文章大纲
一、搜索引擎框架基础介绍
二、ElasticSearch的简介
三、ElasticSearch安装(Windows版本)
四、ElasticSearch操作客户端工具--Kibana
五、ES的常用命令
六、Java连接ElasticSearch进行数据操作
七、项目源码与参考资料下载
八、参考文章

一、搜索引擎框架基础介绍
相关基础学习可参考:https://www.cnblogs.com/WUXIAOCHANG/p/10855506.html
二、ElasticSearch的简介
1. ElasticSearch是什么
ElasticSearch是智能搜索,分布式的搜索引擎。是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
(1)E:EalsticSearch 搜索和分析的功能
(2)L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
(3)K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台

分析日志的用处:假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?
但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
这都依赖ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
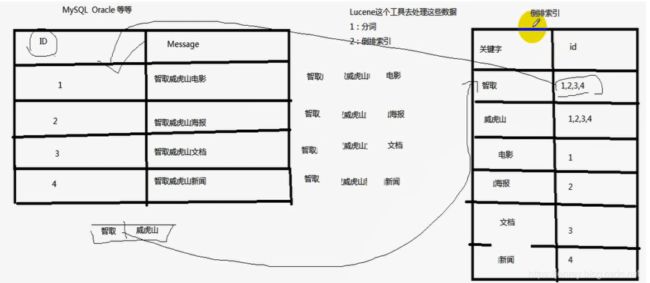
2. 全文检索与倒排索引
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。
3. ElasticSearch的优点
(1)分布式的功能
(2)数据高可用,集群高可用
(3)API更简单
(4)API更高级。
(5)支持的语言很多
(6)支持PB级别的数据
(7)完成搜索的功能和分析功能
(8)基于Lucene,隐藏了Lucene的复杂性,提供简单的API
(9)ES的性能比HBase高,咱们的竞价引擎最后还是要存到ES中的。
(10)Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
(11)Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行
(12)Elasticsearch 一个典型应用就是 ELK 日志分析系统
4. ElasticSearch支持的语言
Curl、java、c#、python、JavaScript、php、perl、ruby
5. ElasticSearch的核心概念
5.1 Node节点
就是集群中的一台服务器
5.2 index 索引(索引库)
我们为什么使用ES?因为想把数据存进去,然后再查询出来。
我们在使用Mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。
其实ES功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇
index类似于我们Mysql里面的一个数据库 create database user; 好比就是一个索引库
5.3 type类型
类型是用来定义数据结构的
在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
5.4 document:文档
文档就是最终的数据了,可以认为一个文档就是一条记录。
是ES里面最小的数据单元,就好比表里面的一条数据
5.5 Field 字段
好比关系型数据库中列的概念,一个document有一个或者多个field组成。
例如:
朝阳区:一个Mysql数据库
房子:create database chaoyaninfo
房间:create table people
5.6 shard:分片
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
kafka:为什么支持分布式的功能,因为里面是有topic,支持分区的概念。所以topic A可以存在不同的节点上面。就可以支持海量数据和高并发,提升性能和吞吐量
5.7 replica:副本
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的shard发生故障,无法提供正常服务。
我们为了保证数据的安全,我们引入了replica的概念,跟hdfs里面的概念是一个意思。可以保证我们数据的安全。
在ES集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
5.8 总结
在默认情况下,我们创建一个库的时候,默认会帮我们创建5个主分片(primary shrad)和5个副分片(replica shard),所以说正常情况下是有10个分片的。
同一个节点上面,副本和主分片是一定不会在一台机器上面的,就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES会自动的给你在新机器上创建一个之前分片的副本。

