非诚勿扰系列(1)—摊牌了,我叫彭于晏,我去和美女嘉宾相亲了!!
文章目录
-
- 故事篇
- 原理篇
- 实战篇
- 小结
故事篇
据说,有一天,我做了个梦,梦里我身高七八尺,纵享八块腹肌,耳边了传来了熟悉的音乐“Can you feeling,show what's this,欢迎各位女嘉宾登场......”侧身一看,是那个头顶反光的男人–孟非老师!
摊牌了!我不装了,我叫彭于晏,我在08年参加了非诚勿扰…

孟非老师:“在第一个阶段,给你提供了一个平板,你在系统里面根据自己的喜好在里面选择自己心仪的女嘉宾,然后我们会根据你的喜好,为你挑选你喜欢的女嘉宾。”
孟非老师:“我们的女嘉宾来自世界各地,有欧美的女生,也有韩国、日本的女生,从安妮·海瑟薇、索菲·玛索到泰勒·斯威夫特,再到韩国的小姐姐–全智贤、裴秀智、宋慧乔等等,再到日本的森系女生–石原里美、三吉彩花、小松菜奈等等,还有香港的港风女神–王祖贤、张柏芝、张曼玉等等,最后到大陆的流量艺人–唐嫣、赵丽颖等等,你们喜欢的冰冰✧(≖ ◡ ≖✿ 也有哦。”
我(彭于晏):“好的,孟老师,我想看一下我们的预选女嘉宾库。”
我(彭于晏)拿起了节目组提供的iPad然后开始了女嘉宾照片的预览…
我(彭于晏)在随意(认真)看了看女嘉宾库后,还是觉得内心美最重要,于是我果断坚决地选择了都要(小孩子才做选择,大人是都要<(▰˘◡˘▰)>)。
孟非老师:“好了你可以做出选择了,彭于晏,看看你的标准是什么?然后筛选女嘉宾。”
我(彭于晏)开始了择偶标准的思考…
这个预选系统分为:自定义模式和默认模式,然后我(彭于晏)选择了自定义模式:

在我(彭于晏)的回忆(・ิω・ิ)里,第一个问题问我(彭于晏)的是关于女孩长相的类型,然后我(彭于晏)选择的是甜美:

紧接着,很快啊,啪地一下,又跳出了一个问题:
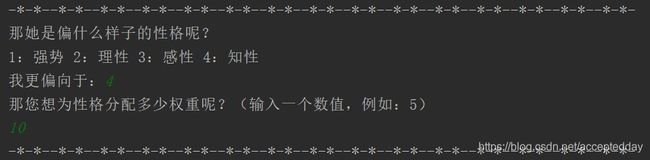
作为一个幽默,帅气,憨批的男人,我(彭于晏)选择了知性的女生类型!(~ ̄▽ ̄)~
然后系统问我,喜欢成熟还是不成熟的?我说成熟的,但是年龄没有那么重要,咱追求的是心态年轻!
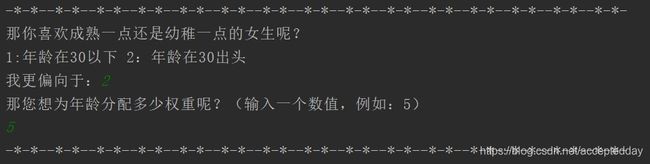
我(彭于晏)在一个飞机还不是很普及的年代(2008年),心仪的女孩最好还是本地的。

作为一个1米83的帅哥,我(彭于晏)当然还是选择170以上的女孩啦,哈哈!

拥有着八块腹肌,还是**希望她对自己的身材也有一定的要求**,于是选了C~D cup`,然后`大眼睛,双眼皮,黑眼睛,高鼻梁٩(๑❛ᴗ❛๑)۶的女生!



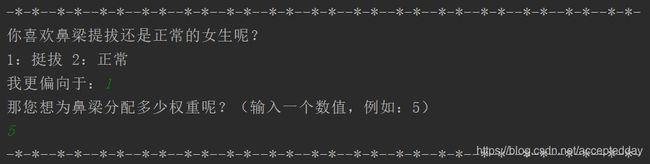
最后一个问题了!!
系统:你希望她是什么职业呢?
我(彭于晏):当然是圈外人啦,但是圈内也没关系啦,因为同行可以互相理解啦其实!

