Hive高级操作
1.使用LIKE、AS创建表,表重命名,添加、修改、删除列
- 表结构数据复制
根据已存在的表结构,使用like关键字,复制一个表结构一模一样的新表
hive> create table student_info2 like student_info;
OK
Time taken: 0.73 seconds
hive> show tables;
OK
employee
student_info
student_info2
student_school_info
student_school_info_external_partition
student_school_info_partition
Time taken: 0.15 seconds, Fetched: 6 row(s)
根据已经存在的表,使用as关键字,创建一个与查询结果字段一致的表,同时将查询结果数据插入到新表
create table student_info3 as select * from student_info;
只有student_id,name两个字段的表
create table student_info4 as select student_id,name from student_info;
- 表重命名
student_info4表重命名为student_id_name
alter table student_info4 rename to student_id_name;
- 添加列
给student_info3表添加性别列,新添加的字段会在所有列最后,分区列之前,在添加新列之前已经存在的数据文件中。
如果没有新添加列对应的数据,在查询的时候显示为空。添加多个列用逗号隔开。
hive> alter table student_info3 add columns(gender string comment '性别');
OK
Time taken: 0.185 seconds
- 删除列或修改列
修改列,将继续存在的列再定义一遍,需要替换的列重新定义
hive> alter table student_info3 replace columns(student_id string,name string,age int,origin string,gender2 int);
OK
Time taken: 0.422 seconds
删除列,将继续存在的列再定义一遍,需要删除的列不再定义
hive> alter table student_info3 replace columns(student_id string,name string,age int,origin string);
OK
Time taken: 0.529 seconds
2.分桶表使用
- 创建分桶表
按照指定字段取它的hash散列值分桶,创建学生入学信息分桶表
| 字段名称 | 类型 | 注释 | 分桶字段 |
|---|---|---|---|
| student_id | string | 学生ID | 是 |
| name | string | 姓名 | 否 |
| age | int | 年龄 | 否 |
| origin | string | 学院ID | 否 |
create table rel.student_info_bucket(
student_id string,
name string,
age int,
origin string
)
clustered by (student_id) sorted by (student_id asc) into 4 buckets
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
- 分桶表插入数据
向student_info_bucket分桶表插入数据
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
insert overwrite table student_info_bucket
select student_id,name,age,origin
from student_info
cluster by(student_id);
查看hdfs分桶文件
[root@hadoop01 ~]# hadoop fs -ls /user/hive/warehouse/rel.db/student_info_bucket
Found 4 items
-rwxr-xr-x 3 hadoop supergroup 78 2018-01-24 19:33 /user/hive/warehouse/rel.db/student_info_bucket/000000_0
-rwxr-xr-x 3 hadoop supergroup 84 2018-01-24 19:33 /user/hive/warehouse/rel.db/student_info_bucket/000001_0
-rwxr-xr-x 3 hadoop supergroup 80 2018-01-24 19:33 /user/hive/warehouse/rel.db/student_info_bucket/000002_0
-rwxr-xr-x 3 hadoop supergroup 81 2018-01-24 19:33 /user/hive/warehouse/rel.db/student_info_bucket/000003_0
说明:
分桶表一般不使用load向分桶表中导入数据,因为load导入数据只是将数据复制到表的数据存储目录下,hive并不会在load的时候对数据进行分析然后按照分桶字段分桶,load只会将一个文件全部导入到分桶表中,并没有分桶。一般采用insert从其他表向分桶表插入数据。
分桶表在创建表的时候只是定义表的模型,插入的时候需要做如下操作:
在每次执行分桶插入的时候在当前执行的session会话中要设置
hive.enforce.bucketing=true;
声明本次执行的是一次分桶操作。需要指定reduce个数与分桶的数量相同
set mapreduce.job.reduces=4,
这样才能保证有多少桶就生成多少个文件。
如果定义了按照分桶字段排序,需要在从其他表查询数据过程中将数据按照分区字段排序之后插入各个桶中,分桶表并不会将各分桶中的数据排序。排序和分桶的字段相同的时候使用Cluster by(字段),cluster by 默认按照分桶字段在桶内升序排列,如果需要在桶内降序排列,使用distribute by (col) sort by (col desc)组合实现。
3.导出数据
- 使用insert将student_info表数据导出到本地指定路径
insert overwrite local directory '/home/hadoop/apps/hive_test_data/export_data'
row format delimited fields terminated by '\t' select * from student_info;
[root@hadoop01 export_data]# cat 000000_0
1 xiaoming 20 11
2 xiaobai 21 31
3 zhangfei 22 44
4 likui 19 44
5 zhaoyun 21 13
6 zhangsan 20 11
7 lisi 19 11
8 wangwu 23 31
9 zhaofei 19 21
