大数据项目之电商数仓(用户行为数仓一)
大数据项目之电商数仓(用户行为数仓)
一:数仓分层概念
1、数据仓库分层:
ODS:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不变
DWD:明细数据层,结构和粒度与原始数据保持一致,对ODS层数据进行清洗(去除空值,脏数据,超过极限范围数据)
DWS:服务数据层,以DWD为基础,进行轻度汇总
ADS层:数据应用层,为各种统计报表提高数据
2、数仓命名规范:
ODS层:ods,DWD层:dwd,DWS层:dws,ADS层:ads,临时表数据库:xxx_tmp,备份数据库:xxx_bak
二:数仓环境准备
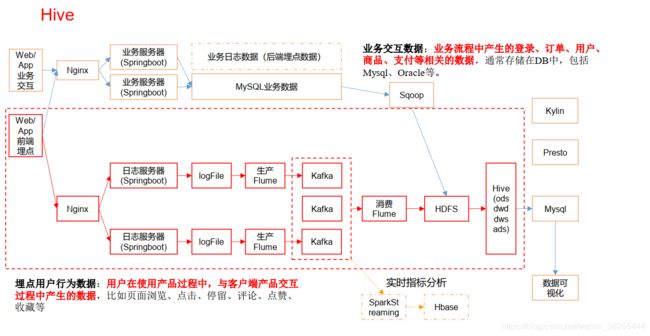
1、数据流程图
2、Hive&&MySQL安装
都安装再102一台机器上,注意元数据库换成mysql
Hive运行引擎Tez
Tez 是一个 Hive 的运行引擎,性能优于 MR,Tez 可以将多个有依赖的作业转换为一个作业, 这样只需写一次 HDFS,且中间节点较少,从而大大提升作业的计算性能。
三:数仓搭建之ODS层
ODS层:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理
1、创建启动日志表:ods_start_log
1) 创建输入数据是 lzo 输出是 text, 支持 json 解析的分区表
hive (gmall)>
drop table if exists ods_start_log;
CREATE EXTERNAL TABLE ods_start_log (`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_start_log';
说明 Hive 的 LZO 压缩: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LZO
2) 加载数据
hive (gmall)>
load data inpath '/origin_data/gmall/log/topic_start/2019-02-
10' into table gmall.ods_start_log partition(dt='2019-02-10');
注意: 时间格式都配置成 YYYY-MM-DD 格式,这是 Hive 默认支持的时间格式
3)查看是否加载成功
hive (gmall)> select * from ods_start_log limit 2;
2、创建时间日志表ods_event_log
1) 创建输入数据是 lzo 输出是 text, 支持 json 解析的分区表
hive (gmall)>
drop table if exists ods_event_log;
CREATE EXTERNAL TABLE ods_event_log(`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_event_log';
2)加载数据
hive (gmall)>
load data inpath '/origin_data/gmall/log/topic_event/2019-02-
10' into table gmall.ods_event_log partition(dt='2019-02-10');
注意: 时间格式都配置成 YYYY-MM-DD 格式,这是 Hive 默认支持的时间格式
3)查看是否加载成功
hive (gmall)> select * from ods_event_log limit 2;
注意:
(1)单引号不取变量值
(2)双引号取变量值
(3)反引号`,执行引号中命令
(4)双引号内部嵌套单引号,取出变量值
(5)单引号内部嵌套双引号,不取出变量值
3、ODS层加载数据脚本
创建脚本:vim ods_log.sh
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/opt/module/hive/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo "===日志日期为 $do_date==="
sql="
load data inpath '/origin_data/gmall/log/topic_start/$do_date'
into table "$APP".ods_start_log partition(dt='$do_date');
load data inpath '/origin_data/gmall/log/topic_event/$do_date'
into table "$APP".ods_event_log partition(dt='$do_date');
"
$hive -e "$sql"
说明 1:
[ -n 变量值 ] 判断变量的值,是否为空
-- 变量的值,非空,返回 true
-- 变量的值,为空,返回 false
脚本权限:chmod 777 ods_log.sh
四:数仓搭建之DWD层
对ODS层数据进行清洗(去除空值,脏数据,超过极限范围数据,行试存储改为列存储,改压缩格式)
1、DWD层启动表数据解析
1)创建启动表:
hive (gmall)>
drop table if exists dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
location '/warehouse/gmall/dwd/dwd_start_log/';
2)向启动表导入数据
hive (gmall)>
insert overwrite table dwd_start_log
PARTITION (dt='2019-02-10')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from ods_start_log
where dt='2019-02-10';
3)测试
hive (gmall)> select * from dwd_start_log limit 2;
2、DWD层事件表数据解析
1、创建基础明细表
明细表用来存储ODS层原始表转换过来的明细数据
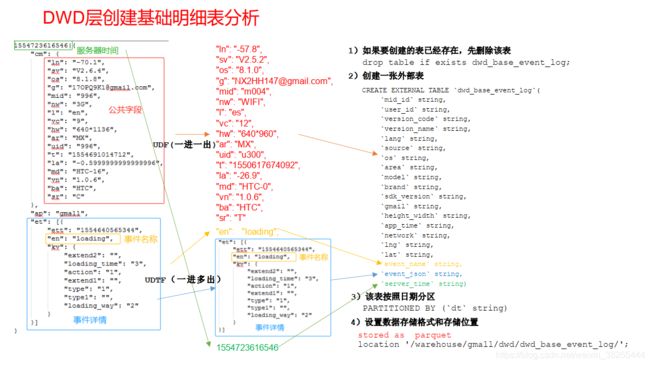
2)创建事件日志基础明细表
hive (gmall)>
drop table if exists dwd_base_event_log;
CREATE EXTERNAL TABLE dwd_base_event_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
`event_name` string,
`event_json` string,
`server_time` string)
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_base_event_log/';
3) 说明: 其中event_name和event_json 用来对应事件名和整个事件。 这个地方将原始日志1对多的形式拆分出来了。操作的时候我们需要将原始日志展平,需要用到 UDF 和 UDTF。
2、自定义UDF函数(解析公共字段)

