重点内容:
- 数据采集及清理
- 运用各类图形函数,调用数据绘制对应可视化图表
数据采集
本案例应用的是UCI的华盛顿自行车租赁数据,数据表地址如下:https://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset
对于在线的数据表压缩包,需要在引用代码中制定路径。为避免数据量过大、占用内存资源等问题,通常会定义临时文件夹来存放数据。
import pandas as pd #读取数据到dataframe
import urllib #获取url数据
import tempfile #创建临时文件夹,大量临时数据放在内存中会占用大量资源,可以使用临时文件来进行储存。临时文件不用命名,且使用后会被自动删除
import shutil #文件操作
import zipfile #压缩解压
#获取数据
temp_dir = tempfile.mkdtemp() #建立临时目录,用于下载线上的zip数据表并解压
data_source = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip'
zipname = temp_dir + '/Bike-Sharing-Dataset.zip' #拼接文件和路径
try:
urllib.urlretrieve(data_source,zipname) #获取数据
except:
urllib.request.urlretrieve(data_source,zipname)
zip_ref = zipfile.ZipFile(zipname,'r') #创建zipefile对象处理压缩文件
zip_ref.extractall(temp_dir) #解压
zip_ref.close()
#清理数据
daily_path = temp_dir + "/day.csv"
daily_data = pd.read_csv(daily_path) #读取csv
daily_data['dteday']=pd.to_datetime(daily_data['dteday']) #把时间字符串转换为日期格式
drop_list = ['instant','season','yr','mnth','holiday','workingday','weathersit','atemp','hum'] #去掉不关注的列
daily_data.drop(drop_list, inplace =True, axis=1)
shutil.rmtree(temp_dir) #删除临时文件目录
#查看数据
daily_data.head()
数据表结果如下:
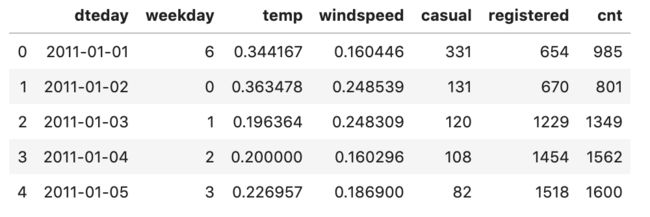
image.png
全局样式参数配置
样式可以做为独立的模块,方便后期对图表全局的样式进行统一配置
import matplotlib
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
%matplotlib inline
#全局配置图像
#设置图片尺寸
matplotlib.rc('figure',figsize=(14,7)) #rc=resource configuration
#matplotlib.rc('figure',facecolor='red')
#设置全局字体
matplotlib.rc('font',size=14)
#设置背景网格
matplotlib.rc('axes',grid=False)
#设置背景颜色
matplotlib.rc('axes',facecolor='white')
可视化
在了解数据以及数据之间的关系以后,通过不同类型的图表可视化数据之间的关系,说明要表达的内容观点。
用matplotlib实现图表可视化分为两块内容:
- 配置基础图表函数(模版化)
- 调用数据赋予给图表,生成根据数据绘制的图表
案例:散点图
- 配置散点图函数模版
#散点图函数模版,单独列出便于复用
def scatterplot(x_data,y_data,x_label,y_label,title,ax = None):
if ax:
pass
else:
fig,ax = plt.subplots() #fig,ax是figure和axes的缩写,使用该函数来确定图的位置,fig是图像对象,ax是坐标轴对象
#不显示顶部和右侧的坐标线
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.scatter(x_data,y_data,s=10,color="blue",alpha=0.7)
#添加标题和坐标说明
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
- 调用数据绘制图表
#调用数据绘制图表,观点:表达温度和租车人数的正相关关系
scatterplot(x_data = daily_data['temp'],
y_data = daily_data['cnt'],
x_label = 'normalized temperature',
y_label = 'check outs', #租车量
title = 'numbers of check outs vs temperature')

image.png
图表函数模版
下面分享一下各类图表的函数模版,具体调用数据部分不再列出
1.双轴曲线图
#双轴曲线图
def lineplot(x_data,x_label,y1_data,y1_label,y1_color,y2_data,y2_label,y2_color,title):
ax1=plt.subplot() #一个figure里面可以包含多个axes
ax1.plot(x_data,y1_data,color=y1_color)
ax2=ax1.twinx()#关键函数,表示ax2和ax1共用x轴
ax2.plot(x_data,y2_data,color=y2_color)
#不显示顶部的坐标线
ax1.spines['top'].set_color('none')
ax2.spines['top'].set_color('none')
#添加标题和坐标说明
ax1.set_title(title)
ax1.set_xlabel(x_label)
ax1.set_ylabel(y1_label)
ax2.set_ylabel(y2_label)
2.直方图
#直方图
def histoplot(data,x_label,y_label,title):
_,ax = plt.subplots() # _,多个变量时需使用
res = ax.hist(data,color = '#539caf',bins=10) #res输出图形的细节值
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_title(title)
return res
3.堆叠直方图
#堆叠直方图,比较两个数据的分布
def overlaid_histoplot(data1,data1_name,data2,data2_name,x_label,y_label,title):
max_nbins = 10
data_range = [min(min(data1),min(data2)),max(max(data1),max(data2))] #对齐两组数据的起止位置
binwidth = (data_range[1] - data_range[0])/max_nbins
bins = np.arange(data_range[0],data_range[1]+binwidth,binwidth)
_,ax = plt.subplots()
ax.hist(data1,bins=bins,color = 'black',alpha=0.7,label=data1_name)
ax.hist(data2,bins=bins,color ='blue',alpha=0.7,label=data2_name)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_title(title)
ax.legend(loc='best')
4.柱状图
#绘制柱状图:数据处理,按照周来查看租车量的分布趋势
mean_data=daily_data[['weekday','cnt']].groupby('weekday').agg([np.mean,np.std])
mean_data.columns = mean_data.columns.droplevel()
#mean_data.head()#查看mean_data的数据
#定义绘制柱状图的函数
def barplot(x_data,y_data,x_label,y_label,title):
_,ax = plt.subplots()
ax.bar(x_data,y_data,align='center')
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_title(title)
barplot(x_data=mean_data.index.values,#为什么不用直接取weekday column?
y_data=mean_data['mean'],
x_label='day of weekdays',
y_label='number of mean check outs',
title="check outs by day of week")
5.堆积柱状图
#堆积柱状图
#数据处理,按照register和causual来查看不同类别用户的租车量分布趋势
mean_data_by_type =daily_data[['weekday','registered','casual']].groupby('weekday').mean()
mean_data_by_type['total']=mean_data_by_type['registered']+mean_data_by_type['casual']
mean_data_by_type['reg_%']=mean_data_by_type['registered']/mean_data_by_type['total']
mean_data_by_type['cas_%']=mean_data_by_type['casual']/mean_data_by_type['total']
#mean_data_by_type.head()#查看mean_data的数据
#定义堆积柱状图的函数
def stackedbarplot(x_data,x_label,y_data_list,y_data_name,y_label,colors,title):
_,ax = plt.subplots()
#循环绘制堆积柱状图
for i in range(0,len(y_data_list)):
if i ==0:
ax.bar(x_data,y_data_list[i],color=colors[i],align='center',label=y_data_name[i])
else:
ax.bar(x_data,y_data_list[i],bottom=y_data_list[i-1],color=colors[i],align='center',label=y_data_name[i])
#定义标题和图例
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_title(title)
ax.legend()
练习

image.png