【Java高薪面试宝典】Day3、图解HashMap高频面试及底层实现架构!
欢迎小伙伴订阅我的新专栏“Java高薪面试宝典”,在这里我将和大家分享在Java面试中常见的核心考点和技术,为大家的Java学习之路助一臂之力!
HashMap高频面试题
1,Map接口和List接口是什么关系?
2、Map有哪些常用的实现类?
3、请阐述HashMap的put过程?
4、链表中是按照怎样的顺序存放数据的?
5、Hash(key)方法是如何实现的?
6、为什么HashMap的容量一直是2的倍数?
7、Hash冲突如何解决?
8、HashMap是如何扩容的?
9、扩容后元素怎么存放的?
10、JDK1.7和JDK1.8对HashMap的实现比较
Hello,你好呀,我是灰小猿!一个超会写bug的程序猿!
Map接口大家应该都听说过吧?它是在Java中对键值对进行存储的一种常用方式,同样其中的HashMap我相信大家应该也不会陌生,一说到HashMap,我想稍微知道点的小伙伴应该都说是:这是存储键值对的,存储方式是数组加链表的形式。但是其中真正是如何进行存储以及它的底层架构是如何实现的,这些你有了解吗?
可能很多小伙伴该说了,我只需要知道它怎么使用就可以了,不需要知道它的底层实现,但其实恰恰相反,只知道它怎么使用是完全不够的,而且在Java开发的面试之中,HashMap底层实现的提问和考察已经是司空见惯的了。所以今天我就来和大家分析一下Map接口的详细使用以及HashMap的底层是如何实现的?
小伙伴们慢慢往下看,看完绝对会让你收获满满的!
1,Map接口和List接口是什么关系?
对于这个问题,如果非要说这两个接口之间存在怎样的关系的话,那无非就只有一个,就都是集合。存放数据的。在其他上面,Map接口和List接口的联系其实并不大,为什么这么说?
先来看List接口,关于List接口我在之前也和大家提到过,《【Java高薪面试宝典】Day2、谈一谈List接口的实现?》,它是继承于Collection接口的,是Collection接口的子接口,只是用于对数据的单列存储。继承关系如下图:

而Map接口是一个顶层接口,下面包含了很多不同的实现类,它是用于对键值对(key:value)进行存储的,实现关系如下图:

所以Map接口和List接口的关系和使用不要混淆了!
2、Map有哪些常用的实现类?
上面关于Map的继承结构我们已经了解了,我们也看了其中很多不同的实现类,这些类很多也是我们比较熟悉的,比如HashMap、TreeMap以及HashTable。在面试的时候,面试官往往就还会问,Map接口下有哪些常用的实现类以及它们的作用,那么接下来我们就来对这几个接口进行简单的介绍和分析一下,
HashMap:上面也说了,HashMap的底层实现是数组+链表+红黑树的形式的,同时它的数组的默认初始容量是16、扩容因子为0.75,每次采用2倍的扩容。也就是说,每当我们数组中的存储容量达到75%的时候,就需要对数组容量进行2倍的扩容。
HashTable:HashTable接口是线程安全,但是很早之前有使用,现在几乎属于一个遗留类了,在开发中不建议使用。
ConcurrentHashMap:这是现阶段使用使用比较多的一种线程安全的Map实现类。在1.7以前使用的是分段锁机制实现的线程安全的。但是在1.8以后使用synchronized关键字实现的线程安全。
其中关于HashMap的考察和提问在面试中是最频繁的,这也是在日常开发中最应该深入理解和掌握的。所以接下来就主要和大家详细分析一下HashMap的实现原理以及面试中的常考问题。
3、请阐述HashMap的put过程?
我们知道HaahMap使用put的方式进行数据的存储,其中有两个参数,分别是key和value,那么关于这个键值对是如何进行储存的呢?我们接下来进行分析一下。
在HashMap中使用的是数组+链表的实现方式,在HashMap的上层使用数组的形式对“相同”的key进行存储,下层对相应的key和value使用链表的形式进行链接和存储。
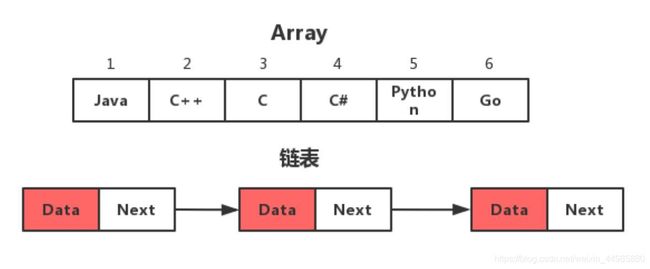
注意:这里所说的相同并不一定是key的数值相同,而是存在某种相同的特征,具体是哪种特征骂我们继续往下看!