1、创建maven工程:hivefunction,添加pom。xml文件
<properties> <project.build.sourceEncoding>UTF8</project.build.sourceEncoding>
<hive.version>1.2.1</hive.version>
</properties>
<dependencies>
<!--添加 hive 依赖-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${
hive.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2、UDF解析公共字段
package com.ityouxin.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.json.JSONException;
import org.json.JSONObject;
public class BaseFieldUDF extends UDF {
public String evaluate(String line, String jsonkeysString) {
// 0 准备一个 sb
StringBuilder sb = new StringBuilder();
// 1 切割 jsonkeys mid uid vc vn l sr os ar md
String[] jsonkeys = jsonkeysString.split(",");
// 2 处理 line 服务器时间 | json
String[] logContents = line.split("\\|");
// 3 合法性校验
if (logContents.length != 2 || StringUtils.isBlank(logContents[1])) {
return "";
}
// 4 开始处理 json
try {
JSONObject jsonObject = new JSONObject(logContents[1]);
// 获取 cm 里面的对象
JSONObject base = jsonObject.getJSONObject("cm");
// 循环遍历取值
for (int i = 0; i < jsonkeys.length; i++) {
String filedName = jsonkeys[i].trim();
if (base.has(filedName)) {
sb.append(base.getString(filedName)).append("\t");
} else {
sb.append("\t");
}
}
sb.append(jsonObject.getString("et")).append("\t");
sb.append(logContents[0]).append("\t");
} catch (JSONException e) {
e.printStackTrace();
}
return sb.toString();
}
public static void main(String[] args) {
String line =
"1541217850324|{
\"cm\":{
\"mid\":\"m7856\",\"uid\":\"u8739\",\"ln\":\"-
74.8\",\"sv\":\"V2.2.2\",\"os\":\"8.1.3\",\"g\":\"[email protected]\",\"nw\":\"3G\
",\"l\":\"es\",\"vc\":\"6\",\"hw\":\"640*960\",\"ar\":\"MX\",\"t\":\"1541204134250\
",\"la\":\"-31.7\",\"md\":\"huawei-
17\",\"vn\":\"1.1.2\",\"sr\":\"O\",\"ba\":\"Huawei\"},\"ap\":\"weather\",\"et\":[{\
"ett\":\"1541146624055\",\"en\":\"display\",\"kv\":{
\"goodsid\":\"n4195\",\"copyrig
ht\":\"ESPN\",\"content_provider\":\"CNN\",\"extend2\":\"5\",\"action\":\"2\",\"ext
end1\":\"2\",\"place\":\"3\",\"showtype\":\"2\",\"category\":\"72\",\"newstype\":\"
5\"}},{
\"ett\":\"1541213331817\",\"en\":\"loading\",\"kv\":{
\"extend2\":\"\",\"load
ing_time\":\"15\",\"action\":\"3\",\"extend1\":\"\",\"type1\":\"\",\"type\":\"3\",\
"loading_way\":\"1\"}},{\"ett\":\"1541126195645\",\"en\":\"ad\",\"kv\":{\"entry\":\
"3\",\"show_style\":\"0\",\"action\":\"2\",\"detail\":\"325\",\"source\":\"4\",\"behavior\":\"2\",\"content\":\"1\",\"newstype\":\"5\"}},{
\"ett\":\"1541202678812\",\"
en\":\"notification\",\"kv\":{
\"ap_time\":\"1541184614380\",\"action\":\"3\",\"type
\":\"4\",\"content\":\"\"}},{
\"ett\":\"1541194686688\",\"en\":\"active_background\"
,\"kv\":{\"active_source\":\"3\"}}]}";
String x = new BaseFieldUDF().evaluate(line,
"mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,nw,ln,la,t");
System.out.println(x);
}
}
3、打包上传到服务器
4、将jar包添加到Hive的classpath
hive (gmall)> add jar /opt/module/hive/hivefunction-1.0-
SNAPSHOT.jar;
5、创建临时函数与开发好的java class关联
hive (gmall)>
create temporary function base_analizer as
'com.ityouxin.udf.BaseFieldUDF';
create temporary function flat_analizer as
'com.ityouxin.udtf.EventJsonUDTF';
3、自定义UDTF函数(解析具体事件字段)

