Node架构图
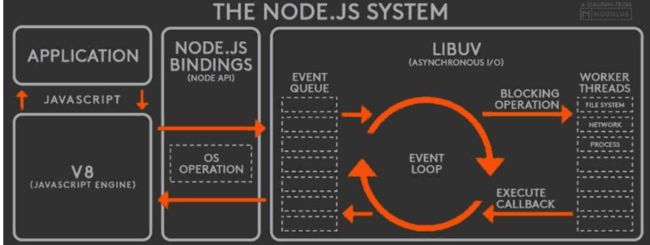
事件循环核心
核心模块就是LIBUV
在linux上,libuv是对epoll的封装;
在windows上,libuv是对iocp的封装;
在macOS/FreeBSD上,libuv是对kqueue的封装。
从上图可知,如果想了解事件循环,必须先要了解LIBUV是什么,而了解libuv需要先弄清楚epoll等;因为内部实现逻辑类似,此处只讨论epoll
操作系统的数据传输
从网卡到操作系统
为了弄清楚高并发网络场景是如何处理的,我们先来看一个最基本的内容:当数据到达网卡之后,操作系统会做哪些事情?
网络数据到达网卡之后,首先需要把数据拷贝到内存。拷贝到内存的工作往往不需要消耗 CPU 资源,而是通过 DMA 模块直接进行内存映射。之所以这样做,是因为网卡没有大量的内存空间,只能做简单的缓冲,所以必须赶紧将它们保存下来。
Linux 中用一个双向链表作为缓冲区,你可以观察下图中的 Buffer,看上去像一个有很多个凹槽的线性结构,每个凹槽(节点)可以存储一个封包,这个封包可以从网络层看(IP 封包),也可以从传输层看(TCP 封包)。操作系统不断地从 Buffer 中取出数据,数据通过一个协议栈,你可以把它理解成很多个协议的集合。协议栈中数据封包找到对应的协议程序处理完之后,就会形成 Socket 文件。
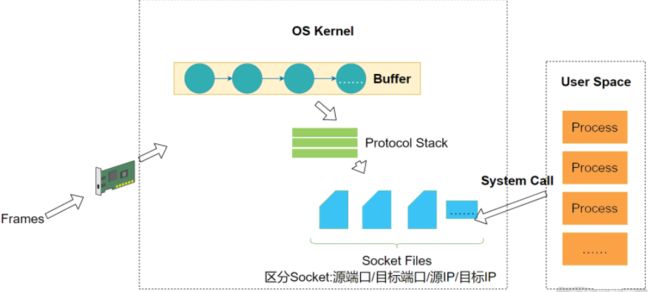
如果高并发的请求量级实在太大,有可能把 Buffer 占满,此时,操作系统就会拒绝服务。网络上有一种著名的攻击叫作拒绝服务攻击,就是利用的这个原理。操作系统拒绝服务,实际上是一种保护策略。通过拒绝服务,避免系统内部应用因为并发量太大而雪崩。
如上图所示,传入网卡的数据被我称为 Frames。一个 Frame 是数据链路层的传输单位(或封包)。现代的网卡通常使用 DMA 技术,将 Frame 写入缓冲区(Buffer),然后在触发 CPU 中断交给操作系统处理。操作系统从缓冲区中不断取出 Frame,通过协进栈(具体的协议)进行还原。
在 UNIX 系的操作系统中,一个 Socket 文件内部类似一个双向的管道。因此,非常适用于进程间通信。在网络当中,本质上并没有发生变化。网络中的 Socket 一端连接 Buffer, 一端连接应用——也就是进程。网卡的数据会进入 Buffer,Buffer 经过协议栈的处理形成 Socket 结构。通过这样的设计,进程读取 Socket 文件,可以从 Buffer 中对应节点读走数据。
对于 TCP 协议,Socket 文件可以用源端口、目标端口、源 IP、目标 IP 进行区别。不同的 Socket 文件,对应着 Buffer 中的不同节点。进程们读取数据的时候从 Buffer 中读取,写入数据的时候向 Buffer 中写入。通过这样一种结构,无论是读和写,进程都可以快速定位到自己对应的节点。
以上就是我们对操作系统和网络接口交互的一个基本讨论。后面,再看一下作为一个编程模型的 Socket。
补充
-
并行和并发
并行: 借助多核 cpu 实现(真并行)
并发:(假并行)
- 宏观:用户体验上,程序在并行执行。
- 微观:多个计划任务,顺序执行。在飞快的切换。轮换使用 cpu 时间轮片。
-
CPU中断
程序中断通常简称中断,是指CPU在正常运行程序的过程中,由于预选安排或发生了各种随机的内部或外部事件,由硬件或者软件发出的一种IRQ(中断请求)信号,一旦CPU接受的中断信号,CPU就会暂停执行的当前的工作,并且保留现场,去响应中断,使CPU中断正在运行的程序,而转到为相应的服务程序去处理,这个过程称为中断。
-
DMA 模块
- Direct Memory Access(存储器直接访问)。这是指一种高速的数据传输操作,允许在外部设备和存储器之间直接读写数据,既不通过CPU,也不需要CPU干预。整个数据传输操作在一个称为"DMA控制器"的控制下进行的。DMA允许不同速度的硬件装置来沟通,而不需要依赖于CPU的大量中断负载。否则CPU需要从来源把每一片段的资料复制到暂存器,然后把它们写到新的地方。但是有了DMA之后,CPU除了在数据传输开始和结束时做一点处理外,在传输过程中CPU可以进行其他的工作。这样,在大部分时间里,CPU和输入输出都处于并行操作。因此,使整个计算机系统的效率大大提高。
