玩转词云图,推荐一个Pyecharts和Plotly数据分析实战项目

作者:来源于读者投稿
出品:Python数据之道
本文中使用的数据是一份美食APP的数据,用来进行数据分析、处理和可视化图形的制作,主要包含内容:
数据的多种处理操作
基于
pyecharts和plotly的饼图和柱状图制作基于
Wordcloud和pyecharts的词云图制作利用
jieba分词,和去停用词后的词云图改进
本文数据文件等素材获取方式见文末。
— 01 —
导入库
本文中使用的库比较多,尤其是 pyecharts相关的,库包含:
数据处理相关
pyecharts相关
词云图相关
plotly相关
如果没有装,需要先装下需要的库才能运行
# 数据处理相关
import pandas as pd
import numpy as np
from datetime import datetime
# 在顶部声明 CurrentConfig.ONLINE_HOST
from pyecharts.globals import CurrentConfig, OnlineHostType, NotebookType
# CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
# OnlineHostType.NOTEBOOK_HOST 默认值为 http://localhost:8888
from pyecharts.charts import Page, Bar, Line, Pie
from pyecharts import options as opts
# 分词
import jieba
# plotly相关
import plotly.express as px
import plotly.graph_objects as go
# 词云图相关
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# pyecharts相关
from pyecharts.globals import ChartType,SymbolType,CurrentConfig,NotebookType
CurrentConfig.ONLINE_HOST = OnlineHostType.NOTEBOOK_HOST
from pyecharts.charts import Sankey,Page,Line,Bar,WordCloud
from pyecharts.globals import ThemeType
