作者 | Omar M'Haimdat
来源 | Medium
编辑 | 代码医生团队
创建单视图应用程序
首先,需要使用单个视图应用创建一个iOS项目:
创建一个视图应用程序
现在已经拥有了自己的项目,并且因为不喜欢使用故事板,所以应用程序以编程方式完成,这意味着没有按钮或开关切换,只需要纯粹的代码。
必须删除main.storyboard并设置您的AppDelegate.swift文件,如下所示:
funcapplication(_application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey:Any]?)->Bool{// Override point for customization after application launch.window =UIWindow(frame:UIScreen.main.bounds) window?.makeKeyAndVisible()letcontroller =ViewController() window?.rootViewController = controller returntrue }
确保从部署信息中删除故事板“Main”。
创建场景并将其添加到子视图
只有一个ViewController,它将是应用程序的主要入口点。
在这个阶段,需要导入ARKit并实例化一个ARSCNView自动渲染来自设备相机的实时视频作为场景背景。它还会自动移动其SceneKit摄像头以匹配设备的真实世界移动,这意味着不需要锚点来跟踪我们添加到场景中的对象的位置。
需要给它屏幕边界,以便摄像机会话占据整个屏幕:
letsceneView = ARSCNView(frame: UIScreen.main.bounds)
在该ViewDidLoad方法中,将设置一些内容,例如委托,还需要查看帧统计信息以监视帧丢弃:
self.view.addSubview(sceneView)// add the scene to the subviewsceneView.delegate =self// Setting the delegate for our view controllersceneView.showsStatistics =true// Show statistics
开始一个ARFaceTrackingConfiguration会话
现在需要开始一个会话ARFaceTrackingConfiguration,这个配置让可以访问仅适用于iPhone X,Xs和Xr的前置TrueDepth摄像头。以下是Apple文档中的更详细说明:
面部跟踪配置会根据设备的前置摄像头检测用户的脸部。运行此配置时,AR会话将检测用户的面部(如果在前置摄像头图像中可见),并在其锚点列表中添加表示面部的ARFaceAnchor对象。每个面部锚点提供有关面部位置和方向,其拓扑以及描述面部表情的特征的信息。
ViewDidLoad方法应如下所示:
overridefuncviewDidLoad(){super.viewDidLoad()self.view.addSubview(sceneView)sceneView.delegate =selfsceneView.showsStatistics =trueguardARFaceTrackingConfiguration.isSupportedelse{return}letconfiguration =ARFaceTrackingConfiguration()configuration.isLightEstimationEnabled =true sceneView.session.run(configuration, options: [.resetTracking, .removeExistingAnchors]) }
训练人脸识别模型
有多种方法可以创建与CoreML兼容的.mlmodel文件,这些是常见的:
Turicreate:它是python库,简化了自定义机器学习模型的开发,更重要的是,可以将模型导出到可由Xcode解析的.mlmodel文件中。
MLImageClassifierBuilder():它是一个内置的解决方案,提供Xcode开箱即用,可以访问几乎一个拖放界面来训练一个相对简单的模型。
https://pypi.org/project/turicreate/?source=post_page---------------------------
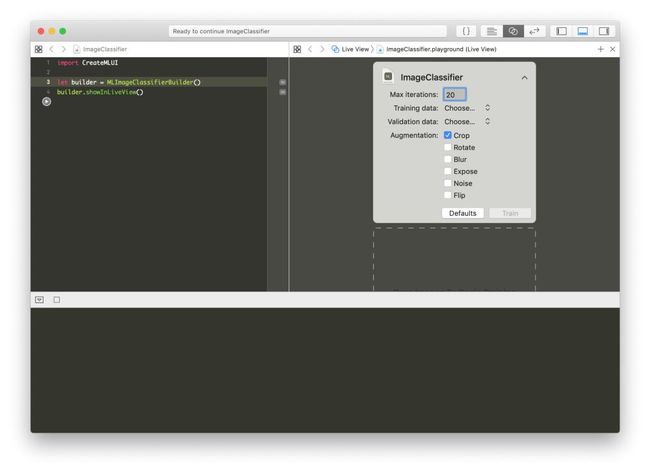
MLImageClassifierBuilder
已经创建了多个模型来测试这两个解决方案,因为没有大数据集,决定使用MLImageClassifierBuilder()和一组67个图像,这些图像是'Omar MHAIMDAT '和一组261 在unsplash上找到的'未知'的面孔。
https://unsplash.com/
打开游乐场并编写此代码:
importCreateMLUI letbuilder =MLImageClassifierBuilder()builder.showInLiveView()
建议将最大迭代次数设置为20并添加裁剪增强,这将为每个图像添加4个裁剪图像实例。
捕获相机帧并将其注入模型
需要使用场景委托来扩展ViewController ARSCNViewDelegate。需要两个委托方法,一个用于设置面部检测,另一个用于在检测到面部时更新场景:
人脸检测:
funcrenderer(_renderer: SCNSceneRenderer, nodeFor anchor: ARAnchor)->SCNNode? { guardletdevice = sceneView.deviceelse{returnnil } letfaceGeometry =ARSCNFaceGeometry(device: device) letnode =SCNNode(geometry: faceGeometry) node.geometry?.firstMaterial?.fillMode = .lines returnnode }
不幸的是,当睁开眼睛或嘴巴时,场景不会更新。在这种情况下,需要相应地更新场景。
更新场景:
funcrenderer(_renderer: SCNSceneRenderer, didUpdate node: SCNNode,foranchor: ARAnchor){ guardletfaceAnchor = anchoras?ARFaceAnchor,letfaceGeometry = node.geometryas?ARSCNFaceGeometryelse{return } faceGeometry.update(from: faceAnchor.geometry)}
采用整个面几何和映射,并更新节点。
获取相机框架:
这很有趣,因为ARSCNView继承自AVCaptureSession,意味着可以得到一个cvPixelFuffer可以提供模型。
这是从sceneView属性中获取它的简单方法:
guardletpixelBuffer =self.sceneView.session.currentFrame?.capturedImageelse{return}
将相机框架注入模型:
现在可以检测到面部并拥有每个相机框架,已准备好为模型提供一些内容:
guardletmodel =try?VNCoreMLModel(for:FaceRecognition3().model)else{fatalError("Unable to load model") } letcoreMlRequest =VNCoreMLRequest(model: model) {[weakself] request, erroringuardletresults = request.resultsas? [VNClassificationObservation],lettopResult = results.firstelse{fatalError("Unexpected results") } DispatchQueue.main.async {[weakself]inprint(topResult.identifier) } } guardletpixelBuffer =self.sceneView.session.currentFrame?.capturedImageelse{return} lethandler =VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:])DispatchQueue.global().async {do{tryhandler.perform([coreMlRequest])}catch{print(error) } }
在识别的脸部上方显示名称
最后也可能是最令人沮丧的部分是在识别出的脸部上方投射3D文本。如果考虑一下,配置就不如ARWorldTrackingConfiguration能够访问众多方法和类的功能那样强大。使用的是前置摄像头,可以实现的功能很少。
尽管如此,仍然可以在屏幕上投影3D文本,但它不会跟踪面部运动并相应地进行更改。
let text =SCNText(string:"", extrusionDepth:2)let font =UIFont(name:"Avenir-Heavy", size:18)text.font = fontlet material =SCNMaterial()material.diffuse.contents =UIColor.blacktext.materials = [material]text.firstMaterial?.isDoubleSided =true let textNode =SCNNode(geometry: faceGeometry)textNode.position =SCNVector3(-0.1,-0.01,-0.5)textNode.scale =SCNVector3(0.002,0.002,0.002)textNode.geometry = text
现在有了SCNText对象,需要使用相应的face更新它并将其添加到rootNode:
letcoreMlRequest =VNCoreMLRequest(model: model) {[weakself] request, erroringuardletresults = request.resultsas? [VNClassificationObservation],lettopResult = results.firstelse{fatalError("Unexpected results") } DispatchQueue.main.async {[weakself]inprint(topResult.identifier)iftopResult.identifier !="Unknown"{ text.string = topResult.identifierself!.sceneView.scene.rootNode.addChildNode(textNode)self!.sceneView.autoenablesDefaultLighting =true } } }
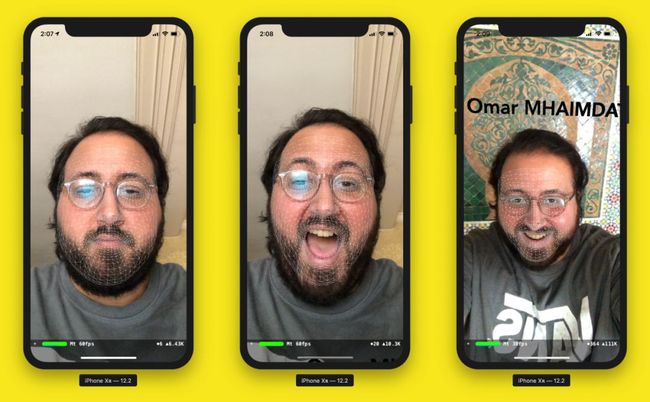
最后结果:
这是面部检测和识别的最终结果。
视频
该项目可从Github帐户下载
https://github.com/omarmhaimdat/WhoAreYou