1.背景&问题描述
接上篇文章 http://www.jianshu.com/p/329b9f92ac4c
在上一篇文章中,由于系统宕机,导致大量索引出现了Unassigned 状态。在上一篇文章中,我们通过reroute API进行了操作,对主分片缺失的索引,经过上述操作之后,分配了主分片。但是在接下来的操作中,对于副本分片,reroute出错!
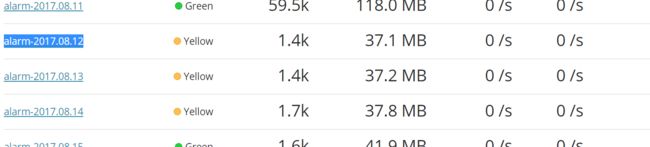
如下是索引 alarm-2017.08.12,第0个分片的副本没有分配:

下面执行语句:
POST /_cluster/reroute
{
"commands": [
{
"allocate_replica": {
"index": "alarm-2017.08.12",
"shard": 0,
"node": "node4-1"
}
}
]
}
结果执行失败!
{
"error": {
"root_cause": [
{
"type": "remote_transport_exception",
"reason": "[node3-2][192.168.21.88:9301][cluster:admin/reroute]"
}
],
"type": "illegal_argument_exception",
"reason": "[allocate_replica] allocation of [alarm-2017.08.12][0] on node {node4-1}{u47KtJGgQw60T_xm9hmepw}{UbaCHI4KRveQeTAnJvGFEQ}{192.168.21.89}{192.168.21.89:9301}{rack=r4, ml.enabled=true} is not allowed, reason: [NO(shard has exceeded the maximum number of retries [5] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [unassigned_info[[reason=ALLOCATION_FAILED], at[2017-08-16T00:54:47.088Z], failed_attempts[5], delayed=false, details[failed recovery, failure RecoveryFailedException[[alarm-2017.08.12][0]: Recovery failed from {node8}{Bpd3y--EQsag1u1NTmtZfA}{4T_McpmjSXqLowRoXztssQ}{192.168.21.89}{192.168.21.89:9301}{rack=r4} into {node5}{i4oG4VcaSdKVeNEvStXwAw}{w4nAITEOR9u7liR55qDsVA}{192.168.21.88}{192.168.21.88:9300}{rack=r3}]; nested: RemoteTransportException[[node8][192.168.21.89:9301][internal:index/shard/recovery/start_recovery]]; nested: RecoveryEngineException[Phase[1] phase1 failed]; nested: RecoverFilesRecoveryException[Failed to transfer [0] files with total size of [0b]]; nested: FileSystemException[/opt/elasticsearch/elasticsearch-node8/data/nodes/0/indices/FgLdgYTmTfazlP8i5K0Knw/0/index: Too many open files in system]; ], allocation_status[no_attempt]]])][YES(primary shard for this replica is already active)][YES(explicitly ignoring any disabling of allocation due to manual allocation commands via the reroute API)][YES(target node version [5.5.1] is the same or newer than source node version [5.5.1])][YES(the shard is not being snapshotted)][YES(node passes include/exclude/require filters)][YES(the shard does not exist on the same host)][YES(enough disk for shard on node, free: [6.4tb], shard size: [0b], free after allocating shard: [6.4tb])][YES(below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2])][YES(total shard limits are disabled: [index: -1, cluster: -1] <= 0)][YES(allocation awareness is not enabled, set cluster setting [cluster.routing.allocation.awareness.attributes] to enable it)]"
},
"status": 400
}
注意看错误:
FileSystemException[/opt/elasticsearch/elasticsearch-node8/data/nodes/0/indices/FgLdgYTmTfazlP8i5K0Knw/0/index: Too many open files in system
2.问题分析:
表面上看好像是还是超出了文件limits。但是在做上述操作的过程中,我已经将所有配置调整,并将elasticsearch集群升级,新增了两台服务器,将服务器修改为如下节点:
| 节点名称 | 服务器 | http端口 | rack | Xms&Xmx |
|---|---|---|---|---|
| node1-1 | 192.168.21.23 | 9201 | rack1 | 20G |
| node1-2 | 192.168.21.23 | 9202 | rack1 | 20G |
| node1-3 | 192.168.21.23 | 9203 | rack1 | 20G |
| node2-1 | 192.168.21.24 | 9201 | rack2 | 20G |
| node2-2 | 192.168.21.24 | 9202 | rack2 | 20G |
| node2-3 | 192.168.21.24 | 9203 | rack2 | 20G |
| node3-1 | 192.168.21.88 | 9201 | rack3 | 20G |
| node3-2 | 192.168.21.88 | 9202 | rack3 | 20G |
| node3-3 | 192.168.21.88 | 9203 | rack3 | 20G |
| node4-1 | 192.168.21.89 | 9201 | rack4 | 20G |
| node4-2 | 192.168.21.89 | 9202 | rack4 | 20G |
| node4-3 | 192.168.21.89 | 9203 | rack4 | 20G |
但是报错日志中还是node8,这证明可能是上次宕机直接导致了副本文件不可用,无法进行reroute.