举例:
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。


5.9 ElasticSearch配置文件详解
配置文件位于%ES_HOME%/config/elasticsearch.yml文件中,用Editplus打开它,你便可以进行配置。
所有的配置都可以使用环境变量,例如:
node.rack: ${RACK_ENV_VAR}
表示环境变量中有一个RACK_ENV_VAR变量。
下面列举一下elasticsearch的可配置项:
1. 集群名称,默认为elasticsearch:
cluster.name: elasticsearch
2. 节点名称,es启动时会自动创建节点名称,但你也可进行配置:
node.name: "Franz Kafka"
3. 是否作为主节点,每个节点都可以被配置成为主节点,默认值为true:
node.master: true
4. 是否存储数据,即存储索引片段,默认值为true:
node.data: true
master和data同时配置会产生一些奇异的效果:
1) 当master为false,而data为true时,会对该节点产生严重负荷;
2) 当master为true,而data为false时,该节点作为一个协调者;
3) 当master为false,data也为false时,该节点就变成了一个负载均衡器。
你可以通过连接http://localhost:9200/_cluster/health或者http://localhost:9200/_cluster/nodes,或者使用插件http://github.com/lukas-vlcek/bigdesk或http://mobz.github.com/elasticsearch-head来查看集群状态。
5. 每个节点都可以定义一些与之关联的通用属性,用于后期集群进行碎片分配时的过滤:
node.rack: rack314
6. 默认情况下,多个节点可以在同一个安装路径启动,如果你想让你的es只启动一个节点,可以进行如下设置:
node.max_local_storage_nodes: 1
7. 设置一个索引的碎片数量,默认值为5:
index.number_of_shards: 5
8. 设置一个索引可被复制的数量,默认值为1:
index.number_of_replicas: 1
当你想要禁用公布式时,你可以进行如下设置:
index.number_of_shards: 1
index.number_of_replicas: 0
这两个属性的设置直接影响集群中索引和搜索操作的执行。假设你有足够的机器来持有碎片和复制品,那么可以按如下规则设置这两个值:
1) 拥有更多的碎片可以提升索引执行能力,并允许通过机器分发一个大型的索引;
2) 拥有更多的复制器能够提升搜索执行能力以及集群能力。
对于一个索引来说,number_of_shards只能设置一次,而number_of_replicas可以使用索引更新设置API在任何时候被增加或者减少。
ElasticSearch关注加载均衡、迁移、从节点聚集结果等等。可以尝试多种设计来完成这些功能。
可以连接http://localhost:9200/A/_status来检测索引的状态。
9. 配置文件所在的位置,即elasticsearch.yml和logging.yml所在的位置:
path.conf: /path/to/conf
10. 分配给当前节点的索引数据所在的位置:
path.data: /path/to/data
可以可选择的包含一个以上的位置,使得数据在文件级别跨越位置,这样在创建时就有更多的自由路径,如:
path.data: /path/to/data1,/path/to/data2
11. 临时文件位置:
path.work: /path/to/work
12. 日志文件所在位置:
path.logs: /path/to/logs
13. 插件安装位置:
path.plugins: /path/to/plugins
14. 插件托管位置,若列表中的某一个插件未安装,则节点无法启动:
plugin.mandatory: mapper-attachments,lang-groovy
15. JVM开始交换时,ElasticSearch表现并不好:你需要保障JVM不进行交换,可以将bootstrap.mlockall设置为true禁止交换:
bootstrap.mlockall: true
请确保ES_MIN_MEM和ES_MAX_MEM的值是一样的,并且能够为ElasticSearch分配足够的内在,并为系统操作保留足够的内存。
16. 默认情况下,ElasticSearch使用0.0.0.0地址,并为http传输开启9200-9300端口,为节点到节点的通信开启9300-9400端口,也可以自行设置IP地址:
network.bind_host: 192.168.0.1
17. publish_host设置其他节点连接此节点的地址,如果不设置的话,则自动获取,publish_host的地址必须为真实地址:
network.publish_host: 192.168.0.1
18. bind_host和publish_host可以一起设置:
network.host: 192.168.0.1
19. 可以定制该节点与其他节点交互的端口:
transport.tcp.port: 9300
20. 节点间交互时,可以设置是否压缩,转为为不压缩:
transport.tcp.compress: true
21. 可以为Http传输监听定制端口:
http.port: 9200
22. 设置内容的最大长度:
http.max_content_length: 100mb
23. 禁止HTTP
http.enabled: false
24. 网关允许在所有集群重启后持有集群状态,集群状态的变更都会被保存下来,当第一次启用集群时,可以从网关中读取到状态,默认网关类型(也是推荐的)是local:
gateway.type: local
25. 允许在N个节点启动后恢复过程:
gateway.recover_after_nodes: 1
26. 设置初始化恢复过程的超时时间:
gateway.recover_after_time: 5m
27. 设置该集群中可存在的节点上限:
gateway.expected_nodes: 2
28. 设置一个节点的并发数量,有两种情况,一种是在初始复苏过程中:
cluster.routing.allocation.node_initial_primaries_recoveries: 4
另一种是在添加、删除节点及调整时:
cluster.routing.allocation.node_concurrent_recoveries: 2
29. 设置复苏时的吞吐量,默认情况下是无限的:
indices.recovery.max_size_per_sec: 0
30. 设置从对等节点恢复片段时打开的流的数量上限:
indices.recovery.concurrent_streams: 5
31. 设置一个集群中主节点的数量,当多于三个节点时,该值可在2-4之间:
discovery.zen.minimum_master_nodes: 1
32. 设置ping其他节点时的超时时间,网络比较慢时可将该值设大:
discovery.zen.ping.timeout: 3s
http://elasticsearch.org/guide/reference/modules/discovery/zen.html上有更多关于discovery的设置。
33. 禁止当前节点发现多个集群节点,默认值为true:
discovery.zen.ping.multicast.enabled: false
34. 设置新节点被启动时能够发现的主节点列表(主要用于不同网段机器连接):
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
35.设置是否可以通过正则或者_all删除或者关闭索引
action.destructive_requires_name 默认false 允许 可设置true不允许
三、ElasticSearch安装(Windows版本)
1. 安装前准备
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎,而Lucene的开发语言是Java,所以电脑上面需要配置好jdk才能运行es数据库。
2. 在官网下载安装包
地址https://www.elastic.co/cn/downloads/elasticsearch
3. 解压到本地,在cmd中运行elasticsearch.bat文件

