作者:敏丞
在大数据分析领域,Apache Kylin 和 Apache Druid (incubating) 是两个普遍使用的 OLAP 引擎,都具有支持在超大数据上进行快速查询的能力。在一些对大数据分析非常依赖的企业,往往同时运行着 Kylin 和 Druid 两套系统,服务于不同的业务场景。
在2018年8月的Apache Kylin Meetup 活动上,美团点评技术团队分享了他们的 Kylin On Druid 方案(简称 KOD)。那么,美团点评为什么要开发这样一套混合系统?这背后是有什么挑战和考虑呢?本文将围绕这些问题跟大家做探讨,帮助读者理解两个OLAP 引擎之间的差异和各自优势。
Apache Kylin 简介
Apache Kylin 是一个开源的分布式大数据分析引擎,在超大规模数据集上建立数据模型,构建支持多维分析的预计算Cube,提供Hadoop 上的SQL 查询接口及多维分析能力。并开放通用的ODBC、JDBC 或Restful API 接口。这种独特的预计算能力使Apache Kylin 可以应对超大数据集上的查询,并实现亚秒级查询响应。
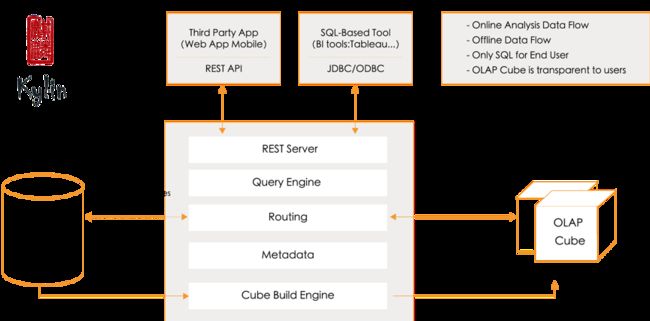
图1 Kylin架构图
Apache Kylin 的优势
基于 Hadoop 成熟的计算引擎(MapReduce 和 Spark),提供了强大的处理超大数据集的预计算能力,能够在主流Hadoop 平台上开箱即用。
支持 ANSI SQL,用户可以使用 SQL 进行数据分析。
亚秒级低延迟响应。
提供 OLAP 通用的星型模型和雪花模型等数据建模方式。
提供丰富的度量(Sum,Count Distinct、Top N、Percentile 等)。
提供智能的 Cuboid 剪枝能力,减少存储和计算资源的消耗。
支持直接跟主流 BI 工具的集成,有丰富的接口。
既支持超大历史数据的批量导入,也支持流数据的微批次导入。
Apache Druid ( incubating )简介
Druid 诞生于 2012 年,是一个开源分布式数据存储,其核心设计结合了分析型数据库、时序数据库、搜索系统的特点,可以处理较大数据集上的数据收集和分析任务。Druid 使用 Apache v2许可,目前是 Apache 基金会孵化项目。
Druid 架构
从 Druid 的部署架构上看,Druid 的进程根据角色主要分为以下三类:
Data Node(Slave 节点,数据摄入和计算)
Historical 负责加载 segment(已提交的不可变数据),接受历史数据查询。
Middle Manager 负责数据摄入和提交 segment,单个 task 由单独 JVM负责。
Peon 负责完成单个 task,由Middle Manager 管理和监控。
Query Node(查询节点)
Broker 接受查询请求,确定数据来自于哪些 segment,分发 sub query 和merge 结果。
Master Node(Master 节点,作业调度和集群管理)
Coordinator 监控 Historical,负责给Historical 分配 Segment 和监控负载。
Overlord 监控 Middle Manager,负责给 Middle Manager 分配任务和协助发布 Segment。
外部依赖
同时 Druid 有三个可替换的外部依赖:
Deep Storage(分布式存储)
Druid 使用 Deep storage 在 Druid 各节点间传输数据文件。
Metadata Storage(元数据存储)
元数据存储了 Segment 的位置和Task 的输出等元数据。.
