本人目前也是在学习阶段,如在文章中有不对的地方欢迎指正~
OK,正篇开始~
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
目录
- 一、安装环境
- 二、基本环境准备
- 三、Hadoop伪·分布式搭建
- 四、Hadoop真·分布式搭建
- 五、搭建时可能遇到的坑
- 六、Hadoop基本使用
- 七、MapReduce简析
- 八、参考并致谢
一、安装环境
操作系统:CentOS 7
Hadoop版本:3.2.1
真·分布式搭建:
主机:192.168.111.249
从机1:192.168.111.247
从机2:192.168.111.248
伪·分布式搭建:
主机:192.168.111.123
二、基本环境准备
1、搭建的几种模式说明
- 本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。
- 模拟分布式模式:这是在单台机器的分布式模拟。Hadoop守护每个进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式对开发非常有用。
- 完全分布式模式:这种模式是完全分布式的最小两台或多台计算机的集群。
2、Hadoop与JDK兼容情况
Hadoop版本与JDK版本兼容关系大致可总结为:
hadoop版本>=2.7:要求Java 7(openjdk/oracle)
hadoop版本<=2.6:要求Java 6(openjdk/oracle)
3、该网站可查阅到当前最新版本
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
4、基础环境准备
这里使用的是VMware 14开的虚拟机,CentOS 7操作系统最小安装,并配置好网络,至于虚拟机怎么搭建,操作系统怎么装,网络怎么配置不在此篇章中,可自行度娘参考
具体配置如下:

三、Hadoop伪·分布式搭建
1、Java环境搭建配置
yum安装java
[root@bogon ~]# yum install java-1.8.0-openjdk* -y
java环境变量配置
which java定位到的是java程序的执行路径,而不是安装路径,经过两次-lrt最后的输出才是安装路径

/etc/profile文件中追加三行
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
export HADOOP_HOME=/home/hadoop-3.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

刷新环境变量
[root@bogon ~]# source /etc/profile
2、修改主机名
依次在/etc/hostname文件中写入master
在/etc/hosts文件中,将主机名写入

使用ping命令ping自己本机,并保证能ping通

3、配置免密登录
检查openssh-server是否已安装
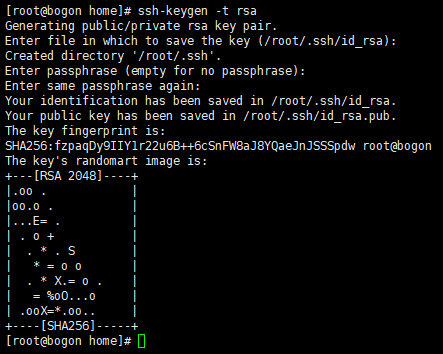
确保安装了openssh-server后,执行ssh-keygen -t rsa命令,然后回车(三次回车)
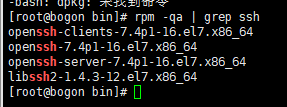
检查openssh-server是否已安装
[root@bogon ~]# rpm -qa | grep ssh
确保安装了openssh-server后,每台机器执行ssh-keygen -t rsa,然后回车(三次回车)
生成的公钥私钥都保存在~/.ssh下,在master上将公钥放入authorized_keys,命令如下
[root@bogon ~]# cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
使用 ssh master测试,检查是否成功配置免密登录(第一次登录会询问是否同意免密登录,之后登录此询问不再出现)
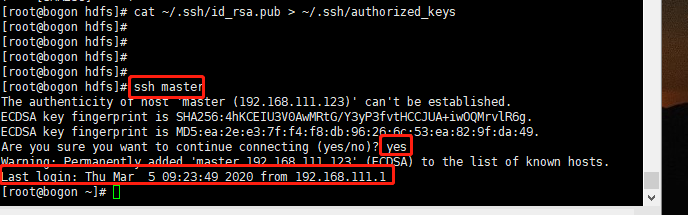
安装Hadoop
从网站中下载对应的版本(这里下载了3.2.1)到/home/目录下
解压文件
[root@bogon ~]# tar zxvf hadoop-3.2.1
进入到解压后的目录,创建hdfs目录,进入到hdfs目录,创建name,data,tmp三个目录
说明
./hdfs/name --存储namenode文件
./hdfs/data --存储数据
./hdfs/tmp --存储临时文件
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs/name
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs/data
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs/tmp