- DMA传输将数据从一个地址空间复制到另一个地址空间。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来完成的。典型的例子就是移动一个外部内存的区块到芯片内部更快的内存区。在实现DMA传输时,是由DMA控制器直接掌握总线,因此,存在着一个总线(数据总线)控制权转移的过程。即DMA传输前,CPU要把总现控制权交给DMA控制器,结束DMA传输后,DMA控制器立即把总现控制权再交回给CPU。
-
总线
- 数据总线:传输数据
- 地址总线:数据地址
- 控制总线:控制信号
Socket 编程模型
通过前面讲述,我们知道 Socket 在操作系统中,有一个非常具体的从 Buffer 到文件的实现。但是对于进程而言,Socket 更多是一种编程的模型。接下来我们讨论作为编程模型的 Socket。
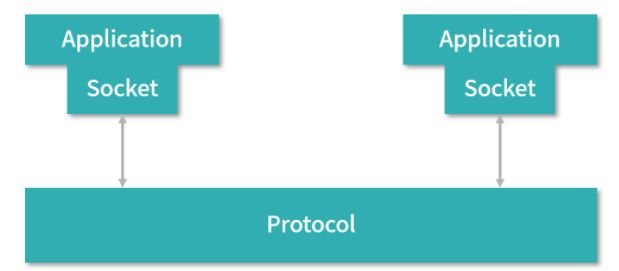
如上图所示,Socket 连接了应用和协议,如果应用层的程序想要传输数据,就创建一个 Socket。应用向 Socket 中写入数据,相当于将数据发送给了另一个应用。应用从 Socket 中读取数据,相当于接收另一个应用发送的数据。而具体的操作就是由 Socket 进行封装。具体来说,对于 UNIX 系的操作系统,是利用 Socket 文件系统,Socket 是一种特殊的文件——每个都是一个双向的管道。一端是应用,一端是缓冲区。
那么作为一个服务端的应用,如何知道有哪些 Socket 呢?也就是,哪些客户端连接过来了呢?这是就需要一种特殊类型的 Socket,也就是服务端 Socket 文件。
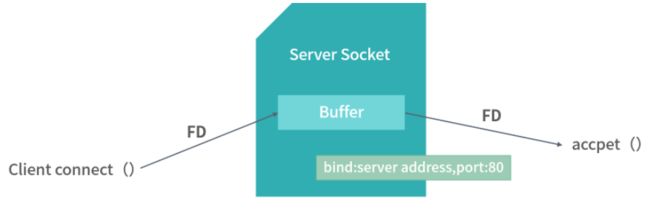
如上图所示,当有客户端连接服务端时,服务端 Socket 文件中会写入这个客户端 Socket 的文件描述符。进程可以通过 accept() 方法,从服务端 Socket 文件中读出客户端的 Socket 文件描述符,从而拿到客户端的 Socket 文件。
程序员实现一个网络服务器的时候,会先手动去创建一个服务端 Socket 文件。服务端的 Socket 文件依然会存在操作系统内核之中,并且会绑定到某个 IP 地址和端口上。以后凡是发送到这台机器、目标 IP 地址和端口号的连接请求,在形成了客户端 Socket 文件之后,文件的文件描述符都会被写入到服务端的 Socket 文件中。应用只要调用 accept 方法,就可以拿到这些客户端的 Socket 文件描述符,这样服务端的应用就可以方便地知道有哪些客户端连接了进来。
而每个客户端对这个应用而言,都是一个文件描述符。如果需要读取某个客户端的数据,就读取这个客户端对应的 Socket 文件。如果要向某个特定的客户端发送数据,就写入这个客户端的 Socket 文件。
- FD : 全称是file descriptor,是进程独有的文件描述符表的索引
I/O多路复用
下面开始进入整体,会聊到epoll模型
那么什么是I/O多路复用:这里的 I/O 通常指网络 I/O,多路指多个 Socket 链接,复用指操作系统进行运算调度的最小单位线程。整体意思也就是多个网络 I/O 复用一个或少量的线程来处理 Socket。
多路复用在前端的应用,例如http1.1->http2
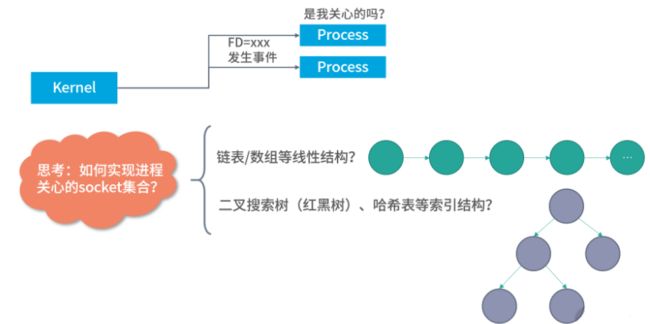
在上面的讨论当中,进程拿到了它关注的所有 Socket,也称作关注的集合(Intersting Set)。如下图所示,这种过程相当于进程从所有的 Socket 中,筛选出了自己关注的一个子集,但是这时还有一个问题没有解决:进程如何监听关注集合的状态变化,比如说在有数据进来,如何通知到这个进程?

