Python数据结构与算法:常见数据结构与复杂度分析
注:数据结构与算法使用Python语言实现,涉及基本数据结构、十大排序算法、递归分治、贪心动归等,意在帮大家更加容易的学习数据结构与算法以及进一步梳理这些知识点。
Python数据结构与算法前文可参考:
Python数据结构与算法(一):引言
目录
一、线性结构
1.顺序存储:数组
2.链式存储:链表
3.线性结构对比
4.队列
6.栈
二、树形结构
1.二叉树
2.二叉树的特点
3.特殊二叉树
4.二叉树的性质
5.二叉树的存储结构
6.二叉树的遍历
三、图形结构
1.图
2.图的存储结构
3.图的遍历
4.图的基本问题
四、集合结构
1.HashMap
2.HashSet
五、算法的复杂度分析
1.算法的时间复杂度
2.常见时间复杂度
3.时间复杂度计算方法
4.算法的空间复杂度
5.空间复杂度计算方法
六、实例分析
1.斐波那契数列
2.两数之和
一、线性结构
1.顺序存储:数组
线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。物理上的存储方式事实上就是在内存中找个初始地址,然后通过占位的形式,把一定的内存空间给占了,然后把相同数据类型的数据元素依次放在这块空地中。

顺序表的加入操作:
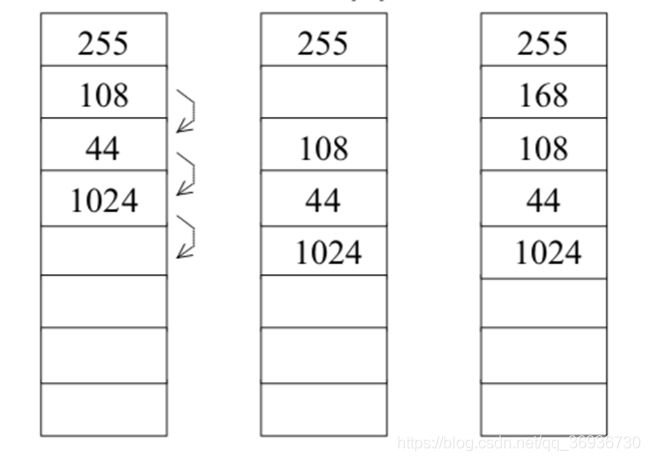
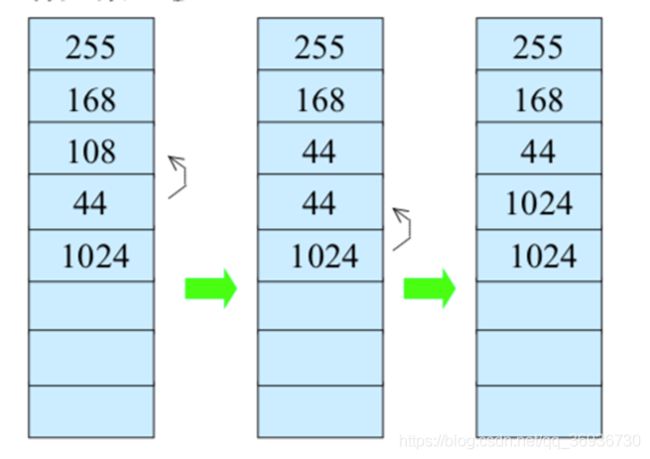
顺序表的删除操作:
2.链式存储:链表
单链表:
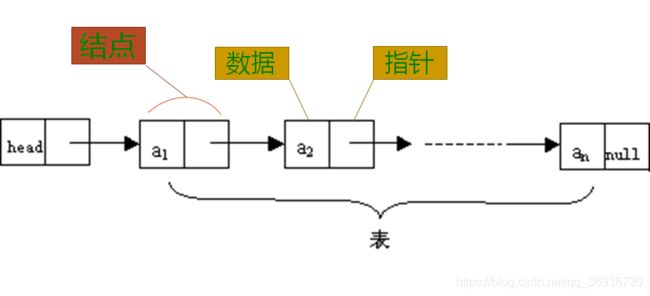
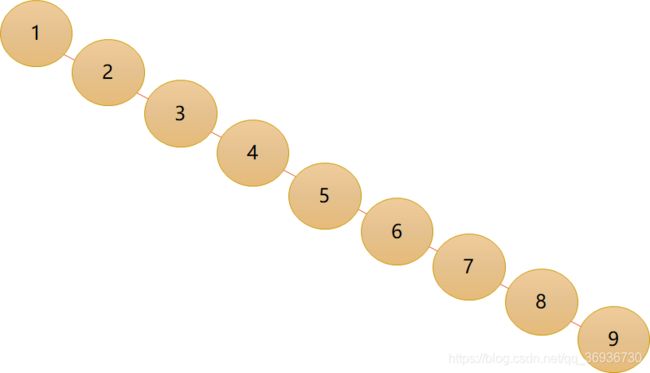
对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中的第一个结点的存储位置叫做头指针,最后一个结点指针为空(NULL)。
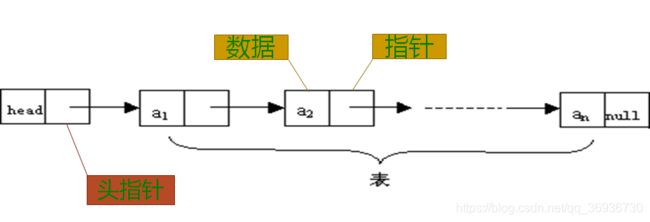
头指针与头结点的异同:头结点是为了操作的统一和方便而设立的,放在第一个元素的结点之前,其数据域一般无意义(但也可以用来存放链表的长度)。有了头结点,对在第一元素结点前插入结点和删除第一结点起操作与其它结点的操作就统一了。头结点不一定是链表的必须要素。
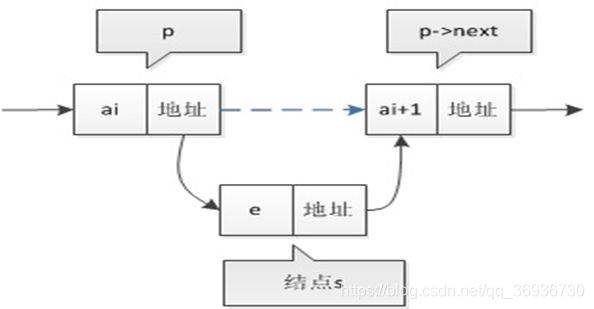
单链表的插入:
单链表的插入根本用不着惊动其他结点,只需要让s.next和p.next的指针做一点改变。
s.next = p.next;
p.next = s;
我们通过图片来解读一下这两句代码。
单链表的删除
现在我们再来看单链表的删除操作。
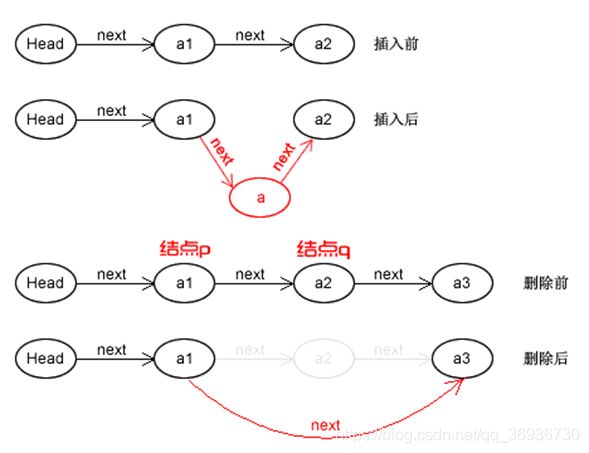
双向链表的插入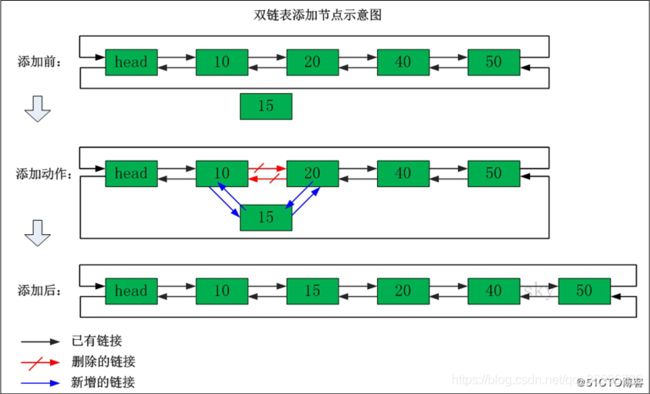
双向链表的删除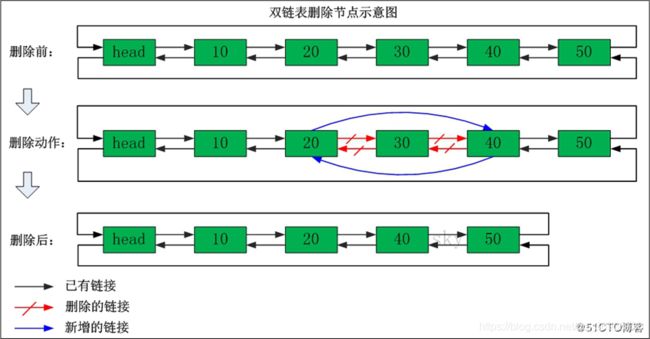
3.线性结构对比
单链表结构与顺序存储结构优缺点:我们分别从存储分配方式、时间性能、空间性能三方面来做对比。
- 存储分配方式:
- 时间性能:
- 空间性能:
- 综上所述对比,我们得出一些经验性的结论:
4.队列
队列的定义:
- 队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
- 队列是一种先进先出(First In First Out, FIFO)的线性表。
- 队列也是一种重要的线性结构,我们可以利用python的列表轻松模拟一个队列,或者使用python自带的队列。

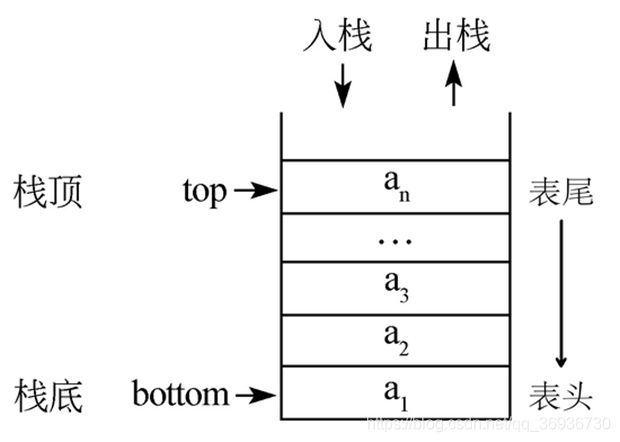
6.栈
栈是一种重要的线性结构,可以这样讲,栈是前面讲过的线性表的一种具体形式。就像我们刚才的例子,栈这种后进先出的数据结构应用是非常广泛的。在生活中,例如我们的浏览器,每点击一次“后退”都是退回到最近的一次浏览网页。例如我们Word,Photoshop等的“撤销”功能也是如此。栈的本质是一个线性表,所以我们可以轻松的用python的列表来模拟一个栈。
最开始栈中不含有任何数据,叫做空栈,此时栈顶就是栈底。然后数据从栈顶进入,栈顶栈底分离,整个栈的当前容量变大。数据出栈时从栈顶弹出,栈顶下移,整个栈的当前容量变小。
二、树形结构
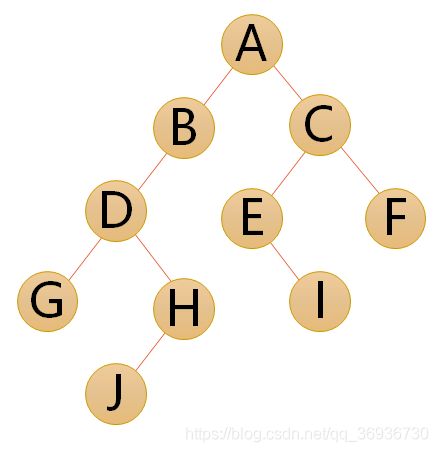
1.二叉树
定义:二叉树(Binary Tree)是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成。
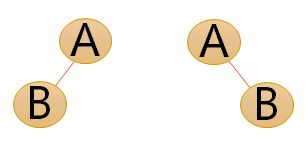
2.二叉树的特点
- 每个结点最多有两棵子树。(注意:不是都需要两棵子树,而是最多可以是两棵,没有子树或者有一棵子树也都是可以的。)
- 左子树和右子树是有顺序的,次序不能颠倒。
- 即使树中某结点只有一棵子树,也要区分它是左子树还是右子树,下面是完全不同的二叉树:
节点:
二叉树中每个元素都称为节点。
度:
二叉树的度表示节点的子树或直接继承者的数目,二叉树的每一个节点最大度数为2,最小度数为0。
叶子:
叶是叶节点的缩写。叶节点是树的底部的节点,叶节点不具有子节点。
3.特殊二叉树
- 满二叉树:在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
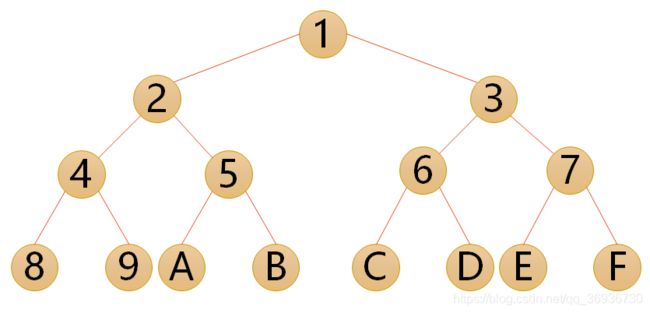
满二叉树的特点有:
- 叶子只能出现在最下一层。
- 非叶子结点的度一定是2。
- 在同样深度的二叉树中,满二叉树的结点个数一定最多,同时叶子也是最多。
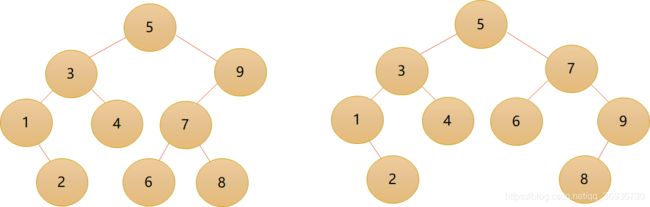
- 完全二叉树:对一棵具有n个结点的二叉树按层序编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点位置完全相同。
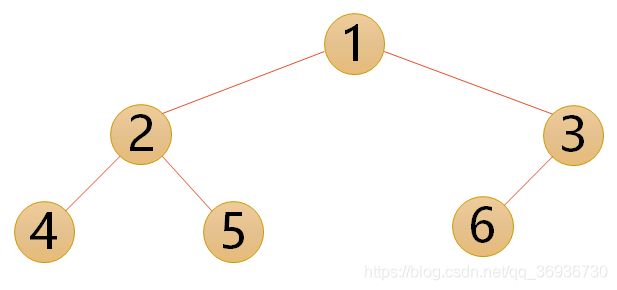
完全二叉树的特点有:
- 叶子结点只能出现在最下两层。
- 最下层的叶子一定集中在左部连续位置。
- 倒数第二层,若有叶子结点,一定都在右部连续位置。
- 如果结点度为1,则该结点只有左孩子。
- 同样结点树的二叉树,完全二叉树的深度最小。
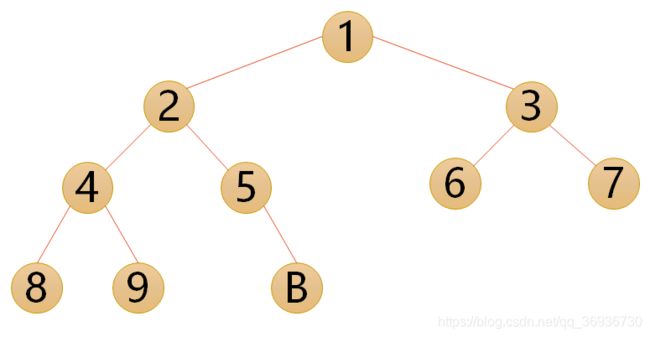
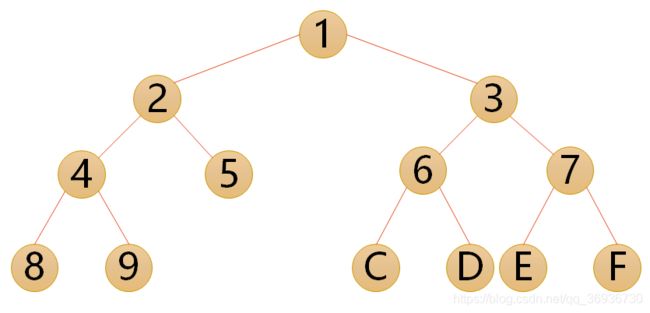
注意:满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
以下这些都不是完全二叉树:
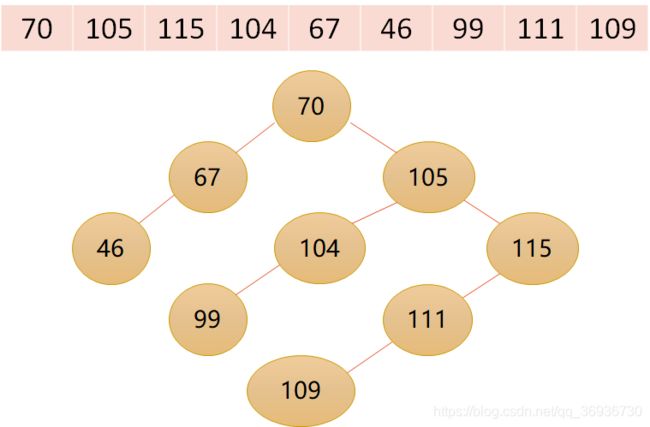
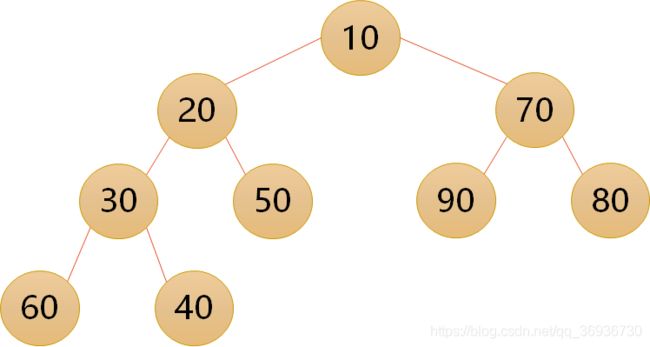
- 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树:
- 若它的左子树不为空,则左子树上所有结点的值均小于它的根节点的值;
- 若它的右子树不为空,则右子树上所有结点的值均大于它的根结构的值;
- 它的左、右子树也分别为二叉排序树(递归定义)。
二叉排序树:
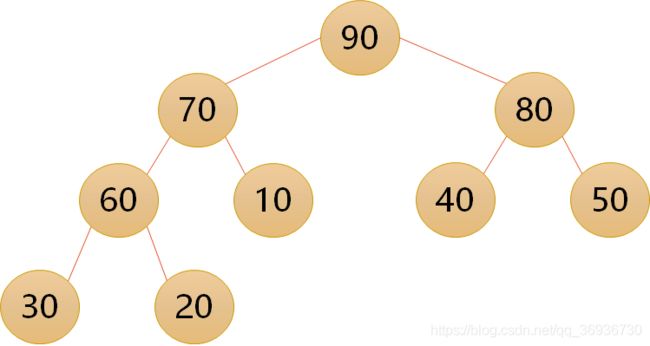
- 平衡二叉树(Balanced Binary Tree)是二叉排序树的一个进化体。1962年,G.M. Adelson-Velsky 和 E.M. Landis发明了这棵树,所以它又叫AVL树。平衡二叉树要求对于每一个节点来说,它的左右子树的高度之差不能超过1,如果插入或者删除一个节点使得高度之差大于1,就要进行节点之间的旋转,将二叉树重新维持在一个平衡状态。这个方案很好的解决了二叉查找树退化成链表的问题
- 堆:根结点一定是堆中所有结点最大或者最小者。大顶堆:堆是一个类似完全二叉树的结构,并同时满足堆积的性质:即子结点的值总是小于(或者大于)它的父节点。
4.二叉树的性质
- 二叉树的性质一:在二叉树的第i层上至多有2^(i-1)个结点(i>=1)
- 二叉树的性质二:深度(二叉树层数)为k的二叉树至多有2^k - 1个结点(k>=1)
- 二叉树的性质三:对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1
- 二叉树的性质三:对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1
- 二叉树的性质四:具有n个结点的完全二叉树的深度为⌊log₂n⌋+1
- 二叉树的性质五:如果对一棵有n个结点的完全二叉树(其深度为⌊log₂n⌋+1)的结点按层序编号,对任一结点i(1<=i<=n)有以下性质
5.二叉树的存储结构
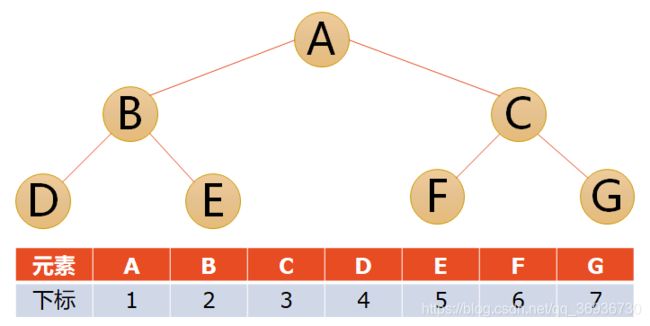
这下凸显完全二叉树的优越性了,由于他的严格定义,在数组直接能表现出逻辑结构。
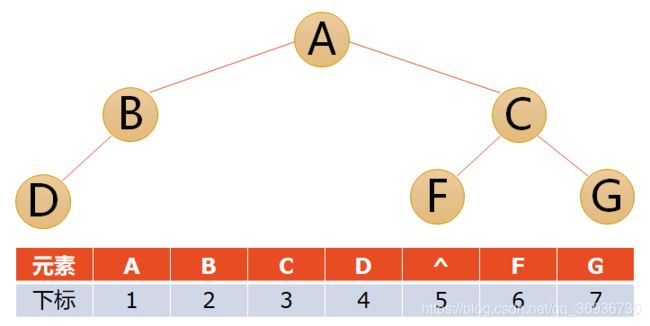
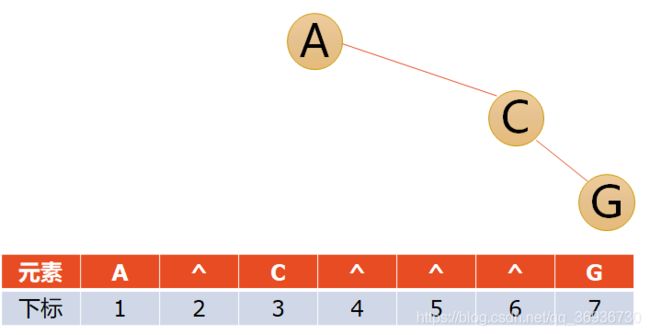
对于一般的二叉树,也可以借鉴完全二叉树的处理方式,把不存在的结点用“^”代替即可。但是考虑到一种极端的情况,回顾一下斜树,如果是一个又斜树,那么会变成这样
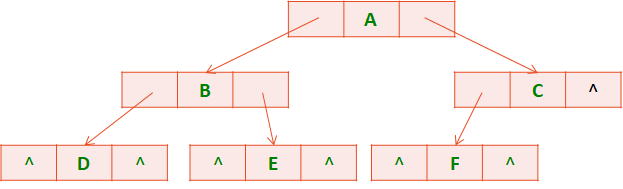
class Node(object):
def __init__(self, data):
self.data = data
self.lchild = None
self.rchild = None
6.二叉树的遍历
二叉树的遍历(traversing binary tree)是指从根结点出发,按照某种次序依次访问二叉树中所有结点,使得每个结点被访问一次且仅被访问一次。
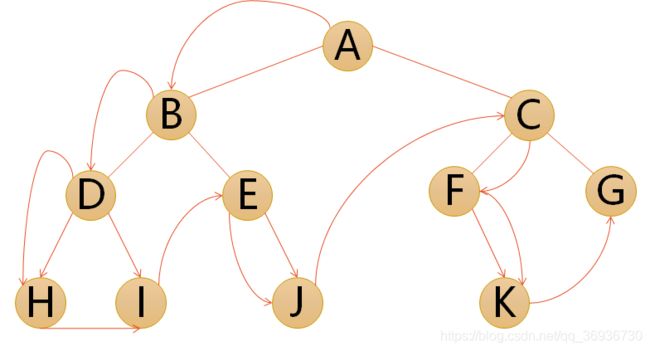
- 前序遍历:若二叉树为空,则空操作返回,否则先访问根结点,然后前序遍历左子树,再前序遍历右子树。
遍历的顺序为:ABDHIEJCFKG
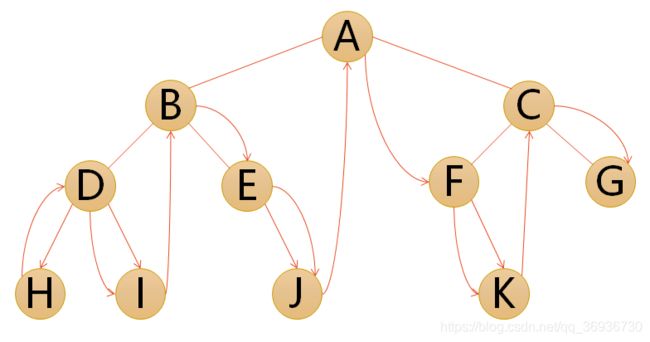
- 中序遍历:若树为空,则空操作返回,否则从根结点开始(注意并不是先访问根结点),中序遍历根结点的左子树,然后是访问根结点,最后中序遍历右子树。
遍历的顺序为:HDIBEJAFKCG
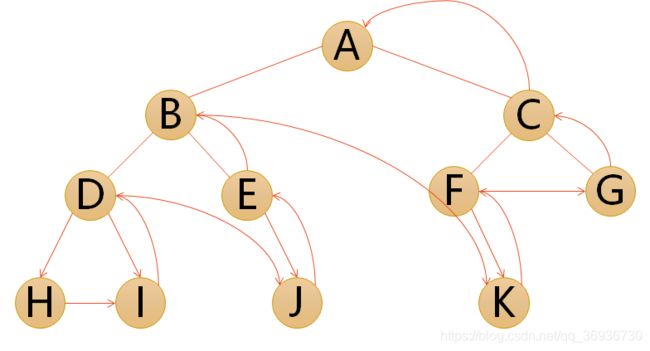
- 后序遍历:若树为空,则空操作返回,否则从左到右先叶子后结点的方式遍历访问左右子树,最后访问根结点
遍历的顺序为:HIDJEBKFGCA
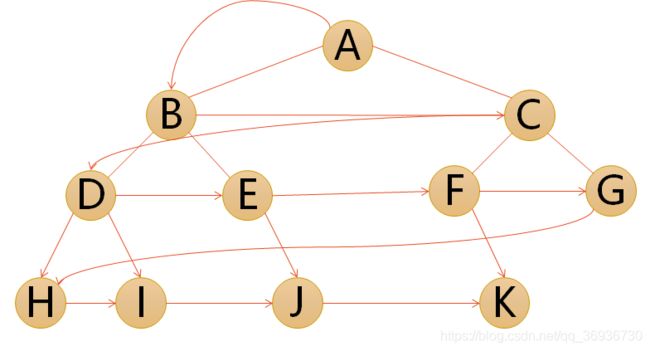
- 层序遍历:若树为空,则空操作返回,否则从树的第一层,也就是根结点开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问。
遍历的顺序为:ABCDEFGHIJK
三、图形结构
1.图
在前边讲解的线性表中,每个元素之间只有一个直接前驱和一个直接后继。在树形结构中,数据元素之间是层次关系,并且每一层上的数据元素可能和下一层中多个元素相关,但只能和上一层中一个元素相关。但这仅仅都只是一对一,一对多的简单模型,如果要研究如人与人之间关系就非常复杂了。图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
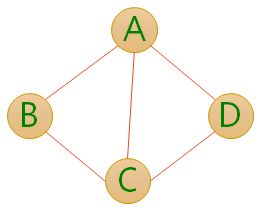
- 无向边:若顶点Vi到Vj之间的边没有方向,则称这条边为无向边(Edge),用无序偶(Vi,Vj)来表示。
上图G1是一个无向图,G1={V1,E1},其中V1={A,B,C,D},E1={(A,B),(B,C),(C,D),(D,A),(A,C)}
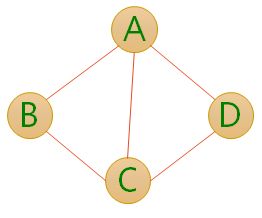
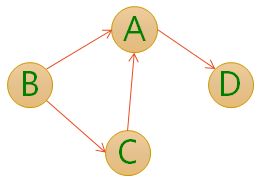
- 有向边:若从顶点Vi到Vj的边有方向,则称这条边为有向边,也成为弧(Arc),用有序偶<Vi,Vj>来表示,Vi称为弧尾,Vj称为弧头。
上图G2是一个无向图,G2={V2,E2},其中V2={A,B,C,D},E2={
对于无向图G=(V,E),如果边(V1,V2)∈E,则称顶点V1和V2互为邻接点(Adjacent),即V1和V2相邻接。边(V1,V2)依附(incident)于顶点V1和V2,或者说边(V1,V2)与顶点V1和V2相关联。顶点V的度(Degree)是和V相关联的边的数目,记为TD(V),如下图,顶点A与B互为邻接点,边(A,B)依附于顶点A与B上,顶点A的度为3。
对于有向图G=(V,E),如果有
2.图的存储结构
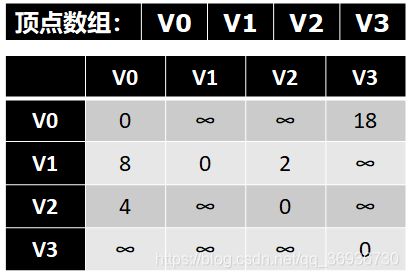
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
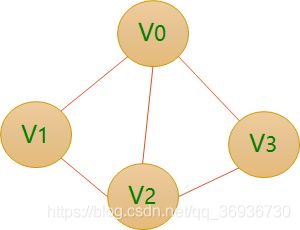
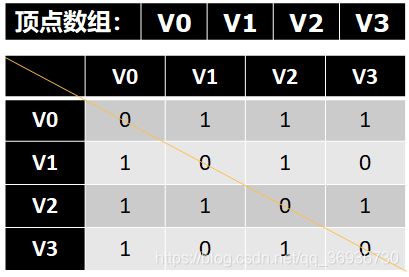
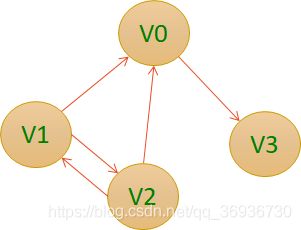
有了这个二维数组组成的对称矩阵,我们就可以很容易地知道图中的信息:要判定任意两顶点是否有边无边就非常容易了;要知道某个顶点的度,其实就是这个顶点Vi在邻接矩阵中第i行(或第i列)的元素之和;求顶点Vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点咯。
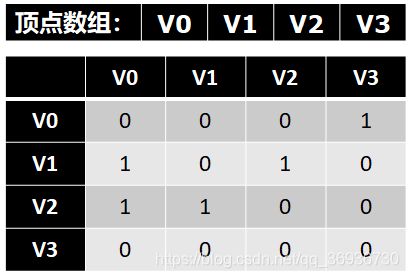
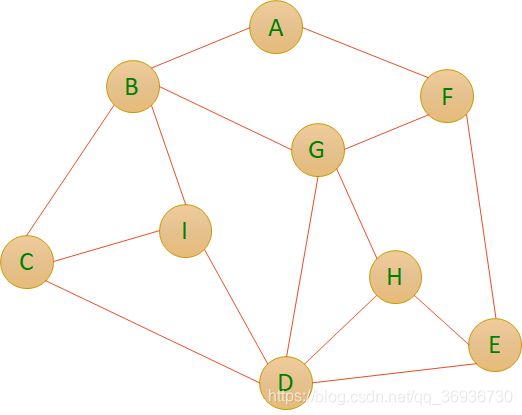
3.图的遍历
深度优先遍历(从顶点G开始):

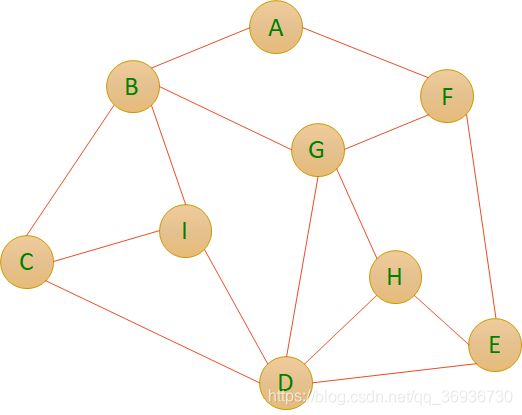
广度优先遍历(从顶点G先开始):

4.图的基本问题
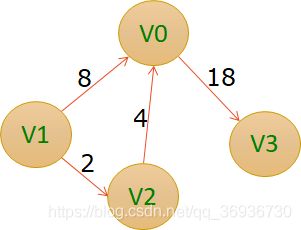
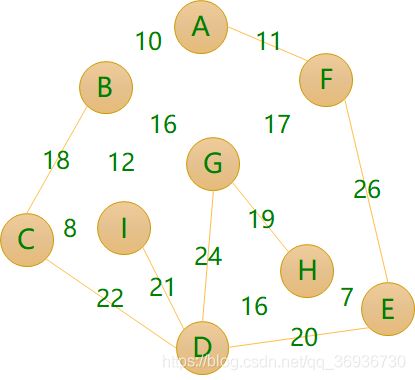
无向带权图的最小生成树问题:在保证任意两个顶点之间都有路径到达的前提下,所使用的边的个数最少(也即不能有环)且权值之和最小。城市抽象成顶点,道路抽象成边在预算极其有限的情况下,要保证所有城市都能有路径到达,且修路总花费最小
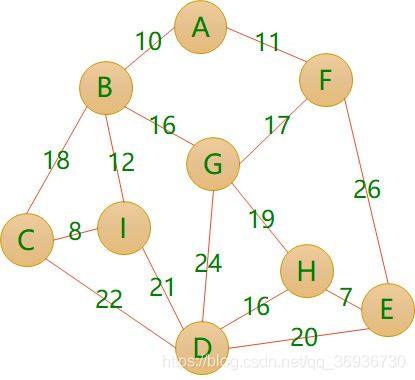
方案一:▪成本:11+26+20+22+18+21+24+19=161
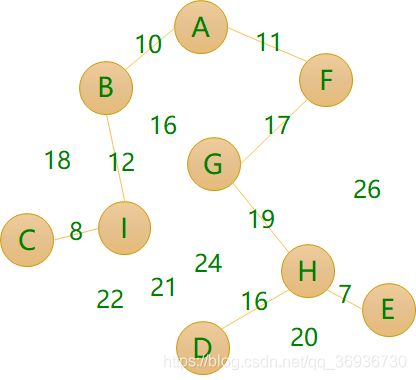
方案二▪成本:8+12+10+11+17+19+16+7=100
方案三▪成本:8+12+10+11+16+19+16+7=99
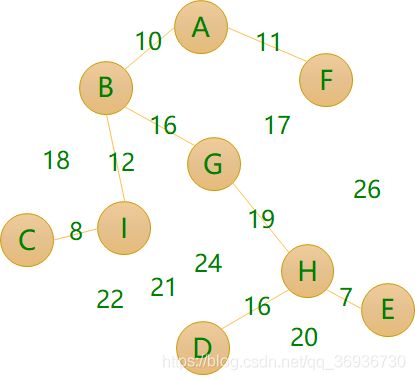
无向带权图最小生成树解决办法:
- 普里姆(Prim)算法
- 克鲁斯卡尔(Kruskal)算法
最短路径问题:
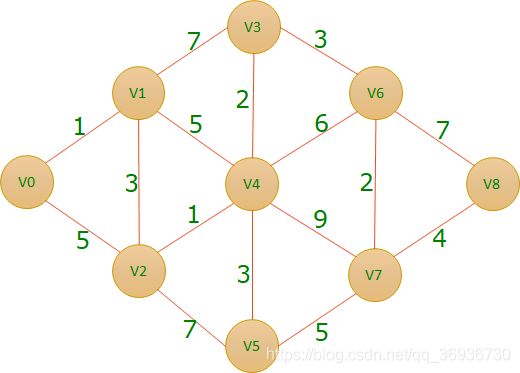
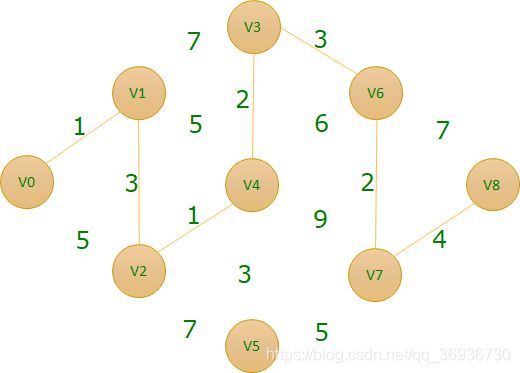
最短路径问题:在网图(带权图)和非网图中,最短路径的含义是不同的。网图是两顶点经过的边上权值之和最少的路径。非网图是两顶点之间经过的边数最少的路径。我们把路径起始的第一个顶点称为源点,最后一个顶点称为终点。关于最短路径的算法,最常见两种:
- 迪杰斯特拉算法(Dijkstra)
- 弗洛伊德算法(Floyd)
四、集合结构
1.HashMap
我们要在a[]中查找key关键字的记录:
- 顺序表查找:挨个儿比较
- 有序表查找:二分法查找
- 散列表查找:?
2.HashSet

f(张三丰) = 图书馆
除留余数法:此方法为最常用的构造散列函数方法,对于散列表长为m的散列函数计算公式为:f(key) = key mod p(p<=m)
例:假设关键字集合为{12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34},同样使用除留余数法求散列表。
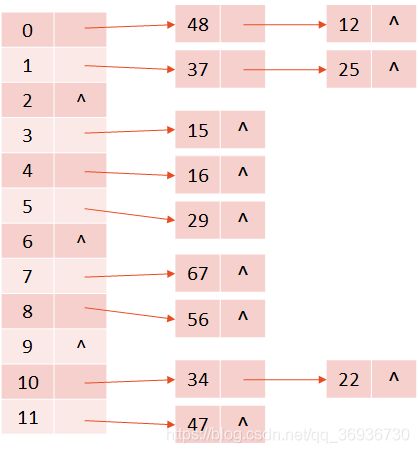
HashMap 存储的是key,value的数据;HashSet 存储的是key数据,可以理解为(key,key)形式的HashMap就是HashSet,且HashSet要求所存储的元素不允许有重复,HashSet的实现方法与HashMap完全一样。
五、算法的复杂度分析
1.算法的时间复杂度
我们提到设计算法要尽量的提高效率,这里效率高一般指的是算法的执行时间。那么我们如何来度量一个算法的执行时间呢?
事后统计方法:这种方法主要是通过设计好的测试程序和数据,利用计算机计时器对不同算法编制的程序的运行时间进行比较,从而确定算法效率的高低。但这种方法显然是有很大缺陷:必须依据算法事先编制好测试程序,通常需要花费大量时间和精力,完了发觉测试的是糟糕的算法,那不是功亏一篑?不同测试环境差别不是一般的大!我们把刚刚的估算方法称为事后诸葛亮。我们的计算机前辈们也不一定知道诸葛亮是谁,为了对算法的评判更为科学和便捷,他们研究出事前分析估算的方法
事前分析估算方法:在计算机程序编写前,依据统计方法对算法进行估算。
经过总结,我们发现一个高级语言编写的程序在计算机上运行时所消耗的时间取决于下列因素:
- 算法采用的策略,方案
- 编译产生的代码质量
- 问题的输入规模
- 机器执行指令的速度
由此可见,抛开这些与计算机硬件、软件有关的因素,一个程序的运行时间依赖于算法的好坏和问题的输入规模。(所谓的问题输入规模是指输入量的多少)
用 n 表示输入数据的个数
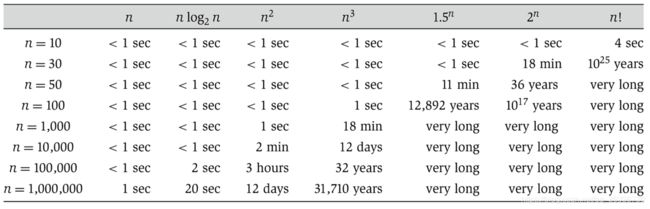
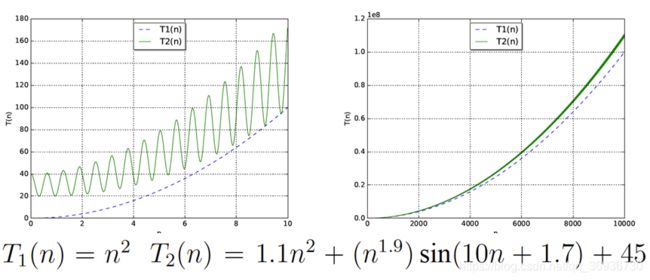
算法时间复杂度的定义:
在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况并确定T(n)的数量级。算法的时间复杂度,也就是算法的时间量度,记作:T(n)= O(f(n))。它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的时间复杂度。其中f(n)是问题规模n的某个函数。
2.常见时间复杂度
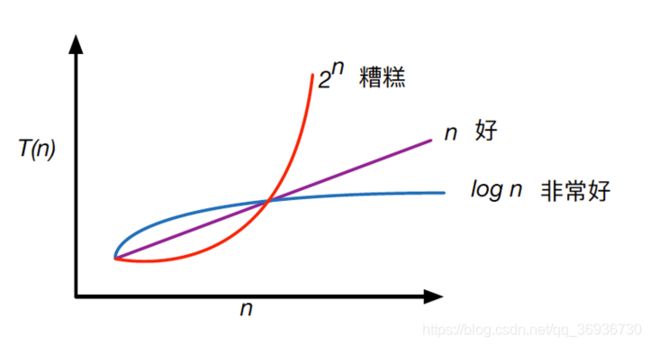
常数阶:
sum = 0
n = 100
print("I love fengwo")
print("I love fengwo")
print("I love fengwo")
print("I love fengwo")
print("I love fengwo")
print("I love fengwo")
sum = (1+n)*n/2
线性阶:一般含有非嵌套循环涉及线性阶,线性阶就是随着问题规模n的扩大,对应计算次数呈直线增长。下面这段代码,它的循环的时间复杂度为O(n),因为循环体中的代码需要执行n次。
sum = 0
for i in range(1,101):
sum = sum + i
平方阶:
n = 100
for i in range(n+1):
for j in range(n+1):
print("I love fengwo")
对数阶:
i = 1
n = 100
while i < n:
i = i * 2
由于每次i*2之后,就举例n更近一步,假设有x个2相乘后大于或等于n,则会退出循环。于是由2^x = n得到x = log(2)n,所以这个循环的时间复杂度为O(logn)。
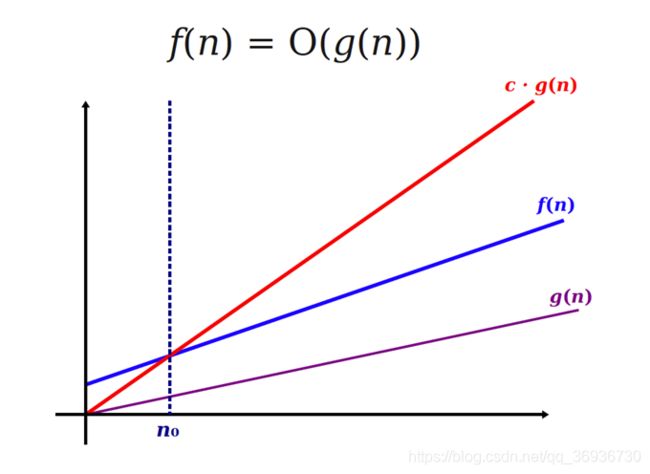
O的定义:如果存在正的常数C和自然数N0,使得当N³N0时有f(N)£Cg(N),则称函数f(N)当N充分大时上有界,且g(N)是它的一个上界,记为f(N)=O(g(N))。即f(N)的阶不高于g(N)的阶。
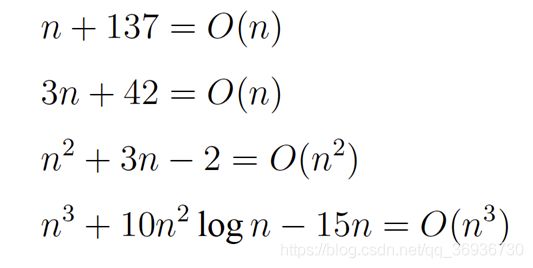
由于我们更加关注算法复杂度的增长趋势,所以判断一个算法的效率时,函数中的常数和其他次要项常常可以忽略,而更应该关注主项(最高项)的阶数。下界表示:
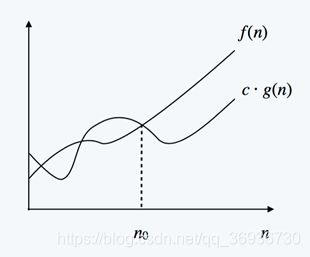
上下界表示:大Theta表示
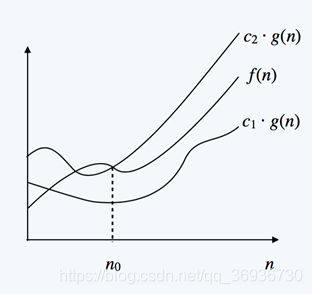
3.时间复杂度计算方法
常见的时间复杂度有:
- 常数阶O(1), 对数阶O(log2 n), 线性阶O(n), 线性对数阶O(n log2 n),
- 平方阶O(n^2), 立方阶O(n^3) k次方阶O(n^K), 指数阶O(2^n)。
- 随着n的不断增大,时间复杂度不断增大,算法花费时间越多。
计算方法
- 选取相对增长最高的项
- 最高项系数是都化为1
- 若是常数的话用O(1)表示
- 如f(n)=2*n^3+2n+100则O(f(n))=O(n^3)。
通常我们计算时间复杂度都是计算最坏情况或者平均情况
4.算法的空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。例如交换列表中两个元素的算法的空间复杂度为O(1)
因为该函数运行时入栈最深为1, 每运行一次只创建一个临时变量temp。
5.空间复杂度计算方法
- 忽略常数,用O(1)表示
- 递归算法的空间复杂度=递归深度N*每次递归所要的辅助空间
- 对于单线程来说,递归有运行时堆栈,求的是递归最深的那一次压栈所耗费的空间的个数,因为递归最深的那一次所耗费的空间足以容纳它所有递归过程。
def func(n):
k = 10
if n >= k:
return n
else:
return func(n+1)
递归实现,调用fun函数,每次都创建1个变量k。调用n次,空间复杂度O(n*1)=O(n)。
六、实例分析
1.斐波那契数列
有一对兔子,从出生两个月后就有繁殖能力,一对兔子每个月都生一对兔子,小兔子对长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?意大利的著名数学家斐波那契在算盘全集中提出的该问题,后人把各个月份兔子数量称为“斐波那契数列”。
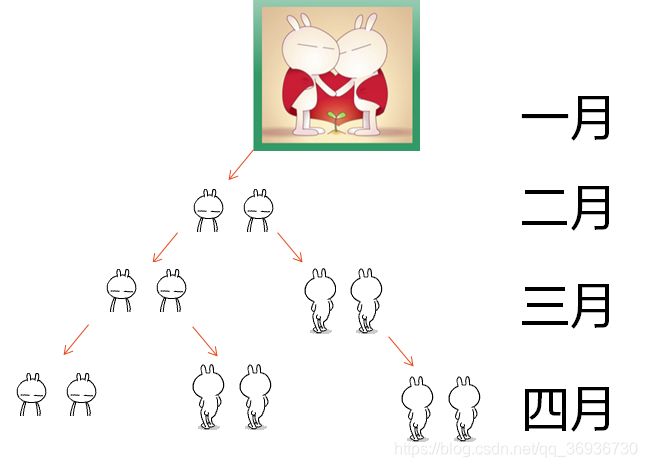
# 假设:刚开始兔子为child
# 分析:兔子的周期分为 child,young,old
# 1月:1,0,0 1
# 2月:0,1,0 1
# 3月:1,0,1 2
# 4月:1,1,1 3
# 5月:2,1,2 5
# 。。。
# 9月:13,8,13 34
# 结论:F(n) = F(n-1) + F(n-2)
非递归版:
def fib(n):
a, b = 0, 1
for i in range(n):
a, b = b, a+b
return a
递归版:
def fib(n):
if n == 1:
return 1
if n == 2:
return 1
return fib(n-1) + fib(n-2)
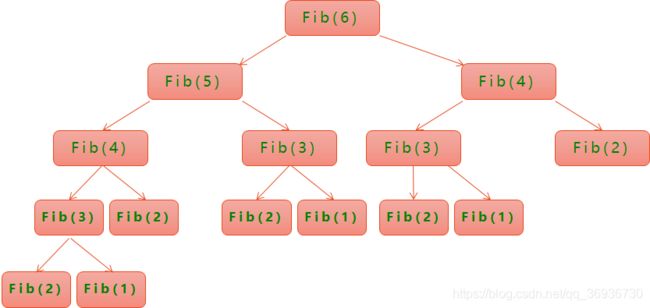
简单证明:这是一颗二叉树,树的高度h与n为线性关系,该算法的总运行次数为2^h,故时间复杂度为2^n
2.两数之和
def twoSum(lst, target):
n = len(lst)
for i in range(1, n):
for j in range(i):
if lst[i] + lst[j] == target:
return (i, j)
return -1
时间复杂度:
最好情况:lst[0] + lst[1] 恰好等于target O(1)
最坏情况:遍历所有情况都没有解 O(n^2)
平均情况: 也是 O(n^2)▪
# 思路二:双指针法
# 如果两个指针指向元素的和 sum == target,那么得到要求的结果;
# 如果 sum > target,移动较大的元素指针,使 sum 变小一些;
# 如果 sum < target,移动较小的元素指针,使 sum 变大一些。
def twoSum(lst,target):
result = []
i = 0
j = len(lst)-1
while i < j:
sum = lst[i] + lst[j]
if sum == target:
result.append((i,j))
i += 1
elif sum > target:
j -= 1
else :
i += 1
return result
return -1
时间复杂度:
O(n)
空间复杂度:
O(1)
# 思路三:HashMap
# 使用字典存储键值对,键为数组中的元素,值为该元素在数组中的下标
# 从左到右扫描,如果target-lst[i]不在字典中,将键值对(lst[i], i)存入字典;
# 如果 target-lst[i]在字典中,那么target-lst[i]与lst[i]刚好可以得到结果,取出他们的索引即可
def twoSum2(lst, target):
indexForNum = dict()
for i in range(len(lst)):
if (target - lst[i]) in indexForNum:
return [indexForNum.get(target-lst[i]), i]
else:
indexForNum[lst[i]] = i
时间复杂度:
O(n)
空间复杂度:
O(n)
相应面试题可参考如下内容:
BAT大厂数据分析面试经验:“高频面经”之数据分析篇
BAT大厂数据挖掘面试经验:“高频面经”之数据结构与算法篇
BAT大厂数据开发面试经验:“高频面经”之大数据研发篇
BAT大厂机器学习算法面试经验:“高频面经”之机器学习篇
BAT大厂深度学习算法面试经验:“高频面经”之深度学习篇