- 存在性检查
--正确姿势:
SELECT COUNT(*) FROM dual WHERE EXISTS (SELECT 1 FROM yxxc_gzb);
--不正确姿势:
SELECT COUNT(*) FROM yxxc_gzb;
- 提防 DDL 提交事务
DDL 语句的第一步就是 COMMIT,然后才是执行 DDL 本身,无任命令是否执行成功,
都已经提交。所以不要在事务中使用 DDL 语句
- 减少对 sysdate 的调用
sysdate 函数在经常会被使用,但它是函数,一定要注意将 sysdate 移出循环,先赋予
变量,然后在循环中引用变量。
- 把静态表达式迁出循环和 SQL 语句
PROCEDURE show_customers(prefix_in IN VARCHAR2, state_in IN VARCHAR2) IS
c_state CONSTANT mfe_customers.state%TYPE := upper(state_in);
c_output_prefix CONSTANT VARCHAR2(32767) := to_char(SYSDATE, 'Mon DD, YYYY') || ' ' ||
upper(prefix_in) || ' ' ||
c_state;
CURSOR customers_cur IS
SELECT last_name, first_name, city
FROM mfe_customers
WHERE state = c_state;
BEGIN
FOR customer_rec IN customers_cur LOOP
dbms_output.put_line(c_output_prefix || ' ' || customer_rec.first_name || ' ' ||
customer_rec.last_name);
END LOOP;
END show_customers;
- 与NULL值进行比较或逻辑运算的时候千万不要使用“=”,“<>”操作符,要用IS NULL操作符
(NULL值并不等于其它的所有值,甚至不等于另外的一个NULL值,程序代码应该显式的处理NULL值)
--假设业务:两个为空的字符相等
DECLARE
v_first_name VARCHAR2(100);
v_second_name VARCHAR2(100);
BEGIN
v_first_name := '';
v_second_name := '';
--不正确姿势
IF v_first_name = v_second_name THEN
dbms_output.put_line('v_first_name和v_second_name相等');
ELSE
dbms_output.put_line('v_first_name和v_second_name不相等');
END IF;
--正确姿势
IF v_first_name = v_second_name THEN
dbms_output.put_line('v_first_name和v_second_name相等');
ELSIF v_first_name IS NULL AND v_second_name IS NULL THEN
dbms_output.put_line('v_first_name和v_second_name相等');
ELSE
dbms_output.put_line('v_first_name和v_second_name不相等');
END IF;
END;
--IF模版
DECLARE
v_action VARCHAR2(100);
BEGIN
IF v_action = 'ADD' THEN
--增加操作
ELSIF v_action = 'UPDATE' THEN
--修改操作
ELSIF v_action IS NULL THEN
--处理NULL值
ELSE
--处理其它情况
ENF IF;
END;
- 避免在声明部分指定默认值,特别这些值是函数调用返回的值
块的异常部分只会处理块的执行部分抛出的异常,假如声明块中抛出异常,是不会被异常处理部分捕获的,而会往调用方抛出。
- 清理PLSQL块中的数据
比如:动态游标使用完记得关闭,很多情况是出现异常没关闭。
- 最好不要在包说明中定义变量,每个对包有执行权限的人都可以看到甚至修改
如果有需要,建议在包体定义变量,并且通过set/get控制对包数据的访问(意味着在过程或函数中,不要直接引用变量,而是通过get方法)
