Python基础入门自学——10
使用@property
在绑定属性时,如果直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改:
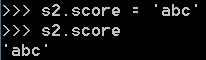
这显然不合逻辑。为了限制score的范围,可以通过一个set_score()方法来设置成绩,再通过一个get_score()来获取成绩,这样,在set_score()方法里,就可以检查参数:
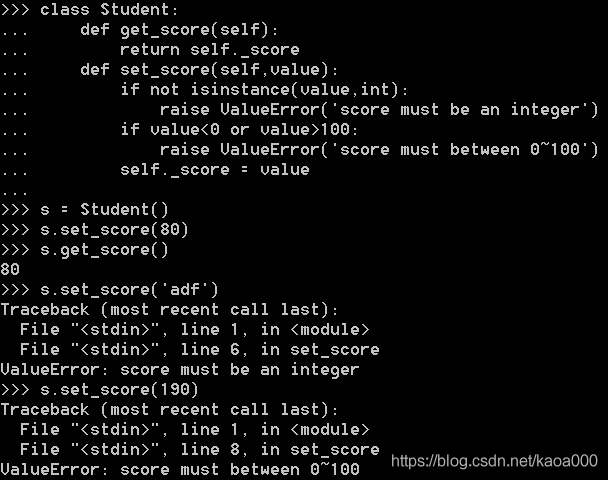
上面的调用方法又略显复杂,没有直接用属性这么直接简单,Python内置的@property装饰器就是负责把一个方法变成属性调用的:

@property的实现比较复杂。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,就拥有一个可控的属性操作:
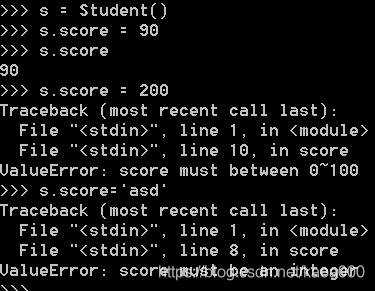
s.score = 90 实际转化为s.set_score(60)
s.score 实际转化为s.get_score()
有了@property,在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的。
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:

birth是可读写属性,而age就是一个只读属性。
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
这个有点像Java的get()和set()方法。
Python实现子类调用父类方法
这里是说在类定义里调用,而不是指实例的调用。
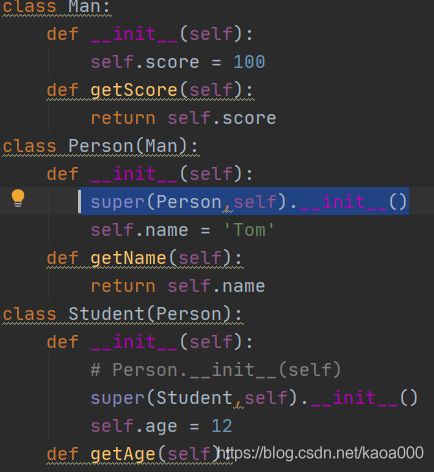
假设存在类Person与类Student:
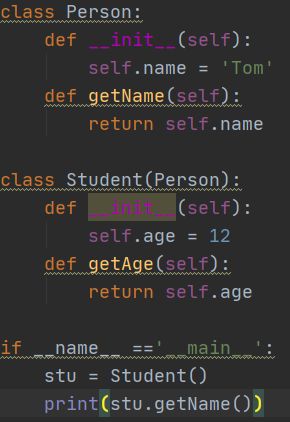

