文 | 全世界最乖巧的小猪
Zoom-in-Net: Deep Mining Lesions for Diabetic Retinopathy Detection
这是一篇关于糖尿病视网膜病变分级诊断的论文,由来自港中文、清华大学等作者发表于MICCAI2018,下载地址:Zoom-in-Net: Deep Mining Lesions for Diabetic Retinopathy Detection
摘要
本文提出了一种能够同时诊断糖网病并突出可疑病灶区域的卷积神经网络,主要贡献体现在以下两方面:1)提出放大网络,模拟医生在诊断时放大图像的过程。仅仅在图像级(image-level)的监督下训练,放大网络就可以生成注意力图(attention map)来显示可疑病灶点区域,并综合整张图像和其中高分辨率的可疑patches,来准确地预测疾病等级。2)由注意力图生成的仅4个边框(bounding box)就足以覆盖由医生标注出来的80%的病灶点,显示了注意力图强大的定位能力,通过将注意力图上高反应位置(high response locations)的特征聚类,可以发现非常有意义的簇,包含了糖网病中的潜在病灶。实验表明,本算法在EyePACS和Messidor数据集上的表现都超过了state-of-the-art方法,很不错!
1 文章简介
识别医疗图像的可疑区域非常重要,但是目前的工作主要依靠强监督,也就是需要精确的病灶点位置信息。由于标注医疗图像的成本太昂贵了,从而大大限制了数据集的规模,因此,急需一个算法,能够通过弱监督的方法利用大数据集同时进行分类和定位任务。
本文提出了广义弱监督学习框架,叫做基于卷积神经网络的放大网络。该方法可以进行准确分类,同时自动检测图像中的病灶点,仅用几个边框就可以达到高召回率。这个框架可以拓展到各种分类问题上,并为医生提供更方便的检查。
本文将在糖网病问题上验证这个框架的有效性,(此处跳过介绍糖网病和前人工作)。
放大网络使用了注意力机制,仅用图像级监督就可以生成注意力图。注意力图是一种热力图,表示哪些像素对最终图像级预测起到重要作用。此外,放大网络的确名副其实,它模拟了医生在诊断时,首先浏览整张图像来辨认病灶点,然后放大图像进一步验证病灶点的过程。放大网络在EyePACS数据集(也就是kaggle糖网病竞赛使用的数据集)和Messidor数据集上进行验证,表现都超过了state-of-the-art方法和普通医生。另外,注意力定位的准确率在200张专业医生标注的图像上进行验证,达到了0.82的召回率。注意力图中高反应位置的聚类区域显示了糖网病中非常有意义的病灶点。
2 放大网络结构框架
放大网络从糖网病检测的图像级监督中学习,却同时实现了图像分级和病灶点定位的功能。它模拟了医生在高分辨率图像上选择高度可疑的区域进行检查的放大过程,并通过全局图像和局部patches来预测最终的等级。
放大网络包括三个模块,如图1所示:用于DR分级的主网络(M-Net),用于生成注意力值的注意力网络(A-Net)和裁剪网络(C-Net),它将高注意力值的高分辨率patches作为输入,以修正M-Net的预测。预测结果分为五个种类:0-无病;1-轻度;2-中度;3-重度;4-增殖。
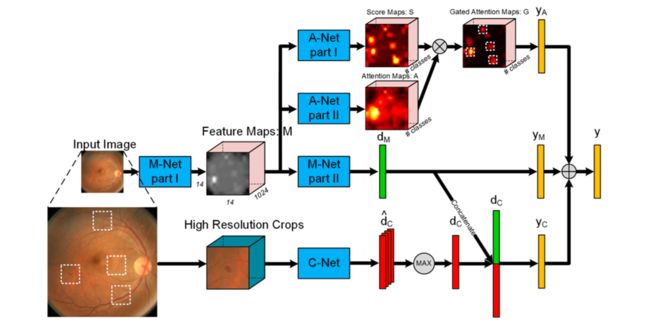
2.1 主网络(M-Net)
