机器学习实战篇 (k近邻算法)
k近邻算法:通过测量不同特征值之间的距离进行分类
优点:精度高,对异常值不敏感,无数据输入假定。
缺点:计算复杂度高,空间复杂度高。
计算公式

分类器的代码实现
import numpy as np
from collections import Counter
def classify0(inx, dataset, labels, k=1):
##预处理(此处的输入labels是带有具体分类内容的list),inx和dataset都numpy对象
if k <= 0:
k = 1
try:
y = inx.shape[1]
except:
inx.shape=(-1, inx.shape[0])
##计算欧氏距离
num_test = inx.shape[0]
num_train = dataset.shape[0]
dists = np.zeros((num_test, num_train))
dists = np.multiply(np.dot(inx, dataset.T), -2)
inx_sq = np.sum(np.square(inx), axis=1, keepdims=True)
dataset_sq = np.sum(np.square(dataset), axis=1)
dists = np.add(dists, inx_sq)
dists = np.add(dists, dataset_sq)
dists = np.sqrt(dists)
###获取标签
result = []
per_line_labels=[]
sort_arg = dists.argsort()[:,:k]
for line in sort_arg:
per_line_labels = [labels[index] for index in line]
result.append(Counter(per_line_labels).most_common(1)[0][0])
return result
实例1 利用K-近邻算法改进约会网站的配对效果
数据集下载 http://pan.baidu.com/s/1geMv2mf
1.从文件中读取数据转化为可计算的numpy对象
def file1matrix(filename):
###从文件中读取数据并转为可计算的numpy对象
dataset = []
labels = []
with open(filename,'r') as f:
for line in f:
line = line.strip().split('\t')
labels.append(line.pop())
dataset.append(line)
dataset = np.array(dataset, dtype=np.float32)
return dataset, labels
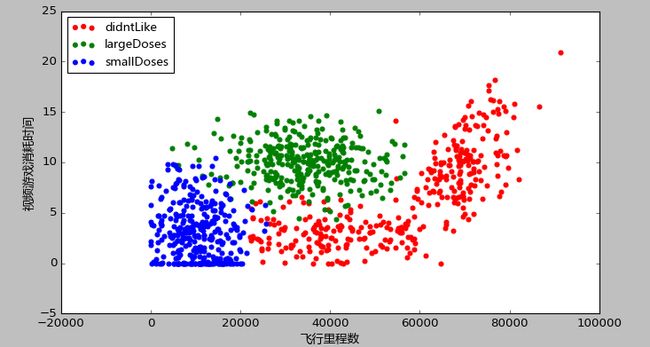
2.将数据可视化
def convert(labels):
label_names = list(set(labels))
labels = [label_names.index(label) for label in labels]
return label_names,labels
def draw(dataset, labels, label_names):
labels = [ i+1 for i in labels] ###下标加1,绘色
from matplotlib import pyplot as plt
from matplotlib import font_manager
zhfont = font_manager.FontProperties(fname='C:\\Windows\\Fonts\\msyh.ttc')
plt.figure(figsize=(8, 5), dpi=80)
ax = plt.subplot(111)
# ax.scatter(dataset[:,1], dataset[:,2], 15.0*np.array(labels), 15.0*np.array(labels))
# plt.show()
type1_x = []
type1_y = []
type2_x = []
type2_y = []
type3_x = []
type3_y = []
for i in xrange(len(labels)):
if labels[i] == 1:
type1_x.append(dataset[i][0])
type1_y.append(dataset[i][1])
if labels[i] == 2:
type2_x.append(dataset[i][0])
type2_y.append(dataset[i][1])
if labels[i] == 3:
type3_x.append(dataset[i][0])
type3_y.append(dataset[i][1])
ax.scatter(type1_x, type1_y, color = 'red', s = 20)
ax.scatter(type2_x, type2_y, color = 'green', s = 20)
ax.scatter(type3_x, type3_y, color = 'blue', s = 20)
plt.xlabel(u'飞行里程数', fontproperties=zhfont)
plt.ylabel(u'视频游戏消耗时间', fontproperties=zhfont)
ax.legend((label_names[0], label_names[1], label_names[2]), loc=2, prop=zhfont)
plt.show()
3.归一化特征值 (这里介绍两种方法)
####由于数据中飞行里程数特征值与其他的特征值差距较大,对计算结果会产生非常大的影响,所以将特征值转化为0到1区间内的值
def autoNorm0(dataset):
if not isinstance(dataset, np.ndarray):
dataset = np.array(dataset,dtype=np.float32)
###归一化特征值 newvalue = (oldvalue - min) / (max - min)
minVals = dataset.min(0)
maxVals = dataset.max(0)
ranges = maxVals - minVals
dataset = dataset - minVals
dataset = dataset / ranges
return dataset
def autoNorm1(dataset):
###归一化特征值 newvalue = (oldvalue - 均值) / 标准差 ----->推荐使用这种方法
if not isinstance(dataset, np.ndarray):
dataset = np.array(dataset,dtype=np.float32)
mean = dataset.mean(0)
std = dataset.std(0)
dataset = dataset - mean
dataset = dataset / std
return dataset
4.编写测试代码
def datingTest():
##随机选取测试集和训练集
filename = 'datingTestSet.txt'
dataset, labels = file1matrix(filename)
dataset = autoNorm1(dataset)
train_length = int(dataset.shape[0] * 0.9)
test_length = dataset.shape[0] - train_length
from random import sample
all_index = sample(range(dataset.shape[0]), dataset.shape[0])
train_index = all_index[:train_length]
test_index = all_index[-test_length:]
train_dataset = dataset[train_index, :]
train_labels = []
test_dataset = dataset[test_index, :]
test_labels = []
for index in train_index:
train_labels.append(labels[index])
for index in test_index:
test_labels.append(labels[index])
##训练并计算错误率
test_result = classify0(test_dataset, train_dataset, train_labels, k=3)
error = 0
for res in zip(test_result, test_labels):
if res[0] != res[1]:
error += 1
print 'error accaury:%f' % (float(error) / len(test_labels))
实例2 识别手写数字
1.读取文件数据并转化为可计算的numpy对象
import os
def imgVector(filename):
vect = []
with open(filename,'r') as f:
for line in f:
line = line.strip()
vect += [float(n) for n in line]
number = os.path.split(filename)[-1].split('_')[0]
return np.array(vect, dtype=np.float32), number
def all_imgVector(directory):
filelist = os.listdir(directory)
vects = []
labels = []
for filename in filelist:
vect, label= imgVector(os.path.join(directory, filename))
vects.append(vect)
labels.append(label)
return np.array(vects, dtype=np.float32), labels
2.编写测试代码
def handwritingClassTest():
test_dir = 'digits\\testDigits'
train_dir = 'digits\\trainingDigits'
train_dataset, train_labels = all_imgVector(train_dir)
test_dataset, test_labels = all_imgVector(test_dir)
result_labels = classify0(test_dataset, train_dataset, train_labels, k=3)
error = 0
for res in zip(result_labels, test_labels):
if res[0] != res[1]:
error += 1
print 'error accaury:%f' % (float(error) / len(test_labels))