问题现象
在TKE控制台上新建版本为v1.18.4(详细版本号 < v1.18.4-tke.5)的独立集群,其中,集群的节点信息如下:
有3个master node和1个worker node,并且worker 和 master在不同的可用区。
| node | 角色 | label信息 |
|---|---|---|
| ss-stg-ma-01 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-ma-02 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-ma-03 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-test-01 | worker | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200004] |
待集群创建好之后,再创建出一个daemonset对象,会出现daemonset的某个pod一直卡住pending状态的现象。
现象如下:
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE NODE
debug-4m8lc 1/1 Running 1 89m ss-stg-ma-01
debug-dn47c 0/1 Pending 0 89m
debug-lkmfs 1/1 Running 1 89m ss-stg-ma-02
debug-qwdbc 1/1 Running 1 89m ss-stg-test-01 (补充:TKE当前支持的最新版本号为v1.18.4-tke.8,新建集群默认使用最新版本)
问题结论
k8s的调度器在调度某个pod时,会从调度器的内部cache中同步一份快照(snapshot),其中保存了pod可以调度的node信息。
上面问题(daemonset的某个pod实例卡在pending状态)的原因就是同步的过程发生了部分node信息丢失,导致了daemonset的部分pod实例无法调度到指定的节点上,卡在了pending状态。
接下来是详细的排查过程。
日志排查
截图中出现的节点信息(来自客户线上集群):
k8s master节点:ss-stg-ma-01、ss-stg-ma-02、ss-stg-ma-03
k8s worker节点:ss-stg-test-01
1、获取调度器的日志
这里首先是通过动态调大调度器的日志级别,比如,直接调大到V(10),尝试获取一些相关日志。
当日志级别调大之后,有抓取到一些关键信息,信息如下:
解释一下,当调度某个pod时,有可能会进入到调度器的抢占preempt环节,而上面的日志就是出自于抢占环节。
集群中有4个节点(3个master node和1个worker node),但是日志中只显示了3个节点,缺少了一个master节点。
所以,这里暂时怀疑下是调度器内部缓存cache中少了node info。
2、获取调度器内部cache信息
k8s v1.18已经支持打印调度器内部的缓存cache信息。打印出来的调度器内部缓存cache信息如下:![]()
![]()
![]()
![]()
可以看出,调度器的内部缓存cache中的node info是完整的(3个master node和1个worker node)。
通过分析日志,可以得到一个初步结论:调度器内部缓存cache中的node info是完整的,但是当调度pod时,缓存cache中又会缺少部分node信息。
问题根因
在进一步分析之前,我们先一起再熟悉下调度器调度pod的流程(部分展示)和nodeTree数据结构。
pod调度流程(部分展示)
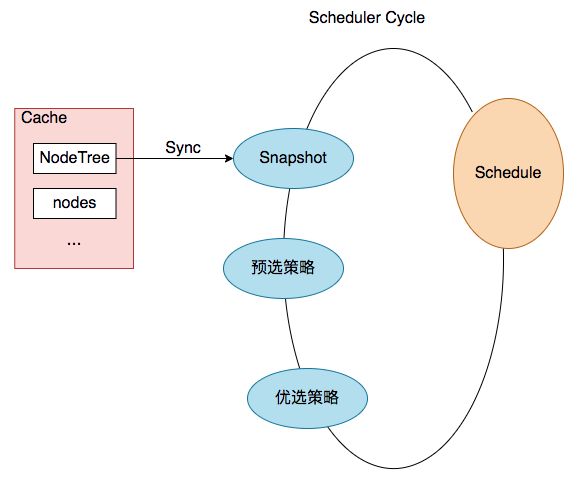
结合上图,一次pod的调度过程就是 一次Scheduler Cycle。 在这个Cycle开始时,第一步就是update snapshot。snapshot我们可以理解为cycle内的cache,其中保存了pod调度时所需的node info,而update snapshot,就是一次nodeTree(调度器内部cache中保存的node信息)到snapshot的同步过程。
而同步过程主要是通过nodeTree.next()函数来实现,函数逻辑如下:
// next returns the name of the next node. NodeTree iterates over zones and in each zone iterates
// over nodes in a round robin fashion.
func (nt *nodeTree) next() string {
if len(nt.zones) == 0 {
return ""
}
numExhaustedZones := 0
for {
if nt.zoneIndex >= len(nt.zones) {
nt.zoneIndex = 0
}
zone := nt.zones[nt.zoneIndex]
nt.zoneIndex++
// We do not check the exhausted zones before calling next() on the zone. This ensures
// that if more nodes are added to a zone after it is exhausted, we iterate over the new nodes.
nodeName, exhausted := nt.tree[zone].next()
if exhausted {
numExhaustedZones++
if numExhaustedZones >= len(nt.zones) { // all zones are exhausted. we should reset.