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
— 02 —
测试Pyecharts
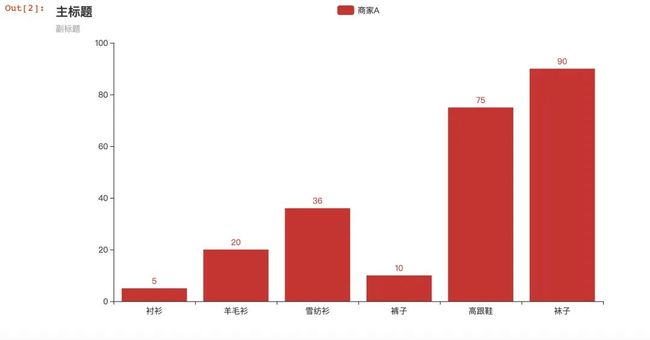
使用官网的示例进行测试,有时候在 jupyter notebook可能出不来图,最好是先进行测试,保证在线出图
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (
Bar()
.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])
.set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"))
# 或者直接使用字典参数
# .set_global_opts(title_opts={"text": "主标题", "subtext": "副标题"})
)
bar.render_notebook()
在jupyter notebook中能够看到图形说明pyecharts出图成功
— 03 —
数据基本信息
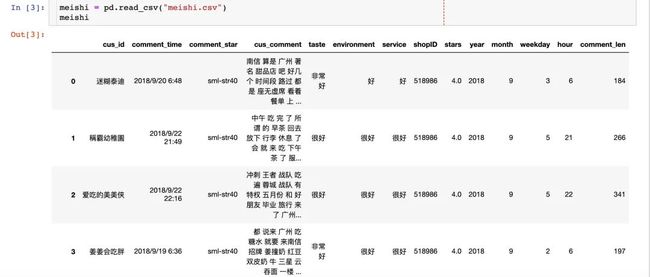
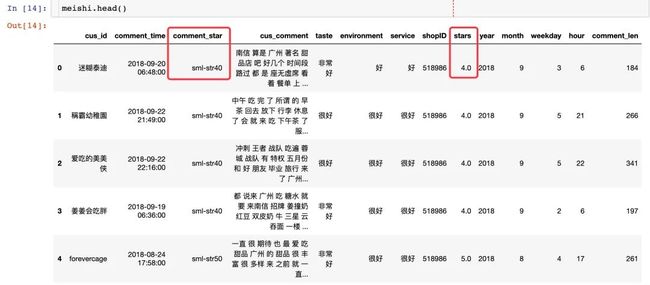
数据信息
数据的主要信息:
用户id: cus_id
评论时间: comment_time
评价: sml-str40,表示4颗星✨
评价内容: cus_comment
口味、环境、服务: taste、environment、service
店铺id:shopID
星星数量:stars
年、月、星期、时间:year/month/weekly/hour
评论长度: comment_len
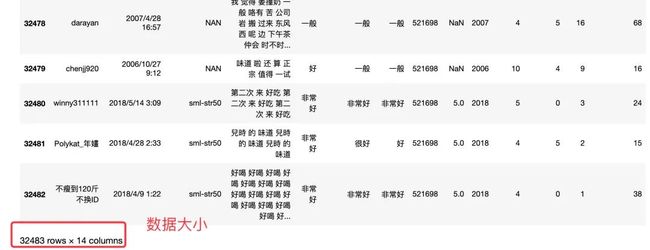
总长度是32483*14的数据
导入数据
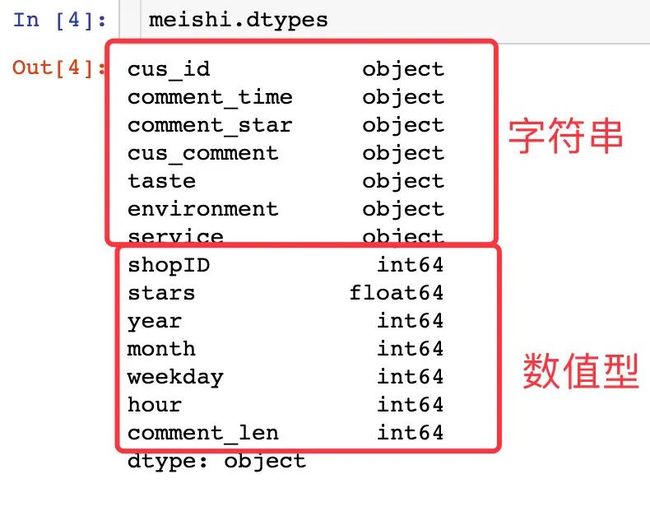
查看数据类型
meishi.dtypes
时间数据转换
将上面????的时间数据comment_time(object)转成时间类型的数据
# 将评论时间comment_time的字符串类型 object 类型转成时间类型
import datetime
meishi["comment_time"] = pd.to_datetime(meishi["comment_time"])
meishi.head(3)

