ) ) ] 2 + CONST \hat{f}(x,x^{(k)}) = f(x^{(k)}) + \nabla f^T(x^{(k)}) (x-x^{(k)}) + \frac{L}{2} \left\lVert x - x^{(k)} \right\rVert^2 \\ \;\;\;= \frac{L}{2}[x - (x^{(k)} - \frac{1}{L} \nabla f(x^{(k)}))]^2 + \text{CONST} f^(x,x(k))=f(x(k))+∇fT(x(k))(x−x(k))+2L∥∥∥x−x(k)∥∥∥2=2L[x−(x(k)−L1∇f(x(k)))]2+CONST
where CONST \text{CONST} CONST is not related with x x x, so can be ignored.
其中 CONST \text{CONST} CONST是与 x x x无关的项,可被忽略。
The original solution for x x x at iteration k + 1 k+1 k+1 is
x x x的第 k + 1 k+1 k+1次迭代的原始解为
x ( k + 1 ) = argmin x { f ( x ) + λ ⋅ g ( x ) } , x^{(k+1)} = \text{argmin}_x\{ f(x) + \lambda \cdot g(x)\}, x(k+1)=argminx{ f(x)+λ⋅g(x)},
In proximal gradient method, we use below instead:
在近端梯度下降法中,我们可用下式替代:
x ( k + 1 ) = argmin x { f ^ ( x , x ( k ) ) + λ ⋅ g ( x ) } = argmin x { L 2 [ x − ( x ( k ) − 1 L ∇ f ( x ( k ) ) ) ] 2 + CONST + λ ⋅ g ( x ) } . x^{(k+1)} = \text{argmin}_x\{ \hat{f}(x,x^{(k)}) +\lambda \cdot g(x) \} \\ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;= \text{argmin}_x\{ \frac{L}{2}[x - (x^{(k)} - \frac{1}{L} \nabla f(x^{(k)}))]^2 + \text{CONST} +\lambda \cdot g(x) \}. x(k+1)=argminx{ f^(x,x(k))+λ⋅g(x)}=argminx{ 2L[x−(x(k)−L1∇f(x(k)))]2+CONST+λ⋅g(x)}.
Given g ( x ) = ∥ x ∥ 1 g(x) = \left\lVert x \right\rVert_1 g(x)=∥x∥1, and let z = x ( k ) − 1 L ∇ f ( x k ) z = x^{(k)} - \frac{1}{L} \nabla f(x_k) z=x(k)−L1∇f(xk), we have
x ( k + 1 ) = argmin x { L 2 ∥ x − z ∥ 2 + λ ∥ x ∥ 1 } . x^{(k+1)} = \text{argmin}_x\{ \frac{L}{2} \left\lVert x - z \right\rVert^2 + \lambda \left\lVert x \right\rVert_1 \}. x(k+1)=argminx{ 2L∥x−z∥2+λ∥x∥1}.
To solve Equation above, let F ( x ) = L 2 ∑ j = 1 p ( x j − z j ) 2 + λ ∑ j = 1 p ∣ x j ∣ F(x) = \frac{L}{2} \sum_{j=1}^p(x_j - z_j)^2 + \lambda\sum_{j=1}^p|x_j| F(x)=2L∑j=1p(xj−zj)2+λ∑j=1p∣xj∣. For j j jth element in x x x, it’s easy to know that the optimal x j ∗ x^*_j xj∗ satisfies
为了求解上面的等式,令 F ( x ) = L 2 ∑ j = 1 p ( x j − z j ) 2 + λ ∑ j = 1 p ∣ x j ∣ F(x) = \frac{L}{2} \sum_{j=1}^p(x_j - z_j)^2 + \lambda\sum_{j=1}^p|x_j| F(x)=2L∑j=1p(xj−zj)2+λ∑j=1p∣xj∣。对于 x x x的第 j j j个分量/元素,易知最优解 x j ∗ x^*_j xj∗满足
∂ F ( x ) ∂ x j = L ( x j − z j ) + λ ⋅ sgn ( x j ) = 0 , \frac{\partial F(x)}{\partial x_j} = L(x_j - z_j) + \lambda \cdot \text{sgn}(x_j)=0, ∂xj∂F(x)=L(xj−zj)+λ⋅sgn(xj)=0,
and we can get
z j = x j + λ L sgn ( x j ) z_j = x_j + \frac{\lambda}{L} \text{sgn}(x_j) zj=xj+Lλsgn(xj).
