
CasperLabs节点发现
CasperLabs节点形成对等网络,不断相互通信以达成关于区块链状态的共识。CasperLabs节点不一定是单个物理计算机,但通过在节点对请求的响应中具有唯一的ID和地址,它对其余节点显示为单个逻辑实体。
节点根据CasperLabs协议的元素定期尝试发现彼此 。与最初使用UDP的CasperLabs不同,节点使用点对点gRPC调用进行通信。根据该协议,每个都Node具有以下属性:
id 是来自节点的SSL证书的公钥的Keccak-256摘要
host 是节点可访问的公共端点
discovery_port是实现的gRPC服务CasperLabsService 正在监听的地方
protocol_port 是实现共识相关功能的gRPC服务正在监听的地方
在CasperLabsService本身只实现两个方法:
Ping用于sender检查被叫方是否还活着。它也使被呼叫者有机会更新其对等方列表,并记住它已经看到了该sender节点。
Lookup问节点返回最接近的节点列表id 中sender寻找,其中根据其位的最长公共前缀的两个节点之间的距离id。
在启动时,应使用众所周知的对等方的地址来配置节点,以自举。要发现其他CasperLabs节点,可以从多种策略中进行选择:
id通过引导节点(尚不了解它们)自行执行一次一次性查找,以获取最接近其自身的对等方列表。递归地与那些对等节点执行相同的查找,以累积越来越多的地址,直到没有新要添加的内容为止。
定期构造人工密钥,以尝试在距id随机节点一定距离处找到对等CasperLabs节点并执行查找。
交互
CasperLabs节点通过查找可以彼此独立应用的Deploys并行提出Blocks。每当形成新的区块时,它就必须通过网络传播以成为共识的一部分。这是由节点通过GRPC对方打电话来调用他们的方法来实现GossipService 接口 应在被监听protocol_port的Node,表示网络中的同龄人。
原理
我们称之为在网络交互中传播信息的方法 。交互意味着,当节点遇到新的信息位时,它将把它中继给其选择的对等节点,这些节点将执行相同的操作,最终使网络饱和,即达到通知每个人的目的。
节点需要有关Block的三层信息才能参与共识:
阻止元数据,例如父母关系,验证者权重,状态散列。
给定块中包含的部署。
全局状态,以便能够运行部署,验证区块并在其之上构建新区块。
在这些节点中,只有前两个节点在节点之间交互。—全球状态,他们必须通过运行Deploys来计算自己。
我们的交互方法有以下要求:
它应该是有效的,即最小化网络流量,同时最大化我们达到完全饱和的速率。
节点运营商应该有一个合理的期望,即网络流量(有限的资源)将随着整个网络中Deploy的数量线性增长,而不受节点总数的影响。这意味着负载应在对等端之间分配,而不要创建热点。
为了实现这些目标,CasperLabs采用以下高级方法:
交互仅关于块的元数据,以最大程度地减少数据传输量。
当交互的元数据是新的时,可以按需提供完整块。
节点应根据它们可以处理的网络流量来选择中继因子,并发现有交互要传播给新信息的节点。
节点应该选择一个中继饱和目标,超过该目标,它们不会尝试推送到新的对等节点,因此最后一个收到消息的节点不必徒劳地联系其他所有对等节点。
节点应尝试将信息主要传播到更近的邻居(根据CasperLabs距离),但也应传播到其较远的对等节点,以加快信息向网络远距离的传播。
为交互挑选节点
正如我们在“节点发现” 部分中建立的那样,CasperLabs节点使用CasperLabs表维护对等方列表。该表在其ID的位之间的每个可能距离处都有一个存储桶,它们选择一个数字k作为它们跟踪的每个存储桶中节点列表的长度。
用统计术语来说,网络中一半的节点将落在第一个存储桶中,因为它们的ID的第一位将是0或1。类似地,每个后续存储桶将占据网络其余部分的一半。由于每个存储桶的k相同,因此这意味着节点可以跟踪比其最近的邻居更多的邻居。这就是为什么在CasperLabs中,当我们执行查找时,我们会越来越接近任何人都知道的最佳匹配。