查看转变之后的数据类型:
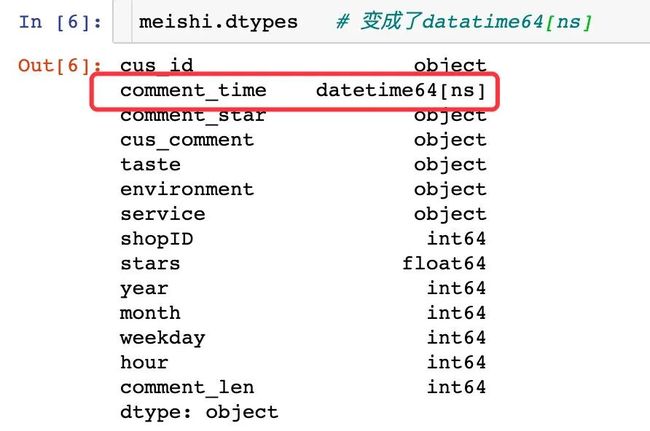
如何将时间类型的数据指定成对应的数据格式:
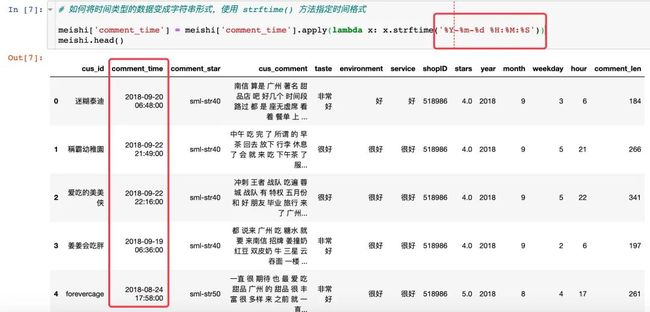
# 如何将时间类型的数据变成字符串形式,使用 strftime() 方法指定时间格式
meishi['comment_time'] = meishi['comment_time'].apply(lambda x: x.strftime('%Y-%m-%d %H:%M:%S'))
meishi.head()
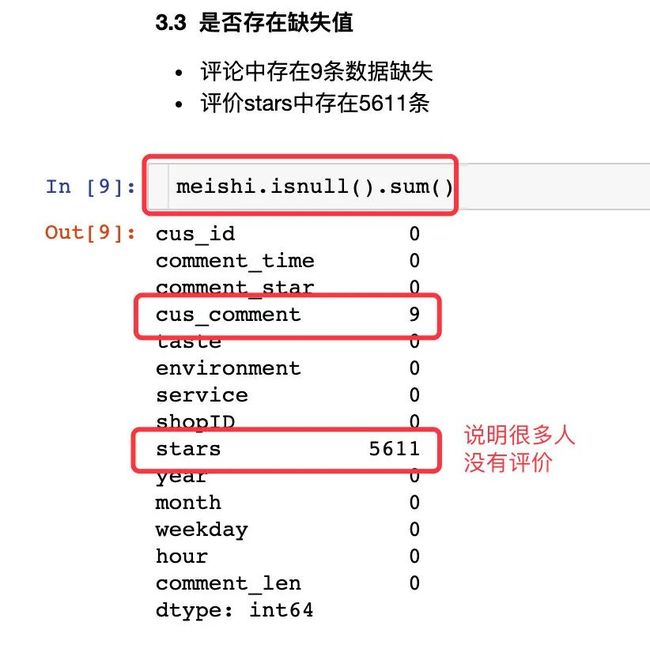
是否有缺失值
查看数据缺失值的方法
meishi.isnull().sum()
— 04 —
数据处理
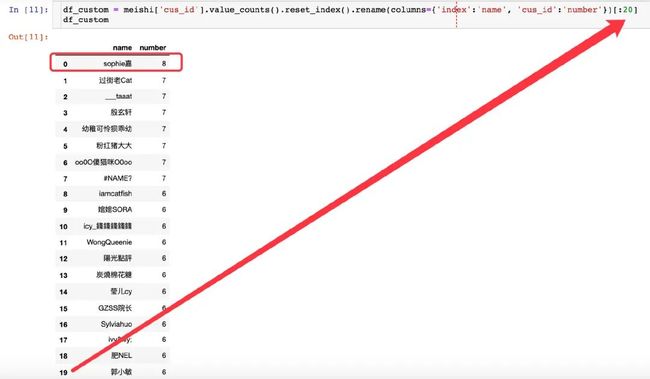
基于用户cus_id
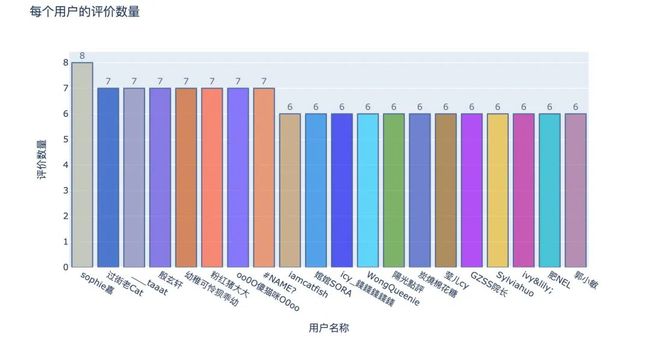
呈现的结果是每个用户对多少个店家进行评价
sophie嘉最多评价了8次
总共有27467个用户进行了评价

