环境
python版本:3.5
数据来源
数据来自51CTO网站的分享,点此下载
关联规则
所谓关联规则,就是指现实中同时发生两种不同事情之间的相关联程度,具体分析可以参考这篇博客,讲的很清晰
数据分析
这是数据文件

数据文件
其中movies中电影信息的内容如图所示
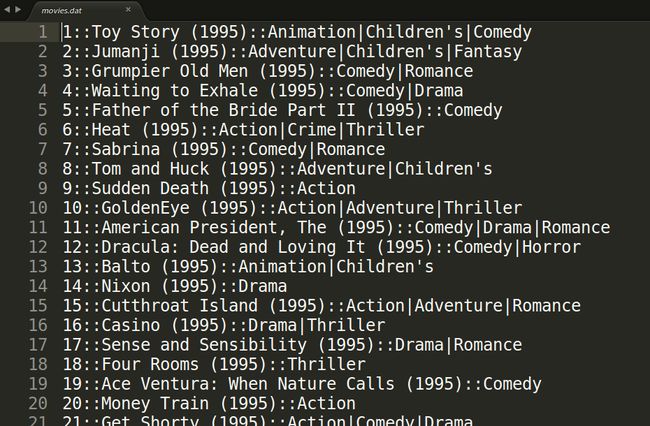
movies.dat
每行分别为电影id,电影名字,电影类型,每项之间用::分隔,rating.dat为收集的用户打分记录,users.dat为用户id对应的用户信息,personalRating.txt为个人打分,用来找到规律后为个人推荐电影,ratings.dat文件内容如图所示

ratings.dat
其中分别为用户id,电影id,评分(1-5分),评分时间,总共一百万行多点的数据。我设置评分3分以上算是喜欢,最小支持度为0.2,最小置信度为0.5,下面是代码实现
# -*- coding: utf-8 -*-
"""
Apriori exercise.
Created on Sun Oct 26 11:09:03 2017
@author: FWW
"""
import time
def createC1( dataSet ):
'''
构建初始候选项集的列表,即所有候选项集只包含一个元素,
C1是大小为1的所有候选项集的集合
'''
C1 = []
for transaction in dataSet:
for item in transaction:
if [ item ] not in C1:
C1.append( [ item ] )
C1.sort()
return list(map( frozenset, C1 ))
def scanD( D, Ck, minSupport ):
'''
计算Ck中的项集在事务集合D的每个transactions中的支持度,
返回满足最小支持度的项集的集合,和所有项集支持度信息的字典。
'''
ssCnt = {}
for tid in D:
# 对于每一条transaction
for can in Ck:
# 对于每一个候选项集can,检查是否是transaction的一部分
# 即该候选can是否得到transaction的支持
if can.issubset( tid ):
ssCnt[ can ] = ssCnt.get( can, 0) + 1
numItems = float( len( D ) )
retList = []
supportData = {}
for key in ssCnt:
# 每个项集的支持度
support = ssCnt[ key ] / numItems
# 将满足最小支持度的项集,加入retList
if support >= minSupport:
retList.insert( 0, key )
# 汇总支持度数据
supportData[ key ] = support
return retList, supportData
# Aprior算法
def aprioriGen( Lk, k ):
'''
由初始候选项集的集合Lk生成新的生成候选项集,
k表示生成的新项集中所含有的元素个数
'''
retList = []
lenLk = len( Lk )
for i in range( lenLk ):
for j in range( i + 1, lenLk ):
L1 = list( Lk[ i ] )[ : k - 2 ];
L2 = list( Lk[ j ] )[ : k - 2 ];
L1.sort();L2.sort()
if L1 == L2:
retList.append( Lk[ i ] | Lk[ j ] )
return retList
def apriori( dataSet, minSupport = 0.5 ):
# 构建初始候选项集C1
C1 = createC1( dataSet )
# 将dataSet集合化,以满足scanD的格式要求
D = list(map( set, dataSet ))
# 构建初始的频繁项集,即所有项集只有一个元素
L1, suppData = scanD( D, C1, minSupport )
L = [ L1 ]
# 最初的L1中的每个项集含有一个元素,新生成的
# 项集应该含有2个元素,所以 k=2
k = 2
while ( len( L[ k - 2 ] ) > 0 ):
Ck = aprioriGen( L[ k - 2 ], k )
Lk, supK = scanD( D, Ck, minSupport )
# 将新的项集的支持度数据加入原来的总支持度字典中
suppData.update( supK )
# 将符合最小支持度要求的项集加入L
L.append( Lk )
# 新生成的项集中的元素个数应不断增加
k += 1
# 返回所有满足条件的频繁项集的列表,和所有候选项集的支持度信息
return L, suppData
def calcConf( freqSet, H, supportData, brl, minConf=0.5 ):
'''
计算规则的可信度,返回满足最小可信度的规则。
freqSet(frozenset):频繁项集
H(frozenset):频繁项集中所有的元素
supportData(dic):频繁项集中所有元素的支持度
brl(tuple):满足可信度条件的关联规则
minConf(float):最小可信度
'''
prunedH = []
for conseq in H:
conf = supportData[ freqSet ] / supportData[ freqSet - conseq ]
if conf >= minConf:
#print (freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append( ( freqSet - conseq, conseq, conf ) )
prunedH.append( conseq )
return prunedH
def rulesFromConseq( freqSet, H, supportData, brl, minConf=0.5 ):