Zookeeper(集群管理和作业调度)
Druid 使用 Zookeeper (ZK) 来负责集群保证集群状态的一致性。

图2 Druid 架构图
Data Source 和 Segment
Druid 中的数据存放在Data Source 中,Data Source 概念上等同于RDBMS中的表;Data Source 概念上会根据时间戳分为若干个Chunk,同一时间区间产生的数据会归属到同一 Chunk;Chunk 内部由若干个 Segment 组成,每个 Segment 是一个物理上的数据文件,同时 Segment 是一个不可再分的存储单元。出于性能考虑,一个Segment 文件的大小是建议在 500mb 左右。
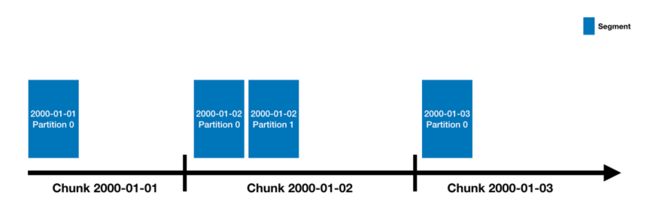
图3 Data Source 和Segment
从 schema 看,因为 Druid具有 OLAP 和 Time Series Database 的特性,列包含三种,分别为时间戳列,维度列和度量列。时间戳列具有Segment 剪枝的作用,维度列和度量列在 Kylin 中有相似的概念。

图4 Druid 中的Schema
Druid 的优势
具有实时摄取数据的能力,数据进入 Druid 即可被查询,延迟为毫秒级,这也是Druid 的最大特点。
支持数据明细查询和聚合查询。
数据存储使用列式存储格式,避免不比较要的 IO。
支持倒排索引,具有良好的过滤性能。
支持冷热数据分离。
为什么美团开发 Kylin on Druid
美团点评自 2015年上线使用 Apache Kylin 做为其离线 OLAP 平台核心组件,服务了几乎所有业务线,数据量和查询次数迅速增长,集群压力越来越大。在这个过程中,美团技术团队不断摸索,针对Kylin 所暴露出的一些问题寻找更优方案,其中一个主要问题就是 Kylin所依赖的存储:Apache HBase。
我们知道,目前的 Kylin 数据存储使用 HBase,存储 Cube 时将维度值和度量值转换成 HBase 的 KeyValue。因为 HBase 不支持二级索引,只有一个行键 (RowKey) 索引,Kylin 的维度值会按照固定的顺序拼接作为 RowKey 存储,那么排在 RowKey 前面的维度,就会获得比后面的维度更好的过滤性能。下面我们来看一个例子。
在测试环境使用两个几乎完全相同的的 Cube(Cube1 和 Cube2),它们的数据源相同,维度和度量也完全相同,两者的唯一差别在于RowKey 中各个维度的顺序:Cube1 将过滤用到的字段(P_LINEORDER.LO_CUSTKEY )放到第一个位置,而 Cube2则将该字段放到最后一个位置。
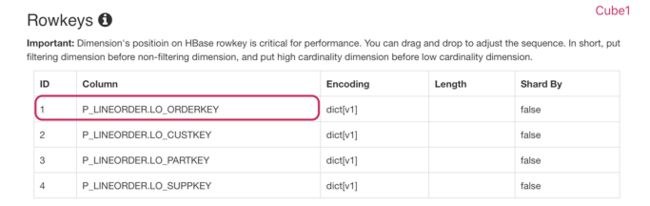
图5 Cube1 的RowKey 顺序
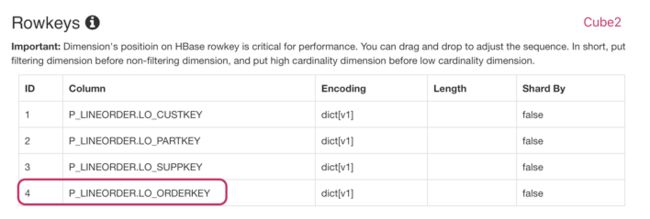
图6 Cube2 的RowKey 顺序
现在我们以相同的 SQL 在这两个 Cube 上进行查询,比较查询用时。
select S_SUPPKEY, C_CUSTKEY, sum(LO_EXTENDEDPRICE) as m1