这是因为尽管Student类继承了Person类,但是并没有调用父类的__init__()方法,那么怎样调用父类的方法呢?有如下两种解决方案:
方法一:调用未绑定的父类构造方法:
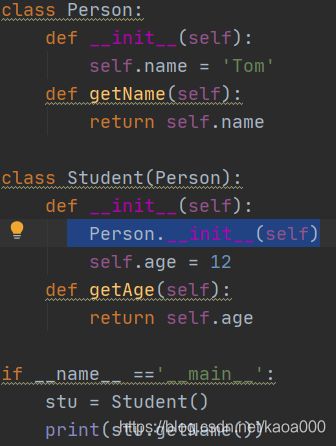
在调用一个实例的方法时,该方法的self参数会被自动绑定到实例上,称为绑定方法;如果调用类的方法(比如Person.__init__()),那么就没有实例会被绑定。这样就可以自由的提供需要的self参数,这种方法称为未绑定方法。
方法二:使用super函数:
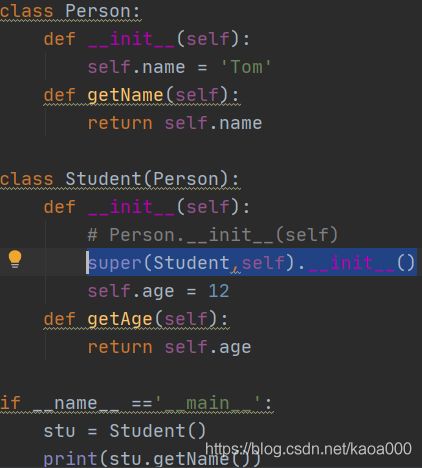
super函数会返回一个super对象,这个对象负责进行方法解析,解析过程其会自动查找所有的父类以及父类的父类。
方法一更直观;
方法二可以一次初始化所有超类.

运行错误
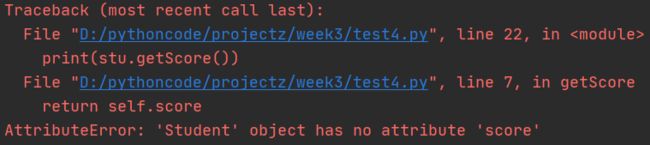
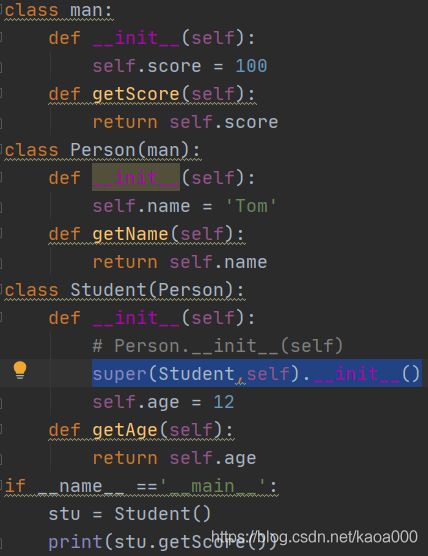
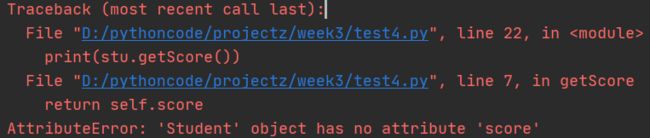
还是出现错误了
这种多级继承的类,中间级的类也需要使用super()函数进行解析。super()在多重继承类中使用效果比较好。 234567890
多重继承
Python 支持一种多重继承。 带有多个基类的类定义语句如下所示:
class DerivedClassName(Base1, Base2, Base3):
...
对于多数应用来说,在最简单的情况下,你可以认为搜索从父类所继承属性的操作是深度优先、从左至右的,当层次结构中存在重叠时不会在同一个类中搜索两次。 因此,如果某一属性在 DerivedClassName 中未找到,则会到 Base1 中搜索它,然后(递归地)到 Base1 的基类中搜索,如果在那里未找到,再到 Base2 中搜索,依此类推。
真实情况比这个更复杂一些;方法解析顺序会动态改变以支持对 super() 的协同调用。 这种方式在某些其他多重继承型语言中被称为后续方法调用。
动态改变顺序是有必要的,因为所有多重继承的情况都会显示出一个或更多的菱形关联(即至少有一个父类可通过多条路径被最底层类所访问)。 例如,所有类都是继承自 object,因此任何多重继承的情况都提供了一条以上的路径可以通向 object。 为了确保基类不会被访问一次以上,动态算法会用一种特殊方式将搜索顺序线性化, 保留每个类所指定的从左至右的顺序,只调用每个父类一次,并且保持单调(即一个类可以被子类化而不影响其父类的优先顺序)。 总而言之,这些特性使得设计具有多重继承的可靠且可扩展的类成为可能。
Animal类层次的设计,假设要实现以下4种动物:
Dog - 狗狗;
Bat - 蝙蝠;
Parrot - 鹦鹉;
Ostrich - 鸵鸟。
按照哺乳动物和鸟类归类,分为Mammal和Bird,按能跑和能飞,分为Runnable和Flayable。