HashMap将将要存储的值按照key计算其对应的数组下标,如果对应的数组下标的位置上是没有元素的,那么就将存储的元素存放上去,但是如果该位置上已经存在元素了,那么这就需要用到我们上面所说的链表存储了,将数据按照链表的存储顺序依次向下存储就可以了。这就是put的简单过程,存储结果如下:
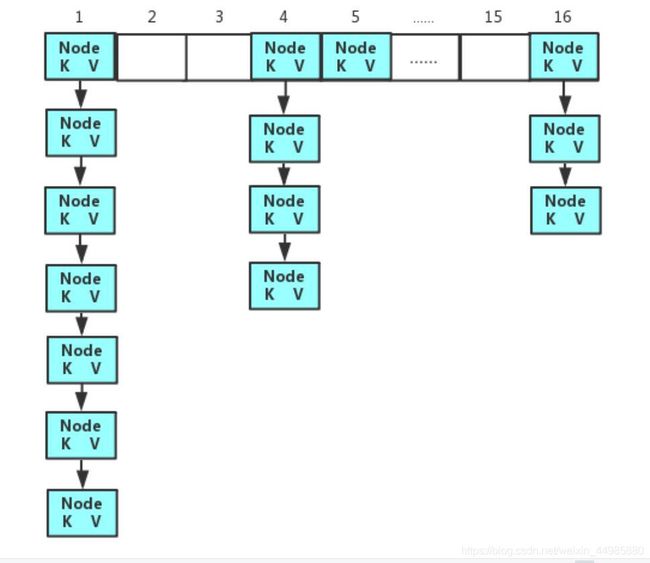
但是我们有时候存储的数据会很多,那么如果一直使用链表的形式进行数据的存储的话就或造成我们的链表的长度非常大,这样无论在进行删除还是在进行插入操作都是十分麻烦的,因此对于这种情况应该怎么办呢?
这里就涉及到了一个链表中数据存储时,进行“树化”和“链化”的一个过程,那么什么是“树化”和“链化”呢?
当我们在对键值对进行存储的时候,如果我们在同一个数组下标下存储的数据过多的话,就会造成我们的链表长度过长,导致进行删除和插入操作比较麻烦,所以在java中规定,当链表长度大于8时,我们会对链表进行“树化”操作,将其转换成一颗红黑树(一种二叉树,左边节点的值小于根节点,右边节点的值大于根节点),这样我们在对元素进行查找时,就类似于进行二分查找了,这样的查找效率就会大大增加。
但是当我们进行删除操作,将其中的某些节点删除了之后,链表的长度不再大于8了,这个时候怎么办?难道就要赶紧将红黑树转化为链表的形式吗?其实并不是,只有当链表的长度小于6的时候,我们才会将红黑树重新转化为链表,这个过程就叫做“链化”。
过程图示如下:

那么为什么要在长度8的时候进行“树化”,而在长度小于6的时候才进行“链化”呢?为什么不直接在长度小于8的时候就进行“链化”?
主要原因是因为:当删除一个元素,链表长度小于8的时候直接进行“链化”,而再增加一个元素,长度又等于8的时候,又要进行“树化”,这样反复的进行“链化”和“树化”操作特别的消耗时间,而且也比较麻烦。所以程序就规定,只有当当链表长度大于等于8的时候才进行“树化”,而长度小于6的时候才进行“链化”,其中关于8树化、6链化这两个阈值希望大家牢记!
4、链表中是按照怎样的顺序存放数据的?
我们现在已经知道了HashMap中的元素是如何存放的,但是有时候面试官可能还会问我们,在HashMap中,向链表中存储元素是在头结点存储的还是在尾节点存储的?
这个我们需要知道,对于HashMap中链表元素的存储。
在JDK1.7以及前是在头结点插入的,在JDK1.8之后是在尾节点插入的。
5、Hash(key)方法是如何实现的?
我们现在已经知道了HashMap中的元素是如何存储的了,那么现在就是如何应该根据key值进行相应的数组下标的计算呢?
我们知道HashMap的初始容量是16位,那么对于初始的16个数据位,如果将数据按照key的值进行计算存储,一般最简单的方法就是根据key值获取到一个int值,方法是:
int hashCode = key.hashCode()
然后对获取到的hashCode与16进行取余运算,
hashCode % 16 = 0~15
这样得到的永远都是0—15的下标。这也是最最原始的计算hash(key)的方法。
但是在实际情况下,这种方法计算的hash(key)并不是最优,存放到数组中的元素并不是最分散的,而且在计算机中进行余运算其实是非常不方便的、
所以为了计算结果尽可能的离散,现在计算数组下标最常用的方法是:先根据key的值计算到一个hashCode,将hashCode的高16位二进制和低16位二进制进行异或运算,得到的结果再与当前数组长度减一进行与运算。最终得到一个数组下标,过程如下:
int hashCode = key.hashCode()
int hash = hash(key) = key.hashCode()的高16位^低16位&(n-1) 其中n是当前数组长度
同时在这里要提醒一点。
在JDK1.7和JDK1.8的时候对hash(key)的计算是略有不同的
JDK1.8时,计算hash(key)进行了两次扰动
JDK1.7时,计算hash(key)进行了九次扰动,分别是四次位运算和五次异或运算
其中扰动可能理解为运算次数
以上就是Hash(key)方法的实现过程。
6、为什么HashMap的容量一直是2的倍数?