from P_LINEORDER
left join SUPPLIER on P_LINEORDER.LO_SUPPKEY = SUPPLIER.S_SUPPKEY
left join CUSTOMER on P_LINEORDER.LO_CUSTKEY = CUSTOMER.C_CUSTKEY
WHERE (LO_ORDERKEY > 1799905 and LO_ORDERKEY < 1799915) or (LO_ORDERKEY > 1999905 and LO_ORDERKEY < 1999935)
GROUP BY S_SUPPKEY, C_CUSTKEY;
下图是它们查询时的耗时和扫描的数据量。

图7 Cube1 查询日志

图8 Cube2查询日志
从上面的测试结果看,对于相同的 SQL 语句,两者查询用时相差两百多倍。两者差别的原因主要在于对 Cube2 所在HTable 进行了更大范围的扫描。
此外,Kylin的多个度量值被存储到一个 Key 对应的 Value,当只查询单个度量时,不需要的度量也会被读取,消耗不必要的IO。总之,HBase 的局限,加大了 Kylin 对用户,尤其是业务用户的使用难度。
如果使用纯列式的存储和多维度索引,将大大提升 Kylin 查询性能,同时减小Kylin 的使用难度。从上面的 Druid 的优点介绍我们得知 Druid 正好符合列式+多维度索引这样的特征。因此美团 Kylin 开发团队决定尝试使用 Druid 替换 HBase。
到这里,读者可能会问,为什么不直接使用 Druid 呢?美团的工程师也分享了他们的经验,主要有以下考虑:
Druid 的原生查询语句是自定义的 JSON 格式,不是 SQL,上手有难度;虽然 Druid 社区后来加入了对 SQL 的支持,但是功能尚不完整,不能满足数据分析师的复杂 SQL 查询需求。而Kylin 原生支持 ANSI-SQL,使用 Apache Calcite 做语法解析,对SQL 有很好的支持(支持 join,sub query,window function 等),并且提供 ODBC/JDBC driver 等标准入口,支持跟 Tableau, Power BI, Superset,Redash 等工具直接对接。
Druid 只支持单表查询,而实际业务中多表 join 的场景非常多,难以满足业务需要;而Kylin 支持星型模型和雪花模型,能满足多表查询的形式。
Druid 不能支持精确去重计算;而 Kylin 既支持基于 HyperLogLog 的近似去重,也支持基于 Bitmap 的精确去重度量,对于某些高精度要求场景,Kylin 几乎成了唯一选择。
Druid 的 rollup 功能只支持预计算出 Base Cuboid;相比而言,Kylin 可以定制更多的更丰富的维度组合,更加精确地匹配查询,利于减少现场计算的计算量。
此外从对 Druid 和 Kylin 的使用经验看,直接使用Druid 作为 OLAP 引擎在管理和运维方面有一些挑战:
Druid 没有供业务人员使用的 Web GUI,要建立新模型,只能通过API 来完成,用户友好度低。而 Kylin 提供了易用的 Web GUI,业务人员通过鼠标点选就可以创建新模型,然后使用 SQL 进行查询,易用性高,在进行简单培训后可以交给业务人员自助使用。
Druid 没有友好的集群监控和管理界面,运维难度较大。而 Kylin 基于Hadoop 平台,主流 Hadoop 在监控管理上已经非常完善,有 Ambari, Cloudera Manager 等工具使用。
Druid 需要部署和配置专门的集群,无法利用现有的 Hadoop 集群的计算资源。而大型企业通常已经部署了Hadoop 集群,使用 YARN/Mesos/Kubernets 等标准资源管理器统一管理计算资源;从这一点来说,Druid 需要单独部署和运维。而 Kylin 基于 MapReduce 或 Spark 做数据加工,能够共享 Hadoop 集群的计算资源,做到动态调度,资源使用率高,无需额外运维成本。
因此,把 Druid优秀的列式存储特性,和 Kylin 在易用性、兼容性和完备性相结合,看上去将是一个不错 OLAP 解决方案。Druid 使用了列式存储和倒排索引,过滤性能优于 HBase,并且 Druid 天生具有 OLAP的特性,也具有良好的二次聚合能力。于是,美团点评技术团队决定进行尝试,用 Druid 替换 HBase作为 Kylin 的存储。
Kylin on Druid 的设计介绍
Apache Kylin 1.5 引入了可插拔架构,将计算和存储等模块做了解耦,使得开发替代 HBase 的存储引擎变成可能。在这里我结合美团工程师康凯森的设计文档,简要介绍Kylin on Druid 的主体设计思想(图9和图10来自于参考[1]的附件,文字说明部分来自于参考链接中的[1]和[3])。
构建Cube的流程
生成 Cuboid 数据文件前,增加计算 Druid Segment 数量和更新 Druid Rule 的步骤。
和原先的构建流程一样,通过 MapReduce 生成Cuboid 文件。
将原有的步骤“转换为HFile”替换为“转换为 Druid Segment ”,该步骤将构建好的 Cuboid 文件转化为Druid 的列存格式,输出到 HDFS 指定路径(下图 1号线条)。
发布 Druid Segment 的元数据到 Druid 元数据存储(下图 2号线条)。
Druid Coordinator 会周期性检查元数据存储的新Segment(下图 3号线条),发现新的 Segment 会通知 Historical(下图 4号线条),Historical 收到通知会去 HDFS 拉取 Segment 数据文件到本地并且加载(下图 5号线条)。
等到全部 Druid Segment 被加载完毕后,Cube 完成构建。

图9 构建Cube 流程
查询 Cube 的流程
当 Kylin Query Server 查询数据时,经过Calcite 解析后的 query plan Druid 的查询(scan 或者groupby),并且将请求发送给 Druid Broker。
Druid Broker 会解析请求找到对应的 Historical 分发请求,并且对 Historical 返回的结果再做一次聚合。