4. 启动测试
在浏览器中输入:http://localhost:9200/

如果出现上图所示内容,表示ElasticSearch启动成功。中小型项目直接使用即可,大型项目还是要调一调参数的。
四、ElasticSearch操作客户端工具--Kibana
1. 为什么要使用Kibana
为了方便我们去操作ES,如果不安装去操作ES很麻烦,需要通过shell命令的方式。
2. 下载Kibana
地址:https://www.elastic.co/cn/downloads/kibana

3. 安装并启动
直接解压即可,进入bin目录下,本文为G:\myProgram\kibana\kibana-6.3.2-windows-x86_64\bin 的cmd,执行kibana

不需要配置任何参数,自动识别localhost,在浏览器中输入 http://localhost:5601

点击下面按钮,进行ES命令操作



五、ElasticSearch的常用命令
1. CURD操作
1.1 GET _cat/health 查看集群的健康状况

温馨提示:green代表是健康的,yellow表示亚健康,red表示异常。
1.2 GET _all 查询所有数据

1.3 PUT wxc_index 增加一个wxc_index的index库

1.4 GET _cat/indices 查询ES中所有的index

1.5 DELETE /wxc_index 删除一个wxc_index的index库

1.6 插入一条数据

温馨提示:
(1)shop代表库名,product代表表名,1代码数据序号
(2)我们插入数据的时候,如果我们的语句中指明了index和type,如果ES里面不存在,默认帮我们自动创建
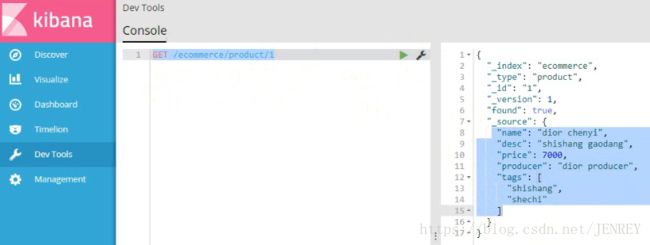
1.7 查询数据
使用语法:GET /index/type/id
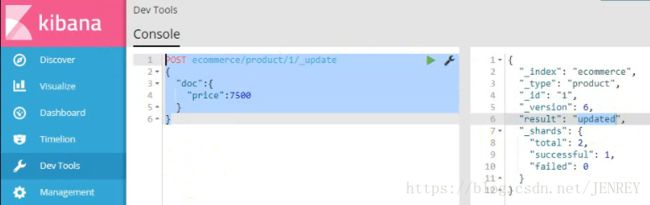
1.8 修改数据
1.9 删除数据