其实更准确地说,一个线程需要处理所有关注的 Socket 产生的变化,或者说消息。实际上一个线程要处理很多个文件的 I/O。所有关注的 Socket 状态发生了变化,都由一个线程去处理,构成了 I/O 的多路复用问题。如下图所示:

处理 I/O 多路复用的问题,需要操作系统提供内核级别的支持。Linux 下有三种提供 I/O 多路复用的 API,分别是:
select
poll
epoll
如下图所示,内核了解网络的状态。因此不难知道具体发生了什么消息,比如内核知道某个 Socket 文件状态发生了变化。但是内核如何知道该把哪个消息给哪个进程呢?
(前端接触的的哈希表:数据结构的Map存储结构,很简化的说就是md5计算的散列值作为key)
一个 Socket 文件,可以由多个进程使用;而一个进程,也可以使用多个 Socket 文件。进程和 Socket 之间是多对多的关系。另一方面,一个 Socket 也会有不同的事件类型。因此操作系统很难判断,将哪样的事件给哪个进程。
这样在进程内部就需要一个数据结构来描述自己会关注哪些 Socket 文件的哪些事件(读、写、异常等)。通常有两种考虑方向,一种是利用线性结构,比如说数组、链表等,这类结构的查询需要遍历。每次内核产生一种消息,就遍历这个线性结构。看看这个消息是不是进程关注的?另一种是索引结构,内核发生了消息可以通过索引结构马上知道这个消息进程关不关注。
补充(红黑树)
红黑树是一种自平衡的二叉搜索树,以前叫做平衡二叉B树;红黑树之所以效率高就是因为平衡,平衡则层级少,则性能高
红黑树增加的一些特性 :
- 结点是红色或者黑色(结点上有一个color属性)
- 根节点是黑色
- 叶子结点都是黑色,且为null
- 链接红色结点的两个子结点都是黑色,红色结点的父结点都是黑色,红色结点的子结点都是黑色
- 从任意的结点出发,到其每个叶子结点的路径中包含相同数据的黑色结点

select()
select 和 poll 都采用线性结构,select 允许用户传入 3 个集合。如下面这段程序所示:
fd_set read_fd_set, write_fd_set, error_fd_set;
while(true) {
select(..., &read_fd_set, &write_fd_set, &error_fd_set);
}
每次 select 操作会阻塞当前线程,在阻塞期间所有操作系统产生的每个消息,都会通过遍历的手段查看是否在 3 个集合当中。上面程序read_fd_set中放入的是当数据可以读取时进程关心的 Socket;write_fd_set是当数据可以写入时进程关心的 Socket;error_fd_set是当发生异常时进程关心的 Socket。
用户程序可以根据不同集合中是否有某个 Socket 判断发生的消息类型,程序如下所示:
fd_set read_fd_set, write_fd_set, error_fd_set;
while(true) {
select(..., &read_fd_set, &write_fd_set, &error_fd_set);
for (i = 0; i < FD_SETSIZE; ++i)
if (FD_ISSET (i, &read_fd_set)){
// Socket可以读取
} else if(FD_ISSET(i, &write_fd_set)) {
// Socket可以写入
} else if(FD_ISSET(i, &error_fd_set)) {
// Socket发生错误
}
}
上面程序中的 FD_SETSIZE 是一个系统的默认设置,通常是 1024。可以看出,select 模式能够一次处理的文件描述符是有上限的,也就是 FD_SETSIZE。当并发请求过多的时候, select 就无能为力了。但是对单台机器而言,1024 个并发已经是一个非常大的流量了。
接下来我给出一个完整的、用 select 实现的服务端程序供你参考,如下所示:
#include
#include
#include
#include
#include
#include
#include
#include
#define PORT 5555
#define MAXMSG 512
int
read_from_client (int filedes)
{
char buffer[MAXMSG];
int nbytes;
nbytes = read (filedes, buffer, MAXMSG);
if (nbytes < 0)
{
/* Read error. */
perror ("read");
exit (EXIT_FAILURE);
}
else if (nbytes == 0)
/* End-of-file. */
return -1;
else
{
/* Data read. */
fprintf (stderr, "Server: got message: `%s'\n", buffer);
return 0;
}
}
int
main (void)
{
extern int make_Socket (uint16_t port);
int sock;
fd_set active_fd_set, read_fd_set;
int i;
struct sockaddr_in clientname;
size_t size;
/* Create the Socket and set it up to accept connections. */
sock = make_Socket (PORT);
if (listen (sock, 1) < 0)
{
perror ("listen");
exit (EXIT_FAILURE);
}
/* Initialize the set of active Sockets. */
FD_ZERO (&active_fd_set);
FD_SET (sock, &active_fd_set);
while (1)
{
/* Block until input arrives on one or more active Sockets. */
read_fd_set = active_fd_set;
if (select (FD_SETSIZE, &read_fd_set, NULL, NULL, NULL) < 0)
{
perror ("select");
exit (EXIT_FAILURE);
}
/* Service all the Sockets with input pending. */
for (i = 0; i < FD_SETSIZE; ++i)
if (FD_ISSET (i, &read_fd_set))
{
if (i == sock)
{
/* Connection request on original Socket. */
int new;
size = sizeof (clientname);
new = accept (sock,
(struct sockaddr *) &clientname,
&size);
if (new < 0)
{
perror ("accept");
exit (EXIT_FAILURE);
}
fprintf (stderr,
