“有些人担心人工智能会让人类觉得自卑,但是实际上,即使是看到一朵花,我们也应该或多或少感到一些自愧不如。”——艾伦·凯AlanKay
这是一个很有意思的入门玩意儿,令我惊奇的是,从设计到实现的过程,并没有耗费我太多的时间。原因是强化学习并没有我想象中如此难以咀嚼。也许是我大学时深厚的动态规划求解功底,当我把西瓜书关于强化学习部分啃完时,我发现我对于这种动态最优化决策过程求解问题,看起来居然如此熟悉。内心居然如此激动~~~~
感谢OpenAI, 感谢莫烦Python,感谢我的组员对我的支持,下面我避免使用枯燥无味的公式来介绍这个小AI。
强化学习
人工智能领域中这个方向是来源于心理学的一个行为主义理论的,也就是说有机体如何在环境给予的奖励或者惩罚的刺激下,逐步形成对刺激的预期,产生最大利益的习惯性行为。

举个例子,训练小狗学会捡飞盘(过程自行脑补)。
而在计算机领域,强化学习是一类算法,是让计算机实现从一开始什么都不懂,脑袋没有一点想法,通过不断尝试从错误中学习,最后找到规律,最后学会目的的方法。
所以,我需要研发一个从不懂到懂的AI来玩跳一跳游戏。
环境信息获取
不同于围棋,Dota这些游戏,跳一跳是一个非常简单的游戏。跳的远近仅仅取决于按压的时间长短。所以,我们需要训练一个能学习一个根据距离长短来决定按压时间长短的AI。
所以,我们首先要获得当前位置到下一个目标位置的精准距离如下图。

感谢wangshub大神的贡献。根据上图的标注,我们根据像素点分布的特点,我们可以十分精准地定位到棋子和棋盘的关键点。尽管算法很精准,但是,存在一个棋盘,导致检测关键点的位置有误差。如下图。
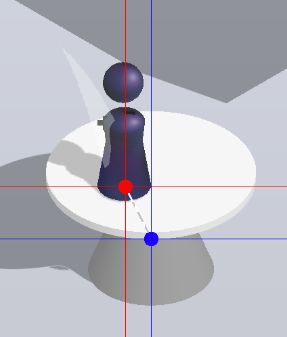
检测点(蓝色)并没有很正确地检测棋盘的中心点,这个误差会导致我们在计算奖励的实话,产生很大的误差。所以,我们还需要一个信息去识别是否精确跳到了目标点。

我留意到了左上角有一个分数,我参考wangshub的方法,利用训练好的模型,使用tensorflow进行数字识别,得到当前的分数。
建模
我假设按压时间与跳远的距离成正相关,所以存在一个按压系数f。使得
强化学习问题本质是一个MDP问题,所以我们需要先定义好状态,那么当前AI选择的按压系数就是我们的当前的状态。
显然,对于同一个oberserveDistance,不同的f会得到不一样的ActualDistance。我定义奖励函数如下:
def getReward(self, target_distance, actual_distance, ActualScore):
error_distance = math.sqrt((target_distance - actual_distance) ** 2)
# 利用踩中中心作为奖励,因为移动后的估算会有问题,所以不能用估算后的位置来评估
if ActualScore - self.lastScore > 1:
return 300
else:
return -1 * (error_distance)
简单理解就是,假如踩到了中心,那么我奖励300,否则,离得也远,惩罚越高。
AI的动作也很简单,就只有三个动作:调高f(f += 0.02 )2. f不变 3. 调低f(f -= 0.02)
可以观察到,我把一个求解连续变量的最优化问题转化成了一个求解离散变量的最优化问题。但是,转化之后会有误差,希望下一个版本不用这样。
DQN
由于我转化成了离散变量的最优化求解问题,状态是有限的,Q Learning完成可以胜任。但是,基于学习的目的,我还是选择了DQN来做,使用深度网络来学习如何根据obervation来做决策。
但是,我牺牲了DQN的优点,没有使用Fixed Q-target。因为在这个游戏里面,容忍忍受的误差范围太小,所以,我没有使用Fixed Q-target,让神经网络及时更新最新的参数和结果。
同时,我缩小了记忆库的范围,并没有让AI随机抽取学习,为了让它快速收敛,我取最前的几条记忆库的数据来学习。
还有,我调整了e-贪婪的参数,逐步增长的随机阈值为0.05,表示20轮之后会采用完全贪婪的方式来选取action。
实验与结果
我是参考OpenAI的小车爬山的代码进行仿写和改进的,效果不错,如下图所示。
2019.06.17,version 1.0
代码:https://github.com/shanxuanchen/wechat_jump_rlLearning
(以后对强化学习更深入了之后再改)