作者简介:
李中凯
八年多工作经验 前端负责人,
擅长JavaScript/Vue。
掘金文章专栏:https://juejin.im/user/57c7cb8a0a2b58006b1b8666/posts
公众号:1024译站
Web 浏览器无疑是用户访问互联网最常见的入口。浏览器凭借其免安装和跨平台等优势,逐渐取代了很多传统的富客户端。
Web 浏览器通过向 URL 发送网络请求来访问 Web 服务器资源,并以交互性的方式展示这些内容。基本操作包括获取、处理、显示和存储。常见的浏览器包括 Internet Explorer、Firefox、谷歌 Chrome、Safari 和 Opera 等。

浏览器架构图
浏览器主要由以下几个部分组成:
- 用户界面
- 浏览器引擎
- 渲染引擎
- 数据存储层
- UI BackEnd
- JavaScript 解析器 (脚本引擎)
- 网络层
用户界面
这是用户与浏览器发生交互的区域。浏览器的外观没有特定的标准,HTML5 规范没有规定 UI 元素该长什么样,但是列了一些常见元素:地址栏、个人信息栏、滚动条、状态栏和工具栏等。
浏览器引擎
它提供了 UI 与底层渲染引擎之间的接口,根据用户交互进行查询和操控渲染引擎,提供初始化加载 URL 的方法,并负责重新加载、返回和前进等操作。
渲染引擎
渲染引擎负责在屏幕上显示网页内容。渲染引擎的主要工作是解析 HTML。渲染引擎默认可展示 HTML、XML和图片,还可以通过插件或扩展程序支持其他数据类型。
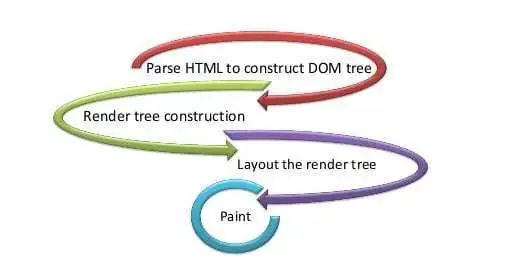
渲染引擎工作过程
现代浏览器使用不同的渲染引擎:
Gecko:Firefox
Webkit:Safari
Blink:Chrome, Opera (version 15 以上).
可以参考这篇:各种浏览器引擎傻傻分不清楚?终于有人说明白了!
web 内容渲染过程大致如下:
HTML 数据转成 DOM
来自网络层的请求内容在渲染引擎中接收(通常是 8 kb 的块),然后将原始字节转换为 HTML 文件中的字符(基于字符编码)。接着词法分析器进行词法分析,将输入分解为各种标记(token)。在标记化过程中,文件中的每个开始和结束标签都被记录下来。它知道如何去掉不相关的字符,比如空格和换行符。
接着,解析器进行语法分析,通过分析文档结构,应用语言语法规则构造解析树。解析过程是迭代进行的。它向词法分析器请求新的 token,如果匹配语法规则,token 就被添加到解析树中。然后再请求另一个 token。如果没有匹配的规则,解析器将在内部存储 token,并不断请求新 token,直到找到匹配所有内部存储 token 的规则。如果没有找到规则,解析器将抛出异常,说明文档无效,包含语法错误。