HashMap的容量之所以一直是2的倍数,其实是与上面所说的hash(key)算法有关的,
原因是只有参与hash(key)的算法的(n-1)的值尽可能都是1的时候,得到的值才是离散的。假如我们当前的数组长度是16,二进制表示是10000,n-1之后是01111,使得n-1的值尽可能都是1,对于其他是2的倍数的值减1之后得到值也是这样的。
所以只有当数组的容量长度是2的倍数的时候,计算得到的hash(key)的值才有可能是相对离散的,
7、Hash冲突如何解决?
什么是Hash冲突?就是当我计算到某一个数组下标的时候,该下标上已经存放元素了,这就叫Hash冲突,很显然,如果我们计算数组下标的算法不够优秀的时候,很容易将存储的数据积累到同一个下标上面,造成过多的Hash冲突。
那么如何解决hash冲突?
最应该解决的其实就是让存储的key计算得到的数组下标尽可能的离散,也就是要求hash(key)尽可能的优化,数组长度是2的倍数。这也就是Hash冲突的主要解决方法。
具体可以查看下面HashMap关键部分的底层源码:
Hash(key)的底层实现
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}put(key,value)方法的底层实现
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
8、HashMap是如何扩容的?
我们在上面说到了HashMap的数组的初始容量是16,但是很显然16个存储位是显然不够的,那么HashMap应该如何扩容呢?
在这里需要用到一个参数叫“扩容因子”,在HashMap中“扩容因子”的大小是0.75,
我们上面也提到过,对于初始长度为16的数组,当其中存储的数据长度等于16*0.75=12时。就会对数组元素进行扩容,扩容量是原来数组容量的2倍,也就是当前是15话,再扩容就是扩容32个数据位。
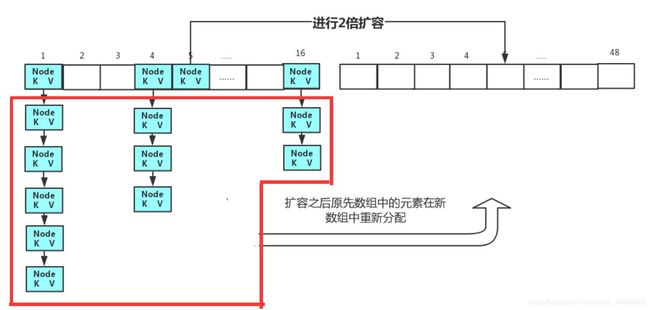
9、扩容后元素怎么存放的?
我们知道HashMap的数组在进行扩容之后,数组长度是增加的,那么这个时候,后面新扩容的部分就是空的。但是这个时候我们就应该让后面的数据位空着吗?显然是不可能的,这样会造成内存的很大浪费。
因此在HashMap的数组扩容之后,原先HashMap数组中存放的数据元素会进行重新的位置分配,重新将元素在新数组中进行存储。以充分利用数组空间。
10、JDK1.7和JDK1.8对HashMap的实现比较
在JDK1.7和JDK1.8中对HashMap的实现是略有不同的,最后我们根据上面的讲解对JDK1.7和JDK1.8在HashMap的实现中的不同进行分析比较。
(1)、底层数据结构不同
在HashMap的put过程中,JDK1.7时是没有红黑树这一概念的,直接是进行的链表存储,在JDK1.8之后才引入了红黑树的概念,来优化存储和查找。
(2)、链表的插入方式不同
在HashMap向链表中插入元素的过程中,JDK1.7时是在表头节点插入的,JDK1.8之后是在尾节点插入的。
(3)、Hash(key)的计算方式不同
在Hash(key)的计算中,JDK1.7进行了九次扰乱,分别是四次位运算和五次异或运算,JDK1.8之后只进行了两次扰动。
(4)、扩容后数存储位置的计算方式不同
在扩容后对存储数据的重新排列上,JDK1.7是将所有数据的位置打乱,然后根据hash(key)进行重新的计算,而在JDK1.8之后是对原来的数据下标进行了两次for循环。计算出新下标位置只能是在原下标位置或者在原下标位置加上原容量位置。
好了,关于Map接口和HashMap的底层实现的过程,以及在面试中参考的核心问题就和大家分析到这里!
有问题的小伙伴可以在评论区留言提出!觉得不错记得点赞关注哟!
我是灰小猿!我们下期见!