Kylin Query Server 通过 HTTP 获取到 Druid Broker 返回的结果,会转化为 Tuple 再交由 Calcite 遍历处理。
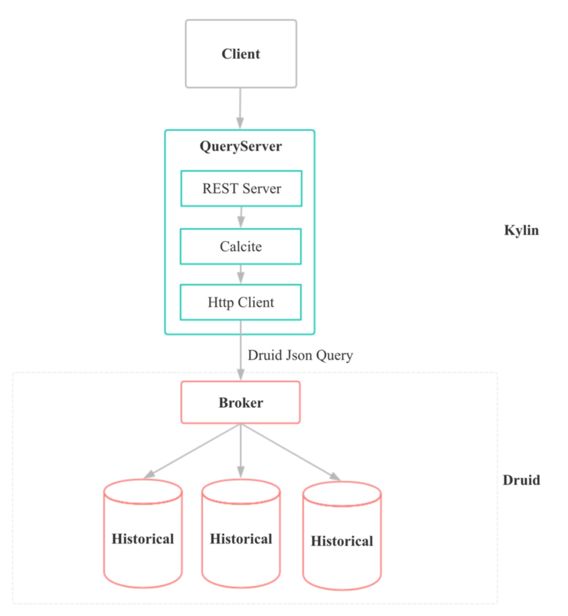
图10 查询Cube 流程
Schema 映射
Kylin 的一个 Cube 会被映射到 Druid 的一个 Data Source
Kylin 的一个 Segment 会被映射到 Druid 的一到多个 Segment
Kylin 的分区时间列映射到 Druid 的时间戳列
Kylin 的 Cuboid 映射到 Druid 的单个维度列
Kylin 的维度列映射到 Druid 的维度列
Kylin 的度量列映射到 Druid 的度量列
总结
在这篇文章里,我们首先分析了Kylin 和 Druid 各自的特点和优势,以及Kylin on HBase 在一些情况下性能不佳的原因;然后基于症状寻找解决办法,得出使用 Druid 作为 Kylin 存储引擎的可行方案;接下来分析了美团开发的 Kylin on Druid 的架构和流程。关于 Kylin on Druid 的使用方式和性能分析,以及Kylin on Druid 目前有哪些尚待完善的部分,请期待下篇文章。
如何使用Kylin on Druid
准备阶段
准备一个 Druid 集群,并且注意以下几点: a) 使用 MySQL 作为元数据存储 b) 使用 HDFS 作为 Deep Storage c) Druid 版本至少为 0.11 d) 因为数据存储和聚合都在 Historical 执行,需要将主要的资源分配给 Historical(Middle Manager 和 Overload 在 KOD 中并不被使用)
从 Kylin 的 Github 仓库获取 kylin-on-druid 分支的最新代码并打包。
修改 kylin.properties,增加配置项。 请参考: https://github.com/apache/kylin/blob/kylin-on-druid/storage-druid/README.md,以下仅列举主要配置 a) kylin.storage.druid.coordinator-addresses 指定了 Druid 的 coordinator 节点地址 b) kylin.storage.druid.broker-host 指定了 Druid 的 Broker 节点地址 c) kylin.storage.druid.mysql-url 指定了作为 Druid 元数据存储的 MySQL 的 JDBC url d) kylin.storage.druid.mysql-seg-table 指定了 Druid 元数据存储 segment 信息的 MySQL 表名 e) kylin.storage.druid.hdfs-location 指定了 Druid Segment 文件在 HDFS 的存储路径 以下是测试环境的配置: 图 1 Kylin 配置文件
按照正常的启动方式启动Kylin。
构建 Cube 阶段