————————————系统正在为您筛选女嘉宾——————————————————————
结果出来了,她就是杨颖!
—————————————————————————————————————————————

杨颖:“你好呀!我是杨颖!下面是我的个人简介: ”
- Angelababy(杨颖),1989年2月28日出生于上海市,华语影视女演员、时尚模特。
- 2003年,Angelababy以模特身份出道,此后,她因担任时尚模特而在香港崭露头角。2007年,开始将工作重心转向大银幕。2011年,在爱情片《夏日乐悠悠》中首次担任电影女主角 [1] 。2012年,凭借言情片《第一次》获得第13届华语电影传媒大奖最受瞩目女演员奖 [2] 。2013年,Angelababy与其她三位女艺人被《南都娱乐周刊》选为新“四小花旦”;同年,她还完成了个人的荧屏处女作《大汉情缘之云中歌》 [3] 。
- 2014年,Angelababy开始凭借真人秀《奔跑吧兄弟》赢得广泛关注 [4] ;同年,她还因出演古装片《狄仁杰之神都龙王》获得第21届北京大学生电影节最受欢迎女演员奖 [5] 。2015年,其主演的冒险片《鬼吹灯之寻龙诀》票房突破16亿人民币 [6] ,而她也凭借该片获得第33届大众电影百花奖最佳女配角奖 [7] 。2017年,其主演的古装剧《孤芳不自赏》取得全国同时段电视剧收视冠军 [8] 。2020年5月20日,确定主演现代爱情片《明天你是否依然爱我》。 [9] 8月27日,第八次入选福布斯中国名人榜,并位列第16位 [10-11] 。2021年2月28日晚,2020新浪微博之夜在上海举行,Angelababy获得微博年度之星 [12] 。
- 您还可以看一下我的一段资料视频哦! https://www.bilibili.com/video/BV1bt4y1y7hj?from=search&seid=948744711247877427
杨颖:“所以,我可以和您交往(◕ᴗ◕✿)嘛,有缘人? ”
内心的OS:我(彭于晏)脸红地看了看她,白皙的皮肤,黑色的大眼睛,双眼皮,高鼻梁,不就是我(彭于晏)想象中的女友样子嘛?!
我(彭于晏):“可以!”
杨颖:“我叫杨颖,谢谢你喜欢我,往后的日子多多指教哇!”

在非诚勿扰节目上,我(彭于晏)认识了Anglebaby,但是没想到刚下节目,她竟然对我说她曾经和前男友…!!!
(未完待续…)

原理篇
我们怎么统计小姐姐的特点,然后根据不同的特点去预测我(彭于晏)可能会选择哪个小姐姐呢?是如何在茫茫小姐姐中选择了杨颖?
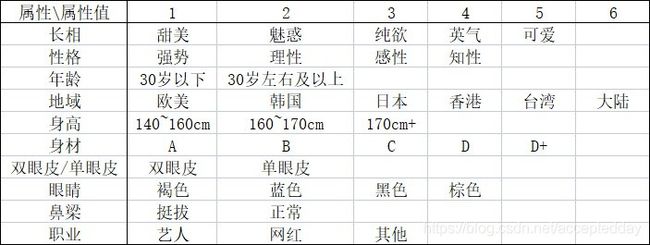
这里我们使用的原理是贝叶斯分类方法,首先将我(彭于晏)看中的择偶标准量化,量化如下表所示:
然后引入贝叶斯公式,当已知x属于类Ci时,p(x|Ci)当知道Ci分类结果的情况具有x特征的概率(理解这一点,非常重要!!),类Ci的后验概率计算如下:
P ( C i ∣ x ) = p ( x ∣ C i ) p ( C i ) p ( x ) = ∑ u = 1 U λ u p ( x u ∣ C i ) p ( C i ) ∑ k = 1 K ∑ u = 1 U λ u p ( x u ∣ C k ) p ( C k ) \mathbf{P}\left( \mathbf{C}_{\mathbf{i}}|\mathbf{x} \right) =\frac{\mathbf{p}\left( \mathbf{x}|\mathbf{C}_{\mathbf{i}} \right) \mathbf{p}\left( \mathbf{C}_{\mathbf{i}} \right)}{\mathbf{p}\left( \mathbf{x} \right)}=\frac{\sum_{\mathbf{u}=1}^{\mathbf{U}}{\mathbf{\lambda }_{\mathbf{u}}}\mathbf{p}\left( \mathbf{x}_{\mathbf{u}}|\mathbf{C}_{\mathbf{i}} \right) \mathbf{p}\left( \mathbf{C}_{\mathbf{i}} \right)}{\sum_{\mathbf{k}=1}^{\mathbf{K}}{\sum_{\mathbf{u}=1}^{\mathbf{U}}{\mathbf{\lambda }_{\mathbf{u}}}\mathbf{p}\left( \mathbf{x}_{\mathbf{u}}|\mathbf{C}_{\mathbf{k}} \right) \mathbf{p}\left( \mathbf{C}_{\mathbf{k}} \right)}} P(Ci∣x)=p(x)p(x∣Ci)p(Ci)=∑k=1K∑u=1Uλup(xu∣Ck)p(Ck)∑u=1Uλup(xu∣Ci)p(Ci)
而贝叶斯分类器选择具有最高后验概率的类,即:
选择 C i , P ( C i ∣ x ) = max k P ( C k ∣ x ) \text{选择}\mathbf{C}_{\mathbf{i}}\text{,}\mathbf{P}\left( \mathbf{C}_{\mathbf{i}}|\mathbf{x} \right) =\underset{\mathbf{k}}{\max}\mathbf{P}\left( \mathbf{C}_{\mathbf{k}}|\mathbf{x} \right) 选择Ci,P(Ci∣x)=kmaxP(Ck∣x)
u是小姐姐的属性,其中包括:长相,性格,年龄,地域,身高,身材,双眼皮/单眼皮,眼睛,鼻梁,职业;λ表示该属性的权重值,在我们的模式选择中,默认模式为λ=1/10,取所有属性的平均权重;而自定义模式则可以自由设定不同属性的权重。
Ci 表示数据库中的某一位小姐姐,其中包括:王冰冰,范冰冰,Lisa,王祖贤,唐嫣等;
P(Ci)表示在全体的广大男性同胞中,序号为i的小姐姐被选择的概率,这里,我们参考的是百度搜索结果的词条统计数,如“唐嫣”:
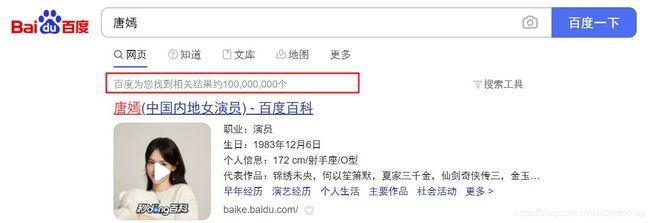
P(x|Ci)表示序号为i的小姐姐具有x属性的概率;
P(Ci|x)表示我们输入的择偶标准x,对应到选择每一个小姐姐后的预测概率。
实战篇
数据加载模块的代码如下:
def Data_Loading(filepath):
"""
csv数据的格式转换为np.ndarray,在读取的时候,pandas的read_csv默认过滤编号这一列数据
:param filepath: 原始csv文件的绝对路径
:return: data:转换为np.ndarray的数组
"""
data = pd.read_csv(filepath, index_col=0, encoding="gbk")
data = np.array(data.head(80)) # 将csv格式转换为np.ndarray
# print(data)
# print("原始数据的规模为:" + str(data.shape))
# print(len(data))
return data
提问回答模块的代码如下:
class Q_A:
def __init__(self):
"""
初始化问答的各项指标和权重参数
"""
self.look, self.character, self.age, self.origin, self.height = 0, 0, 0, 0, 0
self.bodyshape, self.eyelids, self.eyescolor, self.nose, self.career = 0, 0, 0, 0, 0
print("-*-*-" * 15)
mode = int(input("请问您想选择什么模式呢?自定义权重模式,还是默认模式呢?\n1:自定义模式2:默认模式\n"))
print("-*-*-" * 15)
assert (1 <= int(mode) <= 2), "输入的选项错误!"