M-Net采用的是Inception-ResNet模型,模型结构参考Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning论文第7页。中间特征图M是在5 x inception_resnet_c层后提取得到的,,将M-Net分成了两个部分,后面紧跟一个全连接层,映射到一个概率向量,表示该图像属于每个患病等级的概率。M会进一步作为A-Net的输入。
由于Kaggle数据集提供了一个病人的左右眼图像,本文也就充分利用两只眼睛之间的关系。统计表明,超过95%的同一个病人的两只眼睛的等级区别不超过1,因此本文将M-Net中两只眼睛的特征连接在一起,以端到端的方式训练网络。
2.2 注意力网络(A-Net)
A-Net将特征图M作为输入,包括两个分支,第一个分支A-Net Part I 是一个1*1卷积核的卷积层,可以看作是应用在每个像素上的线性分类器,生成得分图(score maps),对应五个患病等级。第二个分支A-Net Part II 用三个卷积层生成注意力门图(attention gate maps),如图2所示。特别地,它为每个患病等级生成了独立的注意力门图。每个注意力图(attention map)由空间softmax操作得到。直观地,空间softmax迫使注意力值相互竞争,并且集中在最有信息的区域。因此将注意力图作为门控,A-Net的输出为:
其中,是A-Net的门控特征(gated feature:被门控制住了的特征),是得分图,是注意力图,对应第个类别,表示逐元素相乘。现在就可以计算最后的得分向量.

2.3 裁剪网络(C-Net)
通过放大可疑的注意力区域来进一步提高准确率,给定门控注意力图(gated attention maps:被注意力门控制住了的图 ),先把它resize成输入图像的大小,然后用贪心算法来采样区域,每次迭代中,记录G中最大反应的位置,然后遮罩掉它周围s*s的区域,防止这个区域再次被选中,重复这个过程,直到N个坐标(实验中N=4)都被记录(病入膏肓的时候),或者最大的注意力反应已经达到(病灶点还很少的时候),这一过程如图3所示:
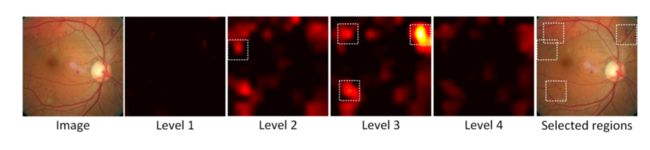
得到记录的位置后,裁剪原高分辨率图中相关patches,输入到C-Net中。C-Net的结构和inception-v3模型相似,参考Rethinking the Inception Architecture for Computer Vision。有所不同的是,它在global_pool层中结合了所有patches的特征 。由于一些patches没有病变(可能是因为需要四个框,但等级低的没那么多病灶点),所以在特征上用element-wise取最大值来提取最有信息的特征,然后把这个特征和从M-Net出来的连接起来分类。
3 注意力定位评估与理解
3.1 注意力定位评估
为了验证高反应区域包含了能够解释患病等级的线索,有请一位专业医生来标注182张EyePACS数据库中的图像,画边框来紧密覆盖病灶点,共标注了306个病灶点。(应该是不分病灶点种类的)
