Hello,我是JAP君,相信经常使用爬虫的朋友对代理ip应该比较熟悉,代理ip就是可以模拟一个ip地址去访问某个网站。我们有时候需要爬取某个网站的大量信息时,可能由于我们爬的次数太多导致我们的ip被对方的服务器暂时屏蔽(也就是所谓的防爬虫防洪水的一种措施),这个时候就需要我们的代理ip出场了,今天我带大家来爬取西刺代理上面免费提供的代理ip并且我们来检测它的有效性来打造我们自己的代理ip池,废话不多说,咱们动工!
里面有很多的,每一个 都包含了我们所需要的数据。
看过我以前一些爬虫文章的朋友估计一下就知道该怎么下手了,但是不急我们还是来分析一下,毕竟这次数据量有点大,而且还得校验代理ip的有效性。
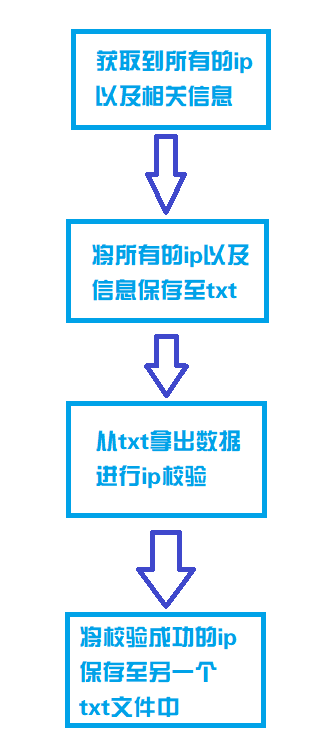
给大家画了张图,其实思路也很简单,也就不多阐述了。
3获取所有的代理ip以及相关信息并保存至文件txt中
我们就按照我们的思路来,在这里我们需要用到的几个库,给大家写出来:
from bs4 import BeautifulSoup
import requests
from urllib import request,error
import threading
导入库后,我们首先获得代理ip,我们来定义一个方法:(每一句的解释我都写在注释里了)
def getProxy(url):
# 打开我们创建的txt文件
proxyFile = open('proxy.txt', 'a')
# 设置UA标识
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit '
'/ 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36'
}
# page是我们需要获取多少页的ip,这里我们获取到第9页
for page in range(1, 10):
# 通过观察URL,我们发现原网址+页码就是我们需要的网址了,这里的page需要转换成str类型
urls = url+str(page)
# 通过requests来获取网页源码
rsp = requests.get(urls, headers=headers)
html = rsp.text
# 通过BeautifulSoup,来解析html页面
soup = BeautifulSoup(html)
# 通过分析我们发现数据在 id为ip_list的table标签中的tr标签中
trs = soup.find('table', id='ip_list').find_all('tr') # 这里获得的是一个list列表
# 我们循环这个列表
for item in trs[1:]:
# 并至少出每个tr中的所有td标签
tds = item.find_all('td')
# 我们会发现有些img标签里面是空的,所以这里我们需要加一个判断
if tds[0].find('img') is None:
nation = '未知'
locate = '未知'
else:
nation = tds[0].find('img')['alt'].strip()
locate = tds[3].text.strip()
# 通过td列表里面的数据,我们分别把它们提取出来
ip = tds[1].text.strip()
port = tds[2].text.strip()
anony = tds[4].text.strip()
protocol = tds[5].text.strip()
speed = tds[6].find('div')['title'].strip()
time = tds[8].text.strip()
# 将获取到的数据按照规定格式写入txt文本中,这样方便我们获取
proxyFile.write('%s|%s|%s|%s|%s|%s|%s|%s\n' % (nation, ip, port, locate, anony, protocol, speed, time))
上面的代码就是我们抓取西刺代理上的所有ip并将它们写入txt中,每一句的解释我都写在注释里面了,这里也就不多说了。
4校验代理ip的可用性
这里我是通过代理ip去访问百度所返回的状态码来辨别这个代理ip到底有没有用的。
def verifyProxy(ip):
'''
验证代理的有效性
'''
requestHeader = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
}
url = "http://www.baidu.com"
# 填写代理地址
proxy = {'http': ip}
# 创建proxyHandler
proxy_handler = request.ProxyHandler(proxy)
# 创建opener
proxy_opener = request.build_opener(proxy_handler)
# 安装opener
request.install_opener(proxy_opener)
try:
req = request.Request(url, headers=requestHeader)
rsq = request.urlopen(req, timeout=5.0)
code = rsq.getcode()
return code
except error.URLError as e:
return e
我们在这个方法中会得到一个状态码的返回,如果返回码是200,那么这个代理ip就是可用的。
def verifyProxyList():
verifiedFile = open('verified.txt', 'a')
while True:
lock.acquire()
ll = inFile.readline().strip()
lock.release()
if len(ll) == 0 : break
line = ll.strip().split('|')
ip = line[1]
port = line[2]
realip = ip+':'+port
code = verifyProxy(realip)
if code == 200:
lock.acquire()
print("---Success:" + ip + ":" + port)
verifiedFile.write(ll + "\n")
lock.release()
else:
print("---Failure:" + ip + ":" + port)
我们写完校验方法后,我们就从我们事先爬取到的所有代理ip的txt文件中获取到ip和端口(ip地址:端口),我们通过判断返回值是否为200来进行写入到有效的txt文件中。
5调用函数
万事俱备只欠调用!