1.10 现在查看所有数据,类似于全表扫描

took:耗费了6毫秒
shards:分片的情况
hits:获取到的数据的情况
total:3 总的数据条数
max_score:1 所有数据里面打分最高的分数
_index:"ecommerce" index名称
_type:"product" type的名称
_id:"2" id号
_score:1 分数,这个分数越大越靠前出来,百度也是这样。除非是花钱。否则匹配度越高越靠前

2. DSL语言
ES最主要是用来做搜索和分析的。所以DSL还是对于ES很重要的
案例:我们要进行全表扫描使用DSL语言,查询所有的商品
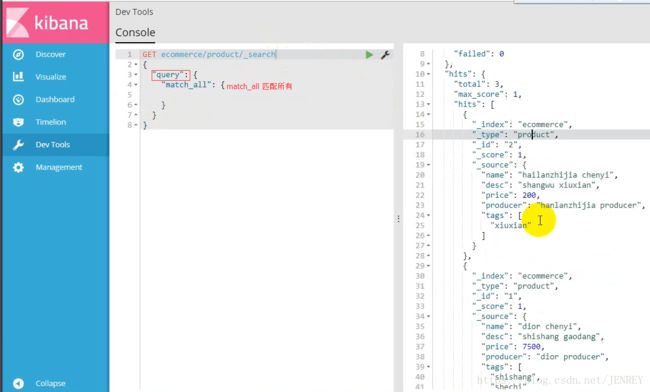
温馨提示:使用match_all 可以查询到所有文档,是没有查询条件下的默认语句。
案例:查询所有名称里面包含chenyi的商品,同时按价格进行降序排序
如上图所示,name为dior chenyi的数据会在ES中进行倒排索引分词的操作,这样的数据也会被查询出来。
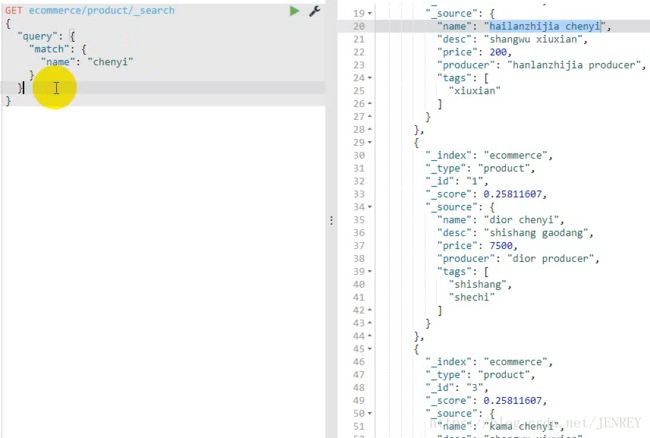
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
下面我们按照价格进行排序:因为不属于查询的范围了。所以要写一个 逗号

这样我们的排序就完成了
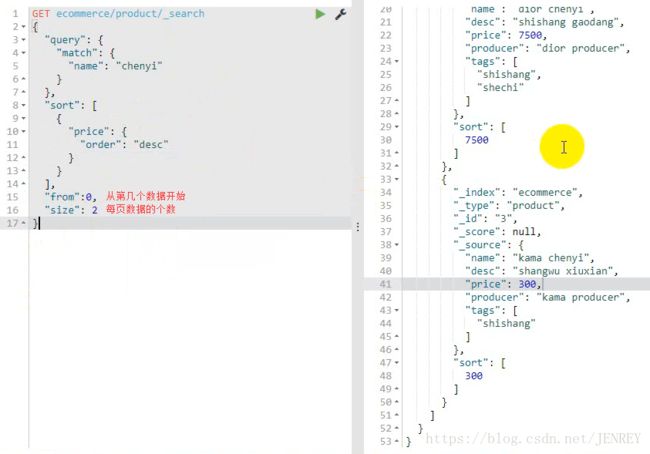
案例:实现分页查询
条件:根据查询结果(包含chenyi的商品),再进行每页展示2个商品
案例:进行全表扫面,但返回指定字段的数据