10 zhangyan 20 21
11 lihe 20 22
12 caoyang 17 32
13 lihao 19 32
14 zhaoming 21 50
15 zhouhong 18 51
16 yangshuo 23 33
17 xiaofei 24 13
18 liman 23 13
19 qianbao 20 13
20 sunce 21 41
导出数据到本地的常用方法
[hadoop@hadoop01 export_data]$ hive -e"select * from rel.student_info"> /home/hadoop/student_info_data.txt
[hadoop@hadoop01 ~]$ cat student_info_data.txt
1 xiaoming 20 11
2 xiaobai 21 31
3 zhangfei 22 44
4 likui 19 44
5 zhaoyun 21 13
6 zhangsan 20 11
7 lisi 19 11
8 wangwu 23 31
9 zhaofei 19 21
10 zhangyan 20 21
11 lihe 20 22
12 caoyang 17 32
13 lihao 19 32
14 zhaoming 21 50
15 zhouhong 18 51
16 yangshuo 23 33
17 xiaofei 24 13
18 liman 23 13
19 qianbao 20 13
20 sunce 21 41
默认结果分隔符:'\t'
4.关联查询
创建2张表
create table rel.a(
id int,
name string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
create table rel.b(
id int,
name string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
导入数据
hive> load data local inpath '/home/hadoop/apps/hive_test_data/a_join_data' into table a;
Loading data to table rel.a
Table rel.a stats: [numFiles=1, totalSize=61]
OK
Time taken: 1.79 seconds
hive> load data local inpath '/home/hadoop/apps/hive_test_data/b_join_data' into table b;
Loading data to table rel.b
Table rel.b stats: [numFiles=1, totalSize=38]
OK
Time taken: 0.562 seconds
- inner或inner join
两个表通过id关联,只把id值相等的数据查询出来。join的查询结果与inner join的查询结果相同。
select * from a join b on a.id=b.id;
等同于
select * from a inner join b on a.id=b.id;
.....
OK
1 a 1 AA
2 b 2 BB
3 c 3 CC
6 f 6 FF
Time taken: 44.337 seconds, Fetched: 4 row(s)
- full outer join或full join
两个表通过id关联,把两个表的数据全部查询出来
OK
1 a 1 AA
2 b 2 BB
3 c 3 CC
4 d NULL NULL
5 e NULL NULL
6 f 6 FF
7 g NULL NULL
8 h NULL NULL
9 i NULL NULL
10 j NULL NULL
11 k NULL NULL
12 l NULL NULL
13 m NULL NULL
14 n NULL NULL
NULL NULL 20 TT
NULL NULL 21 UU
NULL NULL 22 vv
- left join
左连接时,左表中出现的join字段都保留,右表没有连接上的都为空
OK
1 a 1 AA
2 b 2 BB
3 c 3 CC
4 d NULL NULL
5 e NULL NULL
6 f 6 FF
7 g NULL NULL
8 h NULL NULL
9 i NULL NULL
10 j NULL NULL
11 k NULL NULL
12 l NULL NULL
13 m NULL NULL
14 n NULL NULL
- right join
右连接时,右表中出现的join字段都保留,左表没有连接上的都是空
select * from a right join b on a.id=b.id;
OK
1 a 1 AA
2 b 2 BB
3 c 3 CC
6 f 6 FF
NULL NULL 20 TT
NULL NULL 21 UU
NULL NULL 22 vv
Time taken: 25.188 seconds, Fetched: 7 row(s)
- left semi join
左半连接实现了类似IN/EXISTS的查询语义,输出符合条件的左表内容。
hive不支持in …exists这种关系型数据库中的子查询结构,hive暂时不支持右半连接。
例如:
select a.id, a.name from a where a.id in (select b.id from b);
使用Hive对应于如下语句:
select a.id,a.name from a left semi join b on a.id = b.id;
OK
1 a
2 b
3 c
6 f
Time taken: 27.42 seconds, Fetched: 4 row(s)
- map side join
使用分布式缓存将小表数据加载都各个map任务中,在map端完成join,map任务输出后,不需要将数据拷贝到reducer阶段再进行join,
降低的数据在网络节点之间传输的开销。多表关联数据倾斜优化的一种手段。多表连接,如果只有一个表比较大,其他表都很小,
则join操作会转换成一个只包含map的Job。运行日志中会出现Number of reduce tasks is set to 0 since there's no reduce operator
没有reduce的提示。
例如:
select /*+ mapjoin(b) */ a.id, a.name from a join b on a.id = b.id
Total MapReduce CPU Time Spent: 1 seconds 320 msec
OK
1 a
2 b
3 c
6 f
Time taken: 25.538 seconds, Fetched: 4 row(s)
5.Hive内置函数
创建用户评分表
create table rel.user_core_info(
user_id string,
age int,
gender string,
core int
)
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
导入数据
load data local inpath '/home/hadoop/apps/hive_test_data/user_core.txt' into table rel.user_core_info;