实际上,这意味着如果我们有一个由50个节点组成的网络,并且k由10个组成,那么从任何给定对等点的角度来看,有25个节点属于第一个存储桶,但它只能跟踪其中的10个;因此,它永远不会交互到没有表空间的另一半的15个节点。
我们可以利用这种偏度来发挥优势:说我们选择3的中继因子;如果我们确保始终将最远的非空存储桶中的1个节点通知最近的非空桶中的2个节点,则可以增加信息到达我们未跟踪的另一半板上的那些节点的机会。
下图对此进行了说明:左侧的黑色actor表示我们的节点,垂直分区表示与该节点的距离。中间的拆分表示板的右半部分落在CasperLabs表格中的一个桶下面。板上的黑点是我们跟踪的节点,灰色是我们不跟踪的节点。我们从网络的右半部分了解到的同行很少,但在左边的邻居更多,因为它被越来越细的存储桶所覆盖。如果我们选择要在整个距离范围内平均传播的节点,并且右侧的节点遵循相同的规则,则它将开始在板的这一侧分发我们的消息,而其弹跳的可能性要大于将其弹回左侧的可能性。
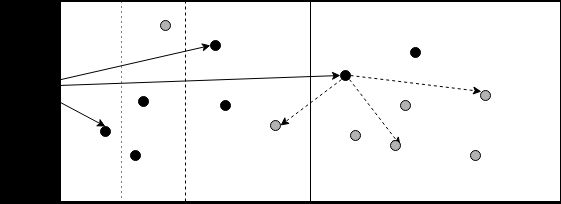
对等体之间的消息传播
就第二轮到达灰色节点的可能性而言,或者在第一轮或第二轮消息传递中消息仅位于板的右侧,收益是微不足道的,并取决于在第二轮中有多少对等点。卡德姆里亚表。我们可以对到达网络未跟踪部分的存储桶赋予更高的权重,但是必须模拟效果。
实际上,消息不必到达网络上的每个节点。实现100%饱和将是不切实际的,因为这将需要高级别的冗余,即,一个节点多次从不同的对等方接收相同的消息。跟踪谁看到了一条消息可能会使消息的大小膨胀或对其进行篡改。但是,即使一个CasperLabs节点没有收到通知的特定块 ,现在,它具有接收下一个块是建立在最重要的是,在这一点上可以赶上失踪链的平等机会。
因此,节点应具有中继饱和度值,超过该值时,它们将不尝试向新节点传播消息。例如,如果我们选择5的中继因子和80%的中继饱和度,则足以尝试最多发送25个节点。如果我们发现其中少于5个对等人是新信息 ,则我们的饱和度超过80%。这样可以防止出现以下情况:获取消息的最后一个节点必须联系其他每个节点,而徒劳地尝试将其传播5次以上。假设每个节点跟踪网络中对等点的随机子集,我们在尝试联系的节点中观察到的饱和度是整个网络中饱和度的近似值,其准确性取决于我们尝试了多少个节点。
algorithm BlockGossip is
input: message M to send,
relay factor rf,
relay saturation rs,
CasperLabs table K
output: number of messages sent s
s <- 0
P <- flatten the peers in K, ordered by distance from current node
G <- partition P into R equal sized groups
n <- an empty set to track notified peers
m <- rf / (1 - rs) // the maximum number of peers to try to send to
i <- 0 // the index of the current group
while i < sizeof(G) and s <= rf and sizeof(n) < m:
p <- a random peer in G(i)-n or None if empty
if p is None then
i <- i + 1
else
n <- n + p
r <- the result of sending M to p, indicating whether M was new to p
if r is true then
i <- i + 1
s <- s + 1
return s
公平
我们可以正确地问一下,面对不想在数据分发中分摊份额的恶意行为者,上述概述的交互算法如何发挥作用,即,如果CasperLabs节点决定不传播消息,会发生什么?