if __name__ == '__main__':
tmp = open('proxy.txt', 'w')
tmp.write("")
tmp.close()
tmp1 = open('verified.txt', 'w')
tmp1.write("")
tmp1.close()
getProxy("http://www.xicidaili.com/nn/")
getProxy("http://www.xicidaili.com/nt/")
getProxy("http://www.xicidaili.com/wn/")
getProxy("http://www.xicidaili.com/wt/")
all_thread = []
# 30个线程
for i in range(30):
t = threading.Thread(target=verifyProxyList)
all_thread.append(t)
t.start()
for t in all_thread:
t.join()
inFile.close()
verifiedtxt.close()
因为西刺代理提供了四种代理ip,所以分别有四个网址。这里我们也采用了线程的方法,主要是为了防止出现线程互相争夺导致我们的数据不精确,在上面几个方法中我们也通过了同步锁来对其进行线程安全的保证。
6结尾
其实总体来说这个爬虫不是特别的难,主要的难点在于数据量可能有点多,很多人可能不会考虑到线程安全的问题,导致数据获取的不精确。
全部代码:
from bs4 import BeautifulSoup
import requests
from urllib import request,error
import threading
inFile = open('proxy.txt')
verifiedtxt = open('verified.txt')
lock = threading.Lock()
def getProxy(url):
# 打开我们创建的txt文件
proxyFile = open('proxy.txt', 'a')
# 设置UA标识
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit '
'/ 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36'
}
# page是我们需要获取多少页的ip,这里我们获取到第9页
for page in range(1, 10):
# 通过观察URL,我们发现原网址+页码就是我们需要的网址了,这里的page需要转换成str类型
urls = url+str(page)
# 通过requests来获取网页源码
rsp = requests.get(urls, headers=headers)
html = rsp.text
# 通过BeautifulSoup,来解析html页面
soup = BeautifulSoup(html)
# 通过分析我们发现数据在 id为ip_list的table标签中的tr标签中
trs = soup.find('table', id='ip_list').find_all('tr') # 这里获得的是一个list列表
# 我们循环这个列表
for item in trs[1:]:
# 并至少出每个tr中的所有td标签
tds = item.find_all('td')
# 我们会发现有些img标签里面是空的,所以这里我们需要加一个判断
if tds[0].find('img') is None:
nation = '未知'
locate = '未知'
else:
nation = tds[0].find('img')['alt'].strip()
locate = tds[3].text.strip()
# 通过td列表里面的数据,我们分别把它们提取出来
ip = tds[1].text.strip()
port = tds[2].text.strip()
anony = tds[4].text.strip()
protocol = tds[5].text.strip()
speed = tds[6].find('div')['title'].strip()
time = tds[8].text.strip()
# 将获取到的数据按照规定格式写入txt文本中,这样方便我们获取
proxyFile.write('%s|%s|%s|%s|%s|%s|%s|%s\n' % (nation, ip, port, locate, anony, protocol, speed, time))
def verifyProxyList():
verifiedFile = open('verified.txt', 'a')
while True:
lock.acquire()
ll = inFile.readline().strip()
lock.release()
if len(ll) == 0 : break
line = ll.strip().split('|')
ip = line[1]
port = line[2]
realip = ip+':'+port
code = verifyProxy(realip)
if code == 200:
lock.acquire()
print("---Success:" + ip + ":" + port)
verifiedFile.write(ll + "\n")
lock.release()
else:
print("---Failure:" + ip + ":" + port)
def verifyProxy(ip):
'''
验证代理的有效性
'''
requestHeader = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
}
url = "http://www.baidu.com"
# 填写代理地址
proxy = {'http': ip}
# 创建proxyHandler
proxy_handler = request.ProxyHandler(proxy)
# 创建opener
proxy_opener = request.build_opener(proxy_handler)
# 安装opener
request.install_opener(proxy_opener)
try:
req = request.Request(url, headers=requestHeader)
rsq = request.urlopen(req, timeout=5.0)
code = rsq.getcode()
return code
except error.URLError as e:
return e
if __name__ == '__main__':
tmp = open('proxy.txt', 'w')
tmp.write("")
tmp.close()
tmp1 = open('verified.txt', 'w')
tmp1.write("")
tmp1.close()
getProxy("http://www.xicidaili.com/nn/")
getProxy("http://www.xicidaili.com/nt/")
getProxy("http://www.xicidaili.com/wn/")
getProxy("http://www.xicidaili.com/wt/")
all_thread = []
for i in range(30):
t = threading.Thread(target=verifyProxyList)
all_thread.append(t)
t.start()
for t in all_thread:
t.join()
inFile.close()
verifiedtxt.close()
你可能感兴趣的:(Python建立ip代理池(多线程))
系统学习Python——并发模型和异步编程:进程、线程和GIL
分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种
Flask框架入门:快速搭建轻量级Python网页应用
「已注销」
python-AI python基础 网站网络 python flask 后端
转载:Flask框架入门:快速搭建轻量级Python网页应用1.Flask基础Flask是一个使用Python编写的轻量级Web应用框架。它的设计目标是让Web开发变得快速简单,同时保持应用的灵活性。Flask依赖于两个外部库:Werkzeug和Jinja2,Werkzeug作为WSGI工具包处理Web服务的底层细节,Jinja2作为模板引擎渲染模板。安装Flask非常简单,可以使用pip安装命令
JSON 与 AJAX
Auscy
json ajax 前端
一、JSON(JavaScriptObjectNotation)1.数据类型与语法细节支持的数据类型:基本类型:字符串(需用双引号)、数字、布尔值(true/false)、null。复杂类型:数组([])、对象({})。严格语法规范:键名必须用双引号包裹(如"name":"张三")。数组元素用逗号分隔,最后一个元素后不能有多余逗号。数字不能以0开头(如012会被解析为12),不支持八进制/十六进制
Python Flask 框架入门:快速搭建 Web 应用的秘诀
Python编程之道
Python人工智能与大数据 Python编程之道 python flask 前端 ai
PythonFlask框架入门:快速搭建Web应用的秘诀关键词Flask、微框架、路由系统、Jinja2模板、请求处理、WSGI、Web开发摘要想快速用Python搭建一个灵活的Web应用?Flask作为“微框架”代表,凭借轻量、可扩展的特性,成为初学者和小型项目的首选。本文将从Flask的核心概念出发,结合生活化比喻、代码示例和实战案例,带你一步步掌握:如何用Flask搭建第一个Web应用?路由
JavaScript 树形菜单总结
Auscy
microsoft
树形菜单是前端开发中常见的交互组件,用于展示具有层级关系的数据(如文件目录、分类列表、组织架构等)。以下从核心概念、实现方式、常见功能及优化方向等方面进行总结。一、核心概念层级结构:数据以父子嵌套形式存在,如{id:1,children:[{id:2}]}。节点:树形结构的基本单元,包含自身信息及子节点(若有)。展开/折叠:子节点的显示与隐藏切换,是树形菜单的核心交互。递归渲染:因数据层级不固定,
python_虚拟环境
阿_焦
python
第一、配置虚拟环境:virtualenv(1)pipvirtualenv>安装虚拟环境包(2)pipinstallvirtualenvwrapper-win>安装虚拟环境依赖包(3)c盘创建虚拟目录>C:\virtualenv>配置环境变量【了解一下】:(1)如何使用virtualenv创建虚拟环境a、cd到C:\virtualenv目录下:b、mkvirtualenvname>创建虚拟环境nam
精通Canvas:15款时钟特效代码实现指南
