【拒绝内卷】狼吃羊的AI奖励机制不合理: 内卷,如何解决?
深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
本文转载自:Ai科技评论

作者 | 耳洞打三金
大家好,我是三金。
前几天我在上班摸鱼的时候,发现朋友圈好多人都在转一个狼吃羊的AI智障游戏,是在讲狼发现自己吃不到羊的情况下直接选择自杀:
自杀的场景大概如下:

事情是这样的,就在前几天,微博上一位网友@二雨TR发文称 “听我老师给我讲他搞游戏ai的事情他妈笑死我了 。”
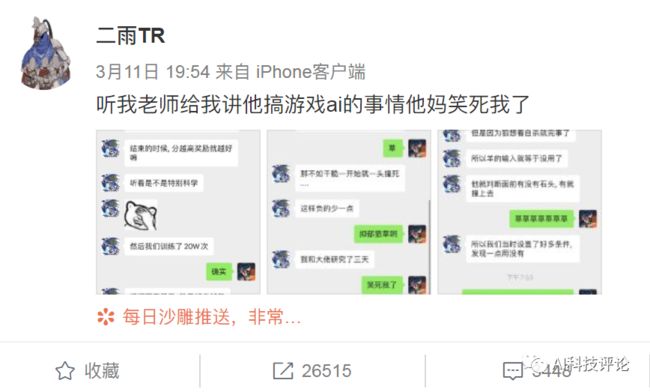
目前这条微博已经有两万多转发、三千多评论,并且这条微博上的三张图已经火出了圈,在朋友圈、知乎、豆瓣等很多平台都能见到它的身影。
下面就来看一下这三张图都讲了啥吧:


狼为什么会选择直接撞死呢?
因为自杀分数最高:
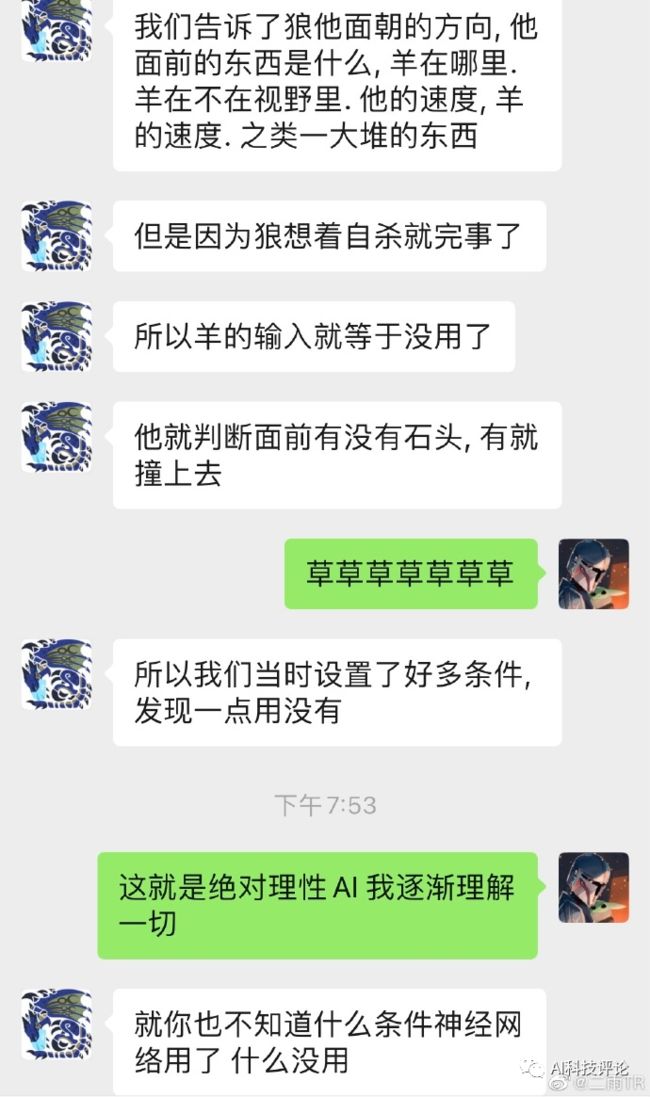
如果抓羊,在狼学会躲避障碍物之前它是碰不到羊的。假设前5w次狼做了一些绕开障碍的尝试但是都死了。
那他通过这5w次学到的东西就是——
原地站着15秒得-1.5分;
一头扎死得-1.1分;
尝试绕路但是撞死得-1.1 到-2.4分。
所以由于狼根本没有吃到过羊,因此狼在-1.1到-2.4分之间选择了-1.1,也就是自杀。
那么不懂强化学习的网友们如何看待这件事呢?
连人工智能都开始知道拒绝内卷了
网友们眼很尖心很细,把AI狼自杀和内卷联系到了一起:

AI:就这? 你们还tm想着我统治人类?
连人工智能都知道拒绝内卷的。
狼就是打工人...每秒扣的是青春和时间,羊永远达不到的“升职、加薪、迎娶白富美、走上人生巅峰”。
面对不合理的KPI和奖惩机制,连ai展现出了令人类叹为观止的尊严。
为了激励狼快点抓羊而倒扣分是错误的,相反,应该激励狼活下去而每秒加0.1分。想要最高分当然会尽量抓羊,抓不到羊还撞障碍物扣分已经很劝退了,只有加分才能激励狼活下去。太现实了,只有活着本身就是一种奖励,人才愿意活下去。要不然真的不如一头撞死。
请给狼加一个参数:生命成本。这个参数的定义是我活这么大不容易随便死了太不值了。每次抓不到羊挫败-0.1,但每多活一天就累积+1,降到0才执行自杀,你就收获了一群要死不死的社畜狼了。









关于以上网友的发言,尽管和强化学习不沾边,但是我们也可以看着乐一乐,某些玩笑话或许在冥冥之中还是有某些道理的。
奖励机制不合理
有网友直言这是强化学习的奖励函数机制做的不合理,碰撞的惩罚太大了且死亡的惩罚应该给到负无穷大,让狼知道痛的滋味和代价,这样狼就不会选择自杀了:


这个狼自杀的事虽然是因为奖励机制设置不合理的原因导致的,但总归还是很有意思的,所以三金我决定深入事件背后一线吃瓜 。
。
据了解,文章开头发三张聊天截图的网友@二雨TR 并不是程序猿而是一位游戏绘画师,而她口中的老师是墨尔本的一位在读研究生。

三金与二雨TR口中的老师 @星尘研 取得了联系,在联系之后,星尘研表示狼自杀的错误是很多东西共同影响产生的,最主要的一个错误是迭代次数太少,20W次完全不够学,后面提高到100W次起步, 效果直线上升。
狼之后是可以成功抓到羊的:
另一个就是奖励分数设置有问题,最后他们控制在了-2到1之间,效果也很好。大概在第十九代狼的时候就差不多可以用了,但是因为项目时间问题就没再接着往后训练了, 狼还是有点蠢。
更巧的是星尘研刚好把这个事情的大概经过以及狼抓羊的游戏录制了一个说明视频放在了B站上面:
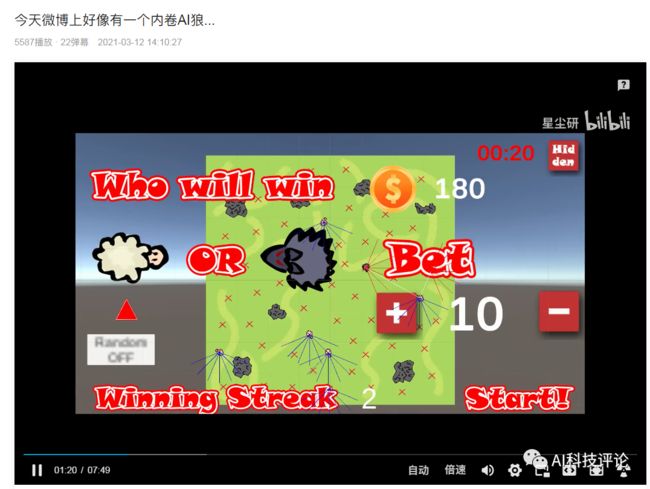
据星尘研向三金介绍,他目前研究生专业是“动画,游戏和交互”,本科时候的专业是游戏和图形编程Games and Graphics Programming, 这个狼抓羊的项目是他本科最后一年的AI课和泰国的一位同学合作完成的,这时当时课程其中的一个作业,要求仅是【使用神经网络和强化学习、遗传算法等配合制作一个AI相关的游戏】。
星尘研表示他只是AI的初学者、门外汉,也是第一次接触强化学习,懂得不多,一切都是摸索着来的。
“这个项目一共4-5个星期,决定做什么, 然后怎么设计这套东西就花了一个星期, 再弄环境和开始的碰壁也花了不少时间,所以最后实际用在调算法bug的时间并不是很多。”
游戏整体都是在Unity上面开发的,开发语言是C#,算法主体是基于Unity上封装好的一个强化学习包——MLAgent,GPU用的是他朋友淘汰的2手1080 Ti 。
星尘研表示而他们摸索的过程并不顺利:
我们最初的一个目标是让狼学会判断他要抓的是羊,并且学会去抓,这里的区别点在于狼要能认识到他要去吃羊,而不是我直接把羊的位置给他, 让狼自己去追。
比如下面这是我们最开始的训练场景,在前几千次训练的时候, 狼都不知道要去吃羊,每次训练狼有大概5秒钟的时间在这个场地上面方向随机的乱跑乱逛 。在这个过程中, 狼可能会无意中吃到羊,并发现, 这一次的得分也许比之前要高,那么狼就可以靠得到更多分的奖励来慢慢学习抓羊。

