(SOTA in ICCV 2019) ABD-Net: Attentive but Diverse Person Re-Identification
https://arxiv.org/pdf/1908.01114.pdf
论文关键词:注意力attention,正交正则化Orthogonality regularization
关于weight间correlation与正交正则化的相关知识,请参考:https://www.jianshu.com/p/3a9660e2dfbc
个人总结:本文提出了一种attention网络,网络同时用到了channel wise attention与spatial wise attention,但是这样高度attention的特征会造成correlation过高,retrieve阶效果不好,因此加入了正交正则化来让attention变得diverse。最终在多个数据集包括MSMT达到了sota效果。
但是本文模型结构可能偏复杂,计算attention步骤计算量大,且特征为两路特征拼接而成,输出特征维度过大(2048),可能在最终计算效率上存在缺陷。
前言
由于一些遮挡、身体不完全的情况存在,attention机制被采用进来,去使得特征主要捕捉人体的外表信息。
一个更理想的模型是要同时保证attentive和diverse:
1、attentive的目的是纠正不对齐的现象,减小背景的特征占比,增大前景的比重
2、diverse的目的是feature间的correlation更加diverse,使得检索环节效率更高,特征空间表达更详细,因为模型过分关注前景后,由于训练样本不均衡导致feature与网络weight间高correlation会更加严重,进而限制了特征的表达。
Attention部分的做法
1、channel wise attention module
Attention机制的目的是,关注行人的前景特征,去除无关背景。
作为一种共识,深层CNN提取的特征是含有语义信息的,在reID任务中,我们假设人体的深层特征也是存在共通性的,比如一些channel共享相似的语义信息(比如前景人体、遮挡物、背景等),因此这部分的目的是聚集这部分语义相似的channel。
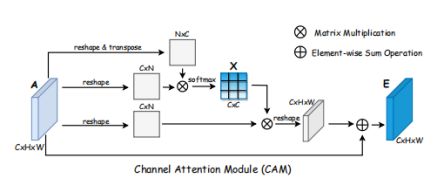
A=C x H x W代表特征图,C是这个特征图的通道数,计算各通道间的相似性矩阵X如下
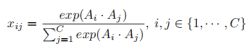
这个xij代表channel i 对channel j的影响程度,最终得到输出的特征图为

其中γ是一个超参数,调整channel wise attention 的影响程度。
2、position attention module
虽然本文用的是position,但理解上和传统说的spatial attention 应该是同个意思,只是改了个说法。这个模块被设计来聚集语义上相近的像素。

输入的特征图首先放入卷积层,卷积层带有BN操作与ReLU激活,然后计算像素相似矩阵S,最终得到输出特征E,计算流程与channel attention module 类似。
Diversity模块:正交正则化
正交正则化使得模型学到信息更丰富与diverse更高的feature。一些研究使用了hard orthogonality约束,使用SVD分解,去严格约束解在stiefel 流型(通过坐标原点的所有n维平面集合,可看做商空间),但是对高维特征进行svd分解开销过大,目前有一些soft orthogonality的方法,能保证正则化后相乘回来的gram 矩阵的二范数几乎不变.
*知识补充:
1、奇异矩阵:若A找不到一个矩阵B,是的AB=BA=I,那么A是奇异的,反之为非奇异矩阵;奇异矩阵的特点为行列式等于0;(singular,找不对配对的相乘为I的矩阵,所以也可以理解为单身矩阵)
2、矩阵条件数:表征矩阵的奇异程度。
本文提出一种新方法,直接正则化FFT的条件数
网络结构总览

本文增加了一层CAM和OF(特征正交正则化)在 res_conv_2 block上,正则化后的特征作为block 3的输入,block4以后,block5的网络分为了平行的两条全局分支与注意力分支,最终两个分支的特征concate起来就是最终feature。所有的卷积层都使用了OW(权重正交正则化)
注意力分支使用的卷积结构与resnet50的block5完全一致,输出特征图进入缩小层(reduction layer)。注意力分支的特征同时进入CAM和PAM,两个注意力分支输出的特征
element wise加和,最终和输入特征拼接起来。
global分支经过block5之后,先进行一次global pooling后再进行一次reduction layer.
最终训练用的loss为:
reduction layer:由线性层、BN层、RELU、dropout构成,具体结构需要参考:
https://github.com/KaiyangZhou/deep-person-reid
训练细节与具体实现:
输入图片resize成384X128,使用了随机水平翻转、随机擦除、像素归一化等argumentation操作。测试集仅用normalization.注意力分支的特征图为1024x24x8,全局分支特征图为2048x24x8,最终拼接global pooling得到的特征为2048。
Back bone 为resnet50,使用two-step方法transfer learning去finetune模型:first step.先冻结backbone 权重,只训练reduction layer,分类器和所有attention 模块共10个epoch,期间只用cross entropy和triplet。Second step.所有层开始训练60个epoch,所有loss都运行,参数选择βtr = 10−1 , βOF = 10−6 ,βOW = 10−3 , margin for triplet loss α = 1.2.
优化器为adam,使用了warmup。(本文的baseline基本全部用到了之前的strong baseline)。
评测指标:mAP,RANK-1。
实验结果:
实验结果在三个数据集上测评market,Duke,MSMT,对比用baseline为resnet50+softmax,一共设计了9组实验,以判别PAM,CAM, O.W. , O.F.等各trick的作用。

实验结果如下:
1、PAM和CAM在两个数据集上都提升了baseline,同时使用两种attention,使得结果有了进一步提升
2、OF,OW也都能提升效果,一起使用能更进一步提升效果,因此本文提出的正交正则化是证明有效的。另外也hard svd作了对比,发现这种基于OW的soft svd效果反而更好。
3、组合attention和diversity,指标又有了进一步的提升,如果在Loss加入triplet,那么还能进一步提升。
特征图可视化
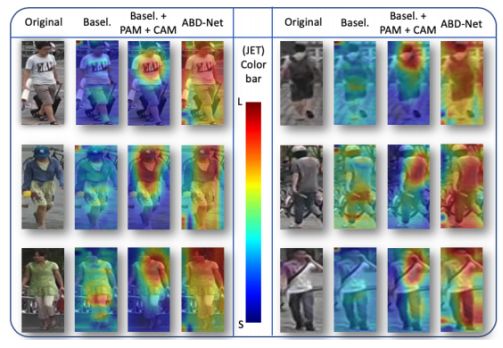
可以看到CAM使得网络更加关注与人体上的特征,防止过拟合到与人体无关的噪音上,但是过于集中的特征会使得特征表示上更加相关,加入了OW后发现特征确实变得diverse了:处理后的特征达到了更好的平衡,即关注了更多人体部分的特征,同时也很好的把人从背景分割出来。
Feature correlation
本文还对比了不同方法下channel输出的特征的correlation matrix。特征为global pooling 前,reshape成CXN,其中N=HXW,发现baseline网络的特征关联最低=0.049,加入了PAM和CAM后,关联度变高=0.368,而在加入了OW正则化后,这个关联度确实被抑制了=0.214;(这个correlation指的是什么?)
观察feature的embedding分布,发现加了attention后,特征分布变散了,加了ow后又聚了回来
