问题:使用scrapy框架下载上证交易所的年报pdf文件,经常性的出现TCP连接错误。并且pdf大小10M量级的文件下载成功率极低。
解决:不是scrapy的提供的下载部件下载,我选择修改下载中间件。在下载中间件中使用requests库来获取请求所要访问的页面信息,然后将获取的信息封装到一个Response中返回,这样实现使用requests库来获取网页数据,跳过scrapy的下载部件。实测:成功率提高,出现的TCP连接失败率大大降低。
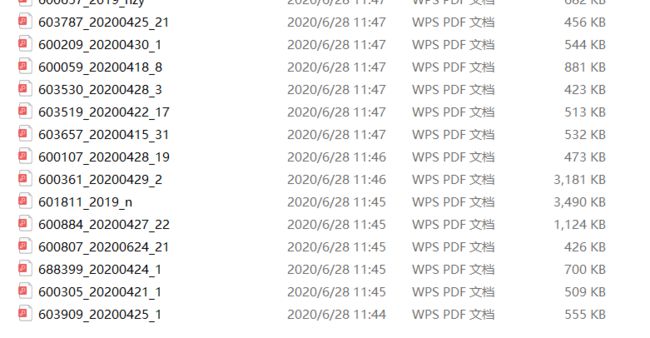
图1为使用scrapy的下载部件下载的内容情况,能够成功下载的文件均不大。
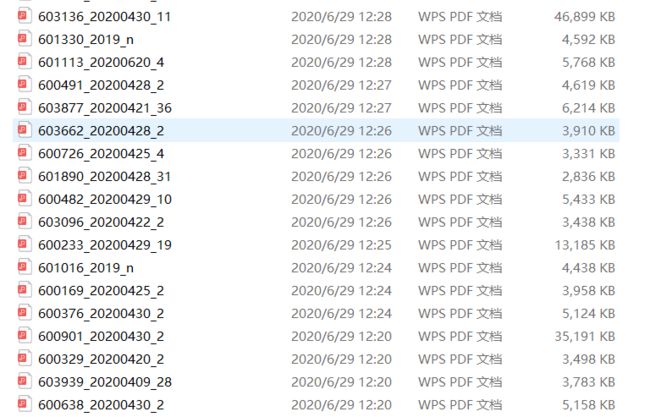
图2位面对上面的问题,做出改进后获取到的文件,由于scrapy的下载部件大的文件下载成功率低,这也导致剩下的文件也多为大文件。
代码:
class ChangeProxy(object):
#运行这一部分代码就已经把ip地址改变了
def __init__(self):
#get_url为申请Ip的APi接口
self.get_url='http://120.79.85.144/index.php/api/entry?method=proxyServer.tiqu_api_url&packid=0&fa=0&dt=0&groupid=0&fetch_key=&qty=4&time=1&port=1&format=json&ss=5&css=&dt=0&pro=&city=&usertype=6'
#通过访问temp_url测试申请Ip有效性
self.temp_url ='http://www.sse.com.cn/disclosure/listedinfo/regular/'
#IP池
self.ip_list = []
#选用Ip在Ip池中的位置
self.ip_pos =0
#定时器
self.pre = time.time()
self.late = time.time()
def getIPData(self):
'''这部分获得ip值,先清空原有的ip值'''
temp_data = requests.get(url=self.get_url).text
#输出请求到的ip列表
print(json.loads(temp_data))
#将申请到的Ip逐个放入IP池
for eve_ipin json.loads(temp_data)["data"]:
self.ip_list.append({
"ip" : eve_ip["IP"],
"port" : eve_ip["Port"],
})
#迭代申请
if (len(self.ip_list) <3):
self.getIPData()
def changeProxy(self, request):
''' 修改代理ip'''
#在IP池中随机获取一个ip
r = random.random()
self.ip_pos = (int)(r *len(self.ip_list))
request.meta['proxy'] ='http://' +str(self.ip_list[self.ip_pos]["ip"]) +':' \
+str(self.ip_list[self.ip_pos]["port"])
def process_request(self, request,spider):
self.late = time.time()
if len(self.ip_list) <3:
time.sleep(2)
self.getIPData()
elif self.late -self.pre >600:
self.pre =self.late
self.ip_list.clear()
self.getIPData()
self.changeProxy(request)
print('\n IP池的IP数量={}\n'.format(len(self.ip_list)))
print('\n current ip: {}\n'.format(self.ip_list[self.ip_pos]) +'{}\n'.format(request.url))
headers = {"User-Agent" : request.headers['User-Agent']}
proxies = {'https' : request.meta['proxy'].split('//')[1]}
res = requests.get(request.url,headers=headers,proxies=proxies)
return HtmlResponse(url=request.url,body=res.content,encoding='utf-8',request=request)
def process_response(self, request, response,spider):
if response.status !=200:
url = request.meta['proxy']
ip = url.split('//')[1].split(':')[0]
port = url.split('//')[1].split(':')[1]
iport = {'ip' : ip,'port' : (int)(port)}
if iportin self.ip_list:
self.ip_list.remove(iport)
request.dont_filter =True
return request
return response

代码贴出的部分包括我切换ip的部分,图3为使用requests库获取网络信息的部分,由于图3中出现部分ip的内容,所以将这整个中间件的代码都放出来。

核心内容为此两行:有res存放requests库请求获得的内容,返回一个htmlResponse类,其括号中的内容,是进行一些属性配置。
from scrapy.httpimport HtmlResponse 可以引入HtmlResponse 类