共识协议具有针对惰性验证器的内置保护:要从其他人产生的Block中获取费用,他们必须在此基础上构建。当他们这样做时,就必须交互,否则它就不会成为DAG的一部分,或者如果出现冲突块,它就会变得孤立,因此,交互以稳定的速度进行符合每个人的利益。
如果他们决定向所有人宣布自己的区块,但从不中继其他节点的其他区块怎么办?他们有一些这样做的诱因:
如果每个人都会这样做,那么创建者未知的节点将在以后获得它,并可能产生冲突的块,共识会变慢。
当他们最终宣布一个Block时,他们构建的每个人都将尝试直接从他们那里下载它,这给他们的网络增加了额外的负担。另外,他们可能还必须下载节点以前无法中继的额外块。
如果我们必须直接中继到100个CasperLabs节点,则100个节点中的每个节点很容易花费更长的时间从1个节点下载,然后10个节点这样做然后再中继到10个以上节点。
具有中继因子以及返回信息是否为新信息的机制,其目的如下:
通过指示该信息是新信息,被呼叫者正在向呼叫者发送信号,告知其一旦完成了对Block的验证,它将中继该信息。因此,呼叫者可以满意地知道,通过通知此节点它执行了要执行的交互次数,即,它将必须为整个块提供R次数的服务。
通过指示该信息不是新信息,被呼叫者表示将不再中继信息,因此,如果呼叫者希望履行其中继到R个新节点的承诺,则呼叫者应选择另一个节点。
节点希望那些表明块元数据对他们来说是新的块,以便以后尝试下载完整的块。这可能不会发生,因为其他节点也可能会通知它们,在这种情况下,它们可以从此处下载一些块,也可以从此处下载一些块。
在这里可以发生两种形式的伪证:
被呼叫者可以说该信息不是新信息,但是无论如何都尝试下载数据。节点可以通过跟踪彼此的信誉并阻止对其撒谎的节点来对此产生抑制作用。
被呼叫者可以说该信息是新信息,但不是中继信息。这也违背了他们自己的利益,但是很难发现。较高的中继因子可以补偿网络上的骗子数量。
如果节点收到有关无法验证的阻止的通知或在被询问时通知者无法提供服务的通知,则节点也可以使用信誉跟踪和阻止。
同步
让我们仔细看看如何使用所支持的方法GossipService在节点之间传播有关块的信息。
NewBlocks
当节点创建一个或多个新块时,它应根据其中继因子选择多个对等点,然后调用NewBlocks它们,并向它们传递新的对等点block_hashes。对等方检查它们是否已经具有相应的块:如果没有,则表明该信息是新信息,并计划从进行下载sender,否则,调用方会寻找其他对等方进行通知。
通过仅发送块哈希,我们可以将消息大小保持为最小。甚至块头也需要包含很多信息,CasperLabs节点才能进行基本验证。如果接收端已经知道了所有信息,则无需发送所有信息。
请注意,该sender值是正确的,因为通过gRPC相互通信的节点必须使用双向SSL加密,这意味着被叫方将在SSL证书中看到呼叫者的公钥。将sender只能是 Node与id公共密钥的散列相匹配。
StreamAncestorBlockSummaries
当节点收到NewBlock有关其不知道的哈希的请求时,它必须将其Block DAG与同步sender。一种实现方法是在节点中运行某种下载管理器,该管理器包括:
维护BlockSummary已看到的记录的部分连接的DAG
尝试通过从发送方下载新的位将其连接到现有的位
跟踪哪些节点通知了每个块,以了解可供下载的替代资源
跟踪它承诺中继到其他节点的块
下载并验证完整块
如果已承诺将已验证的块通知给同行
StreamAncestorBlockSummaries这是一种高级方法,CasperLabs调用者节点可以用它来请求另一个方法来到达刚刚大喊的那个块。这是一种从目标块沿其父对象向后遍历,直到每个祖先路径都可以连接到调用者的DAG的方法。它具有以下参数:
target_block_hashes 通常是通知节点有关的新块的哈希值,但是如果需要多次迭代才能找到连接点,则可以将其进一步返回DAG。
known_block_hashes可以由调用方提供以提供遍历的早期存在标准。例如,这些可以包括靠近呼叫者DAG的尖端的哈希,分叉,从验证程序看到的最后一个Blocks和批准的Blocks(即,具有较高安全阈值的Blocks)。
max_depth可以由调用方提供以限制遍历,以防万一 known_block_hashes不尽早停止它。当我们要回去这可以是迭代过程中非常有用超出批准块求助者,在这种情况下,它可能难有起色称为哈希。
结果应为按BFS反向顺序对DAG进行部分遍历, 返回BlockSummaries调用者可以部分验证的流,并合并到其待处理块的DAG中,然后递归调用 StreamAncestorBlockSummaries未与已知部分连接的任何块。 DAG。最终,所有道路都回到了创世纪。因此最终我们应该找到连接,否则呼叫者可以决定放弃寻求来自恶意行为者的潜在错误线索。
下图说明了该算法。图中的点代表方框;外圈较厚的是通过的 target_block_hashes。虚线矩形是从一次调用到的流中返回的内容StreamAncestorBlockSummaries。
最初,我们只知道构成我们DAG的黑色方块。
我们收到关于白色块的通知,该块尚未包含在我们的DAG中。
我们将StreamAncestorBlockSummaries传递白色块的哈希值作为目标,并将a设为max_depth2(也传递一些我们已知的块哈希值)。
BlockSummary从第1条开始,我们获得了两个相反的记录流,并将它们添加到DAG中。但是,我们可以看到,我们仍然不了解白色街区的祖父母。
我们称StreamAncestorBlockSummaries第二次以祖父母的哈希为目标。
从第二个流中,我们可以看到至少有一个块连接到了DAG的尖端,但是又有一些缺少依赖项的块。
我们StreamAncestorBlockSummaries第三次打电话,现在我们可以与DAG的已知部分建立完整连接,不再有缺少父母的块。