-
- 条件函数 case when
语法1:CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
说明:如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f
例如:
- 条件函数 case when
hive> select case 1 when 2 then 'two' when 1 then 'one' else 'zero' end;
OK
one
Time taken: 0.152 seconds, Fetched: 1 row(s)
语法2:CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
说明:如果a为TRUE,则返回b;如果c为TRUE,则返回d;否则返回e
例如:
hive> select case when 1=2 then 'two' when 1=1 then 'one' else 'zero' end;
OK
one
Time taken: 0.33 seconds, Fetched: 1 row(s)
查询用户评分表,每个年龄段的最大评分值
select gender,
case when age<=20 then 'p0' when age>20 and age<=50 then 'p1' when age>=50 then 'p3' else 'p0' end,
max(core) max_core
from rel.user_core_info
group by gender,
case when age<=20 then 'p0' when age>20 and age<=50 then 'p1' when age>=50 then 'p3' else 'p0' end;
结果为:
OK
female p0 90
female p1 95
female p3 90
male p0 80
male p1 80
male p3 80
Time taken: 28.461 seconds, Fetched: 6 row(s)
-
- 自定义UDF函数
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
UDF 作用于单个数据行,产生一个数据行作为输出。
步骤:
- 先开发一个java类,继承UDF,并重载evaluate方法
- 打成jar包上传到服务器
- 在使用的时候将jar包添加到hive的classpath
hive>add jar /home/hadoop/apps/hive_test_data/HiveUdfPro-1.0-SNAPSHOT.jar;
- 创建临时函数与开发好的java class关联
hive>create temporary function age_partition as 'cn.chinahadoop.udf.AgePartitionFunction';
- 即可在hql中使用自定义的函数
新建Maven 项目
Pom 信息如下:
4.0.0
com.yongliang.udf
HiveUdfPro
1.0-SNAPSHOT
jar
HiveUdfPro
http://maven.apache.org
UTF-8
org.apache.hive
hive-exec
1.2.2
org.apache.hadoop
hadoop-common
2.7.0
org.apache.maven.plugins
maven-compiler-plugin
2.3.2
default-compile
compile
compile
UTF-8
新建类继承UDF
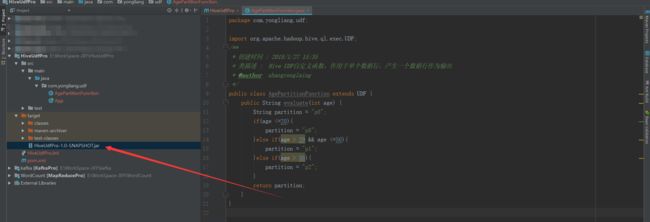
package com.yongliang.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 创建时间 : 2018/1/27 15:35
* 类描述 : Hive UDF自定义函数,作用于单个数据行,产生一个数据行作为输出
* @author zhangyonglaing
*/
public class AgePartitionFunction extends UDF {
public String evaluate(int age) {
String partition = "p0";
if(age <=20){
partition = "p0";
}else if(age > 20 && age <=50){
partition = "p1";
}else if(age > 50){
partition = "p2";
}
return partition;
}
}
说明:
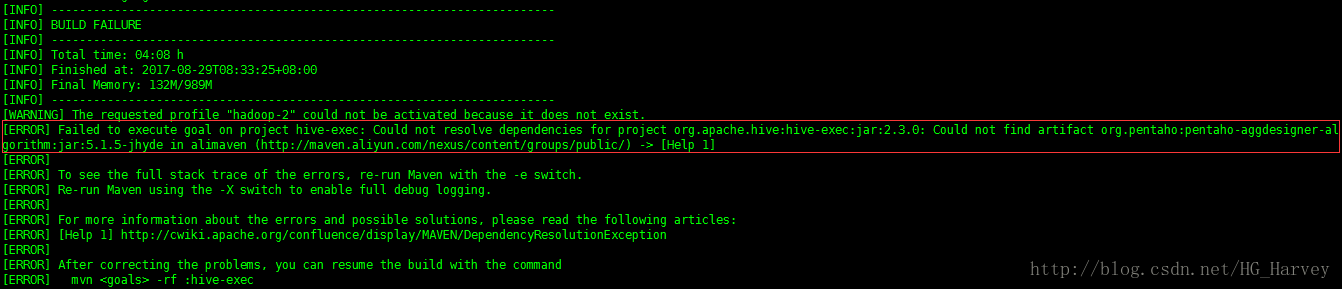
如出现以下异常信息:
Failed to execute goal on project hive-exec:
Could not resolve dependencies for project org.apache.hive:hive-exec:jar:2.3.0:
Could not find artifact org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde in alimaven (http://maven.aliyun.com/nexus/content/groups/public/) -> [Help 1]
请手动下载Jar包pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar下载地址: https://public.nexus.pentaho.org/content/groups/omni/org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde/
将Jar包放置在本地Maven仓库org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde路径下,之后进行重新打包。
- 将jar包添加到hive的classpath
hive> add jar /home/hadoop/apps/HiveUdfPro-1.0-SNAPSHOT.jar;
Added [/home/hadoop/apps/HiveUdfPro-1.0-SNAPSHOT.jar] to class path
Added resources: [/home/hadoop/apps/HiveUdfPro-1.0-SNAPSHOT.jar]
创建临时函数与开发好的java class关联
hive> create temporary function age_partition as 'com.yongliang.udf.AgePartitionFunction';
在hql中使用自定义的函数
select gender,
age_partition(age),
max(core) max_core
from rel.user_core_info
group by gender,
age_partition(age);
结果为:
OK
female p0 90
female p1 95
female p2 90
male p0 80
male p1 80
male p2 80