计算ground truth和采样框之间的IoM(intersection over minimum),采样框就是C-Net里用的四个框。如果IoM高于阈值,则采样框正确。本文画了两条召回率曲线,分别是对人和对框VS阈值。对人召回率表示只要一个人标注的ground truth 框被采样框检索到,就认为此人正确。因此,这比对框召回率要高。注意,我们在IoM阈值为0.3时达到了0.76(对框)和0.83(对人)的召回率。这表明A-Net仅仅用图像级监督就可以准确定位病灶点。我们认为,增大注意力图的分辨率(14*14)可以进一步提高定位准确率。
3.2 注意力视觉理解
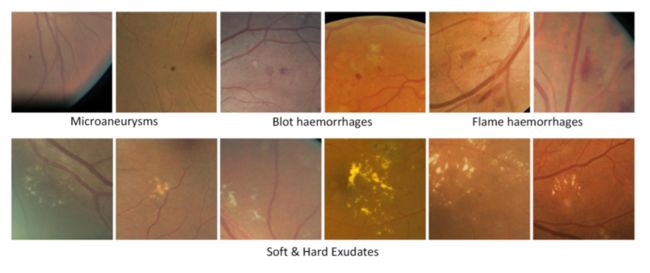
为了更好地理解网络,本文提出了基于聚类的方法来可视化门控注意力图(gated attention maps)中的最高反应位置。我们用AP聚类算法,将特征图M上相同位置的特征分割成簇,不需要预定的簇数量。我们可以恢复到它们相关图像区域作为C-Net输入,并将一些区域可视化,如图4所示。有些簇包含了非常有意义的病灶点比如微血管瘤啥的。这种操作可能会帮助医生找出一些新的病灶点。
4 定量评估
4.1 数据集与评估准则
EyePACS(也就是kaggle数据集):训练/验证/测试数量分别为35k/11k/43k,在不同的场景和设备下拍摄。提供每位患者的左右眼图像,以及医生给出的0-4级。采用相同的官方评价指标:二次加权kappa。
Messidor:公共数据集,包含1200张图像,每张图像提供两个等级,视网膜等级和XXX等级,这里只用视网膜等级。
4.2 实验细节
预处理:
1. 裁剪图像去掉没用的黑边;
2. 数据增强:随机旋转(0/90/180/270),随机翻转;
训练过程:
1. 先训练M-Net,基于Image-Net预训练;
2. 再训练A-Net,固定M-Net的参数;
3. 最后训练C-Net(M-Net和A-Net也同时训练)得到最终的放大网络。
4. 采用mini-batch SGD,初始学习率,步长20k,momentum=0.9,用caffe library训练。
4.3 EyePACS数据集实验结果
实验完整地评估了放大网络的每个部分:M-Net在val/test上分别达到0.832/0.825,加入A-Net之后仅增加了0.5%,这也不奇怪,因为A-Net里面没有加入什么附加信息。
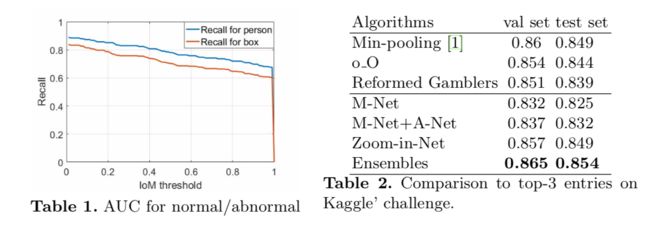
此外,我们用A-Net得到的门控注意力图(gated attention maps)来提取可疑区域并训练C-Net。可以在492*492的图像上观察到,病灶点区域通常小于200*200,因此,我们设置区域大小s=200,裁剪区域N=4. 我们从1230*1230的高分辨率图像中裁剪384*384的patches作为C-Net的输入,在放大网络训练过程中,一个mini-batch包含了图像的全图和4个高分辨率patches,这时候GPU就差不多爆满了,所以网络在每12个mini-batches之后更新参数。最终放大网络达到了0.857/0.849,三个模型集成结果达到0.865/0.854,超过了kaggle竞赛第一名min-pool(0.86/0.849).
5 结论
本文提出了一个新的框架:放大网络,在两个数据集上达到了state-of-the-art的表现。仅靠图像级的监督训练,放大网络可以生成注意力图,突出可疑区域。门控注意力图的定位能力我们也验证过了,很可靠。进一步的实验显示,门控注意力的高反应区域与潜在病灶点有关,因此可以用来进一步促进分类效果。