这些节点在 DOM(文档对象模型)树数据结构中互相链接,建立父子关系、相邻兄弟关系。
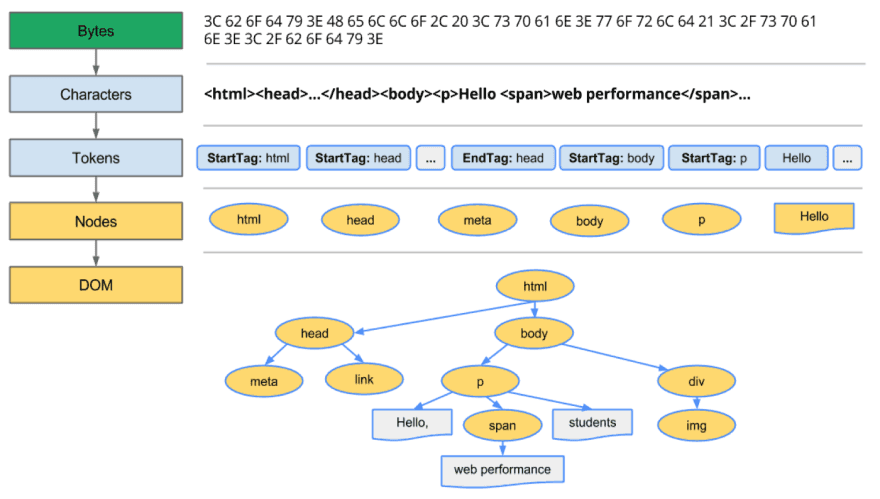
dom-tree
CSS 数据转成 CSSOM
CSS 数据原始字节被转换成字符、token、节点,最终变成 CSSOM(CSS 对象模型)。CSS 的层级特性决定了元素会应用什么样式。元素的样式数据可以来自父元素(通过继承),也可以直接在元素上设置。浏览器需要递归遍历 CSS 树结构来确定特定元素的样式。
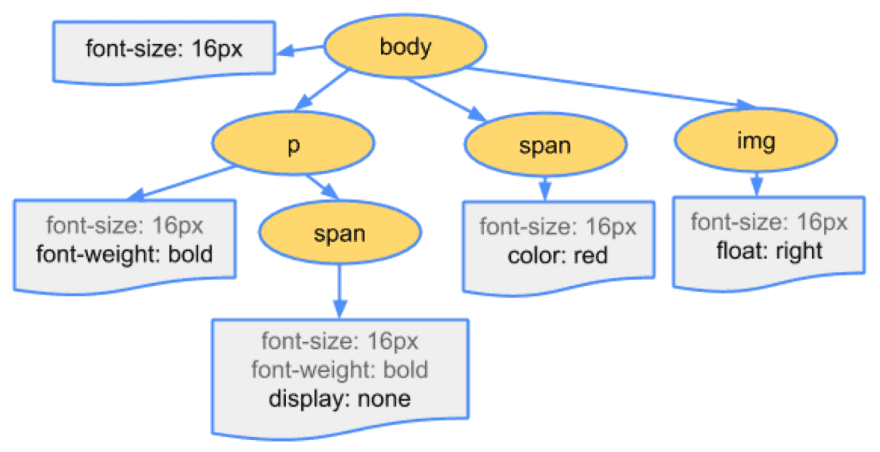
cssom-tree
DOM 与 CSSOM 组成渲染树
DOM 树包含了 HTML 元素之间的关系信息,CSSOM 树则包含了这些元素的样式信息。从根节点开始,浏览器会遍历每一个可见节点。有些节点是隐藏的(通过 CSS 控制),不会出现在渲染结果中。对于每个可见节点,浏览器找到 CSSOM 中定义的相关规则进行匹配,最终这些节点会带着内容和样式出现在渲染树中。
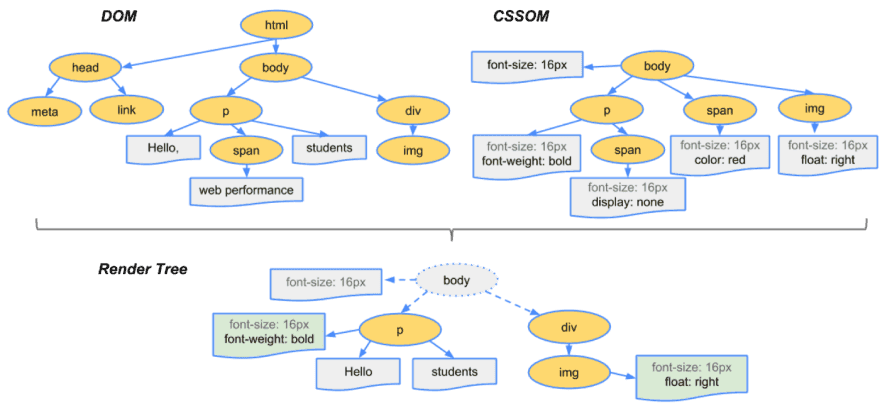
render-tree
布局
接下来进行内容布局。内容的实际尺寸和位置需要经过计算才能渲染到页面上(浏览器视口)。这个过程也叫重排(reflow)。HTML 采用基于流的布局模型,也就是说大部分情况下,几何位置是一次性计算出来的(内容大小或位置发生变化,需要重新计算)。这个过程是从文档根元素开始,递归完成的。
绘制
通过遍历每个渲染器,并调用paint方法在屏幕上显示内容。绘制过程可以是全局的(绘制整个树),也可以是增量的(渲染树在屏幕上验证某个矩形区域),操作系统在这些特定节点上生成绘制事件,整个树不受影响。绘制是一个渐进的过程,其中一部分在被解析和渲染过后,而该过程将继续处理其余部分。
JavaScript 解析器 (JS 引擎)
JavaScript 是一种脚本语言,可动态更新 Web 内容、控制多媒体和动画等,这些是通过浏览器的 JS 引擎完成的。DOM 和 CSSOM 提供了 JS 接口,都可以通过 JS 修改。由于浏览器不确定某些 JS 会做什么,因此它会在遇到 script 标签后会立即暂停构建 DOM 树。