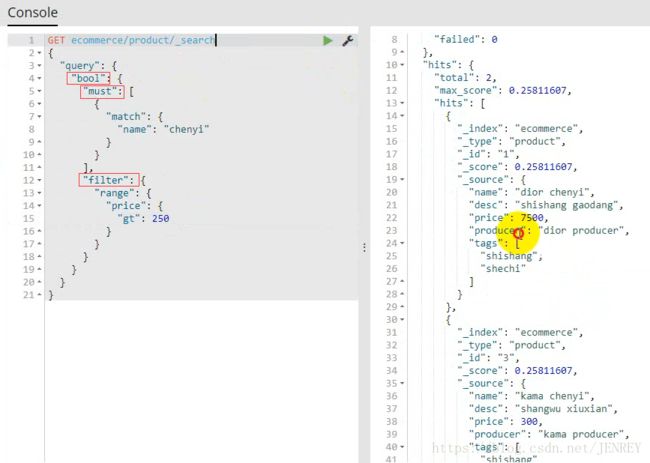
案例:搜索名称里面包含chenyi的,并且价格大于250元的商品
相当于 select * form product where name like %chenyi% and price >250;
因为有两个查询条件,我们就需要使用下面的查询方式
如果需要多个查询条件拼接在一起就需要使用bool
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含以下操作符:
must :: 多个查询条件的完全匹配,相当于 and。
must_not :: 多个查询条件的相反匹配,相当于 not。
should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组
3. 聚合分析
案例:对商品名称里面包含chenyi的,计算每个tag下商品的数量