最开始的训练没有使用障碍物的原因, 就是要让狼先学到抓到羊,不然游戏没法继续。
之后刚把障碍物加入时, 狼会特别完美的躲开障碍物,但是把障碍物稍微挪一下, 或者换一个形状,就不行了,原因就是狼只是记住了哪些点不能碰,而不是真正学会了识别障碍物。

这时会发生很多种情况,比如说其中三种:
1. 狼游荡了10秒, 什么都没碰 -> 得-0.6分。
2. 狼游荡了10秒, 什么都没碰,并且吃了羊 -> 得0.4分。
3. 狼花了3秒, 碰了一个障碍, 但是吃到了羊 -> 得0.72分。
可以看出这时狼即使撞了石头也还是有一个不错的得分的。
至于狼吃羊游戏的基本目标则是:
狼的目标:在20秒的时间内得分越高越好。
羊的目标:存活时间越长得分越高。
狼吃羊游戏基本规则描述:

1、开局两只狼(训练时其实是一只)、六只羊,位置随机,石头位置随机 ,地图上带 X的符号就是狼和羊可能随机出现的位置。
2、狼和羊的感知范围由坐标面前的射线所定义,狼面前的6根线是会和障碍物以及地图边界碰撞的,碰撞的时候会返回一个坐标。
3、狼和羊之间的白线是狼和最近的羊之间连接,狼每次优先去吃离它最近的羊。
4、最开始把羊固定了位置,狼学会抓羊之后,才让羊动。
5、羊撞到石头不会死,羊的高分条件只有一个:存活时间尽量长。羊没有说被训练成要故意躲着狼,羊被吃没有直接惩罚,也不会主动躲避石头。
6、狼得分高的背后就意味着:
狼吃到羊的数量越多越好:抓羊的奖励是每只=1/羊的数量,抓到所有羊奖励为1。
吃到羊所用时间越短越好:表现在狼多花费一秒则每秒惩罚0.06,撞到石头扣0.2。
7、狼和羊是有面积大小的,地图大小在Unity里是80X80 。
而星尘研他们在发现狼自杀后的三天内也不是什么都没做:
为何要让狼撞石头死亡呢?
星尘研的解释是“只是为了加快训练时间,因为在狼学会吃到羊之前它可能只会打转会原地不动来等时间消耗,大大增加了训练所花费的时间。”
在训练了300万次后,狼已经可以成功地吃到羊:
虽然有时是在最后一刻才吃到全部的羊:
当然游戏因为各种原因还是存在缺陷的,比如两只狼还是会偶尔撞石头而死:
两只狼会对着石头硬怼,绕不过去,就把自己磕死:
上面的一只狼出现了未知的bug导致它原地死亡:
两只狼之间无形之间学会了合作?
狼吃羊的游戏先演示到这里,想看到更多的案例可以移步原视频。
这里多问一句有没有更合理的奖励和惩罚机制呢?
知乎网友@曾伊言给出了回答:

而关于强化学习更多的知识,建议大家阅读强化学习领域圣经之书——《强化学习导论》第二版。

那么除了这个狼吃羊的游戏之外,AI出Bug或者说AI智障的例子还多吗?
那难道就没有那种表现聪明的、行为成熟的、多智能体合作的强化学习 AI 吗?
当然也有,这里不得不提一下Open AI的AI玩捉迷藏游戏:

这个强化学习游戏项目的参与者有毕业于姚班现又回姚班教学的吴翼。
吴翼师从人工智能泰斗、加州伯克利大学 Stuart Russell 教授,其论文 Value Iteration Network 荣获 NIPS 2016 年度最佳论文奖;多次在 ACM-ICPC 竞赛中取得好成绩,两次参加全球总决赛获得一枚银牌一枚铜牌。