1. 在 Cube Design 界面的第五步(高级设置)设置 Cube Engine 和 Cube Storage 分别为 MapReduce 和 Druid。Cube 设置全部完成后,选择“ Build Cube ”。
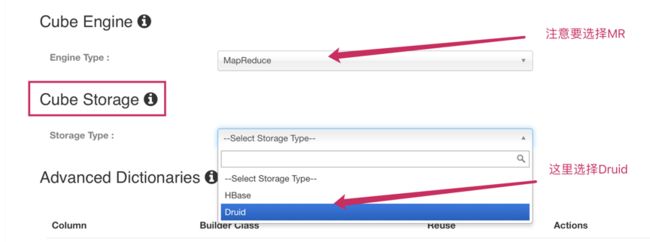
图 2 高级设置中的 Cube Storage 选项
2. 观察 Cube 构建过程,等待构建完成,以下展示了构建 Cube 各个新增步骤的说明和步骤运行成功时的输出信息:
a) “Calculate Shards Info”根据配置项,计算出 Druid Segment File 的数量。

图 3 Calculate Shards Info
从 Output 看出这里设置为 2 个 Segment File,每个约 500 MB。
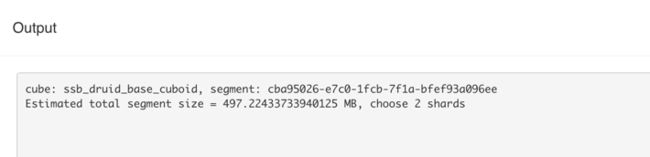
图 4 Calculate Shards Info 输出
b) “Update Druid Tier” 更新 Druid Tier 的 Rule
图 5 Update Druid Tier
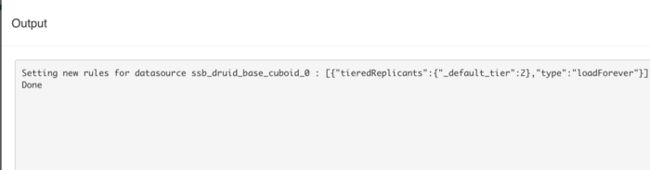
图 6 Update Druid Tier 输出
c) “Convert Cuboid to Druid” 启动一个 MapReduce Job,将 Cuboid 文件转为 Druid 的列式存储格式,生成数据放到 HDFS 的指定目录

图 7 Convert Cuboid to Druid
MapReduce Job 的统计数据
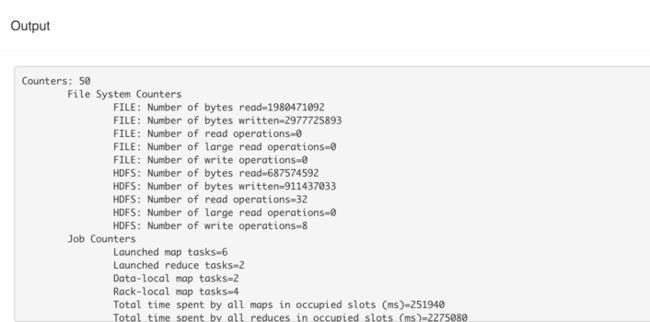
图 8 Convert Cuboid to Druid 输出
该步骤结束时可以检查到文件已经存在于 HDFS 上。

图 9 Convert Cuboid to Druid 生成文件
d) “Load Segment to Druid” 通过 MySQL 来向 Druid 集群 announce 新的 Druid Segment,等到 Segment 已经完全被分发到各个 Druid Historical 才结束该 step。
图 10 Load Segment to Druid
从 Output 看到,首先修改 MySQL 元数据信息花费了 0.11 秒,然后等待 Druid 集群将上步生成的两个 segment 文件 download 到 Historical,这个过程时间约为两分钟。
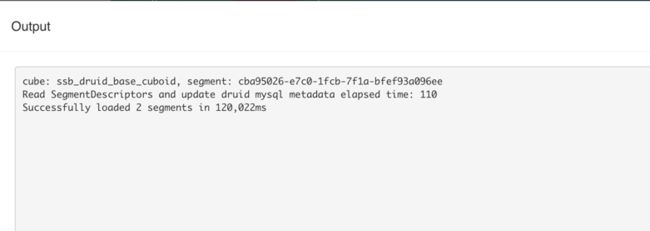
图 11 Load Segment to Druid 输出
运行过程中观察 Coordinator Web UI,可以看到 Data Source 的图标从红色变成蓝色。

图 12 Coordinator Web UI
e) Cube 构建完成
图 13 Cube 构建完成
f) 检查 Druid Segment 状态和分布,检查 Schema 是否正确(可选);通过 Druid API 查看 Cube 对应的 Druid Data Source 的元数据。