烟幕缭绕
本文还有配套的精品资源,点击获取简介:HTML5的Canvas是一个用于绘制矢量图形的API,通过JavaScript实现动态效果。本项目集合了15种不同的时钟特效代码,帮助开发者通过学习绘制圆形、线条、时间更新、旋转、颜色样式设置及动画效果等概念,深化对Canvas的理解和应用。项目中的CSS文件负责时钟的样式设定,而JS文件则包含实现各种特效的逻辑,通过不同的函数或类处理时间更新和动画绘制,提
docker-compose方式搭建lnmp环境——筑梦之路
筑梦之路
linux系统运维 国产化 docker android adb
docker-compose.yml文件#生成docker-compose.ymlcat>docker-compose.ymlnginx/conf.d/default.conf">www/index.phpecho"开始启动服务..."docker-composeup-d#获取本机ipip_addr=$(hostname-I|awk'{print$1}')echo"部署完成!"echo"访问测试页
Python爱心光波
系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt
Python流星雨
Want595
python 开发语言
文章目录系列文章写在前面技术需求完整代码代码分析1.模块导入2.画布设置3.画笔设置4.颜色列表5.流星类(Star)6.流星对象创建7.主循环8.流星运动逻辑9.视觉效果10.总结写在后面系列文章序号直达链接表白系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python
理解TCP连接中的进程阻塞与CPU调度机制
109702008
编程 # C语言 网络 tcp/ip 网络 人工智能
引言在计算机网络通信中,TCP连接的建立是一个经典的三次握手过程。当用户调用connect()函数发起连接时,内核会发送SYN报文并等待对方的SYN-ACK响应。此时,调用进程通常会进入阻塞状态,暂停执行直至连接成功或超时。这一机制看似简单,但其背后的内核实现却涉及进程调度、等待队列管理和CPU资源分配等复杂操作。本文将深入探讨阻塞状态的实现原理,并解析CPU在进程阻塞期间的行为。一、进程阻塞的实
Python之七彩花朵代码实现
PlutoZuo
Python python 开发语言
Python之七彩花朵代码实现文章目录Python之七彩花朵代码实现下面是一个简单的使用Python的七彩花朵。这个示例只是一个简单的版本,没有很多高级功能,但它可以作为一个起点,你可以在此基础上添加更多功能。importturtleastuimportrandomasraimportmathtu.setup(1.0,1.0)t=tu.Pen()t.ht()colors=['red','skybl
Python 脚本最佳实践2025版
前文可以直接把这篇文章喂给AI,可以放到AI角色设定里,也可以直接作为提示词.这样,你只管提需求,写脚本就让AI来.概述追求简洁和清晰:脚本应简单明了。使用函数(functions)、常量(constants)和适当的导入(import)实践来有逻辑地组织你的Python脚本。使用枚举(enumerations)和数据类(dataclasses)等数据结构高效管理脚本状态。通过命令行参数增强交互性
(Python基础篇)了解和使用分支结构
EternityArt
基础篇 python
目录一、引言二、Python分支结构的类型与语法(一)if语句(单分支)(二)if-else语句(双分支)(三)if-elif-else语句(多分支)三、分支结构的应用场景(一)提示用户输入用户名,然后再提示输入密码,如果用户名是“admin”并且密码是“88888”则提示正确,否则,如果用户名不是admin还提示用户用户名不存在,(二)提示用户输入用户名,然后再提示输入密码,如果用户名是“adm
(Python基础篇)循环结构
EternityArt
基础篇 python
一、什么是Python循环结构?循环结构是编程中重复执行代码块的机制。在Python中,循环允许你:1.迭代处理数据:遍历列表、字典、文件内容等。2.自动化重复任务:如批量处理数据、生成序列等。3.控制执行流程:根据条件决定是否继续或终止循环。二、为什么需要循环结构?假设你需要打印1到100的所有偶数:没有循环:需手动编写100行print()语句。print(0)print(2)print(4)
(Python基础篇)字典的操作
EternityArt
基础篇 python 开发语言
一、引言在Python编程中,字典(Dictionary)是一种极具灵活性的数据结构,它通过“键-值对”(key-valuepair)的形式存储数据,如同现实生活中的字典——通过“词语(键)”快速查找“释义(值)”。相较于列表和元组的有序索引访问,字典的优势在于基于键的快速查找,这使得它在处理需要频繁通过唯一标识获取数据的场景中极为高效。掌握字典的操作,能让我们更高效地组织和管理复杂数据,是Pyt
Python七彩花朵
Want595
python 开发语言
系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt
深入解析 TCP 连接状态与进程挂起、恢复与关闭
誰能久伴不乏
tcp/ip 网络 服务器