1)创建类:com.ityouxin.udtf.EventJsonUDTF
2)用于展开业务字段
package com.ityouxin.udtf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import
org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFac
tory;
import org.json.JSONArray;
import org.json.JSONException;
import java.util.ArrayList;
public class EventJsonUDTF extends GenericUDTF {
//该方法中,我们将指定输出参数的名称和参数类型:
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws
UDFArgumentException {
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("event_name");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("event_json");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);
}
//输入 1 条记录,输出若干条结果
@Override
public void process(Object[] objects) throws HiveException {
// 获取传入的 et
String input = objects[0].toString();
// 如果传进来的数据为空,直接返回过滤掉该数据
if (StringUtils.isBlank(input)) {
return;
} else {
try {
// 获取一共有几个事件(ad/facoriters)
JSONArray ja = new JSONArray(input);
if (ja == null)
return;
// 循环遍历每一个事件20 / 84 北京东燕郊开发区燕灵路方舟广场南侧 169 号 电话: 010-83868569
for (int i = 0; i < ja.length(); i++) {
String[] result = new String[2];
try {
// 取出每个的事件名称(ad/facoriters)
result[0] = ja.getJSONObject(i).getString("en");
// 取出每一个事件整体
result[1] = ja.getString(i);
} catch (JSONException e) {
continue;
}
// 将结果返回
forward(result);
}
} catch (JSONException e) {
e.printStackTrace();
}
}
}
//当没有记录处理的时候该方法会被调用,用来清理代码或者产生额外的输出
@Override
public void close() throws HiveException {
}
}
3)打包上传
4)添加jar包到Hive的classpath
hive (gmall)> add jar /opt/module/hive/hivefunction-1.0-
SNAPSHOT.jar;
5)创建临时表与开发好的java class关联
hive (gmall)>
create temporary function base_analizer as
'com.ityouxin.udf.BaseFieldUDF';
create temporary function flat_analizer as
'com.ityouxin.udtf.EventJsonUDTF';
4、解析事件日志基础明细表
1) 解析事件日志基础明细表
hive (gmall)>
set hive.exec.dynamic.partition.mode=nonstrict;
设置为非严格模式(动态分区的模式,默认 strict,表示必须指定至少一个分区为静态分区, nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
2)插入数据
insert overwrite table dwd_base_event_log
PARTITION (dt='2019-02-10')
select
mid_id,
user_id,
version_code,
version_name,
lang,
source,
os,
area,
model,
brand,
sdk_version,
gmail,
height_width,
app_time,
network,
lng,
lat,
event_name,
event_json,
server_time
from
( s
elect
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0]
as mid_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1]
as user_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2]
as version_code,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3]
as version_name,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4]
as lang,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5]
as source,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6]
as os,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7]
as area,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8]
as model,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9]
as brand,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10]
as sdk_version,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11]
as gmail,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12]
as height_width,22 / 84 北京东燕郊开发区燕灵路方舟广场南侧 169 号 电话: 010-83868569
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13]
as app_time,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14]
as network,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15]
as lng,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16]
as lat,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17]
as ops,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18]
as server_time
from ods_event_log where dt='2019-02-10' and
base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>''
) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
3)测试
hive (gmall)> select * from dwd_base_event_log limit 2;
5、DWD层数据解析脚本:省略
3、DWD层数据表获取
1、商品点击表
2、商品详情页表
3、商品列表页表
4、广告表
5、消息通知表
6、用户前台活跃表
7、用户后台活跃表
8、评论表
9、收藏表
10、点赞表
11、错误日志表
12、DWD层事件加载数据脚本
5、需求一:用户活跃主题统计
1、DWS层:
统计当日、当周、当月活动的每个设备明细
1、每日活跃设备明细