修改配置文件
需要修改的文件和所在目录如下所示,要注意的是,2.9版本的slaves文件在3.0版本后名称改为workers
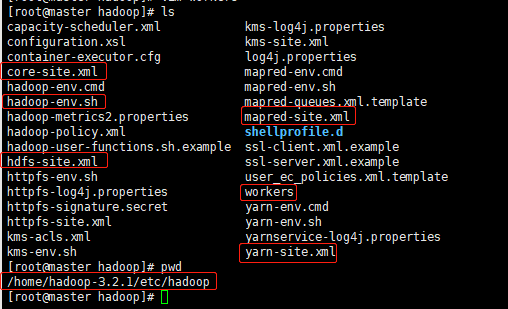
hadoop-env.sh
文件修改的是java的安装路径,跟一开始配置JAVA环境变量的时候写的Java路径一致

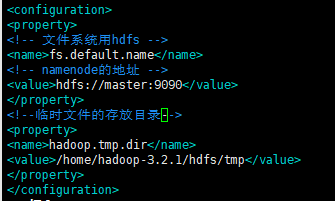
core-site.xml
在configuration标签中插入如下内容
fs.default.name
hdfs://master:9090
hadoop.tmp.dir
/home/hadoop-3.2.1/hdfs/tmp
hdfs-site.xml
在configuration标签中插入如下内容
dfs.replication
1
dfs.name.dir
/home/hadoop-3.2.1/hdfs/name
dfs.data.dir
/home/hadoop-3.2.1/hdfs/data
dfs.permissions
false
dfs.http.address
0.0.0.0:50070
dfs.namenode.rpc-address
192.168.111.249:9000

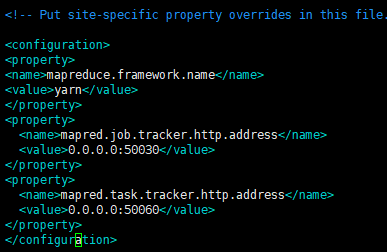
mapred-site.xml
在configration标签之间插入如下内容:
mapreduce.framework.name
yarn
mapred.job.tracker.http.address
0.0.0.0:50030
mapred.task.tracker.http.address
0.0.0.0:50060
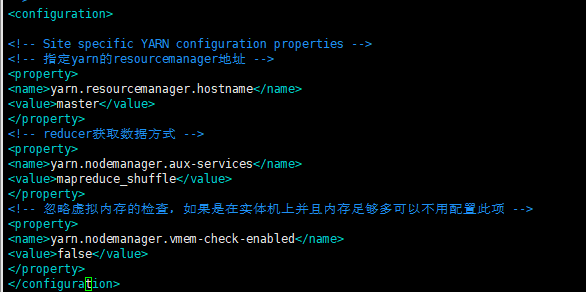
yarn-site.xml
在configuration标签中写入:
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.vmem-check-enabled
false
workers
将文件中的localhost删掉,然后改为本机的主机名master
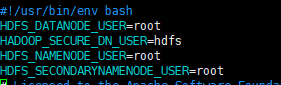
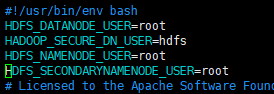
如果是使用linux的root用户启动和使用hadoop的话,那还需要在以下文件添加以下配置
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
start-dfs.sh
stop-dfs.sh
start-yarn.sh

