作者
Yoshua Bengio, Patrice Simard, and Paolo Frasconi
以下介绍中,块引用代表评论。
摘要
指出了 RNN 所面临的问题: temporal contingencies present in the input/output sequences span intervals ,也就是所谓的长依赖问题(long-term dependencies)。接下来指出问题的原因是基于梯度的训练方法。这种方法中存在 trade-off bbetween efficient learning by gradient descent and latching on information for long periods 。
基于此提出的解决方法是使用 alternatives to standard gradient descent ,也就是标准梯度下降外的替代品。
即使作为反向传播算法的提出者, Geoffrey Hinton 在 2017 年也对该算法提出了怀疑。不过近期又发了一篇 Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures ,在一些需要特殊网络结构的数据集上比较了生物学启发的多种训练算法,结果发现效果还是 BP 不好。这篇 1994 年的文章讲了 BP 如何不适合解决序列问题中的长依赖。值得一读。
引言
序列任务中需要系统能够存储、更新信息。从过去输入中计算得到的信息,对于输出是很有用的。 RNN 很适合这样的任务,因为其有内部状态(internal state)可以表示这样的上下文信息(context information)。这种特性来自于结构上的“循环”,静态的神经网络,即使引入延迟(Time Delay Neural Networks)也只能将信息储存特定时间长度,而不能储存不定时间长度。
RNN 的训练算法基于损失函数的梯度下降。比如 back-propagation through time (BPTT) 算法。 Forward propagation (FP) 算法计算代价更高,但可以在线学习。另一个训练受限 RNN 的算法中,动态神经元(dynamic neurons,只有向自己的一个反馈)和 FP 一样在时间上只需要本地信息,但权重更新所需计算只正比于权值数(和 BP 一样)。但其对于一般序列的存储能力有限,因此限制了其表示能力。
Long-term dependencies 的定义是在时间 t 的输出依赖于一个更早时间的 。尽管 RNN 的表现超过很多统计网络,但更难训练到最优。局部最优的原因是次优解将短期依赖纳入了考虑,但没有考虑长期依赖。 Mozer [19] 发现反向传播很难发现长时间间隔的随机事件。本文从理论和实验上解释这个问题。
很惭愧只学过 BPTT ,对于另外两个都没有听说过。
一个含参数的动力系统(parametric dynamic system)的三个基本要求如下:
- 能够将信息储存任意时长
- 能够对抗噪声
- 参数可训练(训练时间合理)
定义信息锁存(information latching)为一个动力系统将特定比特的信息在状态变量中的长期存储。使用 hyperbolic attractor 的形式化定义将在 4.1 节给出。
hyperbolic attractor 本身的定义也将在第 4 节给出
文章共 5 节。第 2 节提出一个只有满足上述条件的系统才能解决的最小任务。接下来展示一个 RNN 解法,和一个负实验结果,表明梯度下降连这个简单任务都不适合。第 4 节的理论结果解释了一个系统要么稳定能够抵抗噪音,要么能使用梯度下降法高效训练,但不能同时达到。否则,在时间 t 的状态对于时间 0 的状态的导数将随 t 增大而指数减小。
因此,反向传播(以及一般的梯度下降算法)对于长序列效率低,因此不满足条件 3 。第 5 节提出了新的算法,并将其与反向传播的变体和模拟退火(simulated annealing)进行比较。使用的是输入输出依赖可以控制的简单任务。
第 2 节 说明问题的最小任务
该任务是一个序列二分类问题,最终的类别只取决于前 L 个输入值。