The goal is to express x j ∗ x^*_j xj∗ as a function of z j z_j zj.This can be done by swapping the x x x- z z z axes of the plot of z j = x j + λ L sgn ( x j ) \;\;z_j = x_j + \frac{\lambda}{L} \text{sgn}(x_j) zj=xj+Lλsgn(xj) :
我们的目标是将 x j ∗ x^*_j xj∗ 表达为 z j z_j zj的函数。这可以通过交换 z j = x j + λ L sgn ( x j ) \;\;z_j = x_j + \frac{\lambda}{L} \text{sgn}(x_j) zj=xj+Lλsgn(xj)图像中的 x x x- z z z轴来做到:

Then x j x_j xj can be expressed as
然后 x j x_j xj可以被表示为
x j = sgn ( z j ) ( ∣ z j ∣ − λ L ) + = sgn ( z j ) ⋅ max { ∣ z j ∣ − λ L , 0 } x_j = \text{sgn}(z_j)(|z_j| - \frac{\lambda}{L})_+ \\ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;= \text{sgn}(z_j) \cdot \text{max}\{|z_j| - \frac{\lambda}{L},\; 0\} xj=sgn(zj)(∣zj∣−Lλ)+=sgn(zj)⋅max{ ∣zj∣−Lλ,0}
Simplified Code简化版代码
The code is Python version of proximal gradient descent from Stanford MATLAB LASSO demo.
这里的代码实现是Stanford MATLAB LASSO demo中近似梯度下降法的Python版本。
In the original code, to make sure the differentiable part of objective function f ( β ) = 1 2 N ∥ Y − X β ∥ 2 f(\beta) = \frac{1}{2N} \left\lVert Y - X\beta \right\rVert^2 f(β)=2N1∥Y−Xβ∥2 will decrease after each time weight update, there is a check to see whether the first-order approximation of f ( β ) f(\beta) f(β) is smaller than the value from previous β \beta β:
在原始代码中,为了确保目标函数的可微部分 f ( β ) = 1 2 N ∥ Y − X β ∥ 2 f(\beta) = \frac{1}{2N} \left\lVert Y - X\beta \right\rVert^2 f(β)=2N1∥Y−Xβ∥2在每次权重更新后会减小,需要检查 f ( β ) f(\beta) f(β)的一阶近似是否小于前一次 β \beta β带入后的结果:
Check whether 1 2 N ∥ Y − X β ( k ) ∥ 2 ≤ 1 2 N ∥ Y − X β ( k − 1 ) ∥ 2 + ∇ f T ( β ( k − 1 ) ) ( β ( k ) − β ( k − 1 ) ) + L 2 ∥ β ( k ) − β ( k − 1 ) ∥ 2 \text{Check whether } \frac{1}{2N} \left\lVert Y - X\beta^{(k)} \right\rVert^2 \le \frac{1}{2N} \left\lVert Y - X\beta^{(k-1)} \right\rVert^2 + \nabla f^T(\beta^{(k-1)}) (\beta^{(k)} - \beta^{(k-1)}) + \frac{L}{2} \left\lVert \beta^{(k)} - \beta^{(k-1)} \right\rVert^2 Check whether 2N1∥∥∥Y−Xβ(k)∥∥∥2≤2N1∥∥∥Y−Xβ(k−1)∥∥∥2+∇fT(β(k−1))(β(k)−β(k−1))+2L∥∥∥β(k)−β(k−1)∥∥∥2
def f(X, y, w):
n_samples, _ = X.shape
tmp = y - np.dot(X,w)
return 2*np.dot(tmp, tmp) / n_samples
def objective(X,y,w,lmbd):
n_samples, _ = X.shape
tmp = y - np.dot(X,w)
obj_v = 2 * np.dot(tmp,tmp) / n_samples + lmbd * np.sum(np.abs(w))
return obj_v
