哎,昨天遗留一道所谓的回溯递归的字母转换大小写的问题!至今没有理清楚思路。但是不能因为这个卡住啊,最低标准一天五道题呢。所以继续开始做新的题目(ps:我觉得那道题绝对不是简单难度的!)
旋转数字
题目:我们称一个数 X 为好数, 如果它的每位数字逐个地被旋转 180 度后,我们仍可以得到一个有效的,且和 X 不同的数。要求每位数字都要被旋转。如果一个数的每位数字被旋转以后仍然还是一个数字, 则这个数是有效的。0, 1, 和 8 被旋转后仍然是它们自己;2 和 5 可以互相旋转成对方;6 和 9 同理,除了这些以外其他的数字旋转以后都不再是有效的数字。现在我们有一个正整数 N, 计算从 1 到 N 中有多少个数 X 是好数?
示例:
输入: 10
输出: 4
解释:
在[1, 10]中有四个好数: 2, 5, 6, 9。
注意 1 和 10 不是好数, 因为他们在旋转之后不变。
注意:
N 的取值范围是 [1, 10000]。
思路:这道题我觉得应该不难吧?最暴力的解法就是从1到n挨个判断?这里能后成为好数的标准是 2569.只有这四个数字组成的数能是好数。我去按照这点思路先尝试谢谢。
思路不对,仔细看了看,1不是好数,但是12反转21就是好数了。同理八也是。怎么说呢,我审题不清,测试案例专门是为了挖坑的,我继续做吧。
做出来了,需要两个判断,首先每一个数字倒转后有没有效。其次整个数字变没变。都满足则是好数:
class Solution {
int res;
public int rotatedDigits(int N) {
for(int i=1;i<=N;i++){
isRotatedDigits(i);
}
return res;
}
public void isRotatedDigits(int i){
boolean flag = true;
while(i>0) {
int temp = i%10;
if(temp==3 || temp==4 ||temp==7) return;
if(temp==5 || temp==2 || temp==6 || temp==9) {
flag = false;
}
i = i/10;
}
if(flag) return;
res++;
}
}
不过这个代码只超过百分之八十多的人,没满足我自己的九十大关,我看看怎么优化优化。
好的,我是一个没原则的人!看了排行第一第二的代码。。。各种复杂,三维数组都见到了。。。简直。。。我还是安安心心做咸鱼吧。下一题。
旋转字符串
题目:给定两个字符串, A 和 B。A 的旋转操作就是将 A 最左边的字符移动到最右边。 例如, 若 A = 'abcde',在移动一次之后结果就是'bcdea' 。如果在若干次旋转操作之后,A 能变成B,那么返回True。
示例 1:
输入: A = 'abcde', B = 'cdeab'
输出: true
示例 2:
输入: A = 'abcde', B = 'abced'
输出: false
注意:
A 和 B 长度不超过 100。
思路:这个题我肯定做过类似的!!我都记得上个题是什么?问B是不是A重叠掐头去尾形成的子串。不是-1.是的话返回A最少重叠几个。其实我觉得这道题也是这样的,首先如果b是a位移过来的,肯定挨着的字母顺序不能变,所以两个a肯定包含一个b,我去照着这个思路做。
感谢leetcode又给我一道送分题让我增加信心!!!直接贴代码:
class Solution {
public boolean rotateString(String A, String B) {
if(A.length()!=B.length()) return false;
if((A+A).indexOf(B)!=-1) return true;
return false;
}
}
性能超过百分百,所以不浪费时间了,直接下一题。
唯一摩尔斯密码词
题目:国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如: "a" 对应 ".-", "b" 对应 "-...", "c" 对应 "-.-.", 等等。为了方便,所有26个英文字母对应摩尔斯密码表如下:[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]给定一个单词列表,每个单词可以写成每个字母对应摩尔斯密码的组合。例如,"cab" 可以写成 "-.-..--...",(即 "-.-." + "-..." + ".-"字符串的结合)。我们将这样一个连接过程称作单词翻译。返回我们可以获得所有词不同单词翻译的数量。
例如:
输入: words = ["gin", "zen", "gig", "msg"]
输出: 2
解释:
各单词翻译如下:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
共有 2 种不同翻译, "--...-." 和 "--...--.".
注意:
单词列表words 的长度不会超过 100。
每个单词 words[i]的长度范围为 [1, 12]。
每个单词 words[i]只包含小写字母。
思路:感觉这个题不是 很难,但是题目是真的很长啊。暂时没啥好想法。就是把每一个单词拼出来然后比较一共有多少种类。先试试吧。
我才发现这个题的难点居然是判断一百个字符串有多少种???有点意思啊~我觉得这里一定要用到哈希Set了。不可存重复元素。
很好,暴力法通过了,简单粗暴的解决了问题
class Solution {
public int uniqueMorseRepresentations(String[] words) {
String[] d =new String[]{".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."};
Set set = new HashSet();
for(String s:words){
StringBuffer sb = new StringBuffer();
for(char c : s.toCharArray()){
sb.append(d[c-97]);
}
set.add(sb.toString());
}
return set.size();
}
}
至于这个性能嘛,,,咱们继续说优化吧。好的吧,知道为啥我的这个性能这么低了!很清晰的认识到了一点:我这c-97也就是char-数字性能不咋滴。改成c-'a'也就是char-char性能一下子上去了!下次我会记得这点。
并且改了这以后性能立刻超过了百分之九十九。所以这道题就这样!下一题。
写字符串需要的长度
题目:我们要把给定的字符串 S 从左到右写到每一行上,每一行的最大宽度为100个单位,如果我们在写某个字母的时候会使这行超过了100 个单位,那么我们应该把这个字母写到下一行。我们给定了一个数组 widths ,这个数组 widths[0] 代表 'a' 需要的单位, widths[1] 代表 'b' 需要的单位,..., widths[25] 代表 'z' 需要的单位。现在回答两个问题:至少多少行能放下S,以及最后一行使用的宽度是多少个单位?将你的答案作为长度为2的整数列表返回。
示例 1:
输入:
widths = [10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]
S = "abcdefghijklmnopqrstuvwxyz"
输出: [3, 60]
解释:
所有的字符拥有相同的占用单位10。所以书写所有的26个字母,
我们需要2个整行和占用60个单位的一行。
示例 2:
输入:
widths = [4,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10]
S = "bbbcccdddaaa"
输出: [2, 4]
解释:
除去字母'a'所有的字符都是相同的单位10,并且字符串 "bbbcccdddaa" 将会覆盖 9 * 10 + 2 * 4 = 98 个单位.
最后一个字母 'a' 将会被写到第二行,因为第一行只剩下2个单位了。
所以,这个答案是2行,第二行有4个单位宽度。
注:
字符串 S 的长度在 [1, 1000] 的范围。
S 只包含小写字母。
widths 是长度为 26的数组。
widths[i] 值的范围在 [2, 10]。
思路:这道题怎么说呢,感觉跟上个异曲同工!就是数组下标代表数字。然后char和数字来回转化而已。感觉这道题也不是很难,我先尝试做一下。
首先说下第一个坑点:就是比如这一行到了95,接下来需要10单位的字母,就不能在这行放了,剩下的5空着,下一行直接放10.所以单纯的累加是不可以的。我要去试试怎么不“单纯”的累加了。
好了,加了一个过程的处理r(行数)。如果这个一行满了100就行数加1.并且判断是不是正好满100.如果是的话行中位数重新为0.如果不是行中位数为最后一个加的位数。接下来贴代码:
class Solution {
public int[] numberOfLines(int[] widths, String S) {
int n = 0;
int r = 0;
for(char c : S.toCharArray()){
n += widths[c-'a'];
if(n>100){
r++;
n = widths[c-'a'];
}
if(n==100) {
r++;
n = 0;
}
}
if(n!=0) return new int[]{r+1,n};
return new int[]{r,100};
}
}
其实我就纳闷了,怎么每次性能都这么差?这个题都是什么妖魔鬼怪哟~1ms执行时间都是排六十多。。。肯定是有一个很容易想到的思路但是我没想到。我再去想想。
!!!我灵机一动,就死命盯着代码看哪里能影响性能,结果还真想到了!就是我计算了两次widths[c-'a']; 我把这个值提出来保存,然后使用保存的值相当于只计算了一次,果然超过百分百了!哈哈,重贴代码:
class Solution {
public int[] numberOfLines(int[] widths, String S) {
int n = 0;
int r = 0;
for(char c : S.toCharArray()){
int i = widths[c-'a'];
n += i;
if(n>100){
r++;
n = i;
}
if(n==100) {
r++;
n = 0;
}
}
if(n!=0) return new int[]{r+1,n};
return new int[]{r,100};
}
}
下一题下一题。
子域名访问计数
题目:一个网站域名,如"discuss.leetcode.com",包含了多个子域名。作为顶级域名,常用的有"com",下一级则有"leetcode.com",最低的一级为"discuss.leetcode.com"。当我们访问域名"discuss.leetcode.com"时,也同时访问了其父域名"leetcode.com"以及顶级域名 "com"。给定一个带访问次数和域名的组合,要求分别计算每个域名被访问的次数。其格式为访问次数+空格+地址,例如:"9001 discuss.leetcode.com"。接下来会给出一组访问次数和域名组合的列表cpdomains 。要求解析出所有域名的访问次数,输出格式和输入格式相同,不限定先后顺序。
示例 1:
输入:
["9001 discuss.leetcode.com"]
输出:
["9001 discuss.leetcode.com", "9001 leetcode.com", "9001 com"]
说明:
例子中仅包含一个网站域名:"discuss.leetcode.com"。按照前文假设,子域名"leetcode.com"和"com"都会被访问,所以它们都被访问了9001次。
示例 2
输入:
["900 google.mail.com", "50 yahoo.com", "1 intel.mail.com", "5 wiki.org"]
输出:
["901 mail.com","50 yahoo.com","900 google.mail.com","5 wiki.org","5 org","1 intel.mail.com","951 com"]
说明:
按照假设,会访问"google.mail.com" 900次,"yahoo.com" 50次,"intel.mail.com" 1次,"wiki.org" 5次。
而对于父域名,会访问"mail.com" 900+1 = 901次,"com" 900 + 50 + 1 = 951次,和 "org" 5 次。
注意事项:
cpdomains 的长度小于 100。
每个域名的长度小于100。
每个域名地址包含一个或两个"."符号。
输入中任意一个域名的访问次数都小于10000。
思路:怎么说呢,感觉这个题目很复杂,但是题本身不难。就是一个域名拆分嘛。我现在的思路是存map。因为这个题有个很有意思的点:次数是累加的。map 的key 的唯一性很好的可以实现累加。感觉也不难,每个域名去掉第一个单词拆分,直到拆分到没有.为止。我去按照这个思路实现下。
emmmm....做出来了,贼麻烦性能贼可怜,但是还要把我第一版本的代码贴上来:
class Solution {
public List subdomainVisits(String[] cpdomains) {
Map map = new HashMap();
for(String s :cpdomains){
String[] arr = s.split(" ");
int n = Integer.valueOf(arr[0]);
String [] strs = arr[1].split("\\.");
for(int i = 0;i res = new ArrayList();
for(Map.Entry entry : map.entrySet()){
res.add(entry.getValue()+" "+entry.getKey());
}
return res;
}
}
毕竟是劳动成果,而且是第一思路。代码虽然麻烦点但是逻辑清晰明了的。剩下开始优化了,我要死盯代码找出优化点。
差不多改完了,现在性能超过百分之九十多,算是及格了。其实优化点就是我之前是根据.拆分成数组然后再加的。后来直接substring截取也可以实现,而且更简单。贴上第二版代码:
class Solution {
public List subdomainVisits(String[] cpdomains) {
Map map = new HashMap();
for(String s :cpdomains){
String[] arr = s.split(" ");
int n = Integer.valueOf(arr[0]);
s = arr[1];
while(true){
if(map.containsKey(s)){
map.put(s,map.get(s)+n);
}else{
map.put(s,n);
}
if(s.indexOf(".")!=-1) {
s = s.substring(s.indexOf(".")+1) ;
}else {
break;
}
}
}
List res = new ArrayList();
for(Map.Entry entry : map.entrySet()){
res.add(entry.getValue()+" "+entry.getKey());
}
return res;
}
}
最后去看看性能排行第一的代码:
感觉代码大同小异,而且也没多简单,所以这个过吧。
最大三角形面积
题目:给定包含多个点的集合,从其中取三个点组成三角形,返回能组成的最大三角形的面积。
示例:
输入: points = [[0,0],[0,1],[1,0],[0,2],[2,0]]
输出: 2
解释:
这五个点如下图所示。组成的橙色三角形是最大的,面积为2。
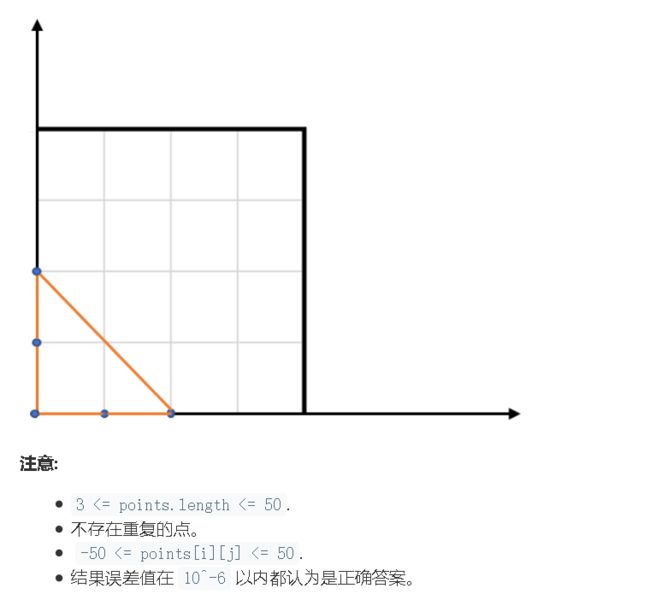
思路:这道题似曾相识的做过。首先从有一道从数组中选出三个数组成三角形面积最大。其次有个题就是回旋镖那个也是坐标系三角形。但是其实都不一样,说这么多还是要想想这道题要怎么做。
我觉得这道题涉及到我的知识盲区了,怎么想也想不出来,所以。。。我还是直接看题解吧。
最坏的情况出现了,看题解也看不明白。接下来的补课时间~~
说一下两个公式
海伦公式
海伦公式又译作希伦公式、海龙公式、希罗公式、海伦-秦九韶公式。它是利用三角形的三条边的边长直接求三角形面积的公式。表达式为:S=√p(p-a)(p-b)(p-c),它的特点是形式漂亮,便于记忆。
相传这个公式最早是由古希腊数学家阿基米德得出的,而因为这个公式最早出现在海伦的著作《测地术》中,所以被称为海伦公式。中国秦九韶也得出了类似的公式,称三斜求积术。
来自于百度百科
海伦公式的公式表述(我一把年纪还要去学高中数学,真真觉得当时为什么不好好学!):
假设在平面内,有一个三角形,边长分别为a、b、c,三角形的面积S可由以下公式求得:
而公式里的p为半周长(周长的一半):
它的特点是形式漂亮,便于记忆。
其实说这么多也没啥实际意义,只要记住这个公式就行了。
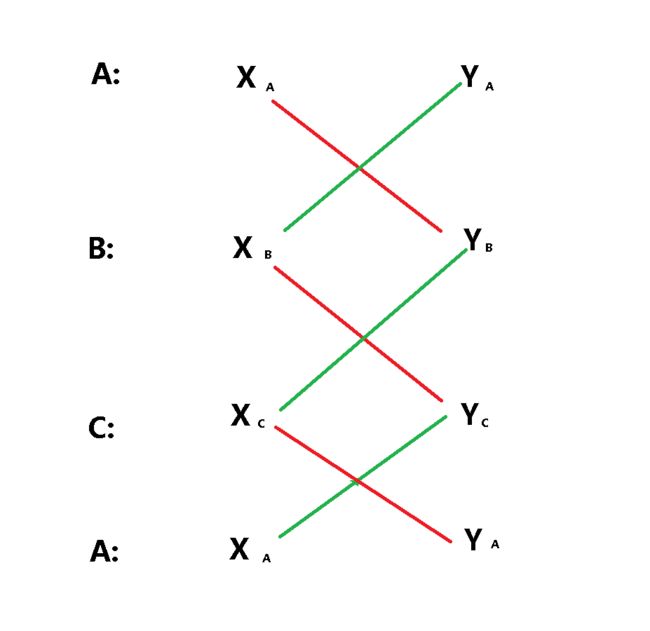
第二个公式:(Shoelace公式)鞋带公式
(Shoelace公式)鞋带公式
首先这个资料介绍没有海伦公式那么全。并且我在百度百科没有找到这个名词的解释。其次这个感觉上更适用于二维的点的求面积(上面的海伦公式好像更适合线)。但是这个方法还是很好记的。我简单的表述下:
- 这个公式不仅仅适用于三角形,还有四边形,五边形等...可以是凹、或凸多边形,但原则上边与边之间不能有交叉。
- shoelace,——“鞋带”——,并不是人名,所以翻译成“鞋带公式”没有任何问题。而鞋带这一个名字的由来是源于计算时类似于鞋带一样错位相乘。
- 鞋带公式又叫“鞋带算法”、“鞋带法”、“高斯面积公式”、测量员公式。
然后开始说如何计算的:
图中A,B,C代表三角形的三个二维坐标点。
每个点分为横坐标x 纵坐标y。而所谓的鞋带法:就是错位相乘后相加。一个从左边起计算(红色线相加)一个从右边起计算(绿色线相加)最终会有两个结果。
然后面积的计算就是 2/1 *|a-b|。
其实具体原理据说是格林公式的特殊情况,但是我还没看。原谅我的不求甚解,我只是想做出这道题而已。有时间有机会会再去补习的。
然后上面的定理知道了的话这道题还是不难的,就是往上套就行。虽然性能有点问题。而且因为三个点,并且 A,B,C和B,A,C是一样的。所以任意三个点只要计算一次就行了。直接贴代码:
class Solution {
public double largestTriangleArea(int[][] points) {
double res = 0;
for(int i = 0;i
其实精髓就是第三层循环中的int a int b的赋值。可能我刚刚接触鞋带算法还不熟,我反正是对着我的画图一点点写的。然后这个三层循环(依稀记得但是学java的时候老师说的超过两次for循环就是代码有问题)的性能反正不太好,我去看看排行第一的代码是怎么写的。
就是很奇怪,代码逻辑差不多,人家3ms,我7ms。。。除了写的略简单点,单独提出来个方法,数组放到成员变量里,也没看出别的不同啊,附上性能第一的代码:
class Solution {
private int[][] mps;
public double largestTriangleArea(int[][] points) {
int len = points.length;
mps = points;
double max = 0;
double temp;
for (int i = 0; i < len; ++i) {
for (int j = i + 1; j < len; ++j) {
for (int k = j + 1; k < len; ++k) {
temp = getArea(i, j, k);
if (temp > max) {
max = temp;
}
}
}
}
return max;
}
private double getArea(int i, int j, int k) {
return Math.abs((mps[i][0] * mps[j][1] + mps[j][0] * mps[k][1] + mps[k][0] * mps[i][1] -
mps[i][0] * mps[k][1]- mps[j][0] * mps[i][1] - mps[k][0] * mps[j][1]) * 0.5);
}
}
这道题就这样吧,海伦公式和鞋带公式算是这道题的收货了。希望若干天后重温到这个题依然记得。
最常见的单词
题目:给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。返回出现次数最多,同时不在禁用列表中的单词。题目保证至少有一个词不在禁用列表中,而且答案唯一。禁用列表中的单词用小写字母表示,不含标点符号。段落中的单词不区分大小写。答案都是小写字母。
示例:
输入:
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
banned = ["hit"]
输出: "ball"
解释:
"hit" 出现了3次,但它是一个禁用的单词。
"ball" 出现了2次 (同时没有其他单词出现2次),所以它是段落里出现次数最多的,且不在禁用列表中的单词。
注意,所有这些单词在段落里不区分大小写,标点符号需要忽略(即使是紧挨着单词也忽略, 比如 "ball,"),
"hit"不是最终的答案,虽然它出现次数更多,但它在禁用单词列表中。
说明:
1 <= 段落长度 <= 1000.
1 <= 禁用单词个数 <= 100.
1 <= 禁用单词长度 <= 10.
答案是唯一的, 且都是小写字母 (即使在 paragraph 里是大写的,即使是一些特定的名词,答案都是小写的。)
paragraph 只包含字母、空格和下列标点符号!?',;.
不存在没有连字符或者带有连字符的单词。
单词里只包含字母,不会出现省略号或者其他标点符号。
思路 :这道题思路就是字符串处理。性能不好就不好吧,反正怎么方便怎么来。第一步标点符号换成空格。第二步全部小写。第三步禁用单词replace为空。第五步map或者数组计数。第六步遍历map或者数组找到计数最多的。over。我去写了。
我也不知道为啥一个看着挺简单的题,写的贼鸡儿墨迹,直接贴代码:
class Solution {
public String mostCommonWord(String paragraph, String[] banned) {
char[] c = paragraph.toCharArray();
//处理大小写和标点符号
for(int i = 0;i='a'&& c[i]<='z') continue;
//空格是32
if(c[i]+' '>='a' && c[i]+' '<='z') {
c[i] = (char)(c[i]+' ');
}else{
c[i] = ' ';
}
}
//这一步可能有多个空格,变成一个
String s = new String(c).replace(" ", " ");
//处理掉所有禁词
for(int i = 0;i map = new HashMap();
//计数最多的
for(String cc : ss) {
if(map.containsKey(cc)) {
map.put(cc, map.get(cc)+1);
if(map.get(cc)>n) {
n = map.get(cc);
res = cc;
}
}else {
map.put(cc, 1);
}
}
return res;
}
}
写这么多性能好也就罢了,关键性能还不好,我简直了。。。感觉优化点很多,我再想想的。
看了性能排第一的代码:
class Solution {
public String mostCommonWord(String paragraph, String[] banned) {
paragraph += ".";
Set ban = new HashSet<>();
for (String s : banned) {
ban.add(s);
}
Map map = new HashMap<>();
String res = "";
int fre = 0;
StringBuilder sb = new StringBuilder();
for (char c: paragraph.toCharArray()) {
if (Character.isLetter(c)) {
sb.append(Character.toLowerCase(c));
} else if (sb.length() > 0) {
String word = sb.toString();
if (!ban.contains(word)) {
map.put(word,map.getOrDefault(word,0) + 1);
if (map.get(word) > fre) {
fre = map.get(word);
res = word;
}
}
sb = new StringBuilder();
}
}
return res;
}
}
首先到我手里性能只排98这个不重要。重要的是这个思路我还真想过!但是没实现。因为我觉得来回来去stringBuffer也不见得性能多好。所以pass了!现在事实告诉我不要瞎想、还是要实践才知道结果。
另外这个Character.isLetter(c)方法以前也确实没见过。其实对于char用的很少。一般也都是随着用随着了解。这次这个题就当学习了这两个api吧。
终于刷题超过200了。为了纪念多做两个题庆祝!~~~
字符的最短距离
题目:给定一个字符串 S 和一个字符 C。返回一个代表字符串 S 中每个字符到字符串 S 中的字符 C 的最短距离的数组。
示例 1:
输入: S = "loveleetcode", C = 'e'
输出: [3, 2, 1, 0, 1, 0, 0, 1, 2, 2, 1, 0]
说明:
字符串 S 的长度范围为 [1, 10000]。
C 是一个单字符,且保证是字符串 S 里的字符。
S 和 C 中的所有字母均为小写字母。
思路:错觉又来了!!这道题我又觉得做过类似的!目前的思路就是把所有给定单词的下标取出来。然后挨个单词从前往后比对。如果后面的比前面的大则直接取前面的,不然就不断比较。到最小。初步思路就这样,接下来我去写代码试试
这个题呦,性能让我绝望了。直接贴代码:
class Solution {
public int[] shortestToChar(String S, char C) {
char[] c = S.toCharArray();
int len = c.length;
int[] ar = new int[len];
int index = 0;
for(int i = 0;i
4ms,只超过了百分之三十多。我记得以前有个题目是供暖的,有点类似但是不完全一样。真的是,现在这个比较是全比较,碰到后面比前面的大了说明超了所以这个就这样判断下一个。之前没有这句话性能也是一样的,我就奇怪为什么一样呢?
或者我想想还能怎么做这道题。好了,换一个思路这个题的性能上来了:
class Solution {
public int[] shortestToChar(String S, char C) {
char[] c = S.toCharArray();
int[] res = new int[c.length];
int n = 10000;
int index = 0;
for(char i:c){
if(i==C){
n = 0;
}
res[index] = n;
index++;
n++;
}
n = 10000;
for(int i = c.length-1;i>=0;i-- ){
if(c[i]==C){
n=0;
}
index--;
res[index] = Math.min(res[index],n);
n++;
}
return res;
}
}
其实这道题难是不难的,只不过怎么处理性能好而已。因为这个已经超过了百分之九十九的人,所以就过了,下一题。
山羊拉丁文
题目:给定一个由空格分割单词的句子 S。每个单词只包含大写或小写字母。我们要将句子转换为 “Goat Latin”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。
山羊拉丁文的规则如下:
- 如果单词以元音开头(a, e, i, o, u),在单词后添加"ma"。
例如,单词"apple"变为"applema"
- 如果单词以辅音字母开头(即非元音字母),移除第一个字符并将它放到末尾,之后再添加"ma"。例如,单词"goat"变为"oatgma"。
- 根据单词在句子中的索引,在单词最后添加与索引相同数量的字母'a',索引从1开始。例如,在第一个单词后添加"a",在第二个单词后添加"aa",以此类推。返回将 S 转换为山羊拉丁文后的句子。
示例 1:
输入: "I speak Goat Latin"
输出: "Imaa peaksmaaa oatGmaaaa atinLmaaaaa"
示例 2:
输入: "The quick brown fox jumped over the lazy dog"
输出: "heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa"
说明:
S 中仅包含大小写字母和空格。单词间有且仅有一个空格。
1 <= S.length <= 150。
思路:其实这个题题干比较长,但是做起来应该不难,就是一个对字符串处理的过程。我直接去实现了。老规矩:转化成数组,然后分情况处理。
好了,做完了,但是又不知道为啥性能还是不行。只超过了百分之七十多的人。我感觉优化点可能是在原因字母这块。先把第一版本代码贴上我再慢慢优化:
class Solution {
public String toGoatLatin(String S) {
Set set = new HashSet();
set.add('a');
set.add('e');
set.add('i');
set.add('o');
set.add('u');
set.add('A');
set.add('E');
set.add('I');
set.add('O');
set.add('U');
String[] arr = S.split(" ");
for(int i = 0;i=0){
sb.append('a');
n--;
}
return sb.toString();
}
}
其实这个题真的很简单,我思路一直再乱跳。还可以实现的方式:直接字符串处理。一边遍历一边往新的上追加。这个类似于今天做的另一道题:就是那个最常见的单词那个。不要非把一句话拆开的。我按照这个思路去试试。
看了排名第一的代码,只能说我直觉贼准:就是想的那样。但是判断贼多。我把代码贴出来分享下,我自己就不再做一遍了:
class Solution {
public String toGoatLatin(String S) {
StringBuffer r=new StringBuffer();
int count=1;
boolean flag=false;
boolean spaceFlag=false;
char first='a';
if(S.length()==0) return S;
for(int i=0;i
然后今天的笔记就到这里,明天元旦,提前祝大家元旦快乐!新的一年2020,多吃不胖,积极向上!工作顺顺利利,身体健健康康!另外本篇文章如果稍微帮到你了记得点个喜欢点个关注呦~!