if mode == 1:
self.wgtmode = True
else:
self.wgtmode = False
# 自定义权重矩阵默认为空
self.weights = []
self.key_value = ["长相", "性格", "年龄", "地域", "身高", "身材", "眼皮类型", "眼睛的颜色", "鼻梁", "职业"]
def _WeightSetting(self, index):
"""
设置不同指标的权重
:param index: 指标的索引
:return: 权重数值
"""
if self.wgtmode is True:
weight_in = input("那您想为%s分配多少权重呢?(输入一个数值,例如:5)\n" % self.key_value[index])
self.weights.append(weight_in)
print("-*-*-" * 15)
def _Look(self):
answer = input("你好,请告诉我,你喜欢什么长相类型(•̀ω•́ )✧的女生呀?\n"
"1:甜美 2:魅惑 3:纯欲 4:英气 5:可爱\n"
"我更偏向于:")
assert (1 <= int(answer) <= 5), "输入的选项错误!"
self.look = answer
if self.wgtmode is True:
self._WeightSetting(0)
else:
print("-*-*-" * 15)
def _Character(self):
answer = input("那她是偏什么样子的性格呢?\n"
"1:强势 2:理性 3:感性 4:知性\n"
"我更偏向于:")
assert (1 <= int(answer) <= 4), "输入的选项错误!"
self.character = answer
if self.wgtmode is True:
self._WeightSetting(1)
else:
print("-*-*-" * 15)
def _Age(self):
answer = input("那你喜欢成熟一点还是幼稚一点的女生呢?\n"
"1:年龄在30以下 2:年龄在30出头\n"
"我更偏向于:")
assert (1 <= int(answer) <= 2), "输入的选项错误!"
self.age = answer
if self.wgtmode is True:
self._WeightSetting(2)
else:
print("-*-*-" * 15)
def _Origin(self):
answer = input("你可以告诉我,她是世界上哪个地域的女生嘛?\n"
"1:欧美 2:韩国 3:日本 4:香港 5:台湾 6:大陆\n"
"我更偏向于:")
assert (1 <= int(answer) <= 6), "输入的选项错误!"
self.origin = answer
if self.wgtmode is True:
self._WeightSetting(3)
else:
print("-*-*-" * 15)
def _Height(self):
answer = input("那她多高呢?\n"
"1:160以下 2:160~170 3:170以上\n"
"我更偏向于:")
assert (1 <= int(answer) <= 3), "输入的选项错误!"
self.height = answer
if self.wgtmode is True:
self._WeightSetting(4)
else:
print("-*-*-" * 15)
def _BodyShape(self):
answer = input("你希望她是什么样纸的身材(ฅωฅ*)呢?\n"
"1:B cup以下 2:C~D cup 3:D+ cup\n"
"我更偏向于:")
assert (1 <= int(answer) <= 3), "输入的选项错误!"
self.bodyshape = answer
if self.wgtmode is True:
self._WeightSetting(5)
else:
print("-*-*-" * 15)
def _Eyelids(self):
answer = input("在你的脑海中,她是双眼皮还是单眼皮呢?\n"
"1:双眼皮 2:单眼皮\n"
"我更偏向于:")
assert (1 <= int(answer) <= 2), "输入的选项错误!"
self.eyelids = answer
if self.wgtmode is True:
self._WeightSetting(6)
else:
print("-*-*-" * 15)
def _EyesColor(self):
answer = input("眼睛是心灵的窗户,她的眼睛是什么颜色呢?\n"
"1:褐色 2:蓝色 3:黑色 4:棕色\n"
"我更偏向于:")
assert (1 <= int(answer) <= 4), "输入的选项错误!"
self.eyescolor = answer
if self.wgtmode is True:
self._WeightSetting(7)
else:
print("-*-*-" * 15)
def _Nose(self):
answer = input("你喜欢鼻梁提拔还是正常的女生呢?\n"
"1:挺拔 2:正常\n"
"我更偏向于:")
assert (1 <= int(answer) <= 2), "输入的选项错误!"
self.nose = answer
if self.wgtmode is True:
self._WeightSetting(8)
else:
print("-*-*-" * 15)
def _Career(self):
answer = input("最后一个问题,你理想中的她是什么职业呢?\n"
"1:艺人 2:网红 3:其他\n"
"我更偏向于:")
assert (1 <= int(answer) <= 3), "输入的选项错误!"
