刨根问底(一)由 Linux 输入流引发的思考
哪些命令支持输入流
cat, more, less, head, tail, cut, sort, wc, sed …
哪些命令不支持输入流
ls, pwd, cd …
什么是输入流
输入流就是标准输入,在 C 程序里习惯记为 STDIN_FILENO。
/* Standard file descriptors. */
#define STDIN_FILENO 0 /* Standard input. */
#define STDOUT_FILENO 1 /* Standard output. */
#define STDERR_FILENO 2 /* Standard error output. */
疑问
命令还有这区别?平时没怎么注意过。什么叫做支持输入流,什么叫做不支持输入流呢?答案就是这个命令能不能够从标准输入读取数据,能就是支持输入流,不能就是不支持输入流。
例如:
支持输入流:cat
$ cat
hello
hello
我们在命令行输入 cat 回车,cat 进程就开始从标准输入读取数据,读不到就阻塞。我们从标准输入(这里是键盘设备)输入 hello 回车,cat 进程就从标准输入读取 hello 并输入到标准输出上(这里是屏幕设备)。
相反,
不支持输入流:ls
$ ls
bin dev lib libx32 mnt root snap sys var
boot etc lib32 lost+found opt run srv tmp
cdrom home lib64 media proc sbin swapfile usr
我们输入 ls 回车,它不会企图从标准输入读入内容。就算我们尝试给它一个输入,如:
$ echo "hello" | ls
bin dev lib libx32 mnt root snap sys var
boot etc lib32 lost+found opt run srv tmp
cdrom home lib64 media proc sbin swapfile usr
ls 也是非常高冷地忽视,不接受标准输入的内容。
背后的原理
cat, ls 差异背后的原理是什么呢?最好的探索办法就是看源码
cat.c 部分代码
FILE *bb_wfopen_input(const char *filename)
{
FILE *fp = stdin;
if ((filename != bb_msg_standard_input)
&& filename[0] && ((filename[0] != '-') || filename[1])
) {
#if 0
/* This check shouldn't be necessary for linux, but is left
* here disabled just in case. */
struct stat stat_buf;
if (is_directory(filename, 1, &stat_buf)) {
bb_error_msg("%s: Is a directory", filename);
return NULL;
}
#endif
fp = bb_wfopen(filename, "r");
}
return fp;
}
可以看到,cat 先判断有没有输入文件名,输入了就打开此文件,没输入文件名就默认打开标准输入。这就是为什么我们在命令行输入 cat 直接回车,cat 会从标准输入读取内容的原因了。
再来看 ls.c
extern int ls_main(int argc, char **argv)
{
ac = argc - optind; /* how many cmd line args are left */
if (ac < 1) {
av = (char **) xcalloc((size_t) 1, (size_t) (sizeof(char *)));
av[0] = bb_xstrdup(".");
ac = 1;
} else {
av = (char **) xcalloc((size_t) ac, (size_t) (sizeof(char *)));
for (oi = 0; oi < ac; oi++) {
av[oi] = argv[optind++]; /* copy pointer to real cmd line arg */
}
}
/* now, everything is in the av array */
if (ac > 1)
all_fmt |= DISP_DIRNAME; /* 2 or more items? label directories */
/* stuff the command line file names into an dnode array */
dn = NULL;
for (oi = 0; oi < ac; oi++) {
char *fullname = bb_xstrdup(av[oi]);
cur = my_stat(fullname, fullname);
if (!cur)
continue;
cur->next = dn;
dn = cur;
nfiles++;
}
...
}
ls 只处理了命令行参数,并没有读取标准输入。
小有结论
至此,命令支不支持输入流的问题已小有结论。就看它有没有去处理 stdin。
波澜再生
又有个疑问冒出来了:进程的 标准输入、标准输出、标准错误 哪来的?
write(1, "test\n", sizeof("test\n"));
为什么这行代码就能向标准输出打印 test ?标准输出 “1” 来自于哪里?
找到答案
按惯例,每当运行一个新程序时,所有的 shell 都为其打开三个文件描述符:标准输入(standard input)、标准输出(standard output) 以及标准错误(standard error)。如果像简单命令 ls 那样没有做什么特殊处理,则这三个描述符都链向终端。
—— 《UNIX 环境高级编程 第3版》
所以说,进程的 标准输入、标准输出、标准错误 来自于 shell。
继续追问
那 shell 是怎么把 标准输入、标准输出、标准错误 给到进程的呢?shell 自身的 标准输入、标准输出、标准错误 又是源自于哪里呢?
shell 的实施原理
回答上面两个问题前,我们先了解以下 shell 的基本实施,请参考 《35 行代码实现一个简单的 shell》
对于问题一,我的理解:
子进程(我们在 shell 中运行的用户程序)是被 shell fork() + execlp() 出来的。在 fork 过程中,子进程获得了和父进程一模一样的资源,其中就包括 标准输入、标准输出、标准错误 。而 execlp 只是替换进程,进程所处的环境没有变,所以 execlp 替换的新进程依然享有被替换的程序所拥有的 标准输入、标准输出、标准错误(经过实验验证了:父进程中关掉标准输出,子进程也找不到标准输出了,但是没找到理论依据)。
对于问题二,我的理解:
shell 进程是被 1 号祖先进程 init 克隆出来的,自然能够从 init 进程获取 标准输入、标准输出、标准错误;而 init 进程又是从 kernel 中获取到它们的。
以下就是我目前的理解框图:
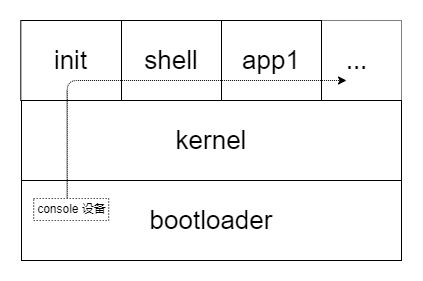
思路清晰度
0.7
欢迎大家讨论并指正