JS 解析器在接收到服务器发送来的代码后,会立即进行解析。代码被转换成机器能理解的对象表示形式。保存了所有解析信息的对象叫做抽象语法树(AST),这些对象又被解析器转换成字节码。这种编译方式叫做Just In Time (JITs) ,也就是 JavaScript 从服务器下载后在客户端实时编译。解析器和编译器是组合使用的,解析器立即处理源代码,编译器则生成机器码,客户端操作系统可直接运行。
不同浏览器的 JS 引擎
Chrome: V8 引擎 (Node JS was built on top of this)
Mozilla: Spider Monkey (以前叫 ‘Squirrel Fish’)
Microsoft Edge: Chakra
Safari: Nitro
UI 后台
用于绘制基础控件,比如复选框和窗口等。底层使用操作系统的用户界面方法,暴露通用的接口,跟平台无关。
数据存储层
这是持久化层,辅助浏览器保存一些数据(比如cookies,session storage,indexed DB,Web SQL,书签,用户偏好设置等)。HTML5 规范提出了浏览器端的完整数据库功能。
网络层
这一层处理浏览器的各种网络通信。浏览器使用各种通信协议获取网络资源,比如 HTTP、HTTPs、FTP 等。
浏览器用 DNS 解析 URL。这些解析记录缓存在浏览器、操作系统、路由器或者 ISP 中。如果请求的 URL 不在缓存中,ISP 的 DNS 服务器首先发起 DNS 查询,找到服务器的 IP 地址。找到正确的 IP 地址后,浏览器使用特定的协议与服务器建立连接。浏览器向服务器发送 SYN 数据包,询问服务器是否打开了 TCP 连接。服务器用 SYN/ACK 数据包响应作为前面 SYN 的应答。
浏览器接收到应答后,再向服务器发送 ACK 数据包。通过这样的三次握手就建立了 TCP 连接。一旦建立了连接,就可以传输数据了。传输数据过程中必须遵守 HTTP 协议的相关要求,包括请求和响应的规则等。
浏览器比较
如今市面上有各种不同的浏览器,尽管核心功能都是相同的,但是它们之间的区别也是多方面的。包括平台(Linux,Windows,Mac,BSD 以及其他 Unix 系统)、协议、用户界面、HTML5 支持情况、是否开源、所有权等等,具体可参考维基百科https://en.wikipedia.org/wiki/Comparison_of_web_browsers.
作者简介:
李中凯
八年多工作经验 前端负责人,
擅长JavaScript/Vue。
掘金文章专栏:https://juejin.im/user/57c7cb8a0a2b58006b1b8666/posts
公众号:1024译站
本文已经获得李中凯老师授权转发,其他人若有兴趣转载,请直接联系作者授权。