stop-yarn.sh

启动前进行格式化
[root@bogon ~]# hadoop namenode -format
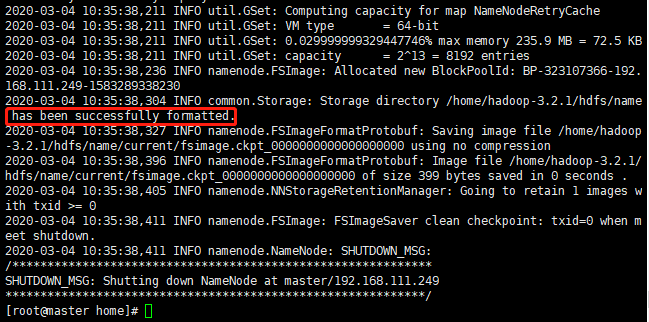
最后出现successfully formatted说明格式化成功
此时name目录下会多出一个current文件夹

使用start-all.sh启动
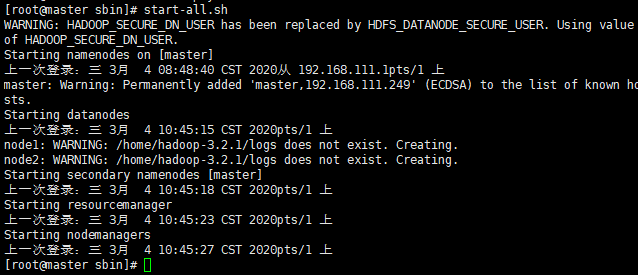
使用jps查看进程
在浏览器网页端管理各个节点状态
打开浏览器,访问master IP:50070(如192.168.111.123:50070)即可进入到图形管理界面
至此伪·分布式的Hadoop已搭建完毕
四、Hadoop真·分布式搭建
1、Java环境搭建配置
yum安装java
[root@bogon ~]# yum install java-1.8.0-openjdk* -y
java环境变量配置
which java定位到的是java程序的执行路径,而不是安装路径,经过两次-lrt最后的输出才是安装路径
/etc/profile文件中追加三行
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64
export HADOOP_HOME=/home/hadoop-3.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新环境变量
[root@bogon ~]# source /etc/profile
2、修改主机名
依次在/etc/hostname文件中,主节点写入master,从节点写入node1或node2
依次在/etc/hosts文件中,将本机和所有节点的主机名写入

使用ping相互测试,并保证能ping通



3、配置节点之间免密登录
效果就是在master上输入ssh node1即可登陆node1,否则开启集群服务时,master与node无法连接,会报出connection refused
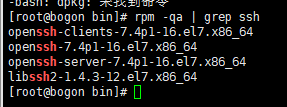
检查openssh-server是否已安装
[root@bogon ~]# rpm -qa | grep ssh
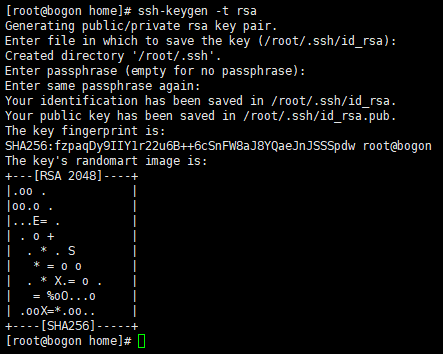
确保安装了openssh-server后,每台机器执行ssh-keygen -t rsa,然后回车(三次回车)
生成的公钥私钥都保存在~/.ssh下,在master上将公钥放入authorized_keys,命令如下
[root@bogon ~]# cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
将master上的authorized_keys放到其它机器上
[root@bogon ~]# scp ~/.ssh/authorized_keys root@node1:~/.ssh/
[root@bogon ~]# scp ~/.ssh/authorized_keys root@node2:~/.ssh

