服务治理
分布式跟踪系统
在现在各大互联网应用中,通常都是采用微服务的方式进行复杂大规模的分布式部署,由于互联网应用的访问量相比传统应用的访问量会高很多,通常会根据自身公司的发展扩展服务器,有可能用到千台以上的服务器,甚至跨机房。在微服务的体系中,会划分为不同的业务领域应用,例如:订单中台、交易中台、库存中心等。每个领域有各自的团队。一个业务请求通常会横跨几个业务领域,例如:订单下单就会横跨从交易中台到订单中心,到库存中心等。如何才能更好的跟踪每一个请求呢?我们需要一些可以帮助跟踪和分析问题的工具。因些分布式跟踪系统就是为了解决上述问题而设计的。分布式跟踪系统主要是为了解决以下几个核心问题,调用链跟踪,监控报警及问题定位,帮助分析和监控系统性能及健康度。分布式跟踪系统是服务治理中比较核心的系统之一。
服务治理需要考虑的各方面
1.支持主机监控、容器监控、JVM监控 和 业务监控。支持实时日志查看,日志采集分析。
2.支持调用链分析、异常总览、慢 SQL分析、应用拓扑大屏和自定义方法堆栈跟踪等功能, 基于探针技术,完全无侵入代码。
3.提供应用诊断功能,支持 GC 诊断、类冲突、类加载分析、对象内存分布、本地方法耗时追踪、热点线程堆栈快照、数据库连接池分析、WEB 服务连接池分析。
4.应用运行期检查功能,提供改进报告和一键优化方案。
5.支持自定义报警规则,监控信息自动对接报警
最大挑战
目前在整个服务治理过程中我们面临的最大挑战分别是:logging(日志)、tracing(跟踪)metrics(统计)。
Logging,Metrics 和 Tracing 有各自专注的部分。
1.Logging - 日志系统,用于收集和上报分散在各服务应用的日志事件,分析日志。例如,应用程序的调试信息或错误信息,业务发生的信息。是诊断问题的依据。
2.Metrics - 用于记录可聚合的数据。例如,每一个服务的请求量,最大最小值,平均值,最长调用时间,平均调用时间等。
3.Tracing - 用于针对每人个请求的跟踪需求。例如,一次远程方法调用的执行过程和耗时。排查系统性能问题的利器。
以点线面的概念去理解Logging ,Tracing 和Metrics:Logging就是点,一切发生的所有事件都记录下来,通过Tracing串起所有的点,跟踪线中的每一步的执行。多个条串起来形成一个面就是Metrics,用于衡量一个服务的指标及健康度
日志收集对服务治理的重要性
Logging是服务治理及服务跟踪的基础,如果没法对分布的日志做集中收集和管理,将无法实现服务治理。日志收集目前比较常用的分布式日志解决方案有ELK。分布式日志是一个比较大的话题,里面涉及如何快速收集、存储及日志检索等。本文将不展开深入讲解分布式日志的实现。
跟踪Tracing
相关理论
Google Dapper ,是Google公布了它的Dapper分布式的监控系统的论文,在文中介绍了google生产环境中大规模分布式系统下的跟踪系统Dapper的设计和使用经验
论文 http://bigbully.github.io/Dapper-translation/
在GoogleDapper的论文中,抽取了3个我认为比较核心的点。1、跟踪系统对业务系统的影响要足够小。2、做到应用透明无感知。3、做好性能的评估及平衡实时性。
1.低消耗:跟踪系统对在线服务的影响应该做到足够小。在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
2.应用级的透明:对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的bug或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。面对当下想Google这样的快节奏的开发环境来说,尤其重要。
3.延展性:Google至少在未来几年的服务和集群的规模,监控系统都应该能完全把控住。
一个额外的设计目标是为跟踪数据产生之后,进行分析的速度要快,理想情况是数据存入跟踪仓库后一分钟内就能统计出来。
模型
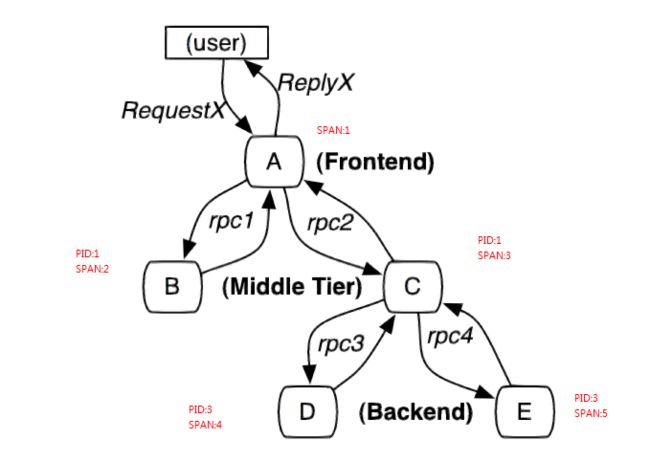
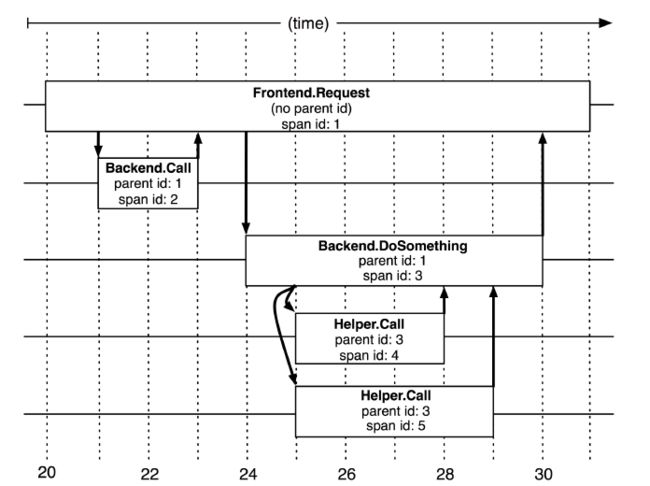
在Tracing的模型中,需要感知的是第一个span对应的父结点是什么。每一个span都会有自己的一些核心指标,在Dapper论文中就列出了如下核心指标如:
tracid。记录这次调用的ID是什么,主要用于可以取tracId返跟踪整个调用链中发生的所有行为。
name,id,pid 。记录每一步行为的名字和id,通过pid跟踪父级
Start/End。记录从哪里开始,服务到哪里结束
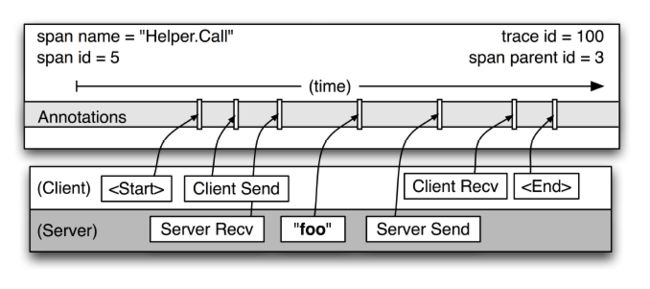
CS/SC/SS/CR。记录调用时间
OpenTracing规范
基于Tracing模型开发的tracing系统有很多种,各有不同的模型,为了统一所有模型和规范,解决各分布式追踪系统API不兼容的问题,因此诞生了OpenTracing规范 https://opentracing.io/
目前基于OpenTracing规范开发的分布式追踪系统有很多,例如:
https://skywalking.apache.org
https://www.jaegertracing.io/docs/1.13/frontend-ui/
https://zipkin.io
OpenTracing的span模型
{
"trace_id": "52.70.15530767312125341",
"endpoint_name": "Mysql/JDBI/Connection/commit",
"latency": 0,
"end_time": 1553076731212,
"endpoint_id": 96142,
"service_instance_id": 52,
"version": 2,
"start_time": 1553076731212,
"data_binary": "CgwKCjRGnPvp5eikyxsSXhD///////////8BGMz62NSZLSDM+tjUmS0wju8FQChQAVgBYCF6DgoHZGIudHlwZRIDc3FsehcKC2RiLmluc3RhbmNlEghyaXNrZGF0YXoOCgxkYi5zdGF0ZW1lbnQYAiA0",
"service_id": 2,
"time_bucket": 20190320181211,
"is_error": 0,
"segment_id": "52.70.15530767312125340"
}
唯品会的span模型
private String traceId;
private String id;
private String parentId;
private String spanName;
private String serviceId;
private List annotations = new ArrayList();
private List binaryAnnotations = new ArrayList();
private List metricAnnotations;
private boolean isSample;
private SpanType spanType;
private String company;
private String secLevel;
private String app;
private String host;
private String port;
private Float sfq;
在唯品的span模型中,核心字段离不开之前Dapper论文中提及的多个核心属性:traceId,parentId,id。
使用annoations存放ClientSend/ServiceRec/ServerSend/ClientRecv数据
为了更好区分由微服务产生的各种衍生出来的数据链路,如SQL调用,reids调用的链路跟踪等,对span模型添加了span类型。
为了解决高并发时,日志大量写入的问题,对span模型加了sfq采样率。
SQL("sql", "sql", Integer.valueOf(1)),
CACHE("cache", "cache", Integer.valueOf(2)),
HTTP("http", "http", Integer.valueOf(3)),
LOG("log", "log", Integer.valueOf(4)),
METRIC("metric", "metric", Integer.valueOf(5)),
OSP("osp", "osp", Integer.valueOf(6)),
HTTP_SERVER("http_server", "http_server", Integer.valueOf(7)),
OSP_SERVER("osp_server", "osp_server", Integer.valueOf(8)),
REDIS("redis", "redis", Integer.valueOf(9)),
KAFKA("kafka", "kafka", Integer.valueOf(10)),
RABBITMQ("rabbitmq", "rabbitmq", Integer.valueOf(11)),
METHOD("method", "method", Integer.valueOf(12)),
THRIFTCLIENT("thriftclient", "thriftclient", Integer.valueOf(13)),
THRIFTSERVER("thriftserver", "thriftserver", Integer.valueOf(14)),
KV("kv", "kv", Integer.valueOf(15)),
MEMCACHED("memcached", "memcached", Integer.valueOf(16)),
HBASE("hbase", "hbase", Integer.valueOf(17)),
OSP_PROXY("osp_proxy", "osp_proxy", Integer.valueOf(19)),
ROOT_METHOD("root_method", "root_method", Integer.valueOf(20)),
DATA_SOURCE("data_source", "data_source", Integer.valueOf(21));
Tracing系统对应用的影响及如何降低开销
探针在日志采集时对系统有二个影响:
高峰流量下,会产生大量的落盘日志,对系统disk I/O的性能影响较大
探针构建完span对象后,在落盘前需要转成json格式,这一步转化比较消耗CPU
如何有效降低开销:
使用采样的方式,降低开销。自适应的采样率,在低吞吐量时候提高采样率,在高吞吐量时自动降低采样率。
允许降级,延迟数据的收集频率。
分布式追踪系统建设的核心问题
实现一个分布式追踪系统离不开三个核心问题:
如何采集tracing和metric生成的数据信息
通过什么方式做数据存储
怎么呈现
以基于OpenTracing规范开源的skywalking为例:
在skywaling的项目中分别有3个子项目分别负责解决上报、存储、呈现的问题。
agent:采集tracing(调用链数据)和metric(指标)信息并上报
OAP:收集tracing和metric信息通过analysis core模块将数据放入持久化容器中(ES,H2(内存数据库),mysql等等),并进行二次统计和监控告警
webapp:前后端分离,前端负责呈现,并将查询请求封装为graphQL提交给后端,后端通过ribbon做负载均衡转发给OAP集群,再将查询结果渲染展示
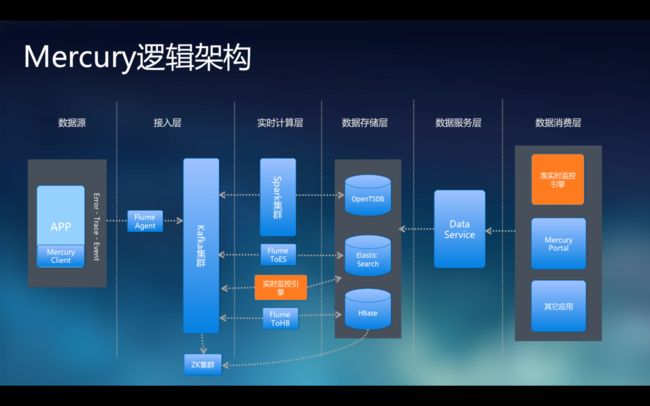
以唯品的Mercury架构为例: