作者:Simon,腾讯后台开发高级工程师
WeTest导读
分布式系统理念渐渐成为了后台架构技术的重要选择,本文介绍了作者在手游领域对分布式系统进行的种种尝试,并在尝试中制定了对服务的定义、整体框架的构建以及服务内部拆分的流程。
前言
业务规模不断扩大,对稳定性、扩展性的要求不断提高,推动了后台架构技术的不断革新。面对日益复杂的需求,分布式系统的理念也逐渐深入到后台开发者的骨髓。2013年,借着手游热潮我对分布式系统开始尝试。在近三年的摸爬滚打中,踩过不少坑,也从业界技术发展中吸取一些经验,逐渐形成了目前的设计思路。这里和大家分享点心得,不敢奢谈有多大参考价值,权当抛砖引玉吧。
1. 失败的首次尝试
最初考虑使用分布式的出发点很简单:解决端游开发时单点结构导致容灾、扩容困难的问题。一种朴素的想法就是将相同功能的进程作为一个整体对外提供服务。这里简要描述下基本框架:
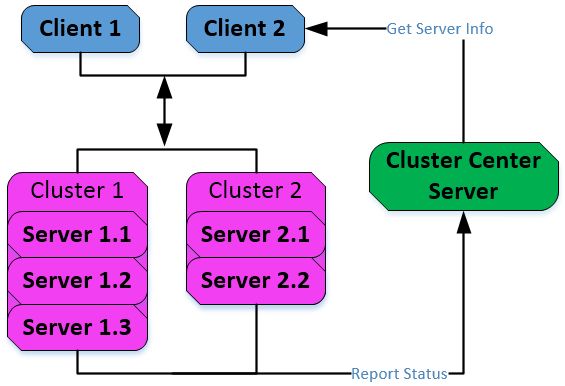
这种架构提供了三个基本组件:
Client API, 服务请求者API:
从 Cluster Center Server 获取服务提供者地址
向Server集群内所有实例注册,注册成功则认为可用
通过负载均衡算法,选择一个Server实例通信
检测Server集群内各实例的运行状态
Server API, 服务提供者API:
向 Cluster Center Server 上报自己的状态、访问地址等
接收 Client API 的注册,并提供服务
向已经注册成功的Client定时汇报状态
Cluster Center Server, 集群中心进程:
接收 Server Cluster 上报,确定服务集群的结构,以及各实例的状态
接收 Client Cluster 的请求,返回可用服务集群列表
这种架构具备了集群的基本雏形,可以满足容灾扩容的基本需求,大家应该也发现不少问题,我这里总结几点:
1. 服务发现的蹩脚实现
Cluster Center Server 的实现是单点,出现故障时Client请求会异常;没有提供监控机制,Client只能通过定时请求来获取服务的最新状况。
2. CS采用Request/Response的通信方式不灵活
现实应用中,服务往往存在相互请求,一应一答远远不够,全双工 是必须要支持的。
3. 有瑕疵的保活机制
Server对Client定期单边心跳,有两个问题:不同Client对保活要求可能不同,有些5s,有些可能1s,如果心跳发起全部在Server,无法满足差异化要求;服务端作为被动方,承担监控请求者存活的责任不明智。
4. 架构设计的层次不清晰
对架构的层次、模块划分没有作出很好的规划,比如通信底层、服务发现、集群探测与保活等等没有清晰定义接口,导致相互耦合,替换、维护较为困难。
2. 看看外面的世界
上述问题,归根结底还是眼界狭窄,自己闷头造轮子没跟上业界技术发展的步伐。近几年微服务架构发展迅速,相比传统面向服务架构不再过分强调企业服务总线,而是深入到单个业务系统内部的组件化。这里我介绍下自己的调研结果。
2.1 服务协同
服务协同是分布式系统一个核心组成部分,概述为:多个进程节点作为整体对外提供服务,服务可以相互发现,服务关注者可以及时获取被关注者的变化以完成协作。具体运行过程包括:服务注册 和 服务发现。在实现上涉及以下方面:
统一命名 对服务以及其中的节点,进行集中式、统一命名,便于相互区分和访问。
监控 确定服务的可用性和状态,当服务状态变化时,关注者要有途径获知。
访问策略 服务通常包含多个节点,以集群形式存在,Client在每次请求时需要策略确定通信节点,策略目标可能是多样的,比如 负载均衡 ,稳定映射 等等。
可用性 容灾处理,动态扩容。
业界中较为成熟的实现如下表所示:

2.2 消息中间件
亦称消息队列,在分布式系统广泛使用,在需要进行网络通信的节点间建立通道,高效可靠地进行平台无关的数据交流。架构上主要分为两种:Broker-Based(代理),和 Brokerless(无代理)。前者需要部署一个消息转发的中间层,提供二次处理和可靠性保证。后者轻量级,直接在内嵌在通信节点上。业界较为成熟的实现如下表所示:

2.3 通信协议数据格式
服务间通信,需要将数据结构/对象和传输过程中的二进制流做相互转化,一般称为 序列化/反序列化 。不同编程语言或应用场景,对数据结构/对象的定义和实现是不同的。在选择时需要考虑以下方面:
通用性 是否支持跨平台、跨语言;业界是否广泛流行或者支持
可读性 文本流有天然优势,纯粹二进制流如果没有便捷可视化工具,调试将会异常痛苦
性能 空间开销——存储空间的占用;时间开销——序列化/反序列化的快慢
可扩展性 业务的不变之道就是——一直在变,必须具有处理新旧数据之间的兼容性的能力
实现 序列化/反序列化 的组件一般包含:IDL(Interface Description Language), IDL Compiler, Stub/Skeleton。业界目前比较流行的序列化协议有:XML, JSON, ProtoBuf, Thrift, Avro等。关于这几种协议的实现以及比较,可以参考文章 《序列化和反序列化》。这里将原文中的选型结论摘录给大家:
允许高延迟比如100ms以上,内容变更频繁,且复杂的业务,可以考虑基于XML的SOAP协议。
基于Web browser的Ajax,以及Mobile app与服务端之间的通讯;对于性能要求不太高,或者以动态类型语言为主的场景,JSON可以考虑。
对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro都差不多。
对于Terabyte级别数据持久化应用场景,Protobuf和Avro是首要选择。持久化后的数据若存储在Hadoop子项目里,或以动态类型语言为主,Avro会是更好的选择;非Hadoop项目,以静态类型语言为主,首选Protobuf。
不想造 RPC 的轮子,Thrift可以考虑。
如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf可以优先考虑。
3. 重整旗鼓
调研周边后,2015年开搞第二款手游,吸取之前的教训,这次设计的基本原则是:
系统拆分、解耦,清晰定义系统间接口,隐藏系统内部实现
大框架尽可能通用,子系统可在不同场景替换
下面首先对服务定义,然后介绍整体框架和服务内部拆分。
3.1 服务定义
举个手游的例子,看图说话:

Service Cluster 服务集群,由功能相同的实例组成,作为整体对外服务,是一个集合。比如 Lobby 提供大厅服务,Battle 提供战斗服务,Club 提供工会服务,Trade 提供交易服务。
Service Instance 服务实例,提供某种服务功能的最细粒度,以进程形式存在。比如Club 集群中有两个实例 3.2.6.1 和 3.2.6.2 ,功能一致。
Service Node 服务节点,是服务发现组件管理的基本单元,可以是集群、实例、层次关系或者业务关心的含义。
Service Key 服务节点的Key,全局唯一的身份标记。key的设计需要能够体现出层级关系,至少要能够体现出 Cluster 和 Instance 的包含关系。etcd和zookeeper均支持key层次化的组织关系,类似文件系统的树形结构。etcd有mkdir直接建立目录,zookeeper则通过路径描述父子关系。但不管怎么都可以在概念层次使用路径结构。
上图中,Service Instance 完整路径可描述为:/AppID/Area/Platform/WorldID/GroupID/ClusterName/InstanceName。有以下特点:
集群路径一定是其中各个实例的父路径
从功能完整性而言,集群是服务的基本粒度
相同功能的集群在不同前缀路径下含义不同,服务目标也可以不同,比如:
/Example/wechat/android/w_1/g_1/Lobby 和/Example/wechat/android/w_3/g_2/Lobby 功能上均表示大厅服务,但一个为大区1分组1服务,一个为大区3分组2服务
3.2 服务发现基本流程