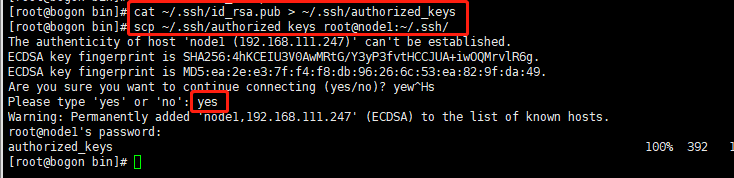
在master端使用 ssh node1测试,node2使用同样的方法测试
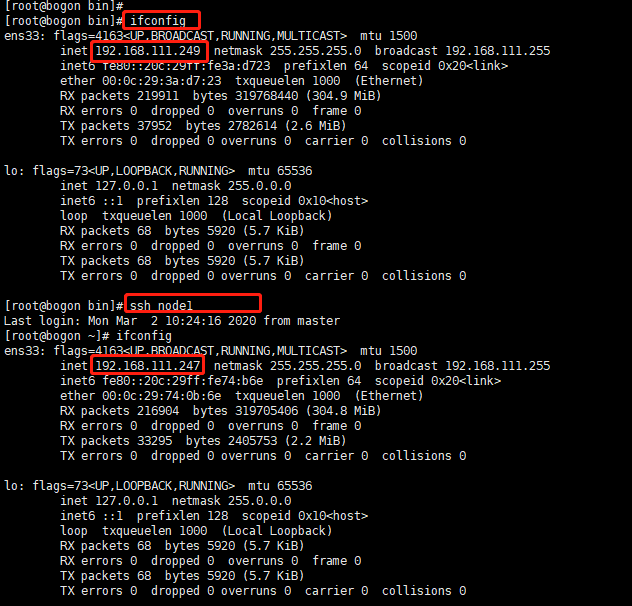
安装Hadoop
从网站中下载对应的版本(这里下载了3.2.1)到/home/目录下
解压文件
[root@bogon ~]# tar zxvf hadoop-3.2.1
进入到解压后的目录,创建hdfs目录,进入到hdfs目录,创建name,data,tmp三个目录
说明
./hdfs/name --存储namenode文件
./hdfs/data --存储数据
./hdfs/tmp --存储临时文件
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs/name
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs/data
[root@bogon ~]# mkdir /home/hadoop-3.2.1/hdfs/tmp
修改配置文件
需要修改的文件和所在目录如下所示,要注意的是,2.9版本的slaves文件在3.0版本后名称改为workers
hadoop-env.sh
文件修改的是java的安装路径,跟一开始配置JAVA环境变量的时候写的Java路径一致
core-site.xml
在configuration标签中插入如下内容
fs.default.name
hdfs://master:9090
hadoop.tmp.dir
/home/hadoop-3.2.1/hdfs/tmp
hdfs-site.xml
在configuration标签中插入如下内容
dfs.replication
3
dfs.name.dir
/home/hadoop-3.2.1/hdfs/name
dfs.data.dir
/home/hadoop-3.2.1/hdfs/data
dfs.permissions
false
dfs.http.address
0.0.0.0:50070
dfs.namenode.rpc-address
192.168.111.249:9000
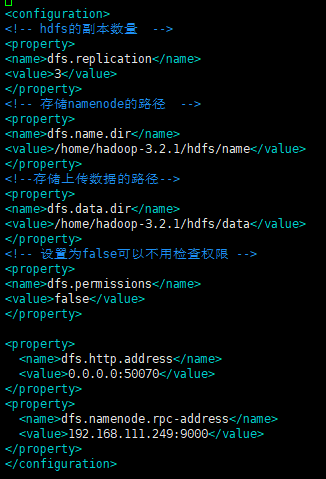
注意: 注意以上配置文件中的dfs.namenode.rpc-address配置项,该配置项的值填写namenode所在的服务器,如果需要用到Hbase、spark等组件的话一定要配置这一项,否则在Hbase启动的时候会报拒绝连接的错误,如果有多个namenode,那么配置值中各个namenode的值用逗号隔开
mapred-site.xml
在configration标签之间插入如下内容:
mapreduce.framework.name
yarn
mapred.job.tracker.http.address
0.0.0.0:50030
mapred.task.tracker.http.address
0.0.0.0:50060
yarn-site.xml
在configuration标签中写入:
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.vmem-check-enabled
false
workers
将文件中的localhost删掉,然后改为节点主机的主机名
如果是使用linux的root用户启动和使用hadoop的话,那还需要在以下文件添加以下配置
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh
启动前进行格式化