self.career = answer
if self.wgtmode is True:
self._WeightSetting(9)
else:
print("-*-*-" * 15)
def Init_Configure(self):
"""
:return: 设定的标准,权重模式,指标的权重参数
"""
self._Look(), self._Character(), self._Age(), self._Origin(), self._Height()
self._BodyShape(), self._Eyelids(), self._EyesColor(), self._Nose(), self._Career()
standard_set = [self.look, self.character, self.age, self.origin, self.height,
self.bodyshape, self.eyelids, self.eyescolor, self.nose, self.career]
# print(standard_set)
return standard_set, self.wgtmode, self.weights
p(Ci)计算模块的代码如下:
def Norm_Ci(data):
"""
将输入的Ci进行正则化操作转换为P(Ci)
:param data: 原始的src_data,格式为np.ndarray
:return: new_data:对Ci转换为P(Ci)之后的标准部分的data数据(1~11列)
"""
# 先对"百度搜素结果统计"进行数据的清洗,例:43,000,000个->43000000
for i in range(len(data[:, 10])):
data[i, 10] = data[i, 10].replace(",", "")
data[i, 10] = data[i, 10].replace("个", "")
# print(data[:, 0:10])
print("-*-*-" * 15)
new_data = np.array(data[:, 0:11], dtype=np.float64) # 取出标准部分的数据(1~11列)转为float型
# print(new_data)
# 正则化Ci,计算P(Ci)
data_sum = sum(new_data[:, 10])
for i in range(len(new_data[:, 10])):
new_data[i, 10] = new_data[i, 10] / data_sum
# print(new_data)
return new_data
贝叶斯算法的核心—p(x|Ci)p(Ci)计算模块如下:
class Bayes_Core:
def __init__(self, stanard_set, data_in, wgtmode=False, weights=None):
# 初始化选择的standard
self.look_standard, self.character_standard, self.age_standard, self.origin_standard, self.height_standard = \
stanard_set[0], stanard_set[1], stanard_set[2], stanard_set[3], stanard_set[4]
self.bodyshape_standard, self.eyelids_standard, self.eyescolor_standard, self.nose_standard, self.career_standard = \
stanard_set[5], stanard_set[6], stanard_set[7], stanard_set[8], stanard_set[9]
# 考虑到测试者对自己的择偶标准可能并不准确,所以采用了近似度原则。
self.look_rule, self.character_rule, self.origin_rule = [], [], []
self.eyescolor_rule, self.career_rule = [], []
# 输入当前样本的各项属性的数据
self.look_in, self.character_in, self.age_in, self.origin_in, self.height_in = \
data_in[0], data_in[1], data_in[2], data_in[3], data_in[4]
self.bodyshape_in, self.eyelids_in, self.eyescolor_in, self.nose_in, self.career_in = \
data_in[5], data_in[6], data_in[7], data_in[8], data_in[9]
# 输入当前样本的P(Ci)
self.P_Ci = data_in[10]
# 添加权重参数错误异常
if wgtmode and weights is None:
raise Exception("输入的权重格式错误!")
# wgtmode=True,采用自定义权重模式;False则采用默认权重模式
self.weightmode = wgtmode
self.weights = np.array(weights, dtype=np.int64)
def __SimilarityRuleSetting(self):
# 1:甜美 2:魅惑 3:纯欲 4:英气 5:可爱
self.look_rule = [[1, 5, 4, 3, 2],
[2, 3, 4, 1, 5],
[3, 2, 1, 5, 4],
[4, 3, 2, 1, 5],
[5, 1, 3, 4, 2]]
# 1:强势 2:理性 3:感性 4:知性
self.character_rule = [[1, 2, 3, 4],
[2, 4, 1, 3],
[3, 4, 1, 2],
[4, 3, 2, 1]]
# 1:欧美 2:韩国 3:日本 4:香港 5:台湾 6:大陆
self.origin_rule = [[1, 4, 3, 2, 5, 6],
[2, 3, 4, 5, 6, 1],
[3, 6, 5, 2, 4, 1],
[4, 1, 3, 2, 5, 6],
[5, 6, 3, 2, 4, 1],
[6, 5, 2, 3, 1, 4]]
# 1:褐色 2:蓝色 3:黑色 4:棕色
self.eyescolor_rule = [[1, 4, 3, 2],
[2, 1, 4, 3],
[3, 1, 4, 2],
[4, 1, 3, 2]]
# 1:艺人 2:网红 3:其他
self.career_rule = [[1, 2, 3],
[2, 1, 3],
[3, 2, 1]]
def _ScorePush(self, score_input, index):
if not self.weightmode:
return score_input * 1 / 10
else:
return score_input * self.weights[index] / sum(self.weights)
def _LookScore(self):
# 1:甜美 2:魅惑 3:纯欲 4:英气 5:可爱
flag = len(self.look_rule[0]) - 1
for i in range(len(self.look_rule[0])):
if self.look_in == self.look_rule[int(self.look_standard) - 1][i]:
flag = i
break
look_score = 1 - 1 * flag / (len(self.look_rule[0]) - 1)
# 根据不同的模式输出属性的score
return self._ScorePush(look_score, 0)
def _CharacterScore(self):
# 1:强势 2:理性 3:感性 4:知性
flag = len(self.character_rule[0]) - 1
for i in range(len(self.character_rule[0])):
if self.character_in == self.character_rule[int(self.career_standard) - 1][i]:
flag = i
break
character_score = 1 - 1 * flag / (len(self.character_rule[0]) - 1)
# 根据不同的模式输出属性的score
return self._ScorePush(character_score, 1)
def _AgeScore(self):
# 1:年龄在30以下 2:年龄在30出头
if not self.weightmode:
if self.age_in == self.age_standard:
return 1 * 1 / 10
else:
return 0
else:
if self.age_in == self.age_standard:
return 1 * self.weights[2] / sum(self.weights)
else:
return 0
def _OriginScore(self):
# 1:欧美 2:韩国 3:日本 4:香港 5:台湾 6:大陆
flag = len(self.origin_rule[0]) - 1
for i in range(len(self.origin_rule[0])):
if self.origin_in == self.origin_rule[int(self.origin_standard) - 1][i]:
flag = i
break
origin_score = 1 - 1 * flag / (len(self.origin_rule[0]) - 1)
# 根据不同的模式输出属性的score
return self._ScorePush(origin_score, 3)
def _HeightScore(self):
# 1:160以下 2:160~170 3:170以上
if not self.weightmode:
if self.height_in == self.height_standard:
return 1 * 1 / 10
else:
return 0
else:
if self.height_in == self.height_standard:
return 1 * self.weights[4] / sum(self.weights)
else:
return 0
def _BodyShapeScore(self):
# 1:B cup以下 2:C~D cup 3:D+ cup
if not self.weightmode:
if self.bodyshape_in == self.bodyshape_standard:
return 1 * 1 / 10
else:
return 0
else:
if self.bodyshape_in == self.bodyshape_standard:
return 1 * self.weights[5] / sum(self.weights)
else:
return 0
def _EyelidsScore(self):
# 1:双眼皮 2:单眼皮
if not self.weightmode:
if self.eyelids_in == self.eyelids_standard:
return 1 * 1 / 10
else:
return 0
else:
if self.eyelids_in == self.eyelids_standard:
return 1 * self.weights[6] / sum(self.weights)
else:
return 0
def _EyesColorScore(self):
# 1:褐色 2:蓝色 3:黑色 4:棕色
flag = len(self.eyescolor_rule[0]) - 1
for i in range(len(self.eyescolor_rule[0])):
if self.eyescolor_in == self.eyescolor_rule[int(self.eyelids_standard) - 1][i]:
flag = i
break
eyescolor_score = 1 - 1 * flag / (len(self.eyescolor_rule[0]) - 1)
# 根据不同的模式输出属性的score
return self._ScorePush(eyescolor_score, 7)
def _NoseScore(self):
# 1:挺拔 2:正常
if not self.weightmode:
if self.nose_in == self.nose_standard:
return 1 * 1 / 10
else:
return 0
else:
if self.nose_in == self.nose_standard:
return 1 * self.weights[8] / sum(self.weights)
else:
return 0
def _CareerScore(self):
# 1:艺人 2:网红 3:其他
flag = len(self.career_rule[0]) - 1
for i in range(len(self.career_rule[0])):
if self.career_in == self.career_rule[int(self.career_standard) - 1][i]:
flag = i
break
career_score = 1 - 1 * flag / (len(self.career_rule[0]) - 1)
# 根据不同的模式输出属性的score
return self._ScorePush(career_score, 9)
def ScoreGather(self):
# 赋值相似度矩阵
self.__SimilarityRuleSetting()
# score_gather=P(x|Ci),final_score=P(x|Ci)*P(Ci)
score_gather = self._LookScore() + self._CharacterScore() + self._AgeScore() + self._OriginScore() + \
self._HeightScore() + self._BodyShapeScore() + self._EyelidsScore() + \
self._EyesColorScore() + self._NoseScore() + self._CareerScore()
final_score = score_gather * self.P_Ci
# 这里打印的是P(X|Ci)
# print(final_score)
return final_score
这里需要注意的是:我们的选择的标准采用了近似度的原则,什么是近似度原则呢?