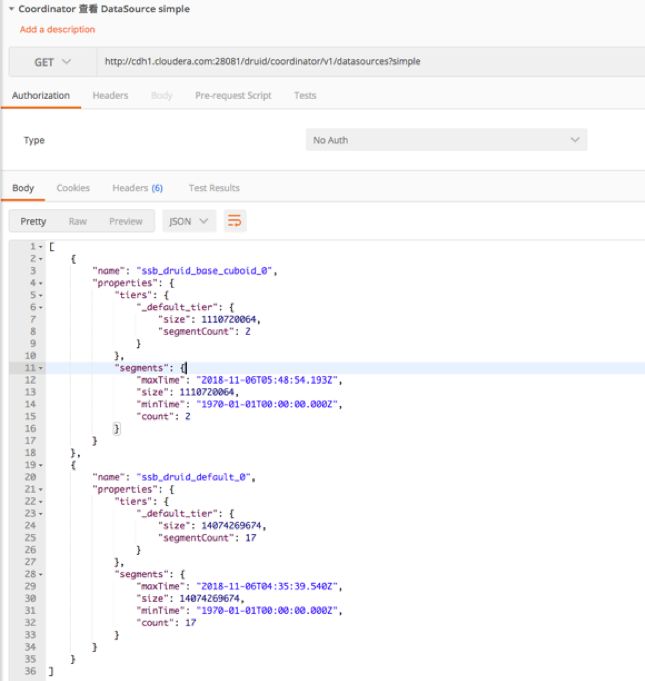
图 14 Data Source Schema
通过 Druid API 查看 Druid Segments 的明细数据。
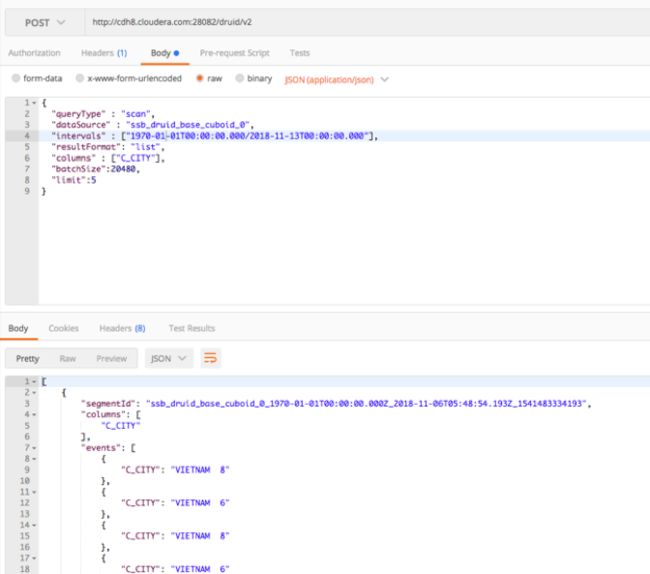
图 15 Data Source Data
检查单个节点的上已经从 Deep Storage 下载下来的 Segment 数据文件。
图 16 Local Cache
Kylin on Druid 的查询时长对比
我们在测试环境下基于 SSB 数据构建不同 Cube,通过比较在不同 Cube 上相同 SQL 的查询用时,来了解使用 Kylin on Druid 对查询用时的影响。
我们使用 SSB 生成测试数据,数据量 29,999,795。
Druid 集群规格如下:
8 台虚拟机(8core, 65GB Memory),其中一台部署 Overlord 和 Coordinator,1 台部署 Broker,6 台部署 Middle Manager 和 Historical,其中 Historical 配置参数如下。
图 17 Historical JVM 参数
图 18 Historical 参数
以下为三种 Cube 构建方案的描述:
Druid Base(绿色列)指的是使用 Druid 作为存储,只构建 Base Cuboid
HBase Base(蓝色列)指的是使用 HBase 作为存储,只构建 Base Cuboid
HBase Default(红色列)指的是使用 kylin-ssb 默认的 cube 元数据的构建方案
下图为三种方案构建的 Cube 在不同查询语句下的平均查询用时对比
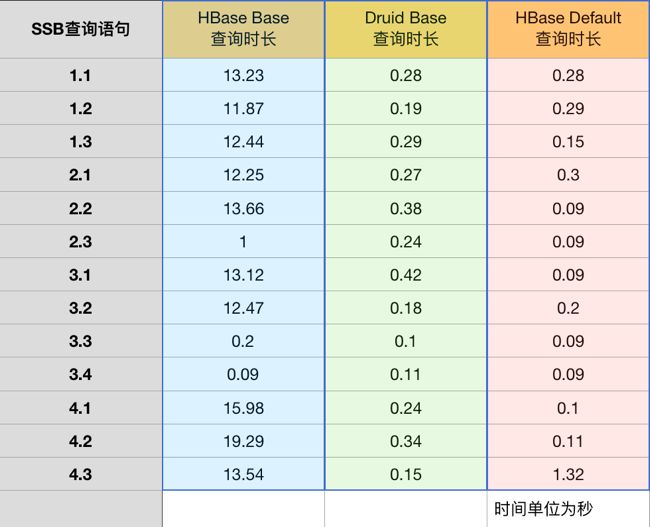
图 19 SSB 查询时长
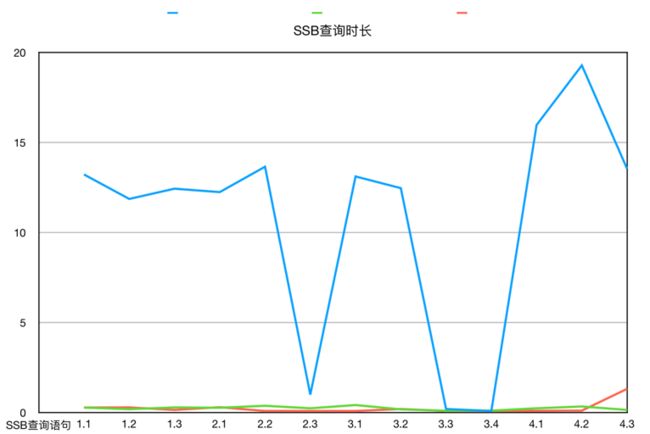
图 20 SSB 查询时长-折线图
结论
关于构建 Cube 时间和 MapReduce 内存,使用 Druid 占用资源略多。基于 Druid 只构建 base cuboid 得到的 Cube,与基于 HBase 根据复杂剪枝设置得到的 Cube 有了相当的查询性能。可见利用 Druid 高效的 filter 和 scan,Kylin 的现场计算能力有了十分明显的提升。而如果 Cube 设计得当,且计算较多 Cuboid 的话,HBase 的性能跟 Druid 不分伯仲。
美团 Kylin on Druid 的线上环境表现
美团点评是 Apache Kylin 的重度用户,Kylin 覆盖了美团点评主要业务线,截止 2018 年 8 月的数字,每天的查询次数超过 380 万次。美团第一批上线使用 Kylin on Druid 后,Cube 存储使用减少了约 79%,构建过程的内存和 CPU 使用减少了 20% 左右;从查询时长观察,大部分的查询用时减少了 50% 以上(图21来自于 Kylin 北京 Meetup 上康凯森的分享内容)。

图 21 Kylin Meetup PPT
Kylin on Druid 的总结