文章目录深入解析TCP连接状态与进程挂起、恢复与关闭一、TCP连接的各种状态1.**`LISTEN`**(监听)2.**`SYN_SENT`**(SYN已发送)3.**`SYN_RECEIVED`**(SYN已接收)4.**`ESTABLISHED`**(已建立)5.**`FIN_WAIT_1`**(关闭等待1)6.**`FIN_WAIT_2`**(关闭等待2)7.**`CLOSE_WAIT`**
Cesium加载各类数据总结
zhu_zhu_xia
cesium JavaScript javascript
接触到的加载数据类型:源地图、shp、Geojson、png、wms、地形底图一.Cesium加载各类底图#此类加载的本质在于newCesium.ImageryProvider()Apidefination:“Providesimagerytobedisplayedonthesurfaceofanellipsoid.Thistypedescribesaninterfaceandisnotinten
【前端】jQuery数组合并去重方法总结
在jQuery中合并多个数组并去重,推荐使用原生JavaScript的Set对象(高效简单)或$.unique()(仅适用于DOM元素,不适用于普通数组)。以下是完整解决方案:方法1:使用ES6Set(推荐)//定义多个数组constarr1=[1,2,3];constarr2=[2,3,4];constarr3=[3,4,5];//合并数组并用Set去重constmergedArray=[...
如何解决 NPM proxy, 当我们在终端nodejs应用程序时出现代理相关报错
Thisisaproblemrelatedtonetworkconnectivity.npmERR!networkInmostcasesyouarebehindaproxyorhavebadnetworksettings.在使用npminstall下载包的时候总是报以下错误:在控制台或VisualStudioCode终端中运行以下命令:npmconfigrmproxynpmconfigrmhttp
用OpenCV标定相机内参应用示例(C++和Python)
下面是一个完整的使用OpenCV进行相机内参标定(CameraCalibration)的示例,包括C++和Python两个版本,基于棋盘格图案标定。一、目标:相机标定通过拍摄多张带有棋盘格图案的图像,估计相机的内参:相机矩阵(内参)K畸变系数distCoeffs可选外参(R,T)标定精度指标(如重投影误差)二、棋盘格参数设置(根据自己的棋盘格设置):棋盘格角点数:9x6(内角点,9列×6行);每个
Anaconda 详细下载与安装教程
Anaconda详细下载与安装教程1.简介Anaconda是一个用于科学计算的开源发行版,包含了Python和R的众多常用库。它还包括了conda包管理器,可以方便地安装、更新和管理各种软件包。2.下载Anaconda2.1访问官方网站首先,打开浏览器,访问Anaconda官方网站。2.2选择适合的版本在页面中,你会看到两个主要的下载选项:AnacondaIndividualEdition:适用于
python中 @注解 及内置注解 的使用方法总结以及完整示例
慧一居士
Python python
在Python中,装饰器(Decorator)使用@符号实现,是一种修改函数/类行为的语法糖。它本质上是一个高阶函数,接受目标函数作为参数并返回包装后的函数。Python也提供了多个内置装饰器,如@property、@staticmethod、@classmethod等。一、核心概念装饰器本质:@decorator等价于func=decorator(func)执行时机:在函数/类定义时立即执行装饰
Python中的静态方法和类方法详解
在Python中,`@staticmethod`和`@classmethod`是两种装饰器,它们用于定义类中的方法,但是它们的行为和用途有所不同。###@staticmethod`@staticmethod`装饰器用于定义一个静态方法。静态方法不接收类或实例的引用作为第一个参数,因此它不能访问类的状态或实例的状态。静态方法可以看作是与类关联的普通函数,但它们可以通过类名直接调用。classMath
计算机网络技术
CZZDg
计算机网络
目录一.网络概述1.网络的概念2.网络发展是3.网络的四要素4.网络功能5.网络类型6.网络协议与标准7.网络中常见的概念8.网络拓补结构二.网络模型1.分层思想2.OSI七层模型3.TCP/IP五层模型4.数据的封装与解封装过程三.IP地址1.进制转换2.IP地址定义3.IP地址组成成分4.IP地址分类5.地址划分6、相关概念一.网络概述1.网络的概念两个主机通过传输介质和通信协议实现通信和资源
Python中类静态方法:@classmethod/@staticmethod详解和实战示例
在Python中,类方法(@classmethod)和静态方法(@staticmethod)是类作用域下的两种特殊方法。它们使用装饰器定义,并且与实例方法(deffunc(self))的行为有所不同。1.三种方法的对比概览方法类型是否访问实例(self)是否访问类(cls)典型用途实例方法✅是❌否访问对象属性类方法@classmethod❌否✅是创建类的替代构造器,访问类变量等静态方法@stati
日历插件-FullCalendar的详细使用
老马聊技术
JavaScript 前端 javascript
一、介绍FullCalendar是一个功能强大、高度可定制的JavaScript日历组件,用于在网页中显示和管理日历事件。它支持多种视图(月、周、日等),可以轻松集成各种框架,并提供丰富的事件处理功能。二、实操案例具体代码如下:FullCalendar日期选择body{font-family:Arial,sans-serif;margin:20px;}#calendar{max-width:900