def LASSO_proximal_gradient(X, y, lmbd, L=1, max_iter=1000, tol=1e-4):
beta = 0.5 # used to update L for finding proper step size
n_samples, n_features = X.shape
w = np.empty(n_features, dtype=float)
w_prev = np.empty(n_features, dtype=float) # store the old weights
xty_N = np.dot(X.T, y) / n_samples
xtx_N = np.dot(X.T, X) / n_samples
prox_thres = lmbd / L
h_prox_optval = np.empty(max_iter, dtype=float)
for k in range(max_iter):
while True:
grad_w = np.dot(xtx_N, w)- xty_N
z = w - grad_w/L
w_tmp = np.sign(z) * np.maximum(np.abs(z)-prox_thres, 0)
w_diff = w_tmp - w
if f(X, y, w_tmp) <= f(X, y, w) + np.dot(grad_w, w_diff) + L/2 * np.sum(w_diff**2):
break
L = L / beta
w_prev = copy(w)
w = copy(w_tmp)
h_prox_optval[k] = objective(X,y,w,lmbd)
if k > 0 and abs(h_prox_optval[k] - h_prox_optval[k-1]) < tol:
break
return w, h_prox_optval[:k]
def pgd_lasso_path(X, y, lmbds):
n_samples, n_features = X.shape
pgd_coefs = np.empty((n_features, len(lmbds)), dtype=float)
for i, lmbd in enumerate(lmbds):
w, _ = LASSO_proximal_gradient(X, y, lmbd)
pgd_coefs[:,i] = w
return lmbds, pgd_coefs
experiment:
实验:
lmbds, pgd_coefs = pgd_lasso_path(X, y, my_lambdas)
# Display results
plt.figure(1)
colors = cycle(['b', 'r', 'g', 'c', 'k', 'y','m'])
neg_log_lambdas_lasso = -np.log10(my_lambdas)
for coef_l, c in zip(coefs_lasso, colors):
l1 = plt.plot(neg_log_lambdas_lasso, coef_l, c=c)
plt.xlabel('-Log($\lambda$)')
plt.ylabel('coefficients')
plt.title('PGD Lasso Paths')
plt.axis('tight')
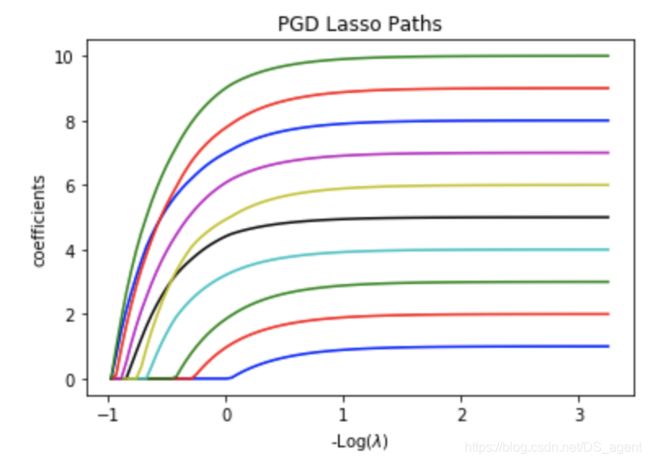
the result looks similar with that using Coordinate Descent Method.
结果与之前用CDM的结果相似。
Speed Comparison计算速度比较
print("Coordinate descent method from scikit-learn:")
%timeit lambdas_lasso, coefs_lasso, _ = lasso_path(X, y, eps, fit_intercept=False)
print("PGD method:")
%timeit lmbds, pgd_coefs = pgd_lasso_path(X, y, my_lambdas)
Results:
结果:
Coordinate descent method from scikit-learn:
4.88 ms ± 97 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
PGD method:
778 ms ± 21.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Pure python PGD is faster than that of coordinate descent method in my previous blog, but slower than Cython coordinate descent method.
纯Python版本的PGD要比本人之前博客中的CDM实现快,但是比Cython的CDM慢。
完整代码
放到GitHub上了,包含了前面coordinate descent method的实验