-
Adjacency Matrix Aggregation
作用:根据你写出的条件会依次去匹配搜索,如下图:
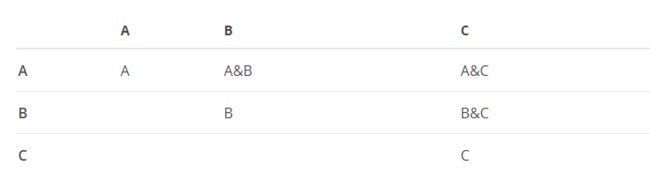 image.png
image.png
{ "index" : { "_id" : 1 } }
{ "accounts" : ["hillary", "sidney"]}
{ "index" : { "_id" : 2 } }
{ "accounts" : ["hillary", "donald"]}
{ "index" : { "_id" : 3 } }
{ "accounts" : ["vladimir", "donald"]}
GET emails/_search
{
"size": 0,
"aggs" : {
"interactions" : {
"adjacency_matrix" : {
"filters" : {
"grpA" : { "terms" : { "accounts" : ["hillary", "sidney"] }},
"grpB" : { "terms" : { "accounts" : ["donald", "mitt"] }},
"grpC" : { "terms" : { "accounts" : ["vladimir", "nigel"] }}
}
}
}
}
}
#结果
{
"took": 9,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"interactions": {
"buckets": [
{
"key":"grpA",#至少符合A条件中的一个
"doc_count": 2
},
{
"key":"grpA&grpB", #至少符合A条件中的一个和至少符合B条件中的一个
"doc_count": 1
},
{
"key":"grpB",
"doc_count": 2
},
{
"key":"grpB&grpC",
"doc_count": 1
},
{
"key":"grpC",
"doc_count": 1
}
]
}
}
}
- Auto-interval Date Histogram (6.3没有)
作用:根据你指定的日期格式输出日期或将日期格式的时间转为时间戳
{
"aggs" : {
"sales_over_time" : {
"auto_date_histogram" : {
"field" : "date",
"buckets" : 5,
"format" : "yyyy-MM-dd"
}
}
}
}
- Children Aggregation
作用: 根据父子索引,并且要满足各自条件搜索
#数据
父:{ "name": "London Westminster", "city": "London", "country": "UK" }
子:{
"name": "Alice Smith",
"dob": "1970-10-24",
"hobby": "hiking"
}
#搜索
{
"size" : 0,
"aggs": {
"country": {
"terms": {
"field": "country" //以不同的 country 来分组(桶分)
},
"aggs": {
"employees": {
"children": { //children aggregation,子 type 为 employee
"type": "employee"
},
"aggs": {
"hobby": {
"terms": {
"field": "hobby" //以不同的 hobby 来分组(桶分)
}
}
}
}
}
}
}
}
#结果
"aggregations": {
"country": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ //country 聚合结果
{
"key": "uk",
"doc_count": 2,
"employees": { //children aggregation 聚合
"doc_count": 1,
"hobby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ //hobby 聚合结果
{
"key": "hiking",
"doc_count": 1
}
]
}
}
}
]
}
}
- Composite Aggregation
作用:算出给与的字段的可能性,然后在去重,如A(3条文档),B(2条文档),C字段(1条文档),就会有321种可能
GET tutuapp_android_view_log_2019.05.26/_search
{
"size":0,
"query": {
"term": {
"entity_id": {
"value": "3061402"
}
}
},
"aggs":{
"123":
{
"composite": {
"sources": [
{"version_code": {
"terms": {
"field": "version_code"
}
}},
{"allneed_lang":{
"terms": {
"field": "allneed_lang"
}
}}
]
}
}
}
}
- Date Histogram Aggregation
作用:根据给定时间间隔,分类时间,并显示该时间段的数据个数
GET tutuapp_android_view_log_2019.05.26/_search
{
"size":0,
"query": {
"term": {
"entity_id": {
"value": "3061402"
}
}
},
"aggs":{
"123":
{
"date_histogram": {
"field": "dateTime",
"interval": "hour"
}
}
}
}
}
- Date Range Aggregation
作用:指定时间返回搜索数据
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"format": "MM-yyyy",
"ranges": [
{ "to": "now-10M/M" }, #小于现在减去十个月的文档
{ "from": "now-10M/M" } #大于等于现在减去十个月的文档
]
}
}
}
}
- Filter Aggregation
作用:根据条件过滤,有terms,range等方法
GET tutuapp_android_view_log_2019.05.26/_search
{
"query": {
"term": {
"entity_id": {
"value": "3061402"
}
}
},
"aggs": {
"123": {
"filter": {
"range": {
"version_code": {
"gte": 2019012903,
"lte": 2019012905
}
}
}
}
}
}
- Filters Aggregation
作用:可定义多个过滤规则
GET tutuapp_android_view_log_2019.05.26/_search
{
"query": {
"term": {
"entity_id": {
"value": "3061402"
}
}
},
"aggs": {
"123": {
"filters": {
"other_bucket_key": "other", #过滤掉的数据
"filters": {
"123": {
"term": {
"version_code": 2019012903
}
}
}
}
}
}
}
- Global Aggregation
作用: 无视某些过滤,计算全体
{
"query" : {
"match" : { "type" : "t-shirt" }
},
"aggs" : {
"all_products" : {
"global" : {},
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
},
"t_shirts": { "avg" : { "field" : "price" } }
}
}
#返回
{
...
"aggregations" : {
"all_products" : {
"doc_count" : 7,
"avg_price" : {
"value" : 140.71428571428572
}
},
"t_shirts": {
"value" : 128.33333333333334
}
}
}
- Histogram Aggregation
作用:根据所给间隔,分类字段
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50
}
}
}
}
#返回
{
...
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0.0,
"doc_count": 1
},
{
"key": 50.0,
"doc_count": 1
},
{
"key": 100.0,
"doc_count": 0
},
{
"key": 150.0,
"doc_count": 2
},
{
"key": 200.0,
"doc_count": 3
}
]
}
}
}
- IP Range Aggregation
作用:搜索指定范围内的ip数量
{
"size": 10,
"aggs" : {
"ip_ranges" : {
"ip_range" : {
"field" : "ip",
"ranges" : [
{ "to" : "10.0.0.5" },小于
{ "from" : "10.0.0.5" }大于
]
}
}
}
}
- Missing Aggregation
作用:统计该数据中遗失某字段的数据总数
GET tutuapp_android_view_log_2019.05.26/_search
{
"query": {
"term": {
"entity_id": {
"value": "3061402"
}
}
},
"aggs": {
"123": {
"missing": {
"field": "version_code"
}
}
}
}
- Nested Aggregation
作用:用于嵌套聚合
# 定义索引时需要指定nested类型
{
"mappings": {
"properties" : {
"resellers" : {
"type" : "nested",
"properties" : {
"name" : { "type" : "text" },
"price" : { "type" : "double" }
}
}
}
}
}
#搜索
{
"query" : {
"match" : { "name" : "led tv" }
},
"aggs" : {
"resellers" : {
"nested" : {
"path" : "resellers"#指定到嵌套的文档
},
"aggs" : {
"min_price" : { "min" : { "field" : "resellers.price" } }
}
}
}
}
- Range Aggregation
作用:指定范围返回数据个数
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100.0 },
{ "from" : 100.0, "to" : 200.0 },
{ "from" : 200.0 }
]
}
}
}
}
#返回
{
...
"aggregations": {
"price_ranges" : {
"buckets": [
{
"key": "*-100.0",
"to": 100.0,
"doc_count": 2
},
{
"key": "100.0-200.0",
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3
}
]
}
}
}
Sampler Aggregation
作用:采样器聚合Significant Terms Aggregation
作用:对该集合中A字段的某分类中的数据中的B字段分类,算出A字段某分类中的B字段的分类在全部数据中出现的概率
#查询
{
"query" : { // @1
"terms" : {"force" : "上海交通警局"
},
"aggregations" : {
"significant_crime_types" : {
"significant_terms" : { "field" : "crime_type" } // @2
}
}
}
代码@1:定义一个查询,该例中查询警局为“ShangHai Transport Police”所有犯罪记录,当成我们关注(感兴趣的集合,也就是Significant Terms Aggregation中的(foreground set)。
代码@2:对crime_type犯罪类型进行significant_terms.
#返回
{
...
"aggregations" : {
"significant_crime_types" : {
"doc_count": 47347, // @1
"bg_count": 5064554, // @2
"buckets" : [ // @3
{
"key": "自行车盗窃案",
"doc_count": 3640, // @4
"score": 0.371235374214817,
"bg_count": 66799 // @5
}
,
{
"key": "小汽车盗窃案",
"doc_count": 6640,
"score": 0.371235374214815,
"bg_count": 66799
}
...
]
}
}
}
代码@1:doc_count:符合查询条件的总文档数量,此例表示上海交通警局总共的犯罪记录数。
代码@2:bg_count:这是Significant Terms中的background set,应该是该索引当前总共的文档个数。
代码@3:是significant_terms针对犯罪类型的聚合结果。
代码@4:表示上海交通警局总共发生的自行车盗窃案的总记录数。
代码@5:表示整个索引库中所有警局发生的自行车盗窃案的总记录数。
- Significant Text Aggregation
作用:指定A字段的某个词汇,返回跟该字段相关性很高的B字段的词汇的数据
{
"query" : {
"match" : {"content" : "Bird flu"}
},
"aggregations" : {
"my_sample" : {
"sampler" : {
"shard_size" : 100
},
"aggregations": {
"keywords" : {
"significant_text" : { "field" : "content" }
}
}
}
}
}
#返回
{
"took": 9,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations" : {
"my_sample": {
"doc_count": 100,
"keywords" : {
"doc_count": 100,
"buckets" : [
{
"key": "h5n1",
"doc_count": 4,
"score": 4.71235374214817,
"bg_count": 5
}
...
]
}
}
}
}
- Terms Aggregation
作用:对字段的值进行分类,别算出每个分类的个数