案例:查询商品名称里面包含chenyi的数据,并且按照tag进行分组,计算每个分组下的平均价格

案例:查询商品名称里面包含chenyi的数据,并且按照tag进行分组,计算每个分组下的平均价格,按照平均价格进行降序排序

六、Java连接ElasticSearch进行数据操作
1. 创建maven项目
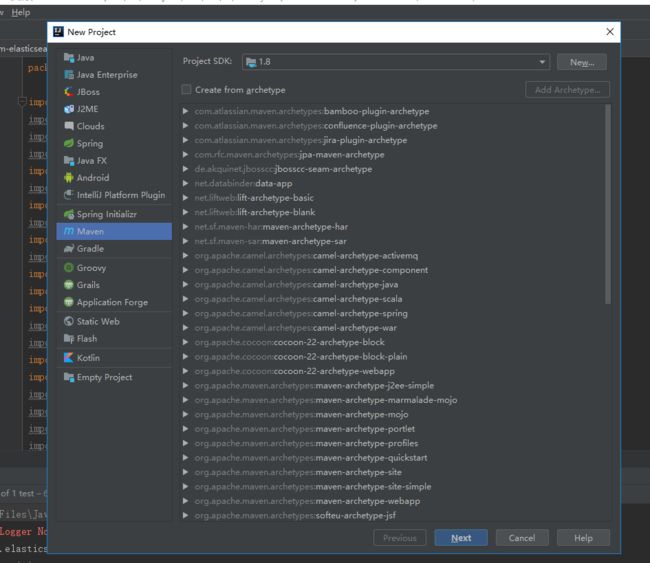
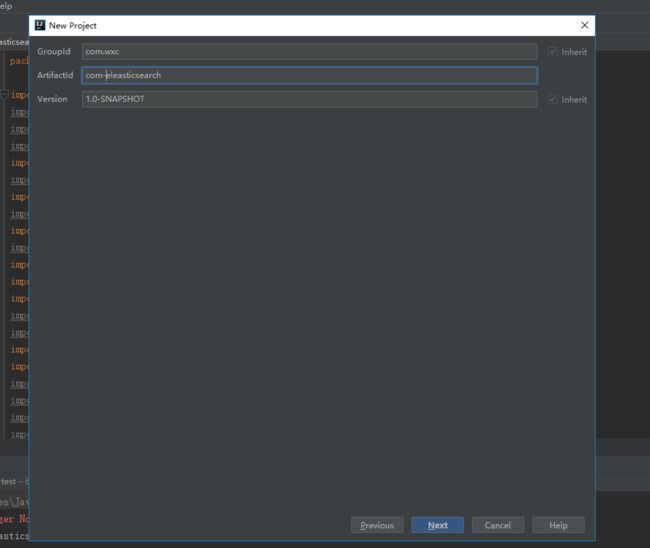
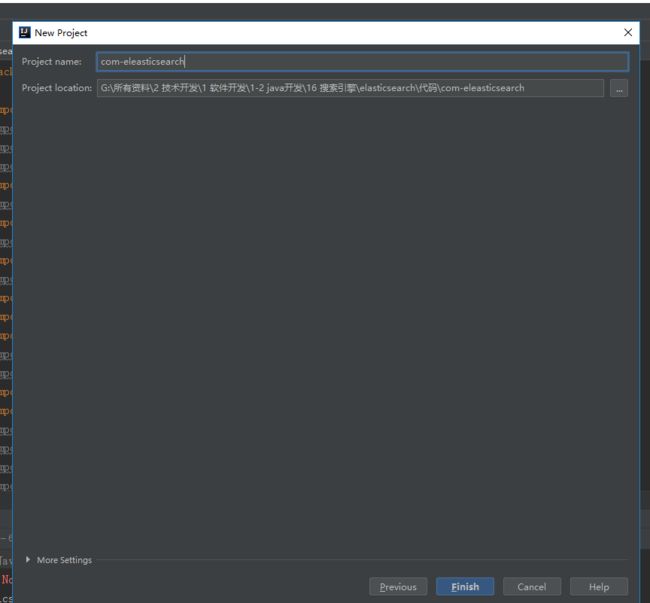
创建后项目结构如下:
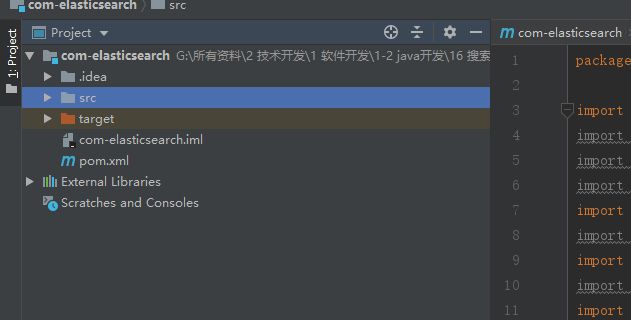
2. pom.xml添加maven依赖
4.0.0
com.wxc
com-elasticsearch
1.0-SNAPSHOT
junit
junit
4.12
javax.servlet
javax.servlet-api
3.1.0
provided
org.elasticsearch.client
transport
5.6.0
org.apache.logging.log4j
log4j-core
2.6.2
org.apache.logging.log4j
log4j-api
2.6.2
com.google.code.gson
gson
2.8.5
3. 新建包,并创建测试类
新建com.wxc.es包