具体而言,研究者在这个项目中创造了一个模拟环境,环境中有许多物体,例如箱子、梯子以及小蓝人和小红人。小蓝人代表捉迷藏游戏中的“藏匿者”,小红人代表游戏中的“寻找者”。
小红人的目的就是为了抓住小蓝人,当然,捉迷藏游戏总是要给藏匿者提供准备时间,所以在游戏开始的一段时间,小红人(寻找者)需要等在原地不能动让小蓝人(藏匿者)做好准备。经过强化学习和多智能体的自博弈,发现藏匿者和寻找者之间生成了很多种策略和反策略。
在训练最初阶段的策略是:小红人追着小蓝人跑,小蓝人只能四处逃窜。
起初,AI们完全不知道自己能做什么,只是出于“本能”逃跑、追逐。
但是在2500万次游戏训练之后,小蓝人学会了通过移动箱子,来建造把自己藏起来的庇护所。
道高一丈魔高一尺。又经过了7500万次训练之后,小红人在没有任何人指导的情况下全凭自己学会了将斜坡移动到小蓝人用箱子搭建的“城堡”旁边,然后借助斜坡闯进“城堡”!
小蓝人在这样输了1000万次之后,竟学会了提前把斜坡给搬进城堡让小红人无坡可爬。
AI只会单打独斗吗?
当然不是,仔细观察后很容易发现,小蓝人之间自主地学会了很有策略性的团队配合:
场景比较封闭、太简单了?
那就换一个更加开放的场景来试试。
在3.8亿次游戏训练之后可以看到,在小蓝人把所有的斜坡都给锁住、并且把自己给保藏起来之后,小红人竟然自主地学会了移动箱子到锁住的斜坡旁边,然后通过斜坡跳到箱子上,然后踩着箱子移动,就好像在冲浪一样,一路来到了小蓝人旁边并跳到里面抓住了小蓝人。
而据研究者爆料,其实“踩着箱子移动”是系统设定产生的“bug”,小红抓住并利用上了这个bug !可真是太鸡贼了,且稍微有些反人类直觉。
最后在将近5亿次训练之后,针对小红人的鸡贼,小蓝人直接放大招!
把梯子和箱子都锁起来,让小红人无法使用任何工具:
好家伙,这群AI,可真TM好家伙。
最后借此谈一谈大的愿景:
从生物进化的角度来看,人类是一个可以不断适应新环境的物种,但人工智能却不是这样。因此,越来越多的研究者希望构建在行为、学习和进化等方面更类人的机器智能。
由于捉迷藏游戏中的目标相对简单,多个智能体通过竞争性的自我博弈进行训练之后,可以学会如何使用工具和类人一样的技能取得游戏中的胜利。
而在这种简单环境中以自监督的方式学到的复杂策略进一步表明,多智能体协同合作适应在将来某一天很有可能生成极度复杂和智能的行为。OpenAI 相信,这一研究会成为一个智能体开发和部署的非常有前景的方向。
而DeepMind 创始人哈萨比斯对游戏AI 则是这样来看的:
游戏AI是通往通用人工智能的垫脚石。我们研究这些游戏的真正原因是,它是研究通用AI算法的一个非常方便的试验场。
我们正在开发一种新算法,可以将其转化到现实世界中来,用于解决现实中真正具有挑战性的问题,并帮助这些领域的专家。
而用游戏的方式训练出可以在真实场景里应用的AI技术,可以称得上是创造了一个小世界,在这个小世界发生的魔幻的事在将来一天未必不会出现在现实生活中。

最后回到狼吃羊身上,也许未来的某一天真的会“狼”来了,而人类就是那“可爱善良但不无辜”的小绵羊......
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5:2019年-57篇深度强化学习文章汇总
总结6: 万字总结 || 强化学习之路
总结7:万字总结 || 多智能体强化学习(MARL)大总结
总结8:深度强化学习理论、模型及编码调参技巧
完
第103篇:解决MAPPO(Multi-Agent PPO)技巧
第102篇:82篇AAAI2021强化学习论文接收列表
第101篇:OpenAI科学家提出全新强化学习算法
第100篇:Alchemy: 元强化学习(meta-RL)基准环境
第99篇:NeoRL:接近真实世界的离线强化学习基准
第98篇:全面总结(值函数与优势函数)的估计方法
第97篇:MuZero算法过程详细解读
第96篇: 值分布强化学习(Distributional RL)总结
第95篇:如何提高"强化学习算法模型"的泛化能力?
第94篇:多智能体强化学习《星际争霸II》研究
第93篇:MuZero在Atari基准上取得了新SOTA效果
第92篇:谷歌AI掌门人Jeff Dean获冯诺依曼奖
第91篇:详解用TD3算法通关BipedalWalker环境
第90篇:Top-K Off-Policy RL论文复现
第89篇:腾讯开源分布式多智能TLeague框架
第88篇:分层强化学习(HRL)全面总结
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