"Server: connect from host %s, port %hd.\n",
inet_ntoa (clientname.sin_addr),
ntohs (clientname.sin_port));
FD_SET (new, &active_fd_set);
}
else
{
/* Data arriving on an already-connected Socket. */
if (read_from_client (i) < 0)
{
close (i);
FD_CLR (i, &active_fd_set);
}
}
}
}
}
poll()
从写程序的角度来看,select 并不是一个很好的编程模型。一个好的编程模型应该直达本质,当网络请求发生状态变化的时候,核心是会发生事件。一个好的编程模型应该是直接抽象成消息:用户不需要用 select 来设置自己的集合,而是可以通过系统的 API 直接拿到对应的消息,从而处理对应的文件描述符。
另外:poll 和 select 在实现上没有本质的区别,相比较 select,poll 基于链表来实现,没有了最大链接 1024 的限制。但是当文件描述符多了之后,每次调用都会对链接进行线性遍历,性能还是十分低下的。这是一个没有银弹的答案
比如下面这段伪代码就是一个更好的编程模型,具体的分析如下:
- poll 是一个阻塞调用,它将某段时间内操作系统内发生的且进程关注的消息告知用户程序;
- 用户程序通过直接调用 poll 函数拿到消息;
- poll 函数的第一个参数告知内核 poll 关注哪些 Socket 及消息类型;
- poll 调用后,经过一段时间的等待(阻塞),就拿到了是一个消息的数组;
- 通过遍历这个数组中的消息,能够知道关联的文件描述符和消息的类型;
- 通过消息类型判断接下来该进行读取还是写入操作;
- 通过文件描述符,可以进行实际地读、写、错误处理。
while(true) {
events = poll(fds, ...)
for(evt in events) {
fd = evt.fd;
type = evt.revents;
if(type & POLLIN ) {
// 有数据需要读,读取fd中的数据
} else if(type & POLLOUT) {
// 可以写入数据
}
else ...
}
}
poll 虽然优化了编程模型,但是从性能角度分析,它和 select 差距不大。因为内核在产生一个消息之后,依然需要遍历 poll 关注的所有文件描述符来确定这条消息是否跟用户程序相关。
epoll
为了解决上述问题,epoll 通过更好的方案实现了从操作系统订阅消息。epoll 将进程关注的文件描述符存入一棵二叉搜索树,通常是红黑树的实现。在这棵红黑树当中,Key 是 Socket 的编号,值是这个 Socket 关注的消息。因此,当内核发生了一个事件:比如 Socket 编号 1000 可以读取。这个时候,可以马上从红黑树中找到进程是否关注这个事件。
另外当有关注的事件发生时,epoll 会先放到一个队列当中。当用户调用epoll_wait时候,就会从队列中返回一个消息。epoll 函数本身是一个构造函数,只用来创建红黑树和队列结构。epoll_wait调用后,如果队列中没有消息,也可以马上返回。因此epoll是一个非阻塞模型。
总结一下,select/poll 是阻塞模型,epoll 是非阻塞模型。当然,并不是说非阻塞模型性能就更好。在多数情况下,epoll 性能更好是因为内部有红黑树的实现。
最后我再贴一段用 epoll 实现的 Socket 服务给你做参考,这段程序的作者将这段代码放到了 Public Domain,你以后看到公有领域的代码可以放心地使用。
下面这段程序跟之前 select 的原理一致,对于每一个新的客户端连接,都使用 accept 拿到这个连接的文件描述符,并且创建一个客户端的 Socket。然后通过epoll_ctl将客户端的文件描述符和关注的消息类型放入 epoll 的红黑树。操作系统每次监测到一个新的消息产生,就会通过红黑树对比这个消息是不是进程关注的(当然这段代码你看不到,因为它在内核程序中)。
非阻塞模型的核心价值,并不是性能更好。当真的高并发来临的时候,所有的 CPU 资源,所有的网络资源可能都会被用完。这个时候无论是阻塞还是非阻塞,结果都不会相差太大。
epoll有 2 个最大的优势:
- 内部使用红黑树减少了内核的比较操作;
- 对于程序员而言,非阻塞的模型更容易处理各种各样的情况。程序员习惯了写出每一条语句就可以马上得到结果,这样不容易出 Bug。
// Asynchronous Socket server - accepting multiple clients concurrently,
// multiplexing the connections with epoll.
//
// Eli Bendersky [http://eli.thegreenplace.net]
// This code is in the public domain.
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "utils.h"
#define MAXFDS 16 * 1024
typedef enum { INITIAL_ACK, WAIT_FOR_MSG, IN_MSG } ProcessingState;
#define SENDBUF_SIZE 1024
typedef struct {
ProcessingState state;
uint8_t sendbuf[SENDBUF_SIZE];
int sendbuf_end;
int sendptr;
} peer_state_t;
// Each peer is globally identified by the file descriptor (fd) it's connected
// on. As long as the peer is connected, the fd is unique to it. When a peer
// disconnects, a new peer may connect and get the same fd. on_peer_connected
// should initialize the state properly to remove any trace of the old peer on
// the same fd.
peer_state_t global_state[MAXFDS];
// Callbacks (on_XXX functions) return this status to the main loop; the status
// instructs the loop about the next steps for the fd for which the callback was
// invoked.
// want_read=true means we want to keep monitoring this fd for reading.
// want_write=true means we want to keep monitoring this fd for writing.