nt.resetExhausted()
}
} else {
return nodeName
}
}
}再结合上面排查过程得出的结论,我们可以再进一步缩小问题范围:nodeTree(调度器内部cache)到的同步过程丢失了某个节点信息。
\### nodeTree数据结构
(方便理解,本文使用了链表来展示)
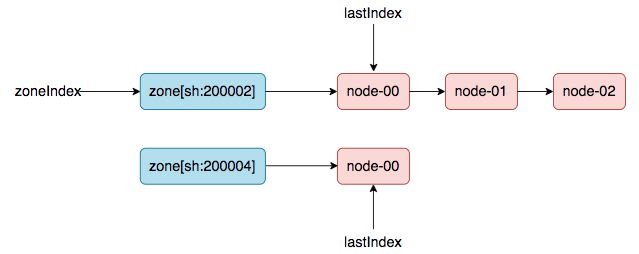
在nodeTree数据结构中,有两个游标zoneIndex 和 lastIndex(zone级别),用来控制 nodeTree(调度器内部cache)到snapshot.nodeInfoList的同步过程。并且,重要的一点是:上次同步后的游标值会被记录下来,用于下次同步过程的初始值。
\### 重现问题,定位根因
创建k8s集群时,会先加入master node,然后再加入worker node(意思是worker node时间上会晚于master node加入集群的时间)。
第一轮同步:3台master node创建好,然后发生pod调度(比如,cni 插件,以daemonset的方式部署在集群中),会触发一次nodeTree(调度器内部cache)到的同步。同步之后,nodeTree的两个游标就变成了如下结果:
nodeTree.zoneIndex = 1,
nodeTree.nodeArray[sh:200002].lastIndex = 3,第二轮同步:当worker node加入集群中后,然后新建一个daemonset,就会触发第二轮的同步(nodeTree(调度器内部cache)到的同步)。同步过程如下:
1、 zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get ss-stg-test-01.
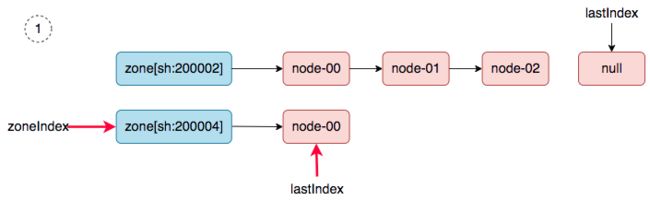
2、 zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=3, return.
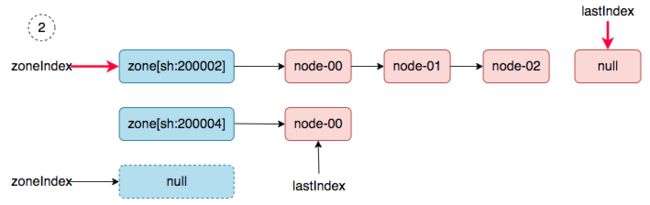
3、 zoneIndex=1, nodeArray[sh:200004].lastIndex=1, return.

4、 zoneIndex=0, nodeArray[sh:200002].lastIndex=0, we get ss-stg-ma-01.
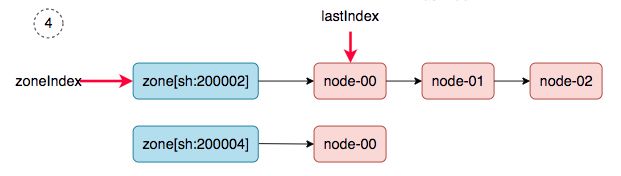
5、 zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get ss-stg-test-01.
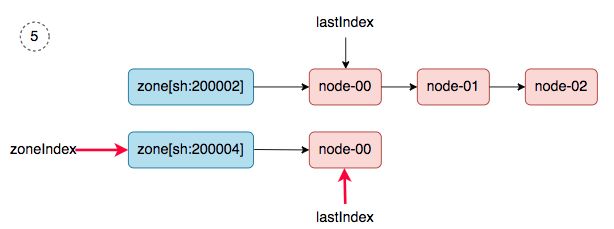
6、 zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=1, we get ss-stg-ma-02.
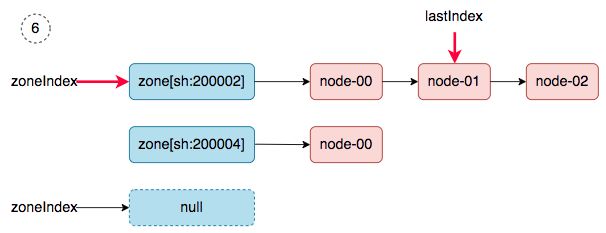
同步完成之后,调度器的snapshot.nodeInfoList得到如下的结果:
[
ss-stg-test-01,
ss-stg-ma-01,
ss-stg-test-01,
ss-stg-ma-02,
]ss-stg-ma-03 去哪了?在第二轮同步的过程中丢了。
解决方案
从问题根因的分析中,可以看出,导致问题发生的原因,在于 nodeTree 数据结构中的游标 zoneIndex 和 lastIndex(zone级别)值被保留了,所以,解决的方案就是在每次同步SYNC时,强制重置游标(归0)。
相关issue:https://github.com/kubernetes...
相关pr(k8s v1.18): https://github.com/kubernetes...
TKE修复版本:v1.18.4-tke.5
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