也即类别 。而整个输入序列可以具有任意长度 。
该任务中,长度 L 之后的输入都是不相关的噪声。因此,模型需要有效地储存信息才能解决这个问题。本次实验中, L 之后的输入是均值为 0 的高斯噪声。
上面提到第 3 个标准是可学习性,这里有两个方面:第一,处理前 L 步的输入并正确分类。第二,将信息储存在状态变量中任意时长。在这个任务中,前面的分类和后面储存的时长无关,因此一个简单的解决方法是使用一个锁存子系统(latching subsystem),接收前面分类子系统的信息作为输入。
由于我们希望结果不与特定的分类任务相关(也就是与分类子系统相独立),因此我们只关注后面的锁存系统。一个锁存系统想要处理任意输入序列,就需要能将错误传播回前面的系统,并检测到引发锁存的事件。(propagate error information to a module that feeds the latching subsystem and detects the events leading to latching)
因此,我们将上面的任务修改如下:前 L 个输入可供输入算法调参(can be tuned by the learning algorithm), L 步之后的输入是随机的高斯噪声。目标函数是二分类(期望输出值分别是 ±0.8)的平方误差和。
经过改造后, 代表了类别信息的计算结果。直接学习 比从输入中学习参数 容易。而且如果 是对应时间步的输入 的带参函数的话,也即 ,代价函数对于 的导数是一样的(BPTT 下)。如果因为梯度消失导致 不能被训练出来的话,那作为带参函数同样训练不出来。
研究锁存子系统的方法十分巧妙。锁存子系统想要达到预期的功能,至少要能将分类结果的正误信息传播回分类子系统。也即假设最后是 1 类,至少应该有方法将其通知到分类子系统。而我们观察其能否通知的方式,就是让其在前 L 步输入处还原最终的分类结果。对于原来的任务来说,我们通过训练参数让这个结果最终在 L 步处出现。而训练的依据就是在第 L 步我们接受到了锁存子系统传播回来的正确类别的信息。
举一个例子来说明。假设原来的任务 L = 3 ,接受到一个序列 101001... ,假设标签为第 1 类。分类系统应该在接受到 101 这三个时间步时就已经得出分类标签为 1 这个结论了。接下来,锁存系统将 1 这个结果储存起来,直至第 T 步输出。
然而我们只希望关注锁存子系统。在原任务中,如果最终标签是 1 ,锁存子系统应该能反向传播到第 3 个时间步,告诉分类子系统标签是 1 。因此,假如序列最终的标签是 1 ,我们希望无论前 3 个输入是什么,都能得到这一标签。所以锁存子系统只需要把真实标签传播给前 3 步的分类系统即可。假如没有分类系统,我们就让锁存子系统在前 3 个位置还原最终的标签。
也就是,假设序列的最终标签是 1 (对应目标值 0.8),锁存子系统应该在前 3 步输出 0.8, 0.8, 0.8 ,如果序列最终标签是 0 ,锁存子系统应该在前 3 步输出 -0.8, -0.8, -0.8 。假如我们有真的分类子系统,它应当能在这里拿到真实的标签,并据此将其与输入序列联系起来(通过调整带参函数的参数),比如 101 或者 010 等等。
个人感觉上面的切片测试方法不仅适合测试锁存,应该适合各种具有确定期望功能的子系统。举例来说,假设一个子系统需要进行 (+1) 这个运算,应当有能力对于输出 x 在输入处还原期望的输入 (x-1) ,这样才能通知前面的系统,我需要 (x-1) 。
当然这只是完成锁存或其他功能的必要条件。
关于导数相同一段,这是因为假设 h_t 仅取决于 u_t (而非其他时间步的输入),因此 h_t(u_t, \theta) 是一个 context-free 的函数,根据求导的链式法则,对 h_t 的导数相同,而不论它是变量还是另一个变量的函数。
关于为何选取目标函数值为 0.8 ,因为 tanh 函数值域为 (-1, 1) ,而下一层的输入在 tanh(-1) = -0.76 到 tanh(1) = 0.76 之间。因此多个 tanh 单元叠加值域就在 (-0.8, 0.8) 之间。
第 3 节 一个简单的 RNN 解决方案
见图 Fig. 1a.
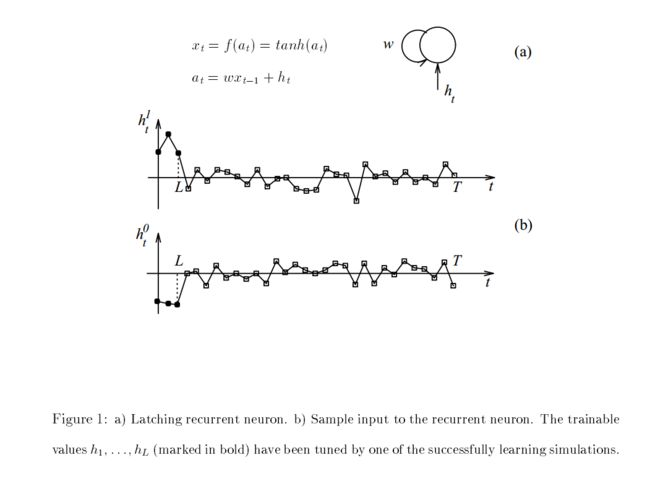
这是一个单一神经元的 RNN ,如果 ,有两个吸引子 ,值取决于 。
假设初值 ,文献 [7, 8] 表明存在 满足:
- maintains its sign if ,也即小于阈值的输入不会改变状态的符号。
- there exists a finite number of steps such that if 。也即假如超过正向阈值的输入持续了超过 步后,会在 步时将状态转到正向吸引子 。
对于初值为正的情况有相应的对称结论。
当 固定, 随着 的增加而减小。
据此我们可以得到:
- 该系统可以储存一个 bit 的信息。通过最终输出的符号确定。
- 存储是通过将足够强(大于 )的输入保持足够长的时间实现的。
- 小的(小于 )噪声不会影响输出的符号。无论持续时间有多长。
参数 也是可训练的,更大的 对应于更大的阈值 ,对抗噪声的能力也就越强。
比如可以通过调整,使得 且 ,其中 来实现。
从上面的 Fig. 1b. 我们可以看到成功学习出来了加粗部分的前 3 个 。
下面看各参数的影响。
首先 Fig. 2a 是噪声的标准差 和初始的权值 的影响。我们可以看到随着 的增大和 的减小,效果变差。
这很符合我们的直觉,噪声越强,对抗噪声的阈值越低,越容易丢失存储。
Fig. 2b 展示了随着 的增加,收敛性变差。这表明,梯度下降即使对于长时间存储 1 位信息也很困难。
第 4 节 使用动力系统学习锁存
本节以基于动力系统的实时识别器为例子,说明 RNN 能够按双曲吸引子(hyperbolic attractors)的方式鲁棒性地储存信息的条件,会导致梯度消失的问题。
非自动(non-autonomous)的离散时间的系统,带有额外的输入:
和自动系统(autonomous system):
其中, 代表系统状态, 代表输入。两者是 维向量, 代表非线性映射。
不带有额外输入的自动系统,可以通过引入额外状态变量和对应输入的方式,转变成非自动的系统。
比如 ( , 分别为 维和 维向量)可以转化为 ,其中 是一个 维向量, 即前 个分量为 0 , 即后 个分量为 0 。
最终, 。
以上转换相当于将本来的内部状态变量当做系统的额外输入。使用映射计算出下面的 n 维状态后,就将剩下的 m 维分量丢弃。再从外界输入同样的 m 维分量,组合在一起恢复内部状态,作为下一次映射的输入。
注意到具有 形式的非自动系统也可以等价转换为自动系统。因此,不失一般性,我们只考虑非自动系统。
下面说明,当使用双曲吸引子进行锁存时,只有两种情况会发生:要么对噪声十分敏感,要么代价函数在 t 时刻对于 0 时刻的导数,将随 t 增加而指数下降。
4.1 分析
为了锁存一位信息,希望将系统的活动 限制在定义域的一个子集 上。这样能区分两个状态:在 内,和不在 内。为了使 保持在其中,动力系统可以将其放在一个吸引子的吸引盆(basin of attraction)中。(吸引子也可以是子流形或子空间的吸引子)。想要“擦除”这一位信息,系统将 从吸引盆中推出,可能放进另一个吸引盆中。本节说明,如果吸引盆是双曲的(hyperbolic),或者可以转化为双曲的(比如周期稳定吸引子 periodic stable attractor),那么对 输入的导数会迅速消失。
定义 1 : 是映射 的不动点,如果
定义 2 : 不动点点集 是可微映射 的双曲吸引子,如果 的特征值的绝对值小于 1 。
吸引子可能包含一个点(固定点吸引子, fixed point attractor),有限个点(周期性吸引子, periodic attractor)或者无限个点(混沌吸引子, chaotic attractor)。
一个稳定的固定点吸引子,对于映射 是双曲的;一个稳定的周期性的吸引子,设其周期为 ,则对于映射 是双曲的。
RNN 的吸引子的种类取决于权值矩阵。对于 ,如果 是对称的,且其最小特征值大于 -1 的话,那么其所有吸引子都是固定点。如果行列式小于 1 或者系统是线性且稳定的,那么只有在原点处有一个固定点吸引子。
以上关于吸引子的知识全没有接触过。翻译了一下。仅从直观上进行理解。
定义 3 : 一个吸引子 的吸引盆 ,指映射 下收敛于 的点集。即
定义 4 : 是双曲吸引子 吸引盆中的 reduced attracting set,如果满足 , 的所有特征值小于 1。
根据定义有, 。
reduced 应该翻译成“剩余”还是“减小”?不太确定。这里只要求特征值小于 1 ,双曲吸引子要求特征绝对值小于 1 ,故双曲吸引子是 Gamma(X) 的子集。直觉上,特征值小于 1 可能对应上面“将其保持在吸引盆”中的要求。
定义 5 : 一个系统可以鲁棒性地在 锁存若干双曲吸引子中的一个吸引子 ,如果 在 对于定义自动系统的映射 的 reduced attracting set 中。
对于非自动动力系统,只需 。接下来证明为什么使用 来储存具有鲁棒性。
定理 1-3 及证明请查阅原文。最终证明了如果在 beta(X) 中,代表不确定性的球体会越来越大,因此输入的微小扰动可能将轨迹引导进入一个错误的吸引盆,即系统无法对抗噪声。相反,如果在 Gamma(X) 中,则能在输入中找到一个界,保证 a_t 一直在 X 中的点的特定距离内。因此是鲁棒的。见 Fig. 3 。

定理 4 : 当输入 使得系统在时间 0 后保持在 上鲁棒时,随着 趋近于无穷, 对 的偏导趋近于 0 。
也就是说对抗噪声的代价是对过去事件的导数与近期事件相比会小很多。
4.2 对权重梯度的影响
因此,相对于较近的事件, 的前两项的乘积较小,因此对最终的结果影响较小。也就是,即使可能存在一个 使得 进入一个更好的吸引盆,但对 的梯度不会反映这种可能性。
举例来说,假设 A , B 两个系统顺次相接完成一项任务。且要求 B 使用 A 在 0 时刻检测到事件的信息,在遥远的 T 时刻使用该信息计算错误。(第 2 节定义的任务符合这个特征)。如果 B 训练不足,不能将 A 的结果锁存,那么 T 时刻的错误对 A 在 0 时刻产生的结果影响非常小。相反,如果 B 能够将信息储存很长时间,正确的梯度会被传播回去,但却迅速消失成为小值。因此, A 很难训练。
第 5 节 替代的方法
本节中给出了模拟退火等算法作为梯度下降的替代算法并在多个任务上测试了结果。每个任务上都有算法比反向传播更佳。
第 6 节 结论
一个未进行讨论的点是类似的问题是否会在混沌吸引子中出现。
这个问题可能也会在深度前馈神经网络(feedforward network)中出现,因为 RNN 按时间展开就是一个共享权值的前馈神经网络。
本文研究并不意味着不能为特定任务训练神经网络,相反,如果有先验知识可以设置神经网络的权值共享和初值,利用起来会提升效果。比如在 latch problem 和 parity problem 中,先使用短序列进行训练可以让系统迅速进入正确的区域。