// When both are false it means the fd is no longer needed and can be closed.
typedef struct {
bool want_read;
bool want_write;
} fd_status_t;
// These constants make creating fd_status_t values less verbose.
const fd_status_t fd_status_R = {.want_read = true, .want_write = false};
const fd_status_t fd_status_W = {.want_read = false, .want_write = true};
const fd_status_t fd_status_RW = {.want_read = true, .want_write = true};
const fd_status_t fd_status_NORW = {.want_read = false, .want_write = false};
fd_status_t on_peer_connected(int sockfd, const struct sockaddr_in* peer_addr,
socklen_t peer_addr_len) {
assert(sockfd < MAXFDS);
report_peer_connected(peer_addr, peer_addr_len);
// Initialize state to send back a '*' to the peer immediately.
peer_state_t* peerstate = &global_state[sockfd];
peerstate->state = INITIAL_ACK;
peerstate->sendbuf[0] = '*';
peerstate->sendptr = 0;
peerstate->sendbuf_end = 1;
// Signal that this Socket is ready for writing now.
return fd_status_W;
}
fd_status_t on_peer_ready_recv(int sockfd) {
assert(sockfd < MAXFDS);
peer_state_t* peerstate = &global_state[sockfd];
if (peerstate->state == INITIAL_ACK ||
peerstate->sendptr < peerstate->sendbuf_end) {
// Until the initial ACK has been sent to the peer, there's nothing we
// want to receive. Also, wait until all data staged for sending is sent to
// receive more data.
return fd_status_W;
}
uint8_t buf[1024];
int nbytes = recv(sockfd, buf, sizeof buf, 0);
if (nbytes == 0) {
// The peer disconnected.
return fd_status_NORW;
} else if (nbytes < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// The Socket is not *really* ready for recv; wait until it is.
return fd_status_R;
} else {
perror_die("recv");
}
}
bool ready_to_send = false;
for (int i = 0; i < nbytes; ++i) {
switch (peerstate->state) {
case INITIAL_ACK:
assert(0 && "can't reach here");
break;
case WAIT_FOR_MSG:
if (buf[i] == '^') {
peerstate->state = IN_MSG;
}
break;
case IN_MSG:
if (buf[i] == '$') {
peerstate->state = WAIT_FOR_MSG;
} else {
assert(peerstate->sendbuf_end < SENDBUF_SIZE);
peerstate->sendbuf[peerstate->sendbuf_end++] = buf[i] + 1;
ready_to_send = true;
}
break;
}
}
// Report reading readiness iff there's nothing to send to the peer as a
// result of the latest recv.
return (fd_status_t){.want_read = !ready_to_send,
.want_write = ready_to_send};
}
fd_status_t on_peer_ready_send(int sockfd) {
assert(sockfd < MAXFDS);
peer_state_t* peerstate = &global_state[sockfd];
if (peerstate->sendptr >= peerstate->sendbuf_end) {
// Nothing to send.
return fd_status_RW;
}
int sendlen = peerstate->sendbuf_end - peerstate->sendptr;
int nsent = send(sockfd, &peerstate->sendbuf[peerstate->sendptr], sendlen, 0);
if (nsent == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
return fd_status_W;
} else {
perror_die("send");
}
}
if (nsent < sendlen) {
peerstate->sendptr += nsent;
return fd_status_W;
} else {
// Everything was sent successfully; reset the send queue.
peerstate->sendptr = 0;
peerstate->sendbuf_end = 0;
// Special-case state transition in if we were in INITIAL_ACK until now.
if (peerstate->state == INITIAL_ACK) {
peerstate->state = WAIT_FOR_MSG;
}
return fd_status_R;
}
}
int main(int argc, const char** argv) {
setvbuf(stdout, NULL, _IONBF, 0);
int portnum = 9090;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Serving on port %d\n", portnum);
int listener_sockfd = listen_inet_Socket(portnum);
make_Socket_non_blocking(listener_sockfd);
int epollfd = epoll_create1(0);
if (epollfd < 0) {
perror_die("epoll_create1");
}
struct epoll_event accept_event;
accept_event.data.fd = listener_sockfd;
accept_event.events = EPOLLIN;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listener_sockfd, &accept_event) < 0) {
perror_die("epoll_ctl EPOLL_CTL_ADD");
}
struct epoll_event* events = calloc(MAXFDS, sizeof(struct epoll_event));
if (events == NULL) {
die("Unable to allocate memory for epoll_events");
}
while (1) {
int nready = epoll_wait(epollfd, events, MAXFDS, -1);
for (int i = 0; i < nready; i++) {
if (events[i].events & EPOLLERR) {
perror_die("epoll_wait returned EPOLLERR");
}
if (events[i].data.fd == listener_sockfd) {
// The listening Socket is ready; this means a new peer is connecting.