先抽象几个基本操作,不同服务发现组件的API可能略有差异,但应该有对应功能:
Create 在服务发现组件中创建 Key 对应的 Service Node,指定全局唯一的标记。
Delete 在服务发现组件中删除 Key 对应的节点。
Set 设置 Key 对应的 Value, 安全访问策略或者节点基础属性等。
Get 根据 Key 获取对应节点的数据,如果是父节点可以获取其子节点列表。
Watch 对节点设置监视器,当该节点自身,以及嵌套子节点数据发生变更时,服务发现组件将变更事件主动通知给监视者。
Service Instance每次在启动时,按照下面的流程处理:
生成自己的 Service Path,注意这是服务实例的路径。
以 Service Path 为key,通过 Create 方法生成节点,Set 数据:对外开放的地址、安全访问策略等。
生成需要访问的服务集群的 Service Path,通过 Get 方法获取集群数据,如果找不到说明该服务不存在;如果可以找到分两种情况:
该路径下没有子节点。说明当前不存在可用的服务实例,对集群路径设置watcher,等待新的可用实例。
该路径下有子节点。那么 Get 所有子节点列表,并进一步 Get 子节点访问方式和其它数据。同时设置 watcher 到集群路径,检测集群是否存在变化,比如新增或减少实例等。
Service Instance在关闭时,按照下面的流程处理:
通过 Delete 方法删除自己对应的节点。有些服务发现组件可以在实例生命周期结束时自行删除,比如zookeeper的临时节点。对于etcd的目录,或者zookeeper的父路径,如果非空,是无法删除的。
根据上面的抽象可以定义 服务发现 的基本接口,接口的具体实现可以针对不同的组件开发不同的wrapper,但可以和业务解耦。
3.3 服务架构
所有的架构归根结底还是需要具体到进程层次实现的。目前我们项目开发的分布式架构组件称之为 DMS(Distributed Messaging System),以 DMS Library 的形式提供,集成该库即可实现面向服务的分布式通信。下面是 DMS 设计的总体结构:


关于Serialize/DeSerialize, APP业务的选择自由度较高,下面介绍其它Layer的具体实现:
3.3.1 Message Middleware
消息中间件前面介绍有很多选择。DMS 使用的是 ZeroMQ,出发点是:轻量级、性能强大、偏底层所以灵活而且可控性较高。由此带来的成本是,高级应用场景需要做不少二次开发,而且长达80多页的资料也需要不少时间。介绍ZeroMQ的文章太多,这里不打算科普,所以直接给出设计方案。
通信模式的选择
ZeroMQ的Socket有多种类型,不同组合可以形成不同的通信模式,列举几种常见的:
REQ/REP 一应一答,有请求必须等待回应
PUB/SUB 发布订阅
PUSH/PULL 流水线式处理,上游推数据,下游拉数据
DEALER/ROUTER 全双工异步通信
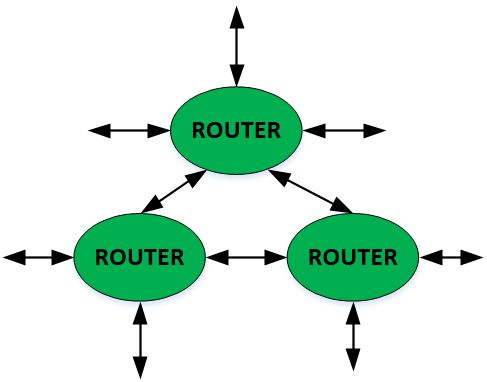
看到这里,大家可能会觉得选择PUB/SUB和DEALER/ROUTER应该可以满足绝大部分应用场景吧。实际上DMS只使用了一种socket类型,那就是ROUTER,通信模式只有一种ROUTER/ROUTER。一种socket,一种通信模式,听起来很简单,但真可以满足要求吗?
DEALER/ROUTER 是传统异步模式,一方connect,一方bind。前端如果要连接多个后端就得建立多个socket。在前面描述的集群服务模式下,一个节点既会作为Client也会作为Server,会有多条入边(被动接收连接)和出边(主动发起连接)。这正好就是路由的概念,一个ROUTER socket可以建立多条通路,并对每条通路发送或者接收消息。
PUB/SUB 注重的是扩展性和规模,按照ZeroMQ作者的意思当每秒钟需要向上千的节点广播百万条消息时,你应该考虑使用 PUB/SUB 。好吧,可预见的将来业务规模恐怕还到达不到这种程度,现在先把简单放在第一位吧。
3.3.2 DMS Protocol
消息结构
DMS的协议实现集群管理,消息转发等基本功能。ZeroMQ的消息可以由 Frame 组成,一个Frame可以为空也可以是一段字节流,一个完整的消息可以包含多个Frame,称为Multipart Message。基于这种特点,在DMS定义协议,可以将内容拆分为不同的基本单元,每个单元用一个Frame描述,通过单元组合表示不同的含义。这与传统方式:一条协议就是一个结构体,不同单元组合需要定义为一个结构体的方式相比更加灵活。
下面来看看DMS Protocol的基本组成。首帧一定是对端ID。对端接收后也一定会获取信息发送端的ID。第二帧包含DMS控制信息。第三、第四帧等全部是业务自定义的传输信息,仅对REQ-REP有效:

PIDF有两层含义:所在服务集群的标记,自身的实例标记。这些标记与Service Discovery关于节点key的定义保持一致,有两种形式 字符串 与 整型,前者可读方便理解,后者是前者的Hash,提高传输效率。使用伪代码来描述PIDF,大概是下面的样子:

PIDF中的 ClusterID 和 InstanceID 各种取值,会有不同的通信行为:

在连接首次建立时,还需要将可读的服务路径传输给对端:

协议命令字
DMS协议全部在每个消息的第二帧即Control Frame中实现。命令字定义为:

通信流程——建立连接

通过Service Discovery找到server后不要立即连接,而是发送探测包。原因有以下几点:
服务发现虽然可以反映节点是否存活,但一般有延迟,所以从服务发现获取的节点仅仅是候选节点。
网络底层机制差异较大,有些基于连接,比如raw socket,有些没有连接,比如shared memory。最好在高层协议中解决连接是否成功。这就好比声纳,投石问路,有回应说明可以连接,没有回应说明目前连接不可用。
通信流程——业务消息发送

普通消息 若 PIDF 表示对端实例和当前进程直接连接,那么发送消息
路由消息 若 PIDF 表示对端实例和当前进程没有直接连接,那么可以通过直连的实例转发。路由机制 后文会介绍
广播消息 若 PIDF InstanceID为负数,则向指定集群内所有实例广播
路由 和 广播 是可以混合使用的。上述过程 DMS 自动完成,业务不必参与,但可以截获干预。
通信流程——保活机制
建立连接后,请求者会持续按照自己的间隔向服务者发送探测包。如果请求者连续若干次没有收到服务者的PONG回包,则请求者认为与服务者的连接已经断开。
如果服务者收到请求者的任何数据包,认为请求者存活,如果超出一定时间没有收到(含PING),则认为请求者掉线。这个超时时间包含在READY协议中,由请求者告知服务者。
通信流程——连接断开
任何一方收到 DISCONNECT 后,即认为对方主动断开连接,不要再主动向对方进行任何形式的通信。
3.3.3 DMS Kernel
下面介绍 DMS Kernel 如何根据 DMS Protocol 实现相关逻辑,并如何与业务交互。