2、每周活跃设备明细

3、每月活跃设备明细

4、DWS层加载数据脚本:省略
2、ADS层
1、活跃设备数

2、ADS层加载数据脚本:省略
6、需求二:用户新增主题
1、DWS(每日新增设备明细表)


2、ADS层(每日新增设备表)

7、需求三:用户留存主题
1、需求目标
留存用户: 某段时间内的新增用户(活跃用户) , 经过一段时间后, 又继续使用应用的被认作是留存用户;
留存率: 留存用户占当时新增用户(活跃用户) 的比例即是留存率。
例如, 2月10日新增用户100, 这100人在2月11日启动过应用的有30人, 2月12日启动过应用的有25人, 2月13日启动过应用的有32人;
则2月10日新增用户次日的留存率是30/100 = 30%, 两日留存率是25/100=25%, 三日留存率32/100=32%。
1、需求描述
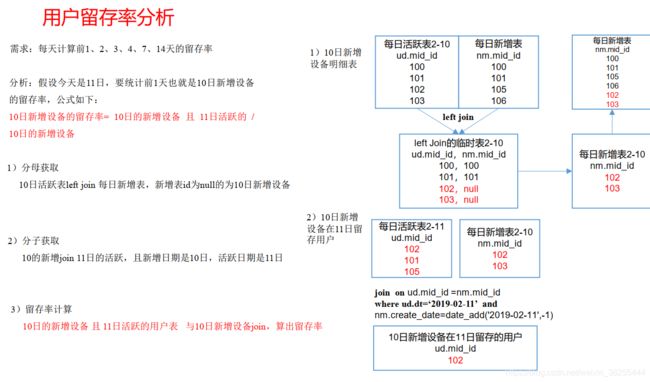
2、DWS层(每日留存用户明细表)

3、DWS层(1,2,3n天留存用户明细表)
1) 导入数据( 每天计算前 1,2,3, n 天的新用户访问留存明细)
hive (gmall)>
insert overwrite table dws_user_retention_day
partition(dt="2019-02-11")
select
nm.mid_id,
nm.user_id,
nm.version_code,
nm.version_name,
nm.lang,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,63 / 84 北京东燕郊开发区燕灵路方舟广场南侧 169 号 电话: 010-83868569
1 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on ud.mid_id
=nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-
11',-1)
union all
select
nm.mid_id,
nm.user_id ,
nm.version_code ,
nm.version_name ,
nm.lang ,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,
2 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on
ud.mid_id =nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-
11',-2)
union all
select
nm.mid_id,
nm.user_id ,
nm.version_code ,
nm.version_name ,
nm.lang ,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,
3 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on
ud.mid_id =nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-
11',-3);
2) 查询导入数据
hive (gmall)> select retention_day , count(*) from
dws_user_retention_day group by retention_day;
总结:
(1) union 会将联合的结果集去重,效率较 union all 差
(2) union all 不会对结果集去重,所以效率高
3、ADS层
1、用户留存数

2、留存用户比率

8、新数据准备
为了分析沉默用户数、本周回流用户数、流失用户数、最近连续三周活跃用户、最近七天内连续活跃用户数,所以需要准备连续三天的用户行为日志数据。
9、需求四:沉默用户数
沉默用户:指的是只在安装当天启动过 ,且启动时间在一周前
1、DWS层
使用日活跃明细表dws_uv_detail_day作为DWS层数据
2、ADS层
沉默用户数

3、编写脚本
#!/bin/bash
hive=/opt/module/hive/bin/hive
APP=gmall
if [ -n "$1" ];then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo "-----------导入日期$do_date-----------"
sql="
insert into table "$APP".ads_slient_count
select
'$do_date' dt,
count(*) slient_count
from
(
select
mid_id
from "$APP".dws_uv_detail_day
where dt<='$do_date'
group by mid_id
having count(*)=1 and min(dt)<=date_add('$do_date',-7)
)t1;"
$hive -e "$sql"
10、需求5:本周回流用户数
本周回流=本周活跃-本周新增-上周活跃
1、DWS层
使用日活跃明细表dws_uv_detail_day 作为 DWS 层数据
2、ADS层
本周回流用户数

3、编写脚本
#!/bin/bash
if [ -n "$1" ];then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
hive=/opt/module/hive/bin/hive
APP=gmall
echo "-----------导入日期$do_date-----------"
sql="
insert into table "$APP".ads_back_count
select
'$do_date' dt,
concat(date_add(next_day('$do_date','MO'),-
7),'_',date_add(next_day('$do_date','MO'),-1)) wk_dt,
count(*)
from
(
select t1.mid_id
from72 / 84 北京东燕郊开发区燕灵路方舟广场南侧 169 号 电话: 010-83868569
(
select mid_id
from "$APP".dws_uv_detail_wk
where wk_dt=concat(date_add(next_day('$do_date','MO'),-
7),'_',date_add(next_day('$do_date','MO'),-1))
)t1
left join
(
select mid_id
from "$APP".dws_new_mid_day
where create_date<=date_add(next_day('$do_date','MO'),-1)
and create_date>=date_add(next_day('$do_date','MO'),-7)
)t2
on t1.mid_id=t2.mid_id
left join
(
select mid_id
from "$APP".dws_uv_detail_wk
where wk_dt=concat(date_add(next_day('$do_date','MO'),-
7*2),'_',date_add(next_day('$do_date','MO'),-7-1))
)t3
on t1.mid_id=t3.mid_id
where t2.mid_id is null and t3.mid_id is null
)t4;
"
$hive -e "$sql"