[root@bogon ~]# hadoop namenode -format
最后出现successfully formatted说明格式化成功
此时name目录下会多出一个current文件夹
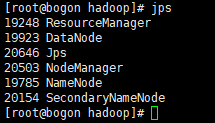
在master端start-all.sh启动
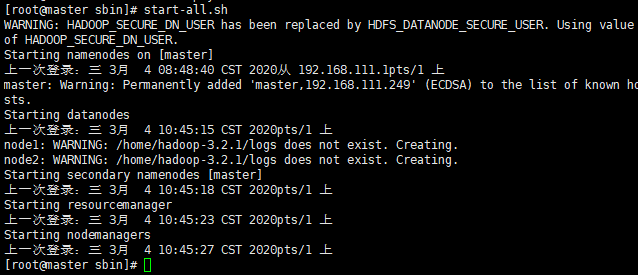
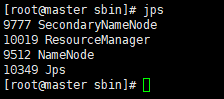
使用jps查看进程
master端
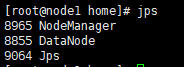
node1端
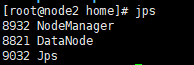
node2端
在浏览器网页端管理各个节点状态
打开浏览器,访问master IP:50070(如192.168.111.249:50070)即可进入到图形管理界面
至此真·分布式的Hadoop已搭建完毕
五、搭建时可能遇到的坑
问题1:浏览器master IP:50070网页打不开
思路1,检查selinux、防火墙是否已关闭,需要关闭selinux和防火墙,同时检查IP地址、端口号是否填写正确
思路2:
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh
此办法从网上贴吧中寻得,其中解决人提到CentOS上会出现该问题,而Ubuntu则可以不用配置也可以正常访问,此处没做具体测试
问题2:在执行start-all.sh时报Attempting to operate on hdfs namenode as root,but there is not HDFS_NAMENODE_USER defined. Aborting operation Sstating datanodes
思路:由于使用了root的用户启动Hadoop,而在启动文件中没有授权(或定义)该用户,解决方法如下:
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
1、然后删除主节点(master)上name目录下的文件夹(即我们一开始创建的hdfs/name这个目录下)
2、从节点上(node1和node2)删除data目录下的文件夹
3、然后在主节点重启执行格式化命令
4、接着在start-all.sh启动
5、如果是伪分布式的话也是同样的操作
六、Hadoop基本使用
# 常用命令简要总结
# 启动Hadoop
start-all.sh -- 此命令默认将hdfs和yarn也启动
starth.sh -- 只启动Hadoop
# 运行dfs
start-dfs.sh
# 运行yarn
start-yarn.sh
# 停止Hadoop
stop-all.sh -- 此命令默认将hdfs和yarn也停止
stoph.sh -- 只停止Hadoop
# 显示目录结构
hdfs dfs -ls -R /
# 在hadoop指定目录中创建新目录
hdfs dfs -mkdir /wei
# 将本地文件夹存储至Hadoop
hdfs dfs -put [本地目录] [hadoop目录]
# 将本地文件存储值Hadoop
hdfs dfs put [本地文件地址] [hadoop目录]
# 查看指定目录下内容
hdfs dfs -ls [目录路径]
# 打开某个已存在的文件
cat dfs -cat [文件路径]
# 在hadoop指定目录新建一个空文件
hdfs dfs -touchz [绝对路径/文件名]
# 将hadoop上某个文件重命名
hdfs dfs -mv [绝对路径/原文件名] [绝对路径/新文件名]