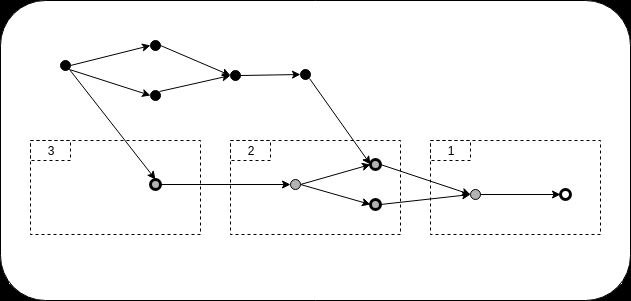
CasperLabs向后遍历以同步DAG
以下CasperLabs算法描述了服务器的角色:
algorithm StreamAncestorBlockSummaries is
input: target block hashes T,
known block hashes K,
maximum depth m,
block summary map B
output: stream of ancestry DAG in child to parent order
G <- an empty DAG of block hashes
Q <- an empty priority queue of (depth, hash) pairs
A <- an empty list of ancestor block summaries
V <- an empty set of visited block hashes
for each hash h in T do
push (0, h) to Q
while Q is not empty do
pop (d, h) from Q
if h in V then
continue
if h is not in B then
continue
b <- B(h)
A <- A + b
V <- V + h
for each parent hash p of b do
G <- G + (h, p)
if d < m and p not in K do
push (d+1, p) to Q
return stream of A
下一个从客户端的角度描述了CasperLabs同步DAG:
algorithm SyncDAG is
input: sender node s,
new block hashes N,
block summary map B
output: new block summaries sorted in topological order from parent to child
G <- an empty DAG of block hashes
A <- an empty map of block summaries
m <- a suitable maximum depth, say 100
function Traverse is
input: block hashes H
output: number of summaries traversed
S <- s.StreamAncestorBlockSummaries(H, m)
for each block summary b in S do
if b cannot be validated then
return 0
if b is not connected to H with a path or the path is longer than m then
return 0
if we see an abnormally shallow and wide DAG being built then
// the server is trying to feed exponential amount of data
// by branching wide while staying within the maximum depth
return 0
h <- the block hash of b
A(h) <- b
for each parent p of b do
if p is not in B do
G <- G + (p, h)
return sizeof(S)
Traverse(N)
define "hashes in G having missing dependencies" as
hash h having no parent in G and h is not in B
while there are hashes in G with missing dependencies do
H <- the hashes in G with missing dependencies
if Traverse(H) equals 0 then
break
if there are hashes in G with missing dependencies then
return empty because the DAG did not connect
else
return A(h) for hashes h in G sorted in topological order from parent to child
SyncDAG 需要采取一些保护措施,以防恶意行为者试图将其引向花园小径并向其提供无限的数据流。
一旦SyncDAG表明,CasperLabs从摘要sender中NewBlocks 与我们有DAG共同的祖先,我们可以安排数据的下载。
Q <- an empty queue of blocks to sync
G <- an empty DAG of block dependencies in lieu of a download queue
S <- a map of source information we keep about blocks
GBS <- the global block summary map
GFB <- the global full block map
function NewBlocks is
input: sender node s,
new block hashes N