com.wxc.es包下新建测试类EsUtils.java
package com.wxc.es;
import com.google.gson.JsonObject;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexResponse;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingResponse;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.IndicesAdminClient;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.HashMap;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
public class EsUtils {
public final static String HOST = "127.0.0.1";
public final static int PORT = 9300;//http请求的端口是9200,客户端是9300
private TransportClient client = null;
/**
* 测试Elasticsearch客户端连接
* @Title: test1
* @author sunt
* @date 2017年11月22日
* @return void
* @throws UnknownHostException
*/
@SuppressWarnings("resource")
@Test
public void test1() throws UnknownHostException {
//创建客户端
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddresses(
new InetSocketTransportAddress(InetAddress.getByName(HOST),PORT));
System.out.println("Elasticsearch connect info:" + client.toString());
//关闭客户端
client.close();
}
/**
* 获取客户端连接信息
* @Title: getConnect
* @author sunt
* @date 2017年11月23日
* @return void
* @throws UnknownHostException
*/
@SuppressWarnings({ "resource", "unchecked" })
@Before
public void getConnect() throws UnknownHostException {
client = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddresses(
new InetSocketTransportAddress(InetAddress.getByName(HOST),PORT));
System.out.println("连接信息:" + client.toString());
}
/**
* 关闭连接
* @Title: closeConnect
* @author sunt
* @date 2017年11月23日
* @return void
*/
@After
public void closeConnect() {
if(null != client) {
System.out.println("执行关闭连接操作...");
client.close();
}
}
/**
* 创建索引库
* @Title: addIndex1
* @author sunt
* @date 2017年11月23日
* @return void
* 需求:创建一个索引库为:msg消息队列,类型为:tweet,id为1
* 索引库的名称必须为小写
* @throws IOException
*/
@Test
public void addIndex1() throws IOException {
IndexResponse response = client.prepareIndex("msg", "tweet", "1").setSource(XContentFactory.jsonBuilder()
.startObject().field("userName", "张三")
.field("sendDate", new Date())
.field("msg", "你好李四")
.endObject()).get();
System.out.println("索引名称:" + response.getIndex() + "\n类型:" + response.getType()
+ "\n文档ID:" + response.getId() + "\n当前实例状态:" + response.status());
}
/**
* 根据索引名称,类别,文档ID 删除索引库的数据
* @Title: deleteData
* @author sunt
* @date 2017年11月23日
* @return void
*/
@Test
public void deleteData() {
DeleteResponse deleteResponse = client.prepareDelete("msg", "tweet", "1").get();
System.out.println("deleteResponse索引名称:" + deleteResponse.getIndex() + "\n deleteResponse类型:" + deleteResponse.getType()
+ "\n deleteResponse文档ID:" + deleteResponse.getId() + "\n当前实例deleteResponse状态:" + deleteResponse.status());
}
/**
* 更新索引库数据
* @Title: updateData
* @author sunt
* @date 2017年11月23日
* @return void
*/
@Test
public void updateData() {
JsonObject jsonObject = new JsonObject();
jsonObject.addProperty("userName", "王五");
jsonObject.addProperty("sendDate", "2008-08-08");
jsonObject.addProperty("msg","你好,张三,好久不见");
UpdateResponse updateResponse = client.prepareUpdate("msg", "tweet", "1")
.setDoc(jsonObject.toString(),XContentType.JSON).get();
System.out.println("updateResponse索引名称:" + updateResponse.getIndex() + "\n updateResponse类型:" + updateResponse.getType()
+ "\n updateResponse文档ID:" + updateResponse.getId() + "\n当前实例updateResponse状态:" + updateResponse.status());
}
/**
* 添加索引:传入json字符串
* @Title: addIndex2
* @author sunt
* @date 2017年11月23日
* @return void
*/
@Test
public void addIndex2() {
String jsonStr = "{" +
"\"userName\":\"张三\"," +
"\"sendDate\":\"2017-11-30\"," +
"\"msg\":\"你好李四\"" +
"}";
IndexResponse response = client.prepareIndex("weixin", "tweet").setSource(jsonStr,XContentType.JSON).get();
System.out.println("json索引名称:" + response.getIndex() + "\njson类型:" + response.getType()
+ "\njson文档ID:" + response.getId() + "\n当前实例json状态:" + response.status());
}
}
4. 运行项目
运行addIndex1方法
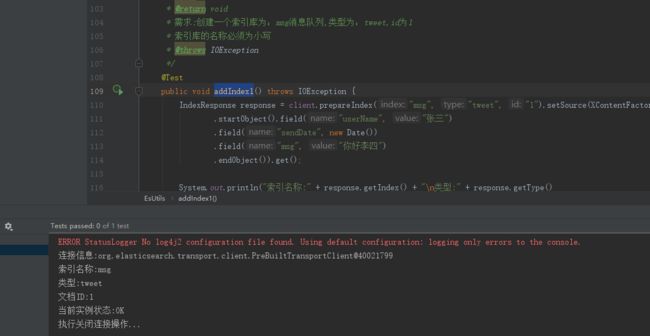
运行updateData方法

运行deleteData方法

运行addIndex2方法
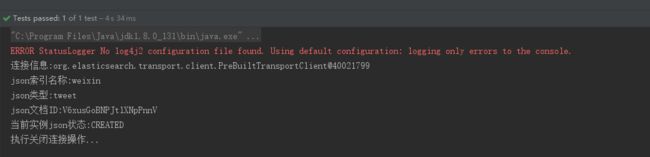
七、项目源码与参考资料下载
链接:https://pan.baidu.com/s/1pRyg_1OEQeeS18AF7X17TA
提取码:2pqc
八、参考文章
- https://blog.csdn.net/wolovexiexiongfei/article/details/83022146
- https://blog.csdn.net/JENREY/article/details/81290535