在复杂的IF ELSIF ELSE 语句中,可以建议使用case语句来替代(不要忘记else语句),增强可读性。
PL/SQL的异常处理机制
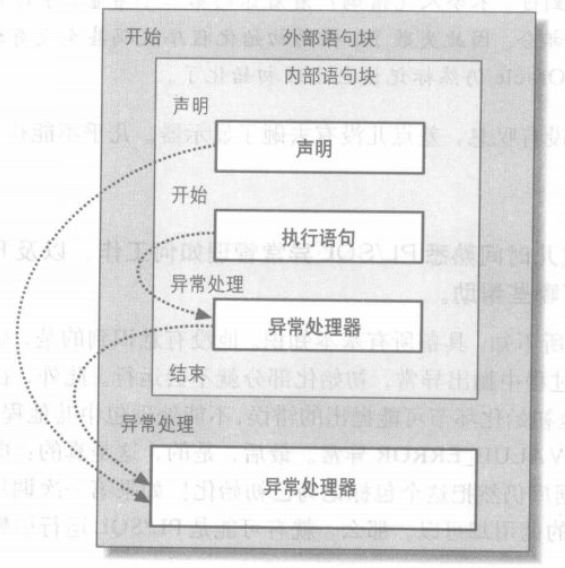
image
- 避免在异常部分中嵌入应用程序逻辑
- 避免通过错误编码引用异常,若Oracle没给该异常命名,自己给它命一个
-
前:
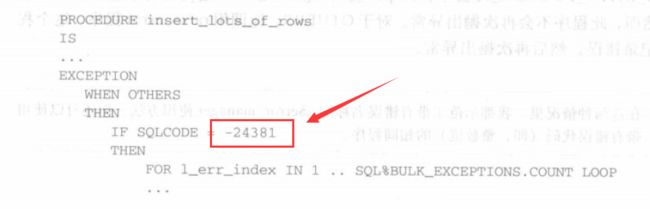 image
image -
后:
 image
image
-
- PL/SQL查询
- 把查询的值写入记录中,即使用%rowtype
- 只有当需要检索多行数据时,才使用游标for循环
- PL/SQL修改
- 要始终显式列出INSERT语句中所使用的数据库表的列
- SQL%属性总是会话中最近执行的隐式游标
注意:当更新或者删除那些“本应该”存在的数据时,要检查SQL%ROWCOUNT属性,以验证所完成动作的正确性。
SQL%ROWCOUNT:受DML语句影响的数据行的数量
SQL%FOUND:该语句影响至少一行数据时,返回TRUE
SQL%NOTFOUND:该语句影响至少一行数据时,返回FALSE
-
动态SQL
- 把动态SQL字符串赋给一个变量,需要时尽可能用占位符,即绑定变量
- 避免SQL串联,防止SQL注入
- 对于存在动态SQL语句的程序(模式级别或者包内过程)来说,最好使用AUTHID CURRENT_USER定义为调用者模式,可最大程度降低风险
函数的要点就是能够返回一个值(标量、集合、记录),如果通过使用OUT、IN OUT参数列表返回值的话,则函数的功能用途显得不明显了,此时可以考虑使用过程。
如果需要同时返回多项信息,可采用如下方式:
1、返回一个记录或集合
2、将函数变成过程
3、将独立的函数分解成复合函数,并全部返回标量值??
- 对于子程序而言,参数列表应该明确地描述程序实现其功能时需要的参数,以及有可能返回的值。
当在一个主过程包含子过程或子函数时,如果子过程等需要的参数包括主过程传递进来的某些参数时,
最好在子过程的参数中也进行定义下,而不要说直接拿主过程的参数,
之前写代码时一直在考虑是否要定义形参,犹豫不决,导致有些子过程有定义,有些则没有,不太规范。
- 如果需要往已有的程序增加参数时,要考虑原有调用程序能够不受影响,可使用以下方式:
1、确保新增的IN参数都有默认值,当然,如果参数是OUT或IN OUY的话,则不行
2、增加重载函数/过程,这时要注意,千万不要将原有函数/过程的代码COPY过来,而应创建另一个“核心”程序供其调用
- 当一个过程实现逻辑比较复杂时,最好对其进行功能拆分(逐步求精法、自顶向下设计法),使用本地子程序,使主程序执行部分可进行调用,使得逻辑更清晰,把实现细节进行封装。
写代码时,可以先进行程序接口设计,将实现逻辑进行拆分,跟JAVA的接口设计类似,
最后再对其具体实现详细编码,让编码者或者他人看到程序执行部分时,能够很好的理解其实现意图
- 尽可能把更多的业务规则封装、隐藏在函数中,供其它过程调用。
所有软件项目的一个特性是:永远不会变化的是事物一直在变化,如业务需求、数据结构或用户界面等等。
我们最好能够编写出能够容易适应这些变化的代码。
- 不要在函数中出现多个出口,遵循“一个入口只能有一个出口”,另外,在异常处理部分也要保留RETURN语句。
- 返回布尔值的函数绝对不能返回NULL(确保返回TRUE或者FALSE),这点在进行条件判断的时候尤其要注意。
-- 是否包含指定数字(6或者8)
--不好的函数:
CREATE OR REPLACE FUNCTION is_contains_special_number(i_str IN VARCHAR2)
RETURN BOOLEAN IS
BEGIN
RETURN instr(i_str, '6') > 0 OR instr(i_str, '6') > 0;
END is_contains_special_number;
--当传入NULL时,输出contains special number,明显有问题
BEGIN
IF NOT is_contains_special_number('') THEN
dbms_output.put_line('not contains special number');
ELSE
dbms_output.put_line('contains special number');
END IF;
END;
--姿势换一下,调用方作处理,但治标不治本,不能确保所有调用方都这么处理:
BEGIN