output: flag indicating if the information was new
H <- find hashes h in N where h is not in GBS
if H is not empty then
push (s, H) to Q
return true
return false
parallel threads Synchronizer is
for each (s, N) message m in Q do
D <- SyncDAG(s, N, GBS)
for each block summary b in D do
r <- if hash of b is in N then true else false
ScheduleDownload(b, s, r)
function ScheduleDownload is
input: block summary b,
sender node s,
relay flag r
h <- the hash of b
if h is in GBS then
return
if h is in S then
S(h) <- S(h) with extra source s
if r is true then
S(h) <- S(h) with relay true
else
N <- the list of potential source nodes for b with single element s
S(h) <- (b, N, r)
if any parent p of b is in pending downloads G then
add h as a dependant of p in G
else
add h to G without dependencies
parallel threads Downloader is
rf <- the relay factor from config, say 5
rs <- the relay saturation from config, say 0.8
for each new item added to G or after an idle timeout do
while we can mark a new hash h in G without dependencies as being downloaded do
(b, N, r) <- S(h)
n <- a random node in N
f <- the full block returned by n.GetBlockChunked(h)
if f is valid then
GFB(h) <- f
GBS(h) <- b
remove h from G
if r is true then
K <- the current CasperLabs table of peers
s <- the current node
BlockGossip(NewBlocks(s, h), rf, rs, K)
GetBlockChunked
CasperLabs包含所有部署的完整块可能会变得很大,并且gRPC底层的HTTP / 2协议对其在请求正文中可以传输的最大消息大小有限制。因此,我们需要将有效负载分解成较小的块,将它们作为流传输,并在另一端进行重构。
调用者应跟踪接收到的数据,并将其与content_length最初在标头中获得的数据进行比较 ,以确保没有收到无限的数据流。
从理论上讲,该方法可以返回多个块的流,但是无论如何从单个源下载,都应优先考虑在通知到达节点的替代源时,从多个对等方一个一个地请求它们。
StreamLatestMessages
当一个新节点加入网络时,它应该向一个或多个对等节点询问其DAG的技巧,即他们自己将在其上提议新区块的区块。随后可以进行任意数量的调用,StreamAncestorBlockSummaries直到新节点已下载并使用上述算法部分验证了完整DAG。值得相互关联多个节点的提示,以免被任何单个恶意行为者欺骗。
通过不时选择随机对等点并询问其DAG技巧,也可以将相同的方法用于基于拉的交互。这弥补了通过基于推的交互尝试达到100%饱和的收益递减:随着我们达到完全饱和,越来越难找到一个没有信息的节点,因此越来越多的消息被无用地发送给已经从另一个对等方接收到等效消息的对等方;但是对于尚未到达的一小部分节点,与之通信的任何对等点都已经收到信息的可能性越来越大。
最后,以下序列图演示了节点之间块传播的生命周期。为简洁起见,虚线框未连接,但它们的作用与左侧的相同。
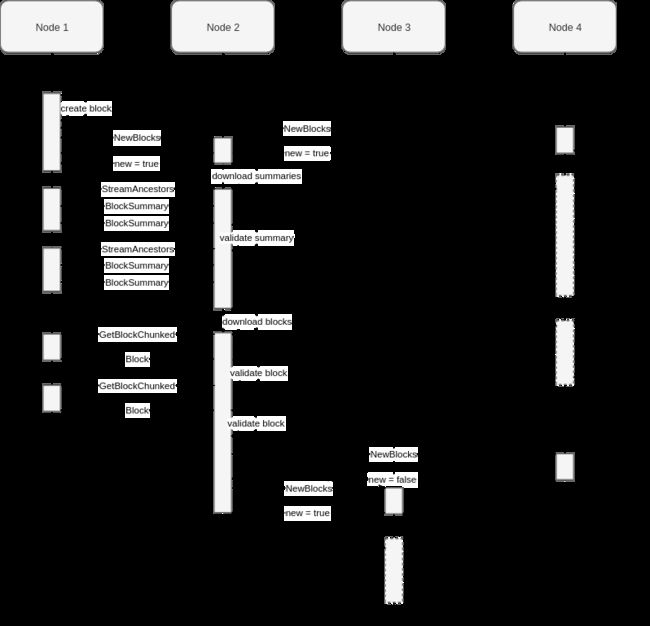
交互
部署交互
CasperLabs使用某些共识协议,节点只能在轮到他们时才生成块。为了确保用户可以将部署发送到任何节点,并看到它们包含在网络上的下一个可用块中,而与哪个验证者创建该块无关,节点需要彼此交互部署,而与块无关。
部署交互的原理和机制与上面描述的块交互完全相同。
一个块可能包含一个节点已经拥有的一个或多个部署,因此在下载一个块时,仅包含部署哈希及其执行结果,而排除部署主体和标头。一个下载节点通过部署散列导出缺少它的部署节点,并分别下载它们。
当节点(从用户或通过部署交互)接收到部署时,它应通知其一些对等节点其部署可供下载。语义与NewBlocks完全相同(使用相同的算法)。
节点使用此方法相互检索一个或多个部署。通常,在部署交互时会流式传输一个部署,但是当节点确定丢失了某个接收到的块中的一个或多个部署主体时(从该块中的部署哈希派生),它将请求丢失的所有部署。
CasperLabs语义与GetBlockChunked非常相似,但是流不包含单个项目,而是在标头块和内容之间交替,每组对应于请求中的一个部署哈希。
作者郑重申明:截至发文时,作者与文中提及项目皆不存在任何利益关系。