现在查看各节点的limits配置:
GET _nodes/stats/process?filter_path=**.max_file_descriptors
结果:
{
"nodes": {
"57A1rYqMRH-igOdlM9VyRg": {
"process": {
"max_file_descriptors": 655350
}
},
"if6AS6S-REKMOOVAp__xkg": {
"process": {
"max_file_descriptors": 655350
}
},
"Q4iPvXjvQkK6OImAHisHcw": {
"process": {
"max_file_descriptors": 655350
}
},
"VTqaCdj6TEGjDN5dlsygVw": {
"process": {
"max_file_descriptors": 655350
}
},
"u47KtJGgQw60T_xm9hmepw": {
"process": {
"max_file_descriptors": 655350
}
},
"Bpd3y--EQsag1u1NTmtZfA": {
"process": {
"max_file_descriptors": 655350
}
},
"i4oG4VcaSdKVeNEvStXwAw": {
"process": {
"max_file_descriptors": 655350
}
},
"pYKjqz0hS3aSs8sBuZbfFg": {
"process": {
"max_file_descriptors": 655350
}
},
"mSyzxBFFTRmLx4TWaPpJYg": {
"process": {
"max_file_descriptors": 655350
}
},
"8_cG1N_cSY-VfQLK-zVuhQ": {
"process": {
"max_file_descriptors": 655350
}
},
"JIKzocuZRtec_XkrM1eXDg": {
"process": {
"max_file_descriptors": 655350
}
},
"Ol6mvLtURTu5Ie6bX_gSdQ": {
"process": {
"max_file_descriptors": 655350
}
}
}
}
可以看到每个节点的max_file_descriptors都非常大,不太可能出现无法打开文件的错误,这只有一种可能,就是原来的副本分片数据存在问题,无法reroute。
副本无法reroute!!!
想了各种办法之后,决定用以下两种方式来解决:
方法一:我想到了将索引snapshot到文件系统,之后再restore 。
但是这个方案再尝试了一个索引之后放弃。因为elasticsearch的snapshot需要每个节点的snapshot目录通过NFS方式实现网络共享。也就是类似与windows的共享文件夹。这样来保证所有节点的备份都导出到同一个目录。这个方案被放弃的原因是nfs共享目录还没有建立,而且这个过程比较复杂。如果有更好的办法肯定放弃这个方案。
方法二:有没有一种简单的办法让索引重建?我查看了elasticsearch的官方文档。终于找到了reindex。对就是这个功能强大的reindex。
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-reindex.html
具体参数可参考上述链接。这个reindex不仅可以让本地索引重建,而且还可以以其他elasticsearch服务器为源重建索引。也就是说可以将其他集群的索引拷贝到目标集群。
补充:
方法三:还有一种更为快捷的办法,考虑到elasticsearch的分片的副本可以动态的设置,那么其实可以先将 number_of_replicas 设为0,待副本分片都删除之后,再将number_of_replicas改为1,这样副本分片就会自动恢复。同时,考虑到副本的优化情况,建议在做该操作的同时,做一次段合并。以节约空间和减少文件句柄数。
3.reindex解决过程
选择了目标索引
alarm-2017.08.12
POST /_reindex
{
"source": {
"index": "alarm-2017.08.12"
}
, "dest": {
"index": "alarm-2017.08.12.bak",
"version_type": "external"
}
}
响应结果
{
"took": 7143,
"timed_out": false,
"total": 1414,
"updated": 0,
"created": 1414,
"deleted": 0,
"batches": 2,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
再查看索引监控,发现索引重建成功,分片也正常。

现在只需要将原来的索引删除即可!
