1.本地模式-local[k]
本地使用k个worker线程运行saprk程序.这种模式适合小批量数据在本地调试代码用.(若使用本地的文件,需要在前面加上:file://)
2.集群模式
- 基于spark集群的standalone模式
spark-submit
--master spark://master:7077
--class --class org.apache.spark.examples.SparkPi
--executor-memory 1g
--total-executor-cores 4
/path/to/examples.jar
- yarn-client模式: 以client模式连接到yarn集群,该方式driver是在client上运行的;
./bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master yarn
--deploy-mode client
--executor-memory 2g
--num-executors 5
/path/to/examples.jar
- yarn-cluster模式:以cluster模式连接到yarn集群,该方式driver运行在worker节点上.
./bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master yarn
--deploy-mode cluster
--driver-memory 4g
--executor-memory 2g
--executor-cores 1
--queue
lib/spark-examples*.jar
对于应用场景来说,Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。
3.yarn-client模式和yarn-cluster模式的区别
yarn的运行流程
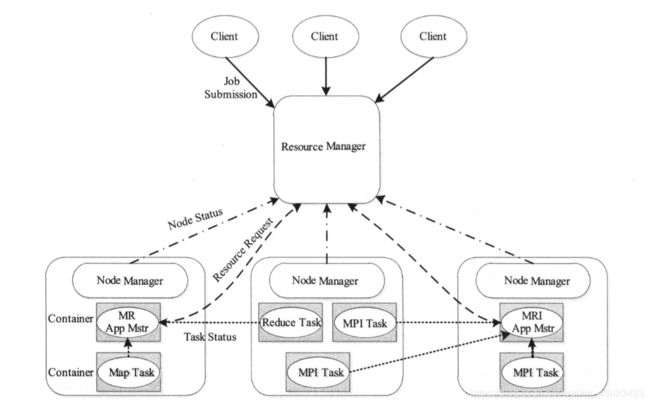
- 用户向 YARN 中提交应用程序,其中包括 MRAppMaster 程序,启动 MRAppMaster 的命令,用户程序等。
- ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求它在这个 Container 中启动应用程序 MRAppMaster。
- MRAppMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结束,重复 4 到 7 的步骤。
- MRAppMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
- 一旦 MRAppMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务。
- NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个 RPC 协议向 MRAppMaster 汇报自己的状态和进度,以让 MRAppMaster随时掌握各个任务的运行状态,从而可以在任务败的时候重新启动任务。
- 应用程序运行完成后,MRAppMaster 向 ResourceManager 注销并关闭自己。
AppMaster和Driver
上面了解了appmaster在yarn运行流程中的角色,再区分下AppMaster和Driver,任何一个yarn上运行的任务都必须有一个AppMaster,而任何一个Spark任务都会有一个Driver,Driver就是运行SparkContext(它会构建TaskScheduler和DAGScheduler)的进程,当然在Driver上你也可以做很多非Spark的事情,这些事情只会在Driver上面执行,而由SparkContext上牵引出来的代码则会由DAGScheduler分析,并形成Job和Stage交由TaskScheduler,再由TaskScheduler交由各Executor分布式执行。
所以Driver和AppMaster是两个完全不同的东西,Driver是控制Spark计算和任务资源的,而AppMaster是控制yarn app运行和任务资源的,只不过在Spark on Yarn上,这两者就出现了交叉,而在standalone模式下,资源则由Driver管理。在Spark on Yarn上,Driver会和AppMaster通信,资源的申请由AppMaster来完成,而任务的调度和执行则由Driver完成,Driver会通过与AppMaster通信来让Executor的执行具体的任务。
client与cluster的区别
对于yarn-client和yarn-cluster的唯一区别在于,yarn-client的Driver运行在本地,而AppMaster运行在yarn的一个节点上,他们之间进行远程通信,AppMaster只负责资源申请和释放(当然还有DelegationToken的刷新),然后等待Driver的完成;而yarn-cluster的Driver则运行在AppMaster所在的container里,Driver和AppMaster是同一个进程的两个不同线程,它们之间也会进行通信,AppMaster同样等待Driver的完成,从而释放资源。
Spark里AppMaster的实现:org.apache.spark.deploy.yarn.ApplicationMaster
Yarn里MapReduce的AppMaster实现:org.apache.hadoop.mapreduce.v2.app.MRAppMaster
yarn-client模式
优先运行的是Driver(我们写的应用代码就是入口),然后在初始化SparkContext的时候,会作为client端向yarn申请AppMaster资源,当AppMaster运行后,它会向yarn注册自己并申请Executor资源,之后由本地Driver与其通信控制任务运行,而AppMaster则时刻监控Driver的运行情况,如果Driver完成或意外退出,AppMaster会释放资源并注销自己。所以在该模式下,如果运行spark-submit的程序退出了,整个任务也就退出了。
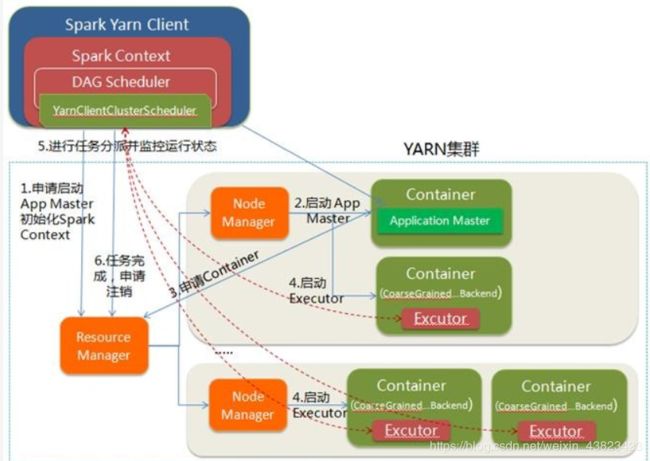
在yarn-cluster模式里
本地进程则仅仅只是一个client,它会优先向yarn申请AppMaster资源运行AppMaster,在运行AppMaster的时候通过反射启动Driver(我们的应用代码),在SparkContext初始化成功后,再向yarn注册自己并申请Executor资源,此时Driver与AppMaster运行在同一个container里,是两个不同的线程,当Driver运行完毕,AppMaster会释放资源并注销自己。所以在该模式下,本地进程仅仅是一个client,如果结束了该进程,整个Spark任务也不会退出,因为Driver是在远程运行的

4.spark-submit参数说明
--master
MASTER_URL, 可 以 是 spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local
--deploy-mode
DEPLOY_MODE, Driver 程序运行的地方,client 或者 cluster,默认是client。
--class
CLASS_NAME, 主类名称,含包名
--jars
逗号分隔的本地 JARS, Driver 和 executor 依赖的第三方 jar 包
--driver-class-path
驱动依赖的jar包
--files
用逗号隔开的文件列表,会放置在每个 executor 工作目录中
--conf
spark 的配置属性
例如:
spark.executor.userClassPathFirst=true
实验性)当在executor中加载类时,是否用户添加的jar比Spark自己的jar优先级高。这个属性可以降低Spark依赖和用户依赖的冲突。它现在还是一个实验性的特征。
spark.driver.userClassPathFirst=true
实验性)当在driver中加载类时,是否用户添加的jar比Spark自己的jar, 优先级高。这个属性可以降低Spark依赖和用户依赖的冲突。它现在还是一个实验性的特征。
--driver-memory
Driver 程序使用内存大小(例如:1000M,5G),默认 1024M
--executor-memory
每个 executor 内存大小(如:1000M,2G),默认 1G
仅限于Spark on Yarn模式
--driver-cores
driver 使用的 core,仅在 cluster 模式下,默认为 1。
--queue
QUEUE_NAME 指定资源队列的名称,默认:default
--num-executors
一共启动的 executor 数量,默认是 2 个。
--executor-cores
每个executor使用的内核数,默认为1。
几个重要的参数说明:
executor_cores*num_executors
表示的是能够并行执行Task的数目不宜太小或太大!一般不超过总队列 cores 的 25%,比如队列总 cores 400,最大不要超过100,最小不建议低于40,除非日志量很小。
executor_cores
不宜为1!否则 work 进程中线程数过少,一般 2~4 为宜。
executor_memory
一般 6~10g 为宜,最大不超过20G,否则会导致GC代价过高,或资源浪费严重。
driver-memory
driver 不做任何计算和存储,只是下发任务与yarn资源管理器和task交互,除非你是 spark-shell,否则一般 1-2g
增加每个executor的内存量,增加了内存量以后,对性能的提升,有三点:
- 如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,
甚至不写入磁盘。减少了磁盘IO。 - 对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。
如果给executor分配更多内存以后,就有更少的数据,需要写入磁盘,甚至不需要写入磁盘。减少了磁盘IO,提升了性能。 - 对于task的执行,可能会创建很多对象.如果内存比较小,可能会频繁导致JVM堆内存满了,然后频繁GC,垃圾回收 ,minor GC和full GC.(速度很慢).内存加大以后,带来更少的GC,垃圾回收,避免了速度变慢,性能提升。
spark提交参数的设置非常的重要,如果设置的不合理,会影响性能,所以大家要根据具体的情况适当的调整参数的配置有助于提高程序执行的性能。