# 将hadoop上某个文件下载至本地已有目录
hdfs dfs -get [hadoop文件绝对路径] [本地绝对路径]
# 将Hadoop指定目录下所有文件内容保存为一个文件,同时下载至本地
hdfs dfs -getmerge /wei/hadoop-file /home/wei/test.txt
# 删除hadoop上指定文件
hdfs dfs -rm [文件地址]
# 删除hadoop上指定文件夹【包含子目录】
hdfs dfs -rm -r [目录地址]
hdfs dfs -rmr [目录地址]
# 将正在运行的hadoop作业kill掉
hadoop job -kill [job-id]
# 查看命令帮助
hdfs dfs -help
# 退出安全模式(NameNode在启动时会自动进入安全模式,安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改。
系统显示Name node in safe mode,说明系统正处于安全模式,这时只需要等待几十秒即可,也可通过下面的命令退出安全模式:)
hadoop dfsadmin -safemode leave
# 进入安全模式
hadoop dfsadmin -safemode enter
# 查看文件最后1kb内容
hdfs dfs –tail /wei/test.txt
# 修改HDFS系统中/user/sunlightcs目录所属群组,选项-R递归执行,跟linux命令一样
hdfs dfs –chgrp [-R] /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录拥有者,选项-R递归执行
hdfs dfs –chown [-R] /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录权限,MODE可以为相应权限的3位数或+/-{rwx},选项-R递归执行
hdfs dfs –chmod [-R] MODE /user/sunlightcs
# 显示该目录中每个文件或目录的大小
hdfs dfs –du PATH
# 类似于du,PATH为目录时,会显示该目录的总大小
hdfs dfs –dus PATH
# 查看PATH目录下,子目录数、文件数、文件大小、文件名/目录名
hdfs dfs –count [-q] PATH
七、MapReduce简析
MapReduce
Hadoop原理和处理机制是MapReduce,而MapReduce其实是Map和Reduce两个步骤,其中,Map可以理解为将任务分布出去,而Reduce可以理解为将分出去的任务合并回来,如下图所示:
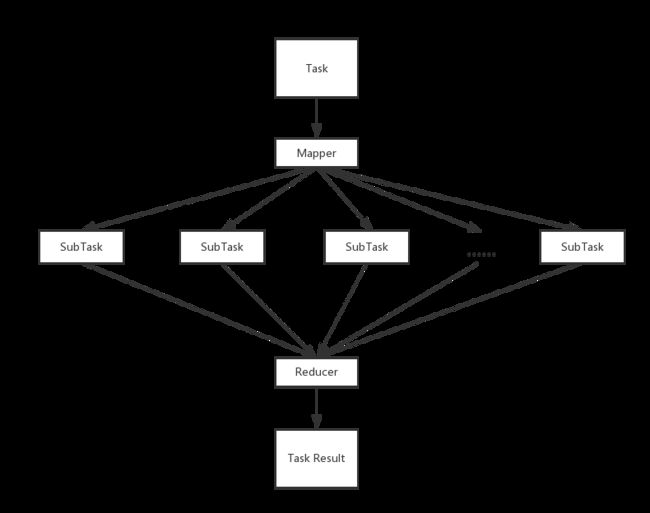
1、Map步骤,当主节点收到一个任务请求时(如是一个计算的任务),它会将这个任务按照子节点的数量拆分成多个子任务并分发出去
2、子节点收到任务后进行计算和处理数据
3、Reduce步骤,当数据处理完时,这些子节点会将任务的结果返回给主节点,之后主节点将所有的结果进行合并,并完成整个数据处理流程的过程
以下一个图是从网上找来的一个例子,可以帮助理解整个MapReduce的基本原理

八、参考并致谢
https://www.cnblogs.com/thousfeet/p/8618696.html
https://www.cnblogs.com/chaofan-/p/9740408.html
https://blog.csdn.net/suixinlun/article/details/81630902