要给动物再加上Runnable和Flyable的功能,只需要先定义好Runnable和Flyable的类:
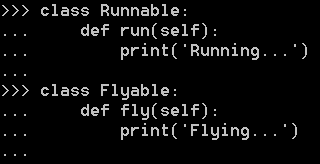
对于需要Runnable功能的动物,就多继承一个Runnable,对于需要Flyable功能的动物,就多继承一个Flyable:
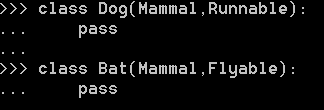
通过多重继承,一个子类就可以同时获得多个父类的所有功能。
MixIn
在设计类的继承关系时,通常,主线都是单一继承下来的,例如,Ostrich继承自Bird。但是,如果需要“混入”额外的功能,通过多重继承就可以实现,比如,让Ostrich除了继承自Bird外,再同时继承Runnable。这种设计通常称之为MixIn。
为了更好地看出继承关系,把Runnable和Flyable改为RunnableMixIn和FlyableMixIn。类似的,还可以定义出肉食动物CarnivorousMixIn和植食动物HerbivoresMixIn,让某个动物同时拥有好几个MixIn:
class Dog(Mammal, RunnableMixIn, CarnivorousMixIn):
pass
MixIn的目的就是给一个类增加多个功能,这样,在设计类的时候,优先考虑通过多重继承来组合多个MixIn的功能,而不是设计多层次的复杂的继承关系。
Python自带的很多库也使用了MixIn。如Python自带了TCPServer和UDPServer这两类网络服务,而要同时服务多个用户就必须使用多进程或多线程模型,这两种模型由ForkingMixIn和ThreadingMixIn提供。通过组合,我们就可以创造出合适的服务来。通过MixIn,不需要复杂而庞大的继承链,只要选择组合不同的类的功能,就可以快速构造出所需的子类。Python允许使用多重继承,因此,MixIn就是一种常见的设计。
再看super()函数的用法:
语法:
super(type[, object-or-self])
参数:
•type —— ——类
•object-or-type —— —— 类,一般是self
super()函数是用于调用下一个父类(超类、基类)并返回该父类实例的一个方法。super()函数是用来解决多重继承问题的,直接用类名调用父类方法使用单继承的时候没有问题,但是如果使用多重继承时会涉及查找顺序(method resolution order MRO)、重复调用(钻石继承)等问题。
钻石继承:由一个基类衍生两个及以上的超类,然后再衍生,在类树的最底层生成一个子类,这样的类树结构就是一个类似 钻石外形,所以,最底层类继承称为钻石继承
MRO就是了ide方法解析顺序,其实就是继承父类方法时的顺序表。
super的作用为返回一个代理对象作为代表调用父类或亲类方法,super()的主要用法有两种: 在单类继承中,其意义就是不需要父类的名称来调用父类的函数,因此当子类改为继承其他父类的时候,不需要对子类内部的父类调用函数做任何修改就能调用新父类的方法。 比如:
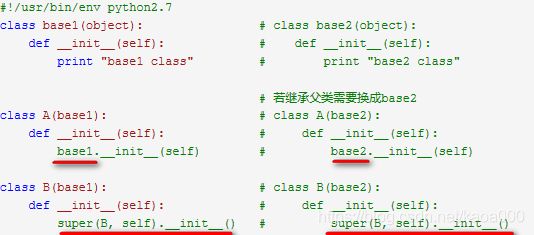
要注意的是由于super将传入self作为调用__init__默认的第一个变量,因此在声明的时候不需要显式表示self。此外由于super返回的是代理对象,因此父类只能调用一次,也就避免了如下异常的可能性。
base1 = A
base1() # 无限递归
再看其定义:super([type [,object-or-type]]):
Return a **proxy object** that delegates method calls to a **parent or sibling** class of type.
返回一个代理对象, 这个对象负责将方法调用分配给第一个参数的一个父类或者同辈的类去完成.
parent or sibling class 如何确定?
第一个参数的__mro__属性决定了搜索的顺序, super指的是 MRO(Method Resolution Order) 中的下一个类, 而不一定是父类!
super()和getattr() 都使用__mro__属性来解析搜索顺序, __mro__实际上是一个只读的元组.
MRO中类的顺序是怎么排的呢?
实际上MRO列表本身是根据一种C3的线性化处理技术确定的, 理论原则如下:
在MRO中, 基类永远出现在派生类的后面, 如果有多个基类, 基类的相对顺序不变.
MRO实际上是对继承树做层序遍历的结果, 把一棵带有结构的树变成了一个线性的表, 所以沿着这个列表一直往上, 就可以无重复的遍历完整棵树, 也就解决了多继承中的Diamond问题.
比如说:
super()实际返回的是一个代理的super对象!
调用super()这个构造方法时, 只是返回一个super()对象, 并不做其他的操作.
然后对这个super对象进行方法调用时, 发生的事情如下:
找到第一个参数的__mro__列表中的下一个直接定义了该方法的类, 并实例化出一个对象
然后将这个对象的self变量绑定到第二个参数上, 返回这个对象
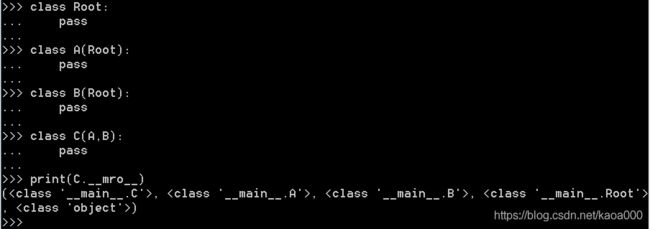