Python多版本管理与pip升级全攻略:解决冲突与高效实践
码界奇点
Python python pip 开发语言 python3.11 源代码管理 虚拟现实 依赖倒置原则
引言Python作为最流行的编程语言之一,其版本迭代速度与生态碎片化给开发者带来了巨大挑战。据统计,超过60%的Python开发者需要同时维护基于Python3.6+和Python2.7的项目。本文将系统解决以下核心痛点:如何安全地在同一台机器上管理多个Python版本pip依赖冲突的根治方案符合PEP标准的生产环境最佳实践第一部分:Python多版本管理核心方案1.1系统级多版本共存方案Wind
基于Python的健身数据分析工具的搭建流程day1
weixin_45677320
python 开发语言 数据挖掘 爬虫
基于Python的健身数据分析工具的搭建流程分数据挖掘、数据存储和数据分析三个步骤。本文主要介绍利用Python实现健身数据分析工具的数据挖掘部分。第一步:加载库加载本文需要的库,如下代码所示。若库未安装,请按照python如何安装各种库(保姆级教程)_python安装库-CSDN博客https://blog.csdn.net/aobulaien001/article/details/133298
Java实现的简单双向Map,支持重复Value
superlxw1234
java 双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
PL/SQL触发器基础及例子
百合不是茶
oracle数据库 触发器 PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
[时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
easy ui datagrid上移下移一行
商人shang
js 上移下移 easyui datagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
springMVC 使用JSR-303 Validation验证
杨白白
spring mvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
使用ajax和history.pushState无刷新改变页面URL
agevs
jquery 框架 Ajax html5 chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
centos中文乱码
AILIKES
centos OS ssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
JS正则表达式的i m g
bijian1013
JavaScript 正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
HTML5模式和Hashbang模式
bijian1013
JavaScript AngularJS Hashbang模式 HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
[Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
巧用视错觉-UI更有趣
brotherlamp
UI ui视频 ui教程 ui自学 ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构 算法 线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
HTTP协议详解
chicony
http协议
引言
Scala设计模式
chenchao051
设计模式 scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
安装mysql
daizj
mysql 安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
C语言中,关键字static的作用
e200702084
C++ c C#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转 递归反转 二分交换反转 java字符串反转 栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
代码实现任意容量倒水问题
home198979
PHP 算法 倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
两种启动监听器ApplicationListener和ServletContextListener
spjich
java spring 框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
JavaScript Rounding Methods of the Math object
何不笑
JavaScript Math
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen