1、基本简介
1.1 为什么要用sqlalchemy,直接用pymysql 或者cx_oracle 不香吗?
orm 框架 和sqlalchemy
简单来说就是orm 框架就是用类的方式来管理数据库。把每一行数据看作一个对象。
sqlalchemy 是orm 比较常用的框架 。
参见大神的解释。
2、基本操作
参考资料
2.1 初始化连接 需要用到两个包
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('mysql://pass@localhost/test',echo=True)
DBSession = sessionmaker(bind=engine)
session = DBSession()
ret=session.execute('desc user')
print ret
# print ret.fetchall()
print ret.first()
注意在这个create_engine 中
engine = create_engine('mysql://pass@localhost/test',echo=True)
参数为 数据库连接类型 :// user : password @ ip地址(可加[:端口])/ 数据库
例如:
- 连接sqlserver:
'mssql+pymysql://user:[email protected]/test' - 连接oracle :
'oracle://user:[email protected]/test' - 连接mysql
'pymysql://user:[email protected]/test' (存疑代证)
有时候还在会后面加上 connect_args ={'charset':'utf8'}
session 就相当于游标
2.2 创建表
from sqlalchemy import Column
from sqlalchemy.types import *
from sqlalchemy.ext.declarative import declarative_base
BaseModel = declarative_base()
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('mysql://root:Hs2BitqLYKoruZJbT8SV@localhost/test')
DBSession = sessionmaker(bind=engine)
class User(BaseModel):
__tablename__ = 'user1' # 表名
user_name = Column(CHAR(30), primary_key=True)
pwd = Column(VARCHAR(20), default='aaa', nullable=False)
age = Column(SMALLINT(), server_default='12')
accout = Column(INT())
birthday = Column(TIMESTAMP())
article = Column(TEXT())
height = Column(FLOAT())
def init_db():
'''
初始化数据库
:return:
'''
BaseModel.metadata.create_all(engine)
def drop_db():
'''
删除所有数据表
:return:
'''
BaseModel.metadata.drop_all(engine)
drop_db()
init_db()
一旦表被创建了,修改User类不能改变数据库结构,只能用sql语句或删除表再创建来修改数据库结构
2.3.添加记录
user1=User(user_name='lujianxing',accout=1245678)
session.add(user1)
session.commit()
要commit才能起作用
2.4.更新记录
- 2.4.1.更新单条记录
query = session.query(User)
user = query.get('lujianxing11')
print user.accout
user.accout='987'
session.flush()
- 2.4.2.更新多条记录
query = session.query(User)
query.filter(User.user_name=='lujianxing2').update({User.age: '15'})
query.filter(User.user_name=='lujianxing2').update({'age': '16'})
query.filter(User.pwd=='aaa').update({'age': '17'})
2.5.删除记录
query = session.query(User)
user = query.get('lujianxing11')
session.delete(user)
session.flush()
2.6.查询(最重要)
query = session.query(User)
print (query ) # 只显示sql语句,不会执行查询(!!!工程中经常用!!!)
print (query[0] ) # 执行查询
print (query.all()) # 执行查询
print (query.first()) # 执行查询
for user in query: # 执行查询
print (user.user_name)
- 高级一点的查询:
# 筛选
user = query.get(1) # 根据主键获取
print query.filter(User.user_name == 2) # 只显示sql语句,不会执行查询
print query.filter(User.user_name == 'lujianxing').all() # 执行查询
print query.filter(User.user_name == 'lujianxing', User.accout == 1245678, User.age > 10).all() # 执行查询
print query.filter(User.user_name == 'lujianxing').filter(User.accout == 1245678).all()
print query.filter("user_name = 'lujianxing'").all() # 执行查询
print query.filter("user_name = 'lujianxing' and accout=1245678").all() # 执行查询
query2 = session.query(User.user_name) # 返回的结果不是User的实例,而是元组
print query2.all() # 执行查询
print query2.offset(1).limit(1).all() # 等于 limit 1,1
# 排序
print query2.order_by(User.user_name).all()
print query2.order_by('user_name').all()
print query2.order_by(User.user_name.desc()).all()
print query2.order_by(User.user_name, User.accout.desc()).all()
print query2.filter("user_name = 'lujianxing' and accout=1245678").count()
# 聚合查询
print session.query(func.count('*')).select_from(User).scalar()
print session.query(func.count('1')).select_from(User).scalar()
print session.query(func.count(User.id)).scalar()
print session.query(func.count('*')).filter(User.id > 0).scalar() # filter() 中包含 User,因此不需要指定表
print session.query(func.count('*')).filter(User.name == 'a').limit(1).scalar() == 1 # 可以用 limit() 限制 count() 的返回数
print session.query(func.sum(User.id)).scalar()
print session.query(func.now()).scalar() # func 后可以跟任意函数名,只要该数据库支持
print session.query(func.current_timestamp()).scalar()
print session.query(func.md5(User.name)).filter(User.id == 1).scalar()
3、项目常用操作方法
项目文件结构如下:
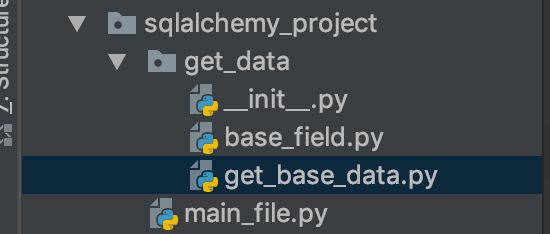
image.png
主要是为了批量查询,所以已经假设很多表已经建好,存好。
3.1. base_field.py (定义表的类)
from sqlalchemy import Column
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.types import Float,VARCHAR,String,Numeric,DateTime,Integer,NVARCHAR
Base = declarative_base()
## j假设存在的表为User
## 定义表的类
class User(Base):
# 表的名字:
__tablename__ = 'user'
# 表的结构:
id = Column(String(20), primary_key=True) # 一定要设这个主键
name = Column(String(20))
在这个文件里,可以设置很多的表的类,统一定义