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd = accept(listener_sockfd, (struct sockaddr*)&peer_addr,
&peer_addr_len);
if (newsockfd < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// This can happen due to the nonblocking Socket mode; in this
// case don't do anything, but print a notice (since these events
// are extremely rare and interesting to observe...)
printf("accept returned EAGAIN or EWOULDBLOCK\n");
} else {
perror_die("accept");
}
} else {
make_Socket_non_blocking(newsockfd);
if (newsockfd >= MAXFDS) {
die("Socket fd (%d) >= MAXFDS (%d)", newsockfd, MAXFDS);
}
fd_status_t status =
on_peer_connected(newsockfd, &peer_addr, peer_addr_len);
struct epoll_event event = {0};
event.data.fd = newsockfd;
if (status.want_read) {
event.events |= EPOLLIN;
}
if (status.want_write) {
event.events |= EPOLLOUT;
}
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, newsockfd, &event) < 0) {
perror_die("epoll_ctl EPOLL_CTL_ADD");
}
}
} else {
// A peer Socket is ready.
if (events[i].events & EPOLLIN) {
// Ready for reading.
int fd = events[i].data.fd;
fd_status_t status = on_peer_ready_recv(fd);
struct epoll_event event = {0};
event.data.fd = fd;
if (status.want_read) {
event.events |= EPOLLIN;
}
if (status.want_write) {
event.events |= EPOLLOUT;
}
if (event.events == 0) {
printf("Socket %d closing\n", fd);
if (epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, NULL) < 0) {
perror_die("epoll_ctl EPOLL_CTL_DEL");
}
close(fd);
} else if (epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event) < 0) {
perror_die("epoll_ctl EPOLL_CTL_MOD");
}
} else if (events[i].events & EPOLLOUT) {
// Ready for writing.
int fd = events[i].data.fd;
fd_status_t status = on_peer_ready_send(fd);
struct epoll_event event = {0};
event.data.fd = fd;
if (status.want_read) {
event.events |= EPOLLIN;
}
if (status.want_write) {
event.events |= EPOLLOUT;
}
if (event.events == 0) {
printf("Socket %d closing\n", fd);
if (epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, NULL) < 0) {
perror_die("epoll_ctl EPOLL_CTL_DEL");
}
close(fd);
} else if (epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event) < 0) {
perror_die("epoll_ctl EPOLL_CTL_MOD");
}
}
}
}
}
return 0;
}
I/O模型
在上面的模型当中,select/poll 是阻塞(Blocking)模型,epoll 是非阻塞(Non-Blocking)模型。阻塞和非阻塞强调的是线程的状态,所以阻塞就是触发了线程的阻塞状态,线程阻塞了就停止执行,并且切换到其他线程去执行,直到触发中断再回来。
补充:
- 阻塞与非阻塞 I/O是对于操作系统内核而言的,发生在等待资源阶段,根据发起 I/O 请求是否阻塞来判断。
-
阻塞 I/O:这种模式下一个用户进程在发起一个 I/O 操作之后,只有收到响应或者超时才可进行处理其它事情,否则 I/O 将会一直阻塞。以读取磁盘上的一段文件为例,系统内核在完成磁盘寻道、读取数据、复制数据到内存中之后,这个调用才算完成。阻塞的这段时间对 CPU 资源是浪费的。 -
非阻塞 I/O:这种模式下一个用户进程发起一个 I/O 操作之后,如果数据没有就绪,会立刻返回(标志数据资源不可用),此时 CPU 时间片可以用来做一些其它事情。
-
- 同步与异步 I/O 发生在使用资源阶段,根据实际 I/O 操作来判断。
- Node.js 就是典型的异步编程例子。
-
同步 I/O:应用发送或接收数据后,如果不返回,继续等待(此处发生阻塞),直到数据成功或失败返回。 -
异步 I/O:应用发送或接收数据后立刻返回,数据写入 OS 缓存,由 OS 完成数据发送或接收,并返回成功或失败的信息给应用。
- select/poll/epoll 三者都是同步调用。
- 非阻塞不一定是异步,阻塞也未必就是同步。比如一个带有回调函数的方法,阻塞了线程 100 毫秒,又提供了回调函数,那这个方法是异步阻塞。
asleep(100ms, () -> {
// 100ms 或更多后到这里
// ...do some thing
})
// 100 ms 后到这里
用户空间与内核空间
操作系统为了支持多个应用同时运行,需要保证不同进程间相对独立、内核的安全,那就不能谁都能来操作了,因此操作系统将内存空间划分为用户空间、内核空间两部分。用户空间存放用户程序代码和数据,而内核空间存放内核代码和数据。下图用于描述OSI七层参考模型和网际网协议族。

select/poll/epoll 有什么区别?
这三者都是处理 I/O 多路复用的编程手段。select/poll 模型是一种阻塞模型,epoll 是非阻塞模型。select/poll 内部使用线性结构存储进程关注的 Socket 集合,因此每次内核要判断某个消息是否发送给 select/poll 需要遍历进程关注的 Socket 集合。
而 epoll 不同,epoll 内部使用二叉搜索树(红黑树),用 Socket 编号作为索引,用关注的事件类型作为值,这样内核可以在非常快的速度下就判断某个消息是否需要发送给使用 epoll 的线程。
事件循环
浏览器的线程
-
js引擎线程(js引擎有多个线程,一个主线程,其它的后台配合主线程)
作用:执行js任务(执行js代码,用户输入,网络请求)- 也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎,包含事件轮询处理线程:处理轮询消息队列,event loop)
- JS引擎线程负责解析Javascript脚本,运行代码。
- JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
- 同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
-
GUI渲染线程
作用:渲染页面(js可以操作dom,影响渲染,所以js引擎线程和UI线程是互斥的。js执行时会阻塞页面的渲染。)- 负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
- 注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
-
浏览器事件触发线程
作用:控制交互,响应用户- 归属于浏览器而不是JS引擎,用来控制事件循环
- 当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
- 注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
-
http请求线程
作用:ajax请求等- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。
-
定时触发器线程
作用:setTimeout和setInteval- 浏览器定时计数器并不是由JavaScript引擎计数的,(因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
- 注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
异步是浏览器的两个或者两个以上线程共同完成的
浏览器中的事件循环
为了协调事件(event),用户交互(user interaction),脚本(script),渲染(rendering),网络(networking)等,用户代理(user agent)必须使用事件循环(event loops)。
- 事件:PostMessage, MutationObserver等
- 用户交互: click, onScroll等
- 渲染: 解析dom,css等
- 脚本:js脚本执行
nodejs中的事件循环
事件循环允许Node.js执行非阻塞I / O操作 - 尽管JavaScript是单线程的 - 通过尽可能将操作卸载到系统内核。 由于大多数现代内核都是多线程的,因此它们可以处理在后台执行的多个操作。当其中一个操作完成时,内核会告诉Node.js,以便可以将相应的回调添加到轮询队列中以最终执行。
- 事件: EventEmitter
- 非阻塞I / O:网络请求,文件读写等
- 脚本:js脚本执行
事件循环的本质
在浏览器或者nodejs环境中,运行时对js脚本的调度方式就叫做事件循环。
setTimeout(() => {
console.log('setTimeout')
}, 0);
Promise.resolve().then(() => {
console.log('promise');
});
console.log('main');
// 1. main 2. promise 3. setTimeout
浏览器事件循环讲解
Javascript为什么是单线程的?
浏览器js的作用是操作DOM,这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
任务队列
单线程就意味着所有任务需要排队,如果因为任务cpu计算量大还好,但是I/O操作cpu是闲着的。所以js就设计成了一门异步的语言,不会做无畏的等待。任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
宏任务与微任务
除了广义的同步任务和异步任务,JavaScript 单线程中的任务可以细分为宏任务(macrotask)和微任务(microtask)。
- macrotask: script(整体代码), setTimeout, setInterval, setImmediate, I/O, UI rendering。
- microtask:process.nextTick, Promise, Object.observe, MutationObserver。
- 宏任务进入主线程,执行过程中会收集微任务加入微任务队列。
- 宏任务执行完成之后,立马执行微任务中的任务。微任务执行过程中将再次收集宏任务,并加入宏任务队列。
- 反复执行1,2步骤
总结:遇到Promise或者nextTick等就把其回调扔进微任务,遇到setTimeout等就是把回调扔进I/O线程,等待一下次事件循环开启宏任务时候I/O事件进入宏任务执行。

setTimeout(() => {
console.log('setTimeout')
}, 0);
Promise.resolve().then(() => {
console.log('promise');
});
console.log('main');
// 1. main 2. promise 3. setTimeout
一些题目
setTimeout(() => {
console.log('setTimeout');
}, 0);
Promise.resolve().then(() => {
console.log('promise');
Promise.resolve().then(() => {
console.log('promise1');
});
});
console.log('main');
//main,promise,promise1,setTimeout
重点:每轮事件循环执行一个宏任务和所有的微任务。所以,promise和promise1会在第一次微任务时候都执行完
setTimeout(() => {
Promise.resolve().then(() => {
console.log('promise');
});
}, 0);
Promise.resolve().then(() => {
setTimeout(() => {
console.log('setTimeout');
}, 0);
});
console.log('main');
//main promise setTimeout
任务队列一定会保持先进先出的顺序执行。
- 首先setTimeout内部整体回调压入I/O线程
- Promise.resolve()内部回调放入当前循环的微任务队列
- 输出main
- 然后执行微任务也就是setTimeout内部回调放入I/O线程
- 进入下次循环(一次循环只从I/O线程取出一个事件执行),取出I/O线程(是队列)第一个任务放入宏任务执行,即setTimeout内部回调,执行完毕其内部回调放入当前事件循环的微任务
- 执行微任务,输出promise
- 进入下次循环,取出I/O线程事件执行,即Promise.resolve()内部回调,放入宏任务,执行完毕内部输出语句放入I/O线程等待下次循环,取出然后输出。
setTimeout(() => {
setTimeout(()=>{
console.log('setTimeout1');
},0)
}, 0)
Promise.resolve().then(() => {
setTimeout(()=>{
console.log('setTimeout');
},0)
})
console.log('main');
//main setTimeout setTimeout1
nodejs事件循环讲解
当Node.js启动时会初始化event loop, 每一个event loop都会包含按如下六个循环阶段,nodejs事件循环和浏览器的事件循环完全不一样。
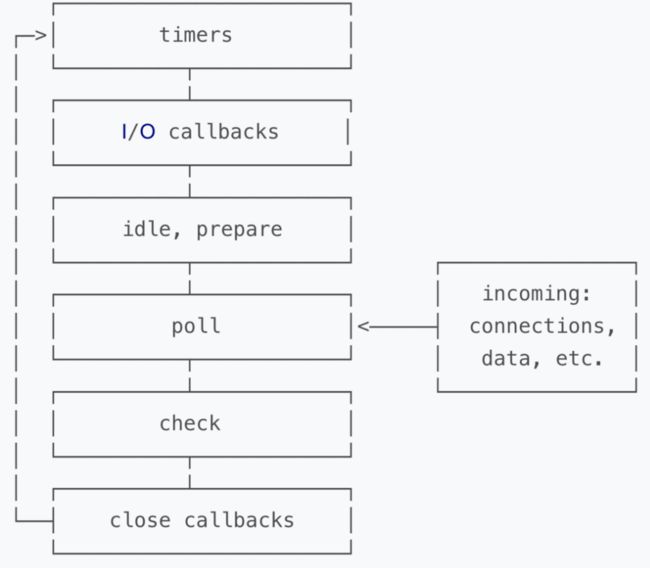
注意: 图中的每个方框被称作事件循环的一个”阶段(phase)”, 这6个阶段为一轮事件循环。
阶段概览
timers(定时器) : 此阶段执行那些由
setTimeout()和setInterval()调度的回调函数.-
I/O callbacks(I/O回调) : 此阶段会执行几乎所有的回调函数, 除了 close callbacks(关闭回调) 和 那些由 timers 与
setImmediate()调度的回调.setImmediate 约等于 setTimeout(cb,0)
idle(空转), prepare : 此阶段只在内部使用
poll(轮询) : 检索新的I/O事件; 在恰当的时候Node会阻塞在这个阶段
check(检查) :
setImmediate()设置的回调会在此阶段被调用close callbacks(关闭事件的回调): 诸如
socket.on('close', ...)此类的回调在此阶段被调用
在事件循环的每次运行之间, Node.js会检查它是否在等待异步I/O或定时器, 如果没有的话就会自动关闭.
如果event loop进入了 poll阶段,且代码未设定timer,将会发生下面情况:
- 如果poll queue不为空,event loop将同步的执行queue里的callback,直至queue为空,或执行的callback到达系统上限;
- 如果poll queue为空,将会发生下面情况:
- 如果代码已经被setImmediate()设定了callback, event loop将结束poll阶段进入check阶段,并执行check阶段的queue (check阶段的queue是 setImmediate设定的)
- 如果代码没有设定setImmediate(callback),event loop将阻塞在该阶段等待callbacks加入poll queue,一旦到达就立即执行
如果event loop进入了 poll阶段,且代码设定了timer:
- 如果poll queue进入空状态时(即poll 阶段为空闲状态),event loop将检查timers,如果有1个或多个timers时间时间已经到达,event loop将按循环顺序进入 timers 阶段,并执行timer queue.
一些题目
在nodejs中, setTimeout(demo, 0) === setTimeout(demo, 1)
在浏览器里面 setTimeout(demo, 0) === setTimeout(demo, 4)
setTimeout(function timeout () {
console.log('timeout');
},1);
setImmediate(function immediate () {
console.log('immediate');
});
// setImmediate它有时候是1ms之前执行,有时候又是1ms之后执行?
因为event loop的启动也是需要时间的,可能执行到poll阶段已经超过了1ms,此时setTimeout会先执行。反之setImmediate先执行
var path = require('path');
var fs = require('fs');
fs.readFile(path.resolve(__dirname, '/read.txt'), () => {
setImmediate(() => {
console.log('setImmediate');
})
setTimeout(() => {
console.log('setTimeout')
}, 0)
});
此时是永远setImmediate先执行,然后执行setTimeout。因为setImmediate在file 的callback之后的check阶段执行,而setTimeout则会进入下次循环的timer阶段执行。
process.nextTick
process.nextTick()不在event loop的任何阶段执行,而是在各个阶段切换的中间执行,即从一个阶段切换到下个阶段前执行。
var fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
process.nextTick(()=>{
console.log('nextTick3');
})
});
process.nextTick(()=>{
console.log('nextTick1');
})
process.nextTick(()=>{
console.log('nextTick2');
})
});
//nextTick1 nextTick2 setImmediate nextTick3 setTimeout
设计原因
允许开发者通过递归调用 process.nextTick() 来阻塞I/O操作。
nextTick应用场景
-
在多个事件里交叉执行CPU运算密集型的任务:
const http = require('http'); function compute() { //此处直接调用compute则会阻塞死掉,http无法响应 //但是通过nextTick则一次计算完成可以事件轮询继续走下去,又http请求过来还可以响应,然后等 //阶段切换会继续执行compute,也就是说递归compute被每次都分隔开计算,如果计算不是十分复杂 //,这种方式很好,但是如果单次compute计算都很长时间,依然会“卡死”请求 process.nextTick(compute); } http.createServer(function(req, res) { // 服务http请求的时候,还能抽空进行一些计算任务 res.writeHead(200, {'Content-Type': 'text/plain'}); res.end('Hello World'); }).listen(5000, '127.0.0.1'); compute();在这种模式下,我们不需要递归的调用compute(),我们只需要在事件循环中使用process.nextTick()定义compute()在下一个时间点执行即可。在这个过程中,如果有新的http请求进来,事件循环机制会先处理新的请求,然后再调用compute()。反之,如果你把compute()放在一个递归调用里,那系统就会一直阻塞在compute()里,无法处理新的http请求了。
-
用在事件触发过程中
EventEmitter有2个比较核心的方法, on和emit。node自带发布/订阅模式
var EventEmitter = require('events').EventEmitter;
function StreamLibrary(resourceName) {
//同步的,此时触发,但是下面的注册事件可能还没完成
this.emit('start');
}
StreamLibrary.prototype.__proto__ = EventEmitter.prototype; // inherit from EventEmitter
var stream = new StreamLibrary('fooResource');
stream.on('start', function() {
console.log('Reading has started');
});
function StreamLibrary(resourceName) {
var self = this;
//改进版本,这样就可以保证触发的时候,肯定已经注册
process.nextTick(function() {
self.emit('start');
}); // 保证订阅永远在发布之前
// read from the file, and for every chunk read, do:
}