IF NOT NVL(is_contains_special_number(''),FALSE) THEN
dbms_output.put_line('not contains special number');
ELSE
dbms_output.put_line('contains special number');
END IF;
END;
--修改函数(确保返回TRUE或者FALSE):
CREATE OR REPLACE FUNCTION is_contains_special_number(i_str IN VARCHAR2)
RETURN BOOLEAN IS
v_result BOOLEAN;
BEGIN
IF instr(i_str, '6') > 0 OR instr(i_str, '6') > 0 THEN
v_result:=TRUE;
ELSE --当i_str为空时,也返回FALSE
v_result:=FALSE;
END IF;
RETURN v_result;
END is_contains_special_number;
-
包的最佳实践:
- 使用程序包组合功能相关的程序,避免编写模式别的过程或函数
总是从程序包开始,即时此时包中仅仅只有一个程序,将来也很有可能会有很多程序- 让程序包的关注面范围小而窄
-
尽可能使用bull colect和forall进行批量提取数据,减少上下文切换
-
关于bull colect的建议
- 更多内存,空间换时间
注意: PL/SQL集合消耗的内存来自于PGA,而不是SGA,即内存消耗是以每个会话为基础的。 假如程序中bull collect需要耗费5M内存,而并发连接有1000个,则你的应用程序需要耗费5G内存,这不容忽视。- LIMIT子句
当使用bull colect时,应该要同时使用LIMIT子句,生产环境的数据量可能会大幅度增长。 可尝试不同的LIMIT值,以平衡优化的性能和内存消耗的关系。- 没有游标属性
当与显式游标和循环一起使用LIMIT子句时,不要使用SQL%NOTFOUND和NO_DATA_FOUND等来终止循环。 而应该要检查bull colect填充的集合,假如没有数据返回了,集合数量为0。- 非字符串索引的集合,集合索引值始终从1开始
-
关于forall的建议
- 异常,考虑添加save exception
默认情况下,当循环中红的DML语句出现问题时导致SQL引擎抛出异常时, 会把这个异常传回PL/SQL引擎,此时会终止程序, 可给forall头部增加save exception子句,保存执行过程中抛出的异常,并在结束时返回所有的异常。- 每个forall语句中,只可以执行一条DML语句
-
-
缓存实践(尽可能在最快的内存位置,缓存静态数据)
备注: SGA:数据库实例保留一份,所有会话均可使用 PGA:每个会话保留一份- 包缓存,保存在PGA,消耗内存大
1、一般后台应用程序会使用连接池技术,需要确保的是:缓冲池中每个连接都包含相同的被缓冲数据, 避免前端应用程序在不同的会话间切换时,操作不同的数据集。 2、应该在包体内部声明数据结构(私有,只能在包内使用),以便于管理其内容,保证完整性。 CREATE OR REPLACE PACKAGE BODY emplu2 IS TYPE tab_tabtype IS TABLE OF employee%ROWTYPE INDEX BY BINARY_INTEGER; loadtab tab_tabtype; FUNCTION onerow ( employee_id_in IN employee.employee_id%TYPE ) RETURN employee%ROWTYPE IS BEGIN RETURN loadtab (employee_id_in); EXCEPTION WHEN NO_DATA_FOUND THEN RETURN emplu1.onerow (employee_id_in); END; BEGIN FOR rec IN (SELECT * FROM employee) LOOP loadtab (rec.employee_id) := rec; END LOOP; END;- 结果缓存,保存在SGA,消耗内存小
管道函数
当集合和记录是OUT或IN OUT参数时,可以考虑使用NOCOPY降低负载
函数或过程参数模式:
1、IN:读(传引用)
2、OUT:写,初始值默认null(传值)
3、IN OUT:读写(传值)
传值:复制进,复制出。参数的值会被复制到应用程序的数据结构,
传引用:程序中参数变量指向值所在内存区域。