class Root:
def __init__(self):
print('Root')
class A(Root):
def __init__(self):
super().__init__() # 等同于super(A, self).__init__()
在A的构造方法中, 先调用super()得到一个super对象, 然后向这个对象调用init方法, 这时super对象会搜索A的__mro__列表, 找到第一个定义了__init__方法的类, 于是就找到了Root, 然后调用Root.__init__(self), 这里的self是super()的第二个参数, 是编译器自动填充的, 也就是A的__init__的第一个参数, 这样就完成对__init__方法调用的分配.
注意: 在许多语言的继承中, 子类必须调用父类的构造方法, 就是为了保证子类的对象能够填充上父类的属性! 而不是初始化一个父类对象...Python中所谓的调用父类构造方法, 就是明明白白地把self传给父类的构造方法,由父类的构造方法在子类身上进行操作。
参数说明
super() -> same as super(__class__,
super(type) -> unbound super object
super(type, obj) -> bound super object; requires isinstance(obj, type)
super(type, type2) -> bound super object; requires issubclass(type2, type)
Typical use to call a cooperative superclass method:
class C(B):
def meth(self, arg):
super().meth(arg)
This works for class methods too:
class C(B):
@classmethod
def cmeth(cls, arg):
super().cmeth(arg)
如果提供了第二个参数, 则找到的父类对象的self就绑定到这个参数上, 后面调用这个对象的方法时, 可以自动地隐式传递self.
如果第二个参数是一个对象, 则isinstance(obj, type)必须为True. 如果第二个参数为一个类型, 则issubclass(type2, type)必须为True
如果没有传递第二个参数, 那么返回的对象就是Unbound, 调用这个unbound对象的方法时需要手动传递第一个参数, 类似于Base.__int__(self, a, b).
不带参数的super()只能用在类定义中(因为依赖于caller的第二个参数), 编译器会自动根据当前定义的类填充参数.
也就是说, 后面所有调用super返回对象的方法时, 第一个参数self都是super()的第二个参数. 因为Python中所谓的方法, 就是一个第一个参数为self的函数, 一般在调用方法的时候a.b()会隐式的将a赋给b()的第一个参数.
super()的两种常见用法:
单继承中, super用来隐式指代父类, 避免直接使用父类的名字
多继承中, 解决Diamond问题 (TODO)
对面向对象的理解
其实我觉得Python里面这样的语法更容易理解面向对象的本质, 比Java中隐式地传this更容易理解.
所谓函数, 就是一段代码, 接受输入, 返回输出. 所谓方法, 就是一个函数有了一个隐式传递的参数. 所以方法就是一段代码, 是类的所有实例共享的, 唯一不同的是各个实例调用的时候传给方法的this 或者self不一样而已.
构造方法是什么呢? 其实也是一个实例方法啊, 它只有在对象生成了之后才能调用, 所以Python中__init__方法的参数是self啊. 调用构造方法时其实已经为对象分配了内存, 构造方法只是起到初始化的作用, 也就是为这段内存里面赋点初值而已.
Java中所谓的静态变量其实也就是类的变量, 其实也就是为类也分配了内存, 里面存了这些变量, 所以Python中的类对象我觉得是很合理的, 也比Java要直观. 至于静态方法, 那就与对象一点关系都没有了, 本质就是个独立的函数, 只不过写在了类里面而已. 而Python中的classmethod其实也是一种静态方法, 不过它会依赖于cls对象, 这个cls就是类对象, 但是只要想用这个方法, 类对象必然是存在的, 不像实例对象一样需要手动的实例化, 所以classmethod也可以看做是一种静态变量. 而staticmethod就是真正的静态方法了, 是独立的函数, 不依赖任何对象.
Java中的实例方法是必须依赖于对象存在的, 因为要隐式的传输this, 如果对象不存在这个this也没法隐式了. 所以在静态方法中是没有this指针的, 也就没法调用实例方法. 而Python中的实例方法是可以通过类名来调用的, 只不过因为这时候self没办法隐式传递, 所以必须得显式地传递.
对super()函数的再认识:
虽然上面讲了一大堆,但是对于super还是搞不太明白:,看下图
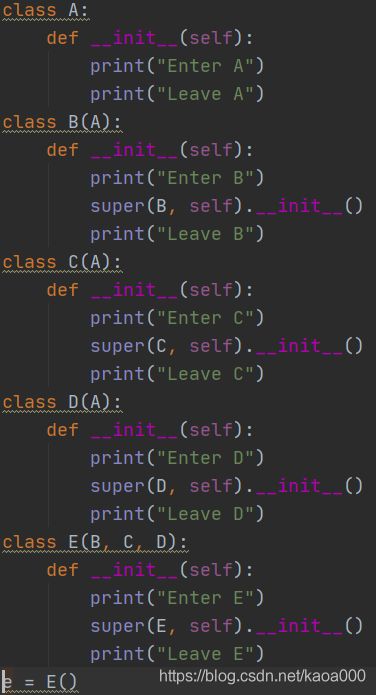
我一开始理解的它的运行结果应该是:

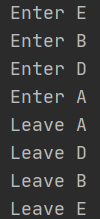
E当中的super()会调用父类B的__init__()方法,而B类中又调用了super(),我感觉就应该是在以B为起点,去调用B的父类,即A的__init__(),A没有调用super(),那就开始返回,返回到B,B在返回到E,E在按照__mro__找下一个父类,即C。
实际运行是:
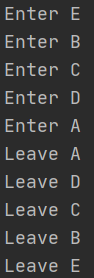
实际上这里对super()没有理解透,要理解super,记住下面三句话:
1.super是一个类,返回的是一个 proxy对象,目的是可以让你访问父类的一些特殊方法
2.你得按照父类对应的特殊方法去传递参数,父类没有的参数就不要乱传
3.不要一说到 super 就想到父类!super 指的是 MRO(method resolution order) 中的下一个类!
第一,super指的是MRO中的下一个类,看一下MRO,是一个元组:
(
super 指的是 MRO(method resolution order) 中的下一个类,那么,在E当中调用super()时,返回的是

做测试:
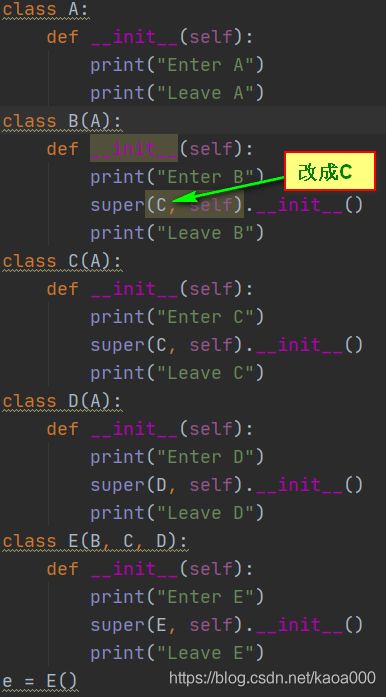
按上面的理论,结果应该跳过C,Enter B后直接是Enter D,看结果:
===================================================================
再看一段关于super的描述:
Python函数对象为descriptors,Python使用描述符协议将函数绑定到实例.这个过程产生一个绑定的方法.
绑定是当您调用方法时出现“magic”self参数,当您尝试将属性用作实例上的属性时,什么使属性对象自动调用方法.
当您尝试使用它来查找父类的方法时,带有两个参数的super()调用相同的描述符协议; super(Foo,self).bar()将遍历Foo父类,直到找到一个属性栏,如果这是一个描述符的对象,它将被绑定到自己.调用栏然后调用绑定方法,该方法又将调用self参数中的函数调用为bar(self).
要做到这一点,super()对象存储类(第一个参数)绑定的自变量,以及自身对象的类型作为属性:
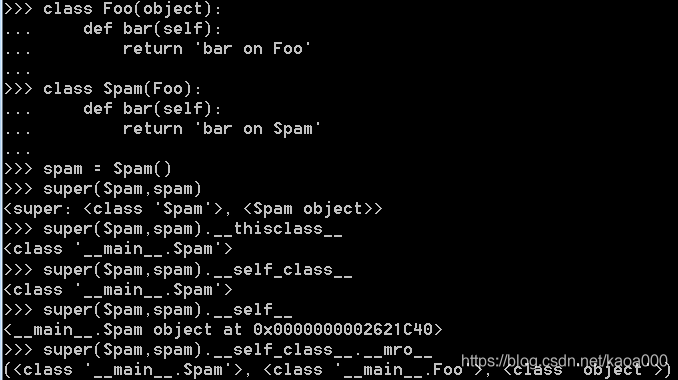
查找属性时,会搜索__self_class__属性的__mro__属性,从__thisclass__的位置开始一个位置,结果被绑定.
只有一个参数的super()将会错过__self_class__和__self__属性,并且不能执行查找:
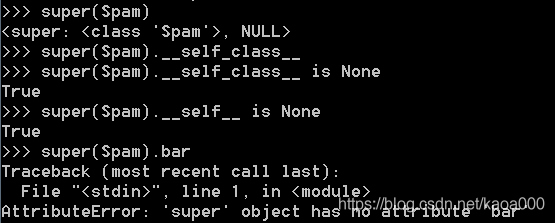
对象确实支持描述符协议,所以你可以绑定它,就像你可以绑定一个方法一样:

对于super()的__get__方法:def __get__(self, *args, **kwargs):
这意味着您可以将这样的对象存储在类上,并使用它来遍历父方法:
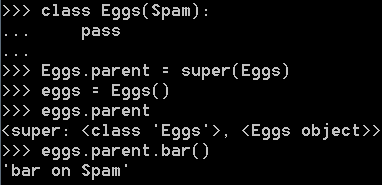
========================================================
前面的示例改一下:

结果:

对一个参数的super还是不太明白。
接下来说说 super(type, obj) 和 super(type, type2)的区别。
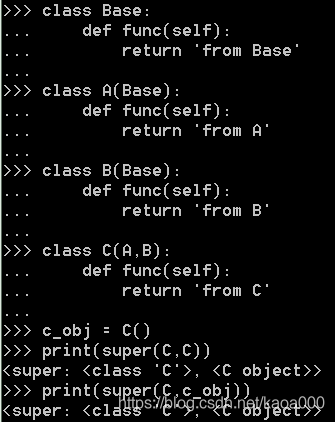
两次的打印结果一模一样,但是,他们不是同一个对象,也不相等
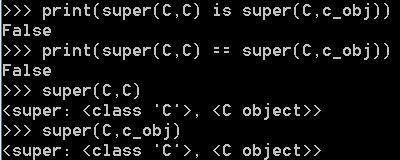
那他们的方法是否是一样的呢?测试一下。

他俩的方法既不是指向同一个,值还不相等。再试试下面的看看。
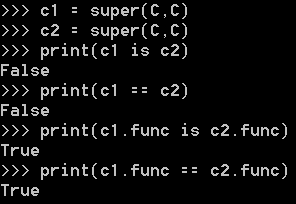
c1和c2不是一个对象,但是他们的方法却是相同的。
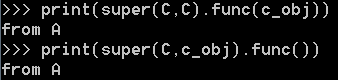
那 super(C, C).func 和 super(C, c_obj).func 的确是不同的。那打印出来看看有什么区别:

super的第二个参数传递的是类,得到的是函数。 super的第二个参数传递的是对象,得到的是绑定方法。
想得到一样的结果,只需要给函数传递一个参数,而绑定方法则不需要传递额外的参数了。
现在总结一下:
1.super()使用的时候需要传递两个参数,在类中可以省略不写,我们使用super()来找父类或者兄弟类的方法;
2.super()是根据第二个参数来计算MRO,根据顺序查找第一个参数类后的方法。
3.super()第二个参数是类,得到的方法是函数,使用时要传self参数。第二个参数是对象,得到的是绑定方法,不需要再传self参数。
给使用super()的一些建议:
1.super()调用的方法要存在;
2.传递参数的时候,尽量使用*args 与**kwargs;
3.父类中的一些特性,比如【】、重写了__getattr__,super对象是不能使用的。
4.super()第二个参数传的是类的时候,建议调用父类的类方法和静态方法。
=================================
函数和绑定方法的区别:
1.与类和实例无绑定关系的function都属于函数(function);
2.与类和实例有绑定关系的function都属于方法(method)。
首先摒弃错误认知:并不是类中的调用都叫方法
函数(FunctionType)
函数是封装了一些独立的功能,可以直接调用,能将一些数据(参数)传递进去进行处理,然后返回一些数据(返回值),也可以没有返回值。可以直接在模块中进行定义使用。 所有传递给函数的数据都是显式传递的。
方法(MethodType)
方法和函数类似,同样封装了独立的功能,但是方法是只能依靠类或者对象来调用的,表示针对性的操作。
方法中的数据self和cls是隐式传递的,即方法的调用者;
方法可以操作类内部的数据
简单的说,函数在python中独立存在,可直接使用的,而方法是必须被别人调用才能实现的。
静态方法除外(与类和对象均无关,通过类名和对象名均可被调用,属函数)
在模块中实现的函数只要导入这个模块的这个函数既可以任意使用了,但是在类中声明的必须导入这个类之后然后再通过创建实例或者类名来调用。可以说直接在模块中声明的是更普遍广泛性的函数,而在类中声明的方法一般是专属于一类事物特有的
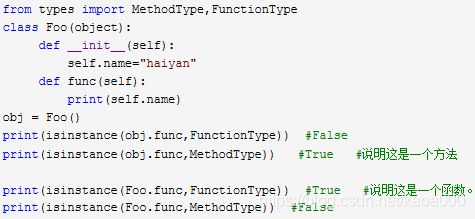
类对象调用func是方法,类调用func是函数,并且是自己传递参数!
注意,这只是在 python3 中才有的区分,python2 中全部称为方法。
最大的区别是参数的传递,方法是自动传参self,函数是主动传参
那么以后我们就可以直接看参数是如何传递的来判断,如果还不确定可以打印类型看看

表面区别:
区别一:所处的位置:函数是直接写文件中而不是class中,方法是只能写在class中。
区别二:定义的方式:
1.函数定义的方式为 def关键字 然后接函数名 再是括号 括号里面写形参也可以省略不写形参
2.方法定义的方式 首先方法是定义在类中的,其他他大体和函数定义差不多,这里需要注意的一点就是方法必须带一个默认参数(相当于this),静态方法除外
区别三:调用的方式:
1.函数的调用:函数的调用是直接写 函数名(函数参数1,函数参数2,......)
2.方法的调用:方法是通过对象点方法调用的(这里是指对象方法)
python类的实例方法、静态方法和类方法区别及其应用场景
一、先看语法,python 类语法中有三种方法,实例方法,静态方法,类方法。
python中self,cls的区别
普通实例方法,第一个参数需要是self,它表示一个具体的实例本身。
如果用了staticmethod,那么就可以无视这个self,而将这个方法当成一个普通的函数使用。
而对于classmethod,它的第一个参数不是self,是cls,它表示这个类本身。

运行结果如下

实例方法只能被实例对象调用,静态方法(由@staticmethod装饰的方法)、类方法(由@classmethod装饰的方法),可以被类或类的实例对象调用。
实例方法,第一个参数必须要默认传实例对象,一般习惯用self。
静态方法,参数没有要求。
类方法,第一个参数必须要默认传类,一般习惯用cls。
====================================
is 与 == 区别 :
is 用于判断两个变量引用对象是否为同一个,就是所引用的对象的内存地址是否一致
== 用于判断引用变量的值是否相等。只判断值和数据类型
id():在内存中存储的位置
type:变量的类型
value:变量的值
==:type value
is:type value id