如果需要索引名与之前一致,则将现有索引增加一个别名即可。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index-aliases.html
DELETE alarm-2017.08.12
PUT alarm-2017.08.12.bak/_alias/alarm-2017.08.12
不难发现,在elasticsearch中并没有类似于mysql table那样直接可以修改表名的操作,这可能与elasticsearch的特殊结构有关系。reindex是一个非常重要的操作,在某些方面,甚至可能取代备份的snapshot。直接通过一个新的集群将数据copy。
4.修改number_of_replicas解决过程
选取目标索引
applog-prod-2016.12.18
可以看到存在分片未分配状况:
GET _cat/shards/applog-prod-2016.12.18*
applog-prod-2016.12.18 4 r STARTED 916460 666.4mb 192.168.21.24 node2-2
applog-prod-2016.12.18 4 p STARTED 916460 666.6mb 192.168.21.23 node1-3
applog-prod-2016.12.18 1 p STARTED 916295 672.8mb 192.168.21.88 node3-3
applog-prod-2016.12.18 1 r STARTED 916295 672.8mb 192.168.21.24 node2-3
applog-prod-2016.12.18 2 r STARTED 916730 670.9mb 192.168.21.89 node4-2
applog-prod-2016.12.18 2 p STARTED 916730 670.9mb 192.168.21.23 node1-3
applog-prod-2016.12.18 3 r STARTED 917570 674.9mb 192.168.21.23 node1-1
applog-prod-2016.12.18 3 p STARTED 917570 674.9mb 192.168.21.24 node2-2
applog-prod-2016.12.18 0 p STARTED 917656 673.5mb 192.168.21.88 node3-2
applog-prod-2016.12.18 0 r UNASSIGNED
现在修改number_of_replicas
PUT applog-prod-2016.12.18/_settings
{
"index":{
"number_of_replicas":0
}
}
可以看到number_of_replicas变成了0,分片只有1份
GET applog-prod-2016.12.18/_settings
{
"applog-prod-2016.12.18": {
"settings": {
"index": {
"refresh_interval": "5s",
"number_of_shards": "5",
"provided_name": "applog-prod-2016.12.18",
"creation_date": "1482019342621",
"number_of_replicas": "0",
"uuid": "hmZfjW80Q-SeV_qha_r-EA",
"version": {
"created": "5000199"
}
}
}
}
}
分片:
GET _cat/shards/applog-prod-2016.12.18*
applog-prod-2016.12.18 4 p STARTED 916460 666.6mb 192.168.21.23 node1-3
applog-prod-2016.12.18 1 p STARTED 916295 672.8mb 192.168.21.88 node3-3
applog-prod-2016.12.18 2 p STARTED 916730 670.9mb 192.168.21.23 node1-3
applog-prod-2016.12.18 3 p STARTED 917570 674.9mb 192.168.21.24 node2-2
applog-prod-2016.12.18 0 p STARTED 917656 673.5mb 192.168.21.88 node3-2
对段进行合并:
POST /applog-prod-2016.12.18/_forcemerge?max_num_segments=1
之后再将number_of_replicas改回来
PUT applog-prod-2016.12.18/_settings
{
"index":{
"number_of_replicas":1
}
}
分片情况:
GET _cat/shards/applog-prod-2016.12.18*
applog-prod-2016.12.18 4 r INITIALIZING 192.168.21.89 node4-1
applog-prod-2016.12.18 4 p STARTED 916460 666.6mb 192.168.21.23 node1-3
applog-prod-2016.12.18 1 p STARTED 916295 672.8mb 192.168.21.88 node3-3
applog-prod-2016.12.18 1 r INITIALIZING 192.168.21.89 node4-3
applog-prod-2016.12.18 2 r STARTED 916730 670.9mb 192.168.21.89 node4-1
applog-prod-2016.12.18 2 p STARTED 916730 670.9mb 192.168.21.23 node1-3
applog-prod-2016.12.18 3 r STARTED 917570 674.9mb 192.168.21.89 node4-3
applog-prod-2016.12.18 3 p STARTED 917570 674.9mb 192.168.21.24 node2-2
applog-prod-2016.12.18 0 p STARTED 917656 673.5mb 192.168.21.88 node3-2
applog-prod-2016.12.18 0 r INITIALIZING 192.168.21.89 node4-1
可以发现分片会被初始化,恢复到2个分片。
5.总结
对于索引出现Unassigned 的情况,最好的解决办法是reroute,如果不能reroute,则考虑重建分片,通过number_of_replicas的修改进行恢复。如果上述两种情况都不能恢复,则考虑reindex。