因为,有个问题是,比如:我喜欢甜美的女孩,但是不代表就不喜欢纯欲风格的女生,所以如果一个女生不是甜美风格,她也是部分符合我(彭于晏)的择偶标准的!因此,我们引入了近似度原则,甜美的近似序列为:甜美—可爱—英气—纯欲—魅惑(近似度依次递减)。最终,经过考虑,对**“长相”、“性格”、“地域”、“眼睛的颜色”、“职业”采用了近似度的计算原则**,详情参考代码。
P(Ci|x)计算模块的代码如下:
def ScoreComputeAndSort(standard, use_data, src_data, wgtmode, weights):
# 将计算得到的所有的P(X|Ci)P(Ci)
stac_score = []
for i in range(len(use_data)):
stac_score.append(float(Bayes_Core(standard, use_data[i], wgtmode, weights).ScoreGather()))
# 将计算得到的所有的P(X|Ci)P(Ci)相加得到P(X),然后得到P(Ci|X)=P(X|Ci)P(Ci)/P(X)
final_Probab = []
for i in range(len(stac_score)):
final_Probab.append(stac_score[i] / sum(stac_score))
max_index = 0
for i in range(len(final_Probab)):
print("您选择%s的" % src_data[i][11] + "预测概率为:%f%%" % float(final_Probab[i] * 100))
if final_Probab[i] > final_Probab[max_index]:
max_index = i
print("-*-*-" * 15)
return max_index
预测选择的女嘉宾的信息展示模块的代码如下:
def VisualPredict(index, src_data, img_path):
print("%s:“你好呀! " % str(src_data[index][11]) + "我是%s!下面是我的个人简介:”" % str(src_data[index][11]))
print("-*-*-" * 15)
print("%s" % str(src_data[index][12]) + "\n您还可以看一下我的一段资料视频哦!\n%s" % str(src_data[index][13]))
print("-*-*-" * 15)
img = Image.open(os.path.join(img_path, str(index + 1) + ".jpg"))
img.show()
x = input("%s:“所以,我可以和您交往(◕ᴗ◕✿)嘛,有缘人?”\n1:可以,2:不可以\n我的选择是:" % str(src_data[index][11]))
print("-*-*-" * 15)
if int(x) == 1:
print("%s:" % str(src_data[index][11]) + "“我叫%s,谢谢你喜欢我,往后的日子多多指教哇!”" % str(src_data[index][11]))
LoveHeart(" 我❤你 ")
else:
print("%s:" % str(src_data[index][11]) + "你倔强的样子,人家好喜欢(✪ω✪),我来了,哈哈哈哈!")
LoveHeart(" 淦 ")
print("-*-*-" * 15)
def LoveHeart(keyword):
print("\033[0;31m%s\033[0m" % '\n'.join(
[''.join([(keyword[(x - y) % len(keyword)] if ((x * 0.05) ** 2 + (y * 0.1) ** 2 - 1) ** 3 - (
x * 0.05) ** 2 * (y * 0.1) ** 3 <= 0 else ' ') for x in range(-30, 30)]) for y in range(30, -30, -1)]))
点这里->该项目的测试视频的链接!!!
点这里->本文所有项目数据及代码均以上传,内含80位小姐姐的美图!提取码:ety3,如果bdy限速,请评论区留言,项目文件压缩包私发你!
完整的代码一定要下载,玩一玩!!!有彩蛋!!!!!
完整的代码一定要下载,玩一玩!!!有彩蛋!!!!!
完整的代码一定要下载,玩一玩!!!有彩蛋!!!!!
小结
整个项目,从数据集的收集及处理花了一整天的时间,外加代码的实现花了3天的时间,经过了几天的折腾,终于完成了这个非诚勿扰系列(1)--“心动女嘉宾的预测”,后面也会继续更新这个系列,想通过更多有趣的故事构思,给大家更生动理解机器学习或者深度学习的算法原理!