'''
对频繁项集中元素超过2的项集进行合并。
freqSet(frozenset):频繁项集
H(frozenset):频繁项集中的所有元素,即可以出现在规则右部的元素
supportData(dict):所有项集的支持度信息
brl(tuple):生成的规则
'''
m = len( H[ 0 ] )
if m == 1:
calcConf( freqSet, H , supportData, brl, minConf )
# 查看频繁项集是否大到移除大小为 m 的子集
if len( freqSet ) > m + 1:
Hmp1 = aprioriGen( H, m + 1 )
Hmp1 = calcConf( freqSet, Hmp1, supportData, brl, minConf )
# 如果不止一条规则满足要求,进一步递归合并
if len( Hmp1 ) > 1:
rulesFromConseq( freqSet, Hmp1, supportData, brl, minConf )
def recommendMovies(rules,personal_list,movie_list):
recommend_list = []
sup_list = []
for rule in rules:
if rule[0] <= personal_list:
for movie in rule[1]:
if movie_list[movie-1] not in recommend_list:
recommend_list.append(movie_list[movie-1])
sup_list.append(rule[2])
for recommend in recommend_list:
i = recommend_list.index(recommend)
print('Recommend you to watch',recommend,',',round(sup_list[i]*100,2),'% people who is similar to you like it!')
def generateRules( L, supportData, minConf=0.5 ):
'''
根据频繁项集和最小可信度生成规则。
L(list):存储频繁项集
supportData(dict):存储着所有项集(不仅仅是频繁项集)的支持度
minConf(float):最小可信度
'''
bigRuleList = []
for i in range( 1, len( L ) ):
for freqSet in L[ i ]:
# 对于每一个频繁项集的集合freqSet
H1 = [ frozenset( [ item ] ) for item in freqSet ]
# 如果频繁项集中的元素个数大于2,需要进一步合并
if i > 1:
rulesFromConseq( freqSet, H1, supportData, bigRuleList, minConf )
else:
calcConf( freqSet, H1, supportData, bigRuleList, minConf )
return bigRuleList
if __name__ == '__main__':
# 导入数据集
start_time = time.time()
file_object = open('ratings.dat')
movies_object = open('movies.dat')
personal_object = open('personalRatings.txt')
file_list = []
try:
all_the_text = file_object.read()
origin_list = (line.split('::') for line in all_the_text.split('\n'))
tem_list = []
for line in origin_list:
if len(file_list)3:
tem_list.append(int(line[1]))
movies_text = movies_object.read()
movies_list = []
for item in (line.split('::') for line in movies_text.split('\n')):
if item[1] not in movies_list:
movies_list.append(item[1])
personal_text = personal_object.read()
personal_list = []
for item in (line.split('::') for line in personal_text.split('\n')):
if int(item[2])>3:
personal_list.append(int(item[1]))
finally:
file_object.close()
movies_object.close()
personal_object.close()
print('Read file sucess in',time.time()-start_time,'s')
# 选择频繁项集
L, suppData = apriori( file_list, 0.2 )
rules = generateRules( L, suppData, minConf=0.5 )
#print ('rules:\n', rules)
print ('Caculate rules success in',time.time()-start_time,'s')
recommendMovies(rules,frozenset(personal_list),movies_list)
print ('The program completes in',time.time()-start_time,'s')
运行结果
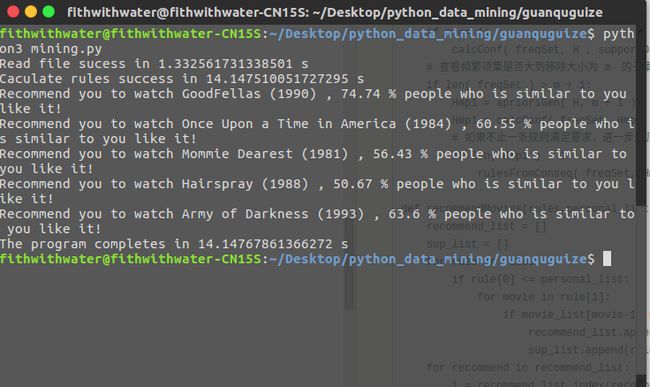
2017-11-05 14-53-20屏幕截图.png
读文件用了1.3秒,运行花了14秒,相信之后用numpy数组改进一下运行速度会更快