选取前20个用户进行绘图
df_custom = meishi['cus_id'].value_counts().reset_index().rename(columns={'index':'name', 'cus_id':'number'})[:20] # 前20个用户
df_custom
# 绘图:基于Plotly
# 颜色的随机生成:#123456 # 加上6位数字构成
def random_color_generator(number_of_colors):
color = ["#"+''.join([random.choice('0123456789ABCDEF') for j in range(6)])
for i in range(number_of_colors)]
return color
text = df_custom.number
trace = go.Bar(
x = df_custom.name,
y = df_custom.number,
text = text,
marker = dict(
color = random_color_generator(100),
line = dict(color='rgb(8, 48, 107)',
width = 1.5)
),
opacity = 0.7 # 透明度设置
)
data_custom = [trace]
# 布局设置
layout = go.Layout(
title = '每个用户的评价数量', # 整个图的标题
margin = dict(
l = 100
),
xaxis = dict(
title = '用户名称'
),
yaxis = dict(
title = '评价数量'
),
width = 900,
height = 500
)
fig = go.Figure(data=data_custom, layout=layout)
fig.update_traces(textposition="outside")
fig.show()
基于时间comment_time
基于评论时间的处理
px.scatter(meishi, x='cus_id', y='comment_time',color='year')

基于星星(stars或comment_star)
对应关系
我们通过观察数据发现,这两个字段是一一对应的关系:
sml-str50:5.0
sml-str40:4.0
sml-str30:3.0
sml-str20:2.0
sml-str10:1.0
NAN:0.0
在这里我们直接分析stars字段即可
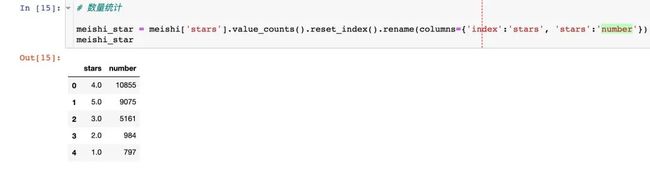
数据处理
绘图
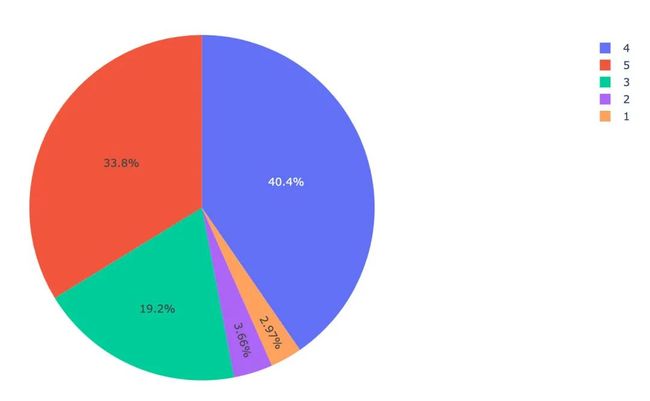
基于 plotly express绘制每个星星数量的占比饼图
px.pie(meishi_star, names='stars', values='number',color='number')
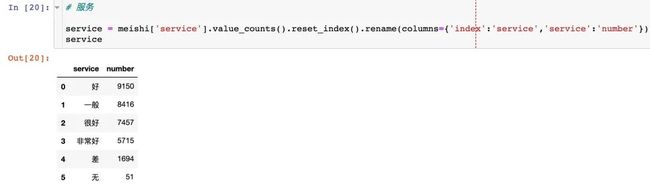
口味-环境-服务
这3个字段的评价分为6种情况: 非常好、很好、好、一般、差、无。我们对6种评价进行饼图和柱状图的绘制
饼图基于
plotly express柱状图基于
pyecharts
数据处理
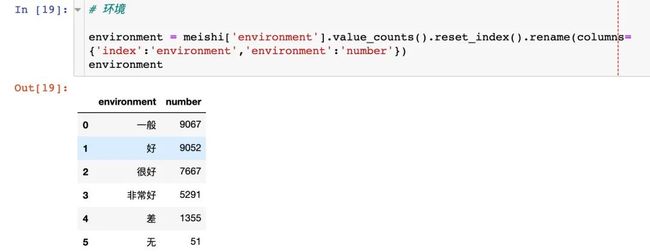
# 口味
taste = meishi['taste'].value_counts().reset_index().rename(columns={'index':'taste','taste':'number'})
taste

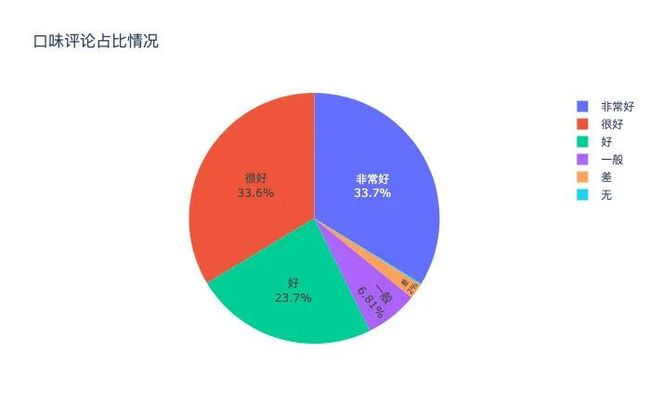
绘图饼图
以口味字段为例,绘制评价的占比饼图
# 口味-taste
fig = px.pie(taste, names='taste', values='number',title = '口味评论占比情况')
fig.update_traces(textposition='inside',textinfo='percent+label')
fig.show()
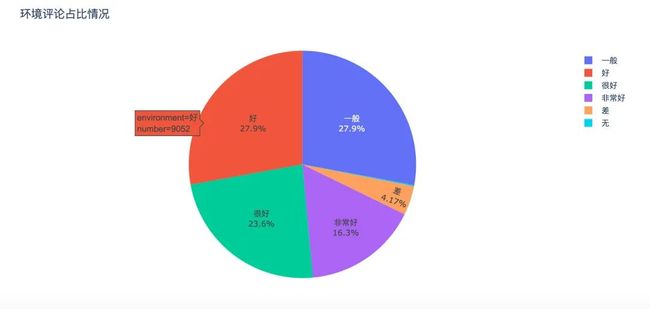
环境和服务的饼图绘制如法炮制,不具体阐述,直接看结果:

绘制柱状图
使用的是Pyecharts这个库绘制
# 三个评价在一个坐标系中
c = (
Bar()
.add_xaxis(taste['taste'].tolist())
.add_yaxis('口味', taste['number'].tolist())
.add_yaxis('环境', environment['number'].tolist())
.add_yaxis('服务', service['number'].tolist())
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="3种指标评价情况"))
# .render("3种评价.html")
)
c.render_notebook()
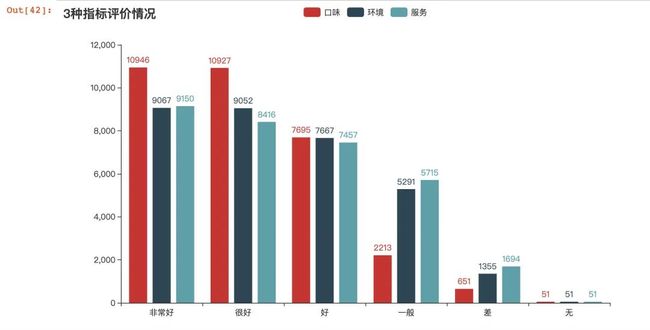
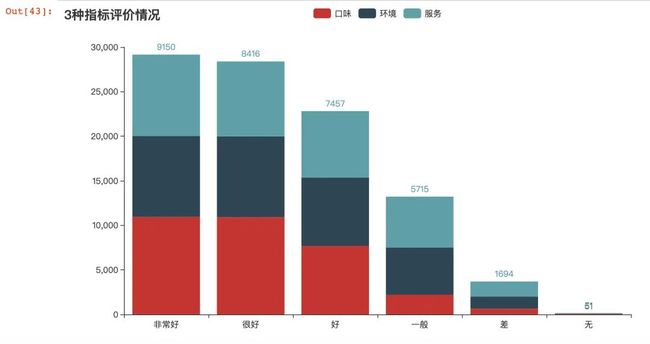
采用堆叠的柱状图
# 使用堆叠柱状图
c = (
Bar()
.add_xaxis(taste['taste'].tolist())
.add_yaxis('口味', taste['number'].tolist(), stack='stack1') # 堆叠柱状图
.add_yaxis('环境', environment['number'].tolist(), stack='stack1')
.add_yaxis('服务', service['number'].tolist(), stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="3种指标评价情况"))
# .render("3种评价.html")
)
c.render_notebook()
基于评论内容cus_comment
我们对顾客的评论使用词云图的方式展示,找出他们全部评论中重点关注的词语
jieba分词
将全部评价内容放在一起

jieba分词
基于WordCloud实现
首先使用的wordcloud中自带的图形形状
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = " ".join(i for i in jieba_name)
# 注意:改成自己的字体路径!!!!!
font = r'/Users/Desktop/spider/SimHei.ttf' # 改成相应的字体的路径即可
wc = WordCloud(collocations=False, font_path=font, max_words=2000,
width=4000, height=4000, margin=4).generate(text.lower())
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file('meishi.png') # 把词云保存下来

使用自定义的图形形状
使用的是一个动漫图画,原始图形为:

#!/usr/bin/env python
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
d = path.dirname('.') # 在ide中使用这段代码
# d = path.dirname(__file__)
# 待处理的文件
text = " ".join(i for i in jieba_name)
alice_coloring = np.array(Image.open(path.join(d, "haizewang.png")))
# 设置停用词
stopwords = set(STOPWORDS)
stopwords.add("said")
# 注意:改成相应的字体的路径!!!!
font = r'/Users/peter/Desktop/spider/SimHei.ttf'
wc = WordCloud(background_color="white", font_path=font,
max_words=3000, mask=alice_coloring,
height=8000,width=8000,
stopwords=stopwords, max_font_size=40, random_state=42)
wc.generate(text)
image_colors = ImageColorGenerator(alice_coloring)
# 图片形状的词云
# 我们还可以直接在构造函数中直接给颜色
# 通过这种方式词云将会按照给定的图片颜色布局生成字体颜色策略
plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
plt.show()
wc.to_file('meishi1.png') # 把词云保存下来
自定义图形形状的结果如下图:

基于pyecharts
在使用pyecharts实现之前,我们先使用去停用词技术将上面????词云图中的无效词语去掉,比如: 所以、真的、不过等,停用词表是自己在收集汇总的
统计单词个数
# 统计每个词的个数
dic = {}
count = 0
for i in jieba_name:
count += 1
dic[i] = count

去停用词
使用的是自己收集的停用词表
# 去停用词
stopwords = [line.strip() for line in open("nlp_stopwords.txt",encoding='UTF-8').readlines()]
stopwords[:10]

停用词反选
使用 反选符号~,留下有用的信息
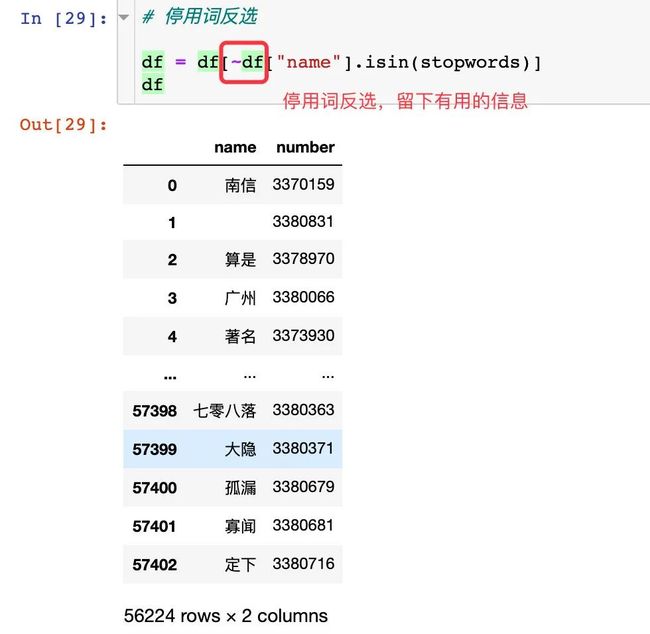
排序
df = df.sort_values("number", ascending=False)
df

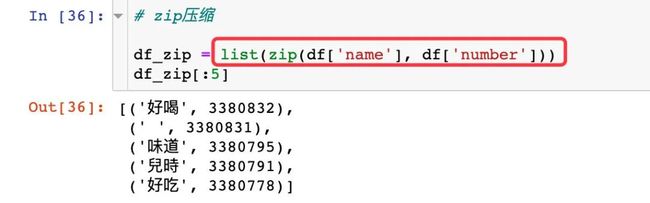
生成绘图数据
使用 zip函数生成绘图的数据
df_zip = list(zip(df['name'], df['number']))
df_zip[:5]
# 结果
[('好喝', 3380832),
(' ', 3380831),
('味道', 3380795),
('兒時', 3380791),
('好吃', 3380778)]
去停用词绘图
在使用去停用词后,基于 pyecharts绘图
# 绘图
c = (
WordCloud()
.add("", data_pair=df_zip[:20],word_size_range=[12,100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title='评论内容词云图'))
# .render("meishi.html")
)
c.render_notebook()

— 05 —
总结
本文主要是对一组美食数据进行了处理和可视化,使用的库主要是 pandas,以及 Plotly 和 pyecharts 两个可视化库,绘制的图形包含:
基于时间的散点图
不同的柱状图????
饼图
不同方式的词云图
为方便大家练习,提供了本文pdf版文章以及数据文件等素材,可以在公号「Python数据之道」后台回复 “20200927” 获取。
关于 Plotly 的内容,「Python数据之道」介绍过多次,可以通过下面的专辑内容来了解:

本文来自公众号读者投稿,欢迎各位童鞋向公号投稿,点击下面图片了解详情!

作者简介
Peter,硕士毕业僧一枚,从电子专业自学Python入门数据行业,擅长数据分析及可视化。喜欢数据,坚持跑步,热爱阅读,乐观生活。
个人格言:不浮于世,不负于己
个人站点:www.renpeter.cn,欢迎常来小屋逛逛
---------End---------
关注后回复“w”,加我私人微信




“分享”和“在看”是更好的支持!