目前 Kylin on Druid 的限制和要求
要求 Druid 使用 MySQL 作为元数据存储,使用 HDFS 作为分布式存储
Druid 需要 0.11 版本或者以上,Java 需要 JDK8 或者以上
Cube 构建目前只支持 MapReduce
Cuboid 数量相同时,Kylin on Druid 较使用 HBase 构建 Cube 而言,时间和计算资源使用一般稍多
Measure 尚不能完全支持,美团近期即将开源的包括 EXTENDED_COLUMN、Count Distinct(BitSet),这些 Measure 需要以向 Druid 添加扩展的方式支持;Count Distinct(HyperLogLog) 后续根据需求开发
Decimal 类型在 Druid 端使用 double 替换,美团近期也会提供准确的 Decimal 类型支持
转换为 Druid Segment 步骤使用内存比转HFile更多,一般需要分配更多内存
Kylin on Druid 的优势
1. 查询时无需加载字典,因此相比 Kylin on HBase 查询稳定性更高
2. 存储层支持业务隔离
3. 亿级及以下数据只需构建 Base Cuboid
4. 构建资源使用减少(因为需要构建的 Cuboid 数量减少了),查询时长减少(因为现场计算能力有了比较好的提升)
何时使用Kylin on Druid
1. 对 Druid 有充分的理解,有足够的经验去部署和运维 Druid 集群
2. 有足够的机器资源部署Druid
3. 查询没有较为固定的模式,因此大部分查询难以精确匹配Cube预计算得到的维度组合,可以利用Kylin on Druid来加速现场计算能力
4. 对查询响应速度有较高的要求
总结
在这两篇文章中,我们一步一步分析 Kylin 目前使用 HBase 作为存储的不足之处,同时比较了 Kylin 和 Druid 各自的特点,得出了将两者相结合的 Kylin on Druid 的方案。
随后介绍了美团开发的 KOD 使用方式,通过不同 Cube 构建方案的查询时长对比,得出 KOD 较原有 HBase 存储有较大性能和易用性提升的结论。最后总结了 KOD 的优势和使用经验,也了解到 KOD 目前有部分功能尚未完成。
目前这部分代码在 Kylin 的 Git 仓库的“ kylin-on-druid ”分支,欢迎广大开发者试用并积极参与开发和改进,更多问题可以发送到 Kylin 开发者邮件群组 [email protected] 进行讨论,谢谢大家。
参考链接
https://issues.apache.org/jira/projects/KYLIN/issues/KYLIN-3694
https://github.com/apache/kylin/tree/kylin-on-druid
https://blog.bcmeng.com/post/kylin-on-druid.html
http://druid.io/docs/latest/design
原文链接:
https://kyligence.io/zh/blog/why-meituan-develop-kylin-on-druid-i/