SERVICE MANAGER
self 确定自身 服务路径,实现服务注册,以及与目标通信链路的注册,供路由表使用
targets 获取并监控目标服务的数据以及运行状态
ACL 访问控制管理
对服务发现层接口进行封装,不同的 SERVICE DISCOVERY 功能可能有所不同
ROUTER MANAGER

每个服务实例在主动成功连接对端服务后,通过 SERVICE MANAGER 将连接以边的形式写入到 SERVICE DISCOVERY 中,这样就会以 邻接边 的形式生成一张完整的图结构,也就是routing table。比如: Service 1 和 Service 2,Service 3,Service 4 均有连接,那么将边(1,2),(1,3),(1,4) 记录下来。SERVICE DISCOVERY 关于路由邻接链表的记录可以使用公共的key,比如: /AppID/Area/Platform/routing_table 。然后所有的服务实例都可以更新、访问该路径以便获得一致的路由表。基础功能有两个:
Updater 用于向路由表中添加边,删除边,设置边的属性(比如权重),并对边的变化进行监控
Calculator 根据邻接边形成的 图结构 计算路由,出发点是当前实例,给定目标点判断目标是否可达,如果可达确定路径并传输给下一个节点转发。默认选择 Dijkstra 算法,业务可以定制。
CONNECTION MANAGER
管理 Frontends 即前端请求进入的连接,和 Backends 即向后端主动发起的连接。Backends的目标来源于 Service Manager。
Sentinel 对前端发起的连接,通过 READY 协议,可以获取该连接的失活标准,并通过前端主动包来判断进入连接是否存活。如果失活,将该连接置为断开状态,不再向对应前端主动发包。
Prober 对后端服务进行连接建立和连接保活。
Dispatcher 消息发送时用于确定通信对端实例。连接是基于实例的,但是业务一般都是面向服务集群的,所以Dispathcer 需要实现一定的分配机制,将消息转发给 服务集群中的某个 具体实例 。注意这里仅只存在直接连接的单播。分配时应考虑 负载均衡 默认使用一致性哈希算法,业务完全可以根据具体应用场景自定义。
3.3.4 DMS Interface
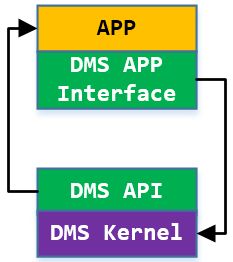
DMS API 是DMS对业务提供的服务接口,可以管理服务、通信等基本功能;
DMS APP Interface 是DMS要求业务必须实现的接口比如:Dispatcher 的负载均衡策略,对端服务状态变化通知,以及业务自定义 路由算法 等等。
3.4 应用场景
下面罗列DMS三大类典型应用场景,其它场景应该可以通过这三个例子组合实现:
无Broker通信

最基础的通信方式——两个集群之间的 Instance 全连接,适合服务数量不多、逻辑不复杂的简单业务。
Broker通信

对于一个内部聚合的子系统,可能包含N个服务,这些服务之间相互存在较强的交互行为。如果使用无Broker模式可能有两个问题:链路过多:通信层的内存占用较大;运维维护困难;服务没有解耦,直接依赖于对端的存在;
这时Broker集群可以承担消息中转的作用,而且可以完成一些集中式逻辑处理。注意这里Broker只是一个名字,通过 DMS Library 可以直接实现。
Broker级联通信

多个子系统相互通信,估计没有设计者愿意把内部细节完全暴露给对方,这时两个Broker集群就相当于门户:首先可以实现内部子系统相互通信,以及集中逻辑;其次,可以作为所处子系统的对外接口,屏蔽细节。这样不同子系统只需通过各自的Broker集群对外提供服务即可。
总结
本文主要介绍了 DMS 的几个基础结构:服务发现、消息中间件以及通信架构。基本思想是:框架分层、层级之间接口清晰定义,以便在不同场景下使用不同的具体实现进行替换。其中 zookeeper,ZeroMQ 只是举例说明当前的一种实现方式,在不同场景下可以选择不同组件,只要满足接口即可。