提出一种transformer结构,去除rnn和cnn网络,去掉了recurrent的概念
background
rnn缺点:时序计算导致无法并行训练,且无法有效解决
现状
some用cnn取代rnn来优化计算。在计算两个distant input时候计算量较大,而transformer是线性的
(如何实现?
transformer完全依赖self-attention
结构
stacked self-attention and point-wise
encode和decoder

如图所示,
encoder的基本结构是一个multi-head attention 子网络加一个全连接子网络。每个子网络都引入了residual直连机制,将输入和子网络输出做了一次normalization。encoder由6个这样的子结构组成(为了方便直连,所有embedding输出都是512维度)
decoder基本结构是两个multi-head attention子网络加一个全连接网络,第二个multi-head用来处理encoder的输出。decoder由6个这样的子结构组成(加入了mask机制, masking 的作用就是防止在训练的时候 使用未来的输出的单词。 比如训练时,第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能基于比 i 小的输出。
注意,对于multi-head attention,在encoder中,query=key=value=encoder的输入,在decoder中的第一个multi-head网络中,query=key=value=decoder的输入。在decoder的第二个multi-head网络中,query=decoder第一个mutli-head网络的输出,key=value=encoder的输出。
对于query=key=value的情况,即是大名鼎鼎的self-attention机制
attention机制
给定query,key的维度是,value的维度是
一个attention 函数可以被看做一个query和key-value pairs 到output的映射。query,key,values,output都是向量。
output是由value的加权和得到的,权重取决于query以及对应的key。
目前有两种常用的attention function: 内积和加性(加性通过全连接实现)
scaled内积attention
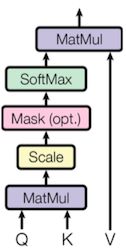
先内积,再用 scale, 最后通过一个softmax function得到weight
当较小时,内积attention和加性attention表现差不多。
如果 较大,加性attention表现的更好
论文猜测如果较大,会导致输入到softmax的值较大,使落入饱和区,进而导致梯度消失问题(梯度消失问题很重要)
因子起到调节作用,使得内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了
multi-head attention
multi-head attention的思想很像卷积网络的卷积核
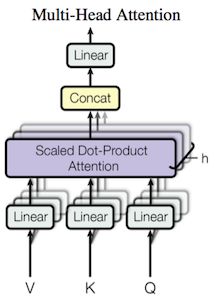
对query,key,value做h次投影,每次投影后的维度都是,,
然后都经过scaled dot-attention,最后将这h次结果拼接在一起,最后线性输出。

这里的多头参数并不共享
因为论文设定h=8,所以,=/h
Position-wise Feed-Forward Network
Embeddings and Softmax
在预训练input tokens和output tokens的embedding时,embedding层共用相同的权重和softmax权重。
在embedding层,transformer对权重乘以了一个
Positional Encoding
transformer在网络结构中没有recurrent和convlution的概念,为了学习到相对位置之间的关系,提出了position embedding
position embeding是在网络最底层和word embedding一起加入的,维度和embedding维度一样都是,是直接加在一起的

这里的意思是将id为p的位置映射为一个dpos维的位置向量,这个向量的第i个元素的数值就是PE(p,i)。这里的i对照着公式看可知i<=/2
transformer使用这种正弦函数的原因是,若固定k,位置置p+k的向量可以表示成位置p的向量的线性变换
self-attention的好处
主要体现在计算复杂度的降低和长句子之间的词关联程度。
attention的思路很粗暴,它一步到位获取了全局信息
训练
预处理
WMT 2014 English-German datase数据集
相似长度的句子放在同一batch
训练方法
Adam。β1 = 0.9, β2 = 0.98 and ε = 10−9.
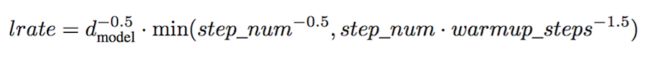
learning_rate前warmup_step 步线性增长,后面以正比于的速度减少
正则项
在每一层子网络输入到normalizaiton和下一层网络前做了dropout。
在word embeeding和position embedding相加的时候,做了dropout
dropout率都是0.1
做了label smoothing。 =0.1
u(k)可以是均匀分布
即是在label中加入噪声
实验结果
在机器翻译时,对最近20个保存结果取了平均。采用了beam_search,
beam_size=4, length_penalty=0..6
设置了最长生成长度为input长度+50,但是往往终结得很早。
文章为了比较不同模块对结果的影响,在base的基础上设置了不同的参数进行比较
PPL定义。N是句子长度。PPL越小越好

bleu是针对机器翻译的一种评判标准,bleu值在0和1之间,值越大越好
发现变小,模型性能变差