3.2. get_base_data.py(取数)
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import pandas as pd
## 导入base_field 中的表
from get_data.base_field import User
from sqlalchemy_project import singleton ## 3.4 会讲
## 定义取数的地址和游标
@ singleton ## 3.4 中会讲
class BaseData(object):
def __init__(self):
host = '0.0.0.0'
user= 'user'
password ='pass'
database = 'db'
# charset = 'utf8'
self.engine = create_engine('mssql+pymssql://'+
user + ":"+
password + "@"+
host +'/'+
database)
self.Session = sessionmaker(bind=self.engine)
self.session =self.Session()
class GetBaseData(object):
def __init__(self,base_data):# 传进去一个实例
self.engine = base_data.engine
self.session = base_data.session
# 开始查询数据
def get_query_data(self):
query = self.session.query(User).filter(User.name =='tom')
df = pd.read_sql(query.statement,self.engine)
return df
3.3. main_file.py(主文件)
from get_data.get_base_data import BaseData,GetBaseData
if __name__ =='__main__':
base_data = BaseData()
base_data_obj = GetBaseData(base_data)
df = base_data_obj.get_query_data()
print(df)
3.4 singleton (限制一个实例是一样的)
在主文件下放一个这singleton.py 的文件
# -*- coding: utf-8 -*-
from functools import wraps
def singleton(cls):
instances = {}
@wraps(cls)
def get_instance(*args,**kw):
if cls not in instances:
instances[cls] = cls(*args,**kw)
return instances[cls]
return get_instance
具体的原理 ,后面会专门出一个。(列上链接的地方)
4 sqlalchemy 插入df数据
# -*- coding: utf-8 -*-
# ------------------------------
# @Time : 2020/7/16
# @Author : wangyd
# @File : insert_df.py
# @Project : sqlalchemy insert database
# ------------------------------
from sqlalchemy import types
import sqlalchemy
import os
import pandas as pd
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.AL32UTF8'
# sqlserver
engine = sqlalchemy.create_engine('mssql+pymssql://user:password@ip/database',
connect_args={'charset':'utf8'})
data=pd.DataFrame({'a':[1,2,3,4],'b':['a','b','c','d']})
## 注意这一步要变成大写
data.columns = [x.upper()for x in data.columns]
## tosql
dtypes= {}
# 注意下面的是小写
dtypes['a'] = types.Numeric(20,4)
dtypes['b'] = types.VARCHAR(4)
# 插入数据库,注意TABLE_NAME 大写,这个表需要提前在数据库中创建好
data.to_sql('TABLE_NAME',con=engine,if_exists='append',index=False,
dtypes= dtypes,index_label=None)
注意大小写
在type[小写] 其他数据都大写
5、注意事项
5.1 主键
在取数的过程中,使用sqlchemy 调用数据的过程,必须在原表中增加 primary key 。所有在data_base_field 中也得在主键后面增加 primary key
5.2 主键
可以从sqlalchemy 中导入 func_,_or 等方便查询辅助的函数
6、sqlalchemy filter 总结
参考资料
from flask import Flask, jsonify, json
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float, func, and_, or_
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from datetime import datetime
# 连接数据库字符串
DB_URI = "mysql://root:[email protected]/pyDemo"
engine = create_engine(DB_URI)
# 判断是否连接成功
engine.connect()
# 创建ORM
Base = declarative_base(engine)
# 创建回话
session = sessionmaker(engine)()
class Article(Base):
# 表名字
__tablename__ = 'Article'
# 列
id = Column(Integer, primary_key=True, autoincrement=True)
# read_count = Column(Integer, default=0)
title = Column(String(50), default='1111')
content = Column(String(50))
price = Column(Float, nullable=False)
# 查询条件
# 1.equal
res = session.query(Article).filter(Article.id == 21).first()
# print(res)
# 2.notequal
res = session.query(Article).filter(Article.id != 21).all()
# print(res)
# 3.like & ilike不区分大小写
res = session.query(Article).filter(Article.title.like('title%')).all()
# print(res)
# 4.in
res = session.query(Article).filter(Article.title.in_(['title0', 'title1'])).all()
# print(res)
# 5.not in
res = session.query(Article).filter(~Article.title.in_(['title0', 'title1'])).all()
# print(res)
res = session.query(Article).filter(Article.title.notin_(['title0', 'title1'])).all()
# print(res)
# 6.isnull
res = session.query(Article).filter(Article.content == None).all()
# print(res)
# 7.is not null
res = session.query(Article).filter(Article.content != None).all()
# print(res)
# 8 and
res = session.query(Article).filter(Article.content == None, Article.title.notin_(['title0', 'title1'])).all()
# print(res)
res = session.query(Article).filter(and_(Article.content == None, Article.title.notin_(['title0', 'title1']))).all()
# print(res)
# 9 or
res = session.query(Article).filter(
or_(Article.content != None, Article.title.notin_(['title0', 'title1', 'title5']))).all()
print(res)
参考资料
注意问题
1、oracle 数据库中读取数据,如果中文,需要设置编码
记录一个成功的写法,借助cx_Oracle,
import cx_Oracle
create_orgine("oracle+cx_oracle://user:password@host/database",connect_args = {
'encoding' = 'UTF-8',
